交叉重复提取妙计! wps中REGEXP正则表达式函数用法
脚本之家
问题求助SOS:如何对比两个单元格字符,将交叉重复的字符提取到另一个单元格中?
虽然小编不知道这位朋友咨询的问题具体应用于什么办公场景中,但既然提出了问题,肯定就是存在具体的需求,那咱就要想方法解决一下。


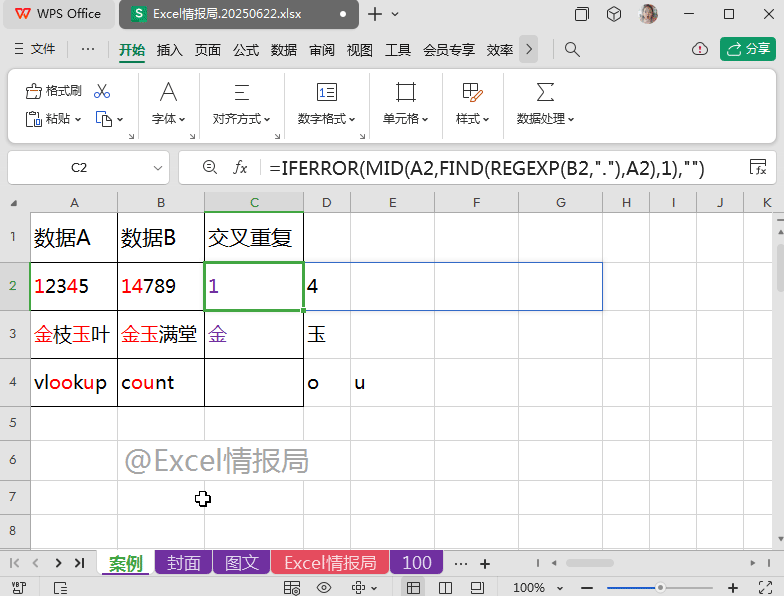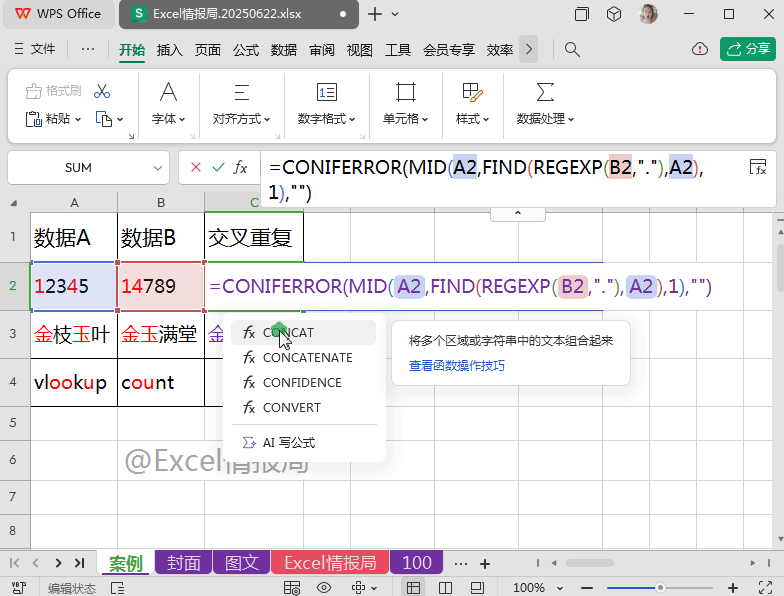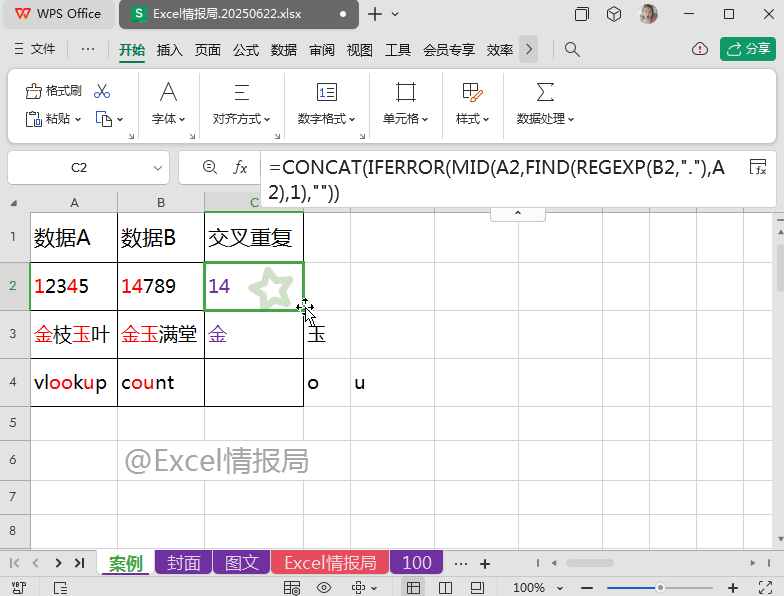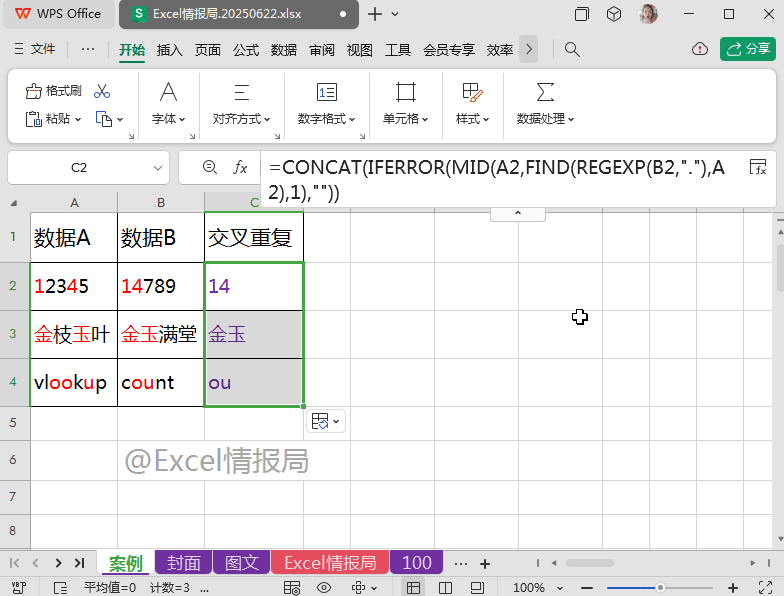
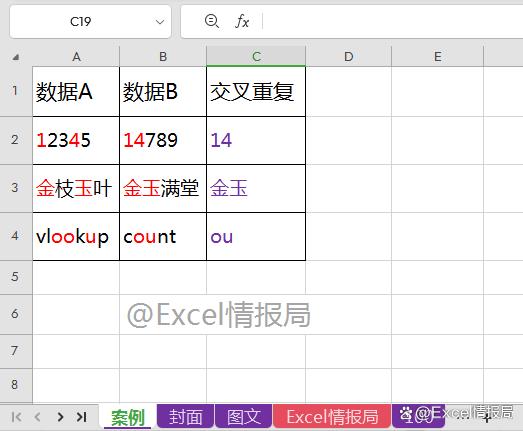
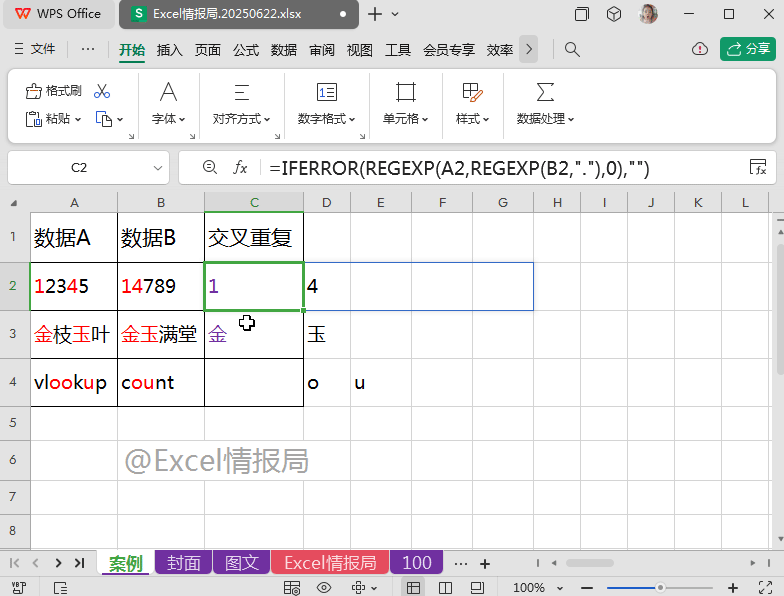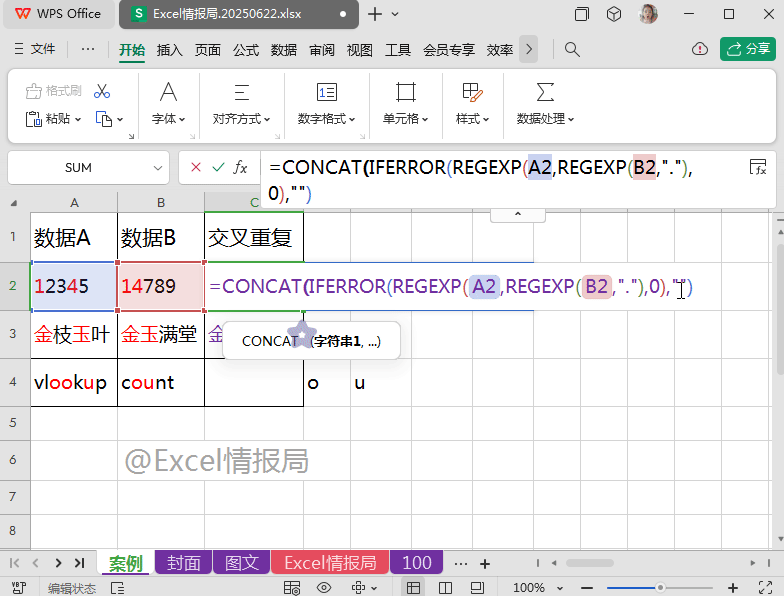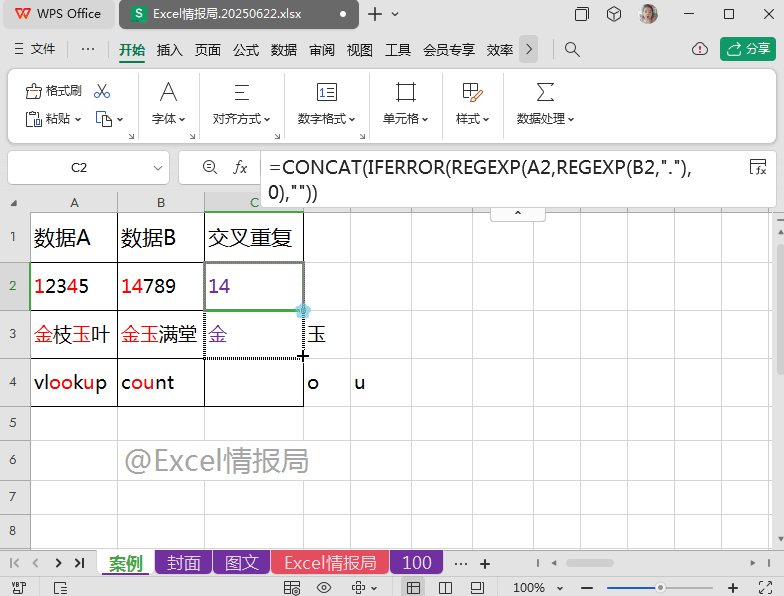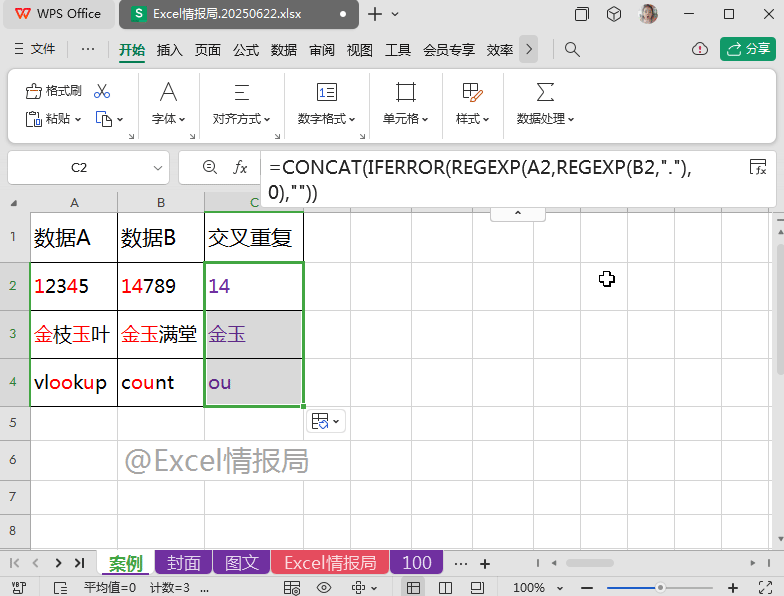
如下图所示:
有“数据A”与“数据B”两列数据,我们想要把每行对应的两个单元格中的重复出现的字符提取到C列单元格中显示。
比如A2与B2单元格中都存在“1”与“4”,故在C2单元格中显示交叉重复值:“14”。
举例数据清晰明了,提干相对简单。
下面我们分两种思路进行问题剖析,两种方法都用到了REGEXP正则表达式函数(WPS版),可见学习并了解一些REGEXP函数的常规知识很重要。
第一步:正则字符拆分
输入强大的REGEXP正则表达式函数:
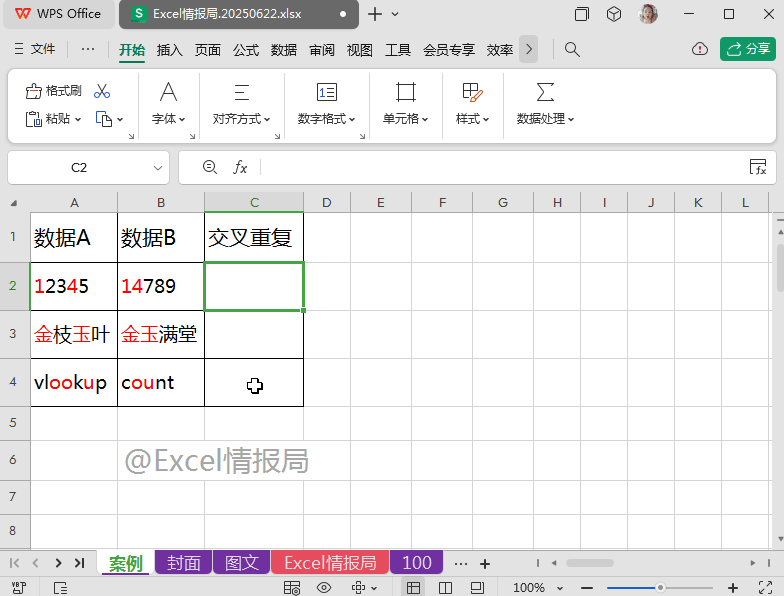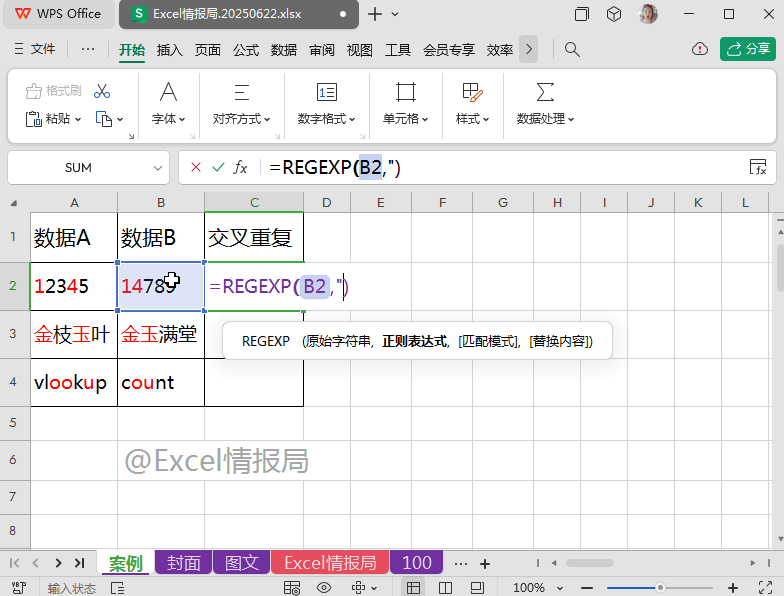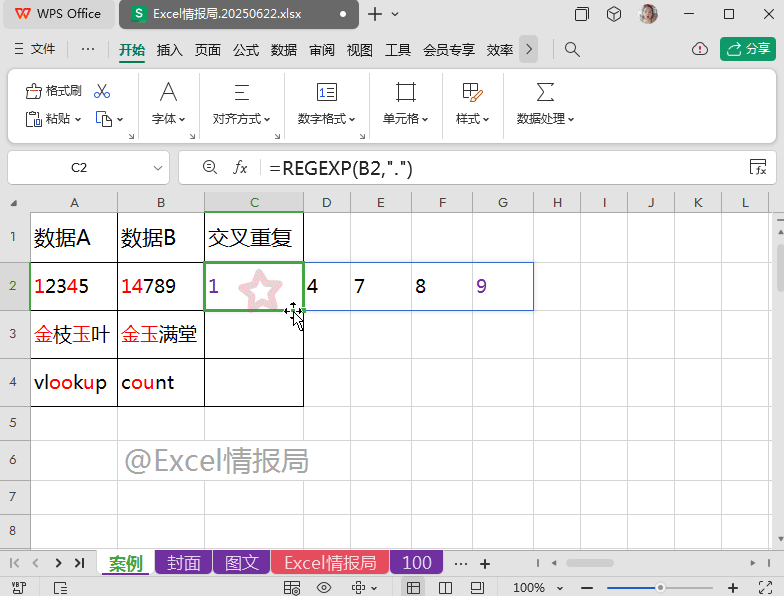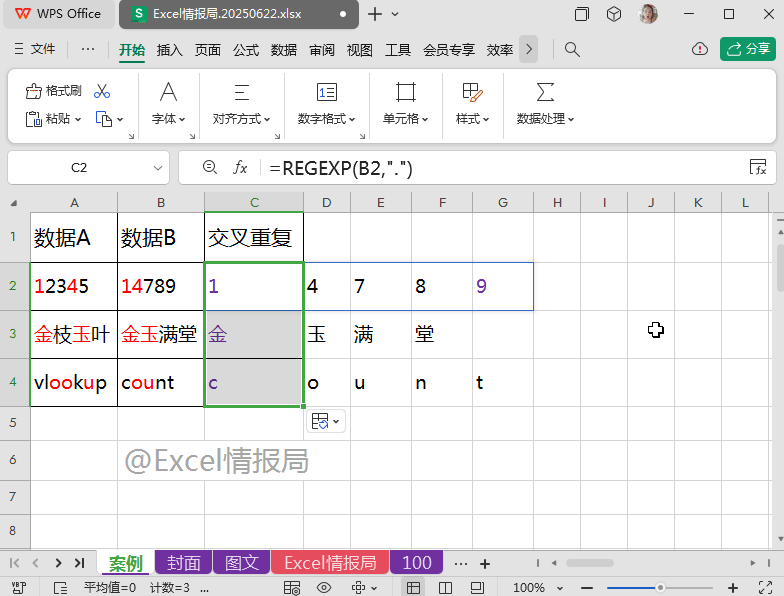
=REGEXP(B2,".")
.(点):表示任意的单个字符。
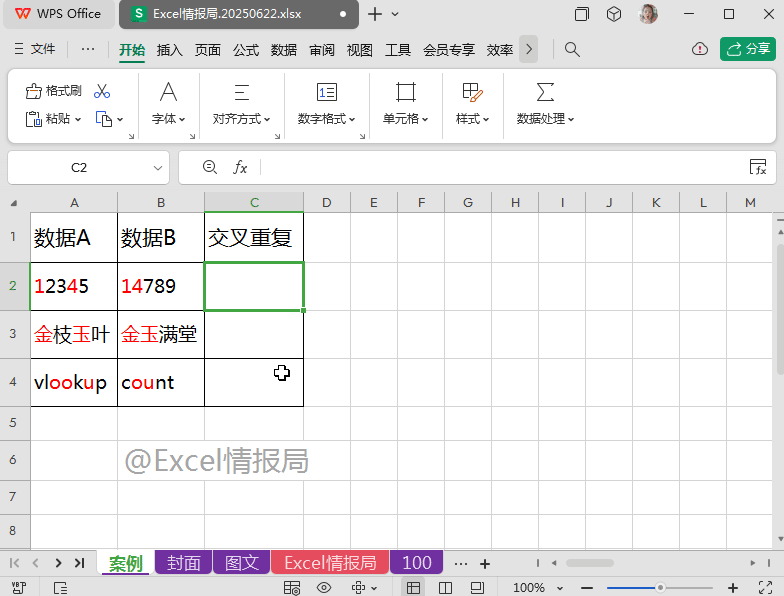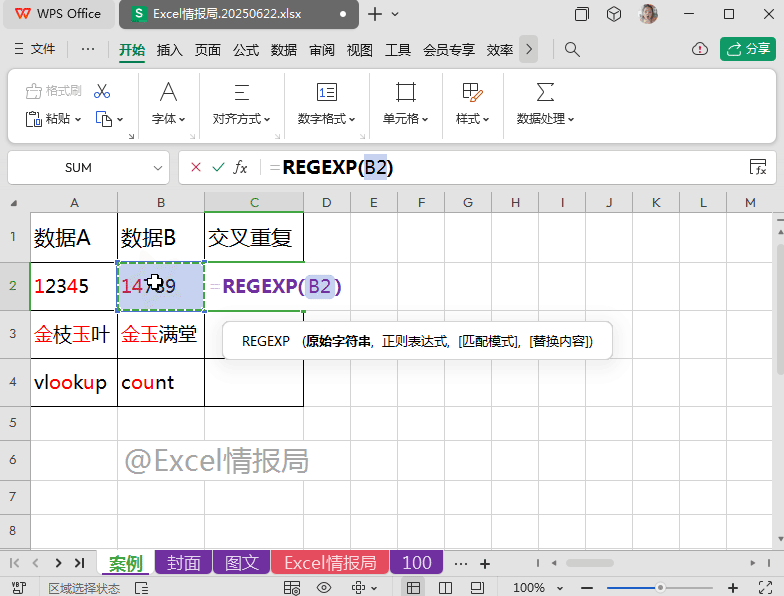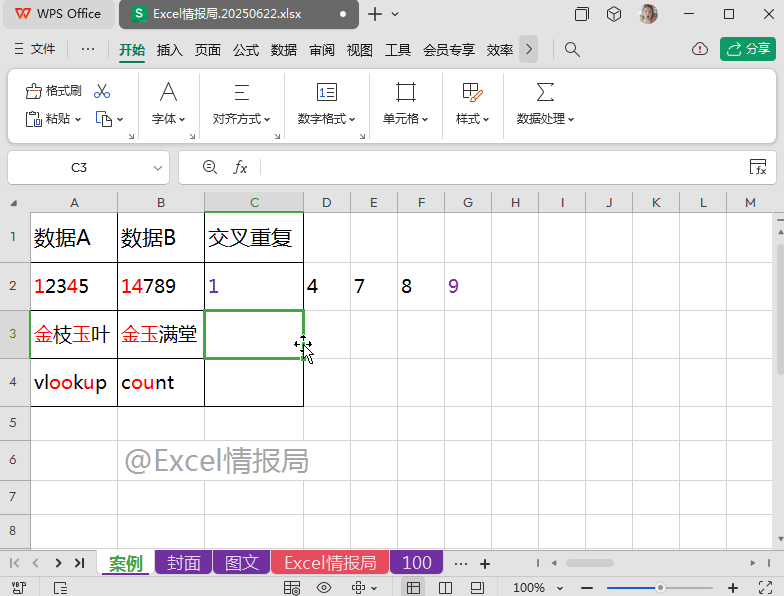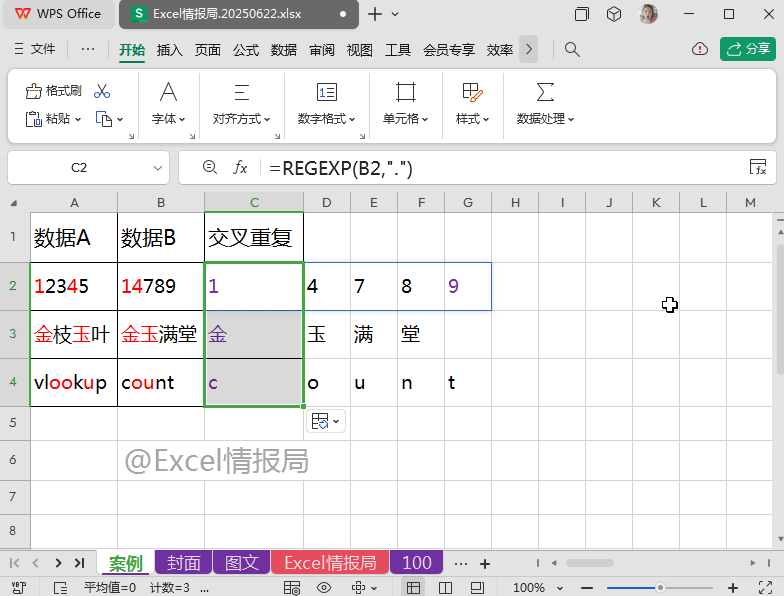
REGEXP函数省略第3参数,表示“提取”模式。提取B2单元格中任意的单个字符,则会把所有的单个字符以数组溢出的方式显示在一行多个单元格中。
此步的核心目的:
按1个字符的长度进行数据分列。
第二步:正则二次提取
继续向外嵌套一个REGEXP函数:
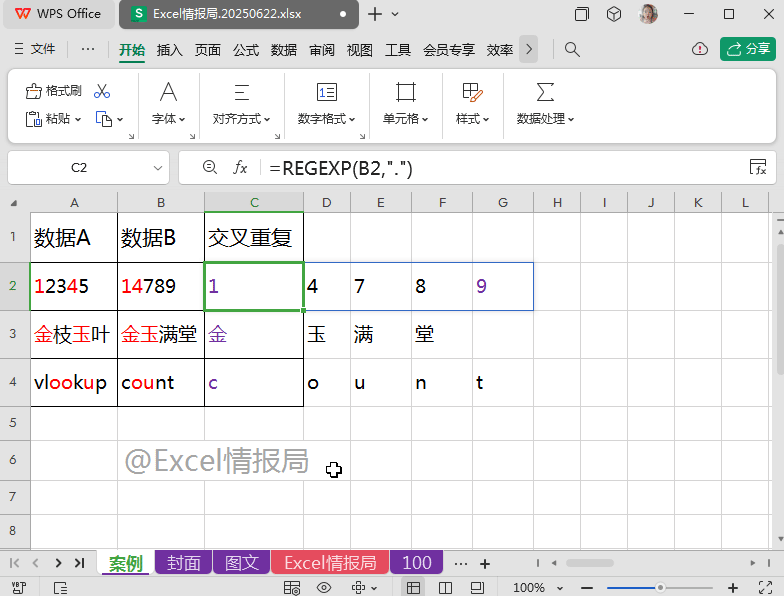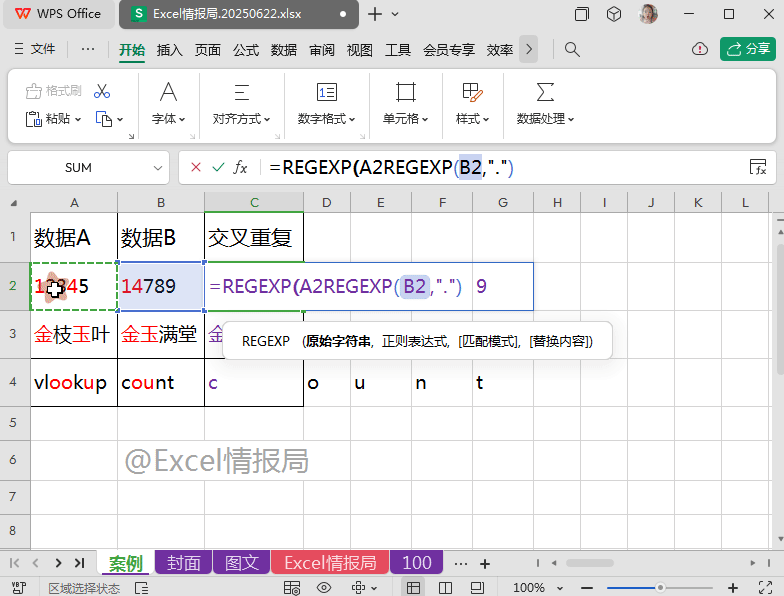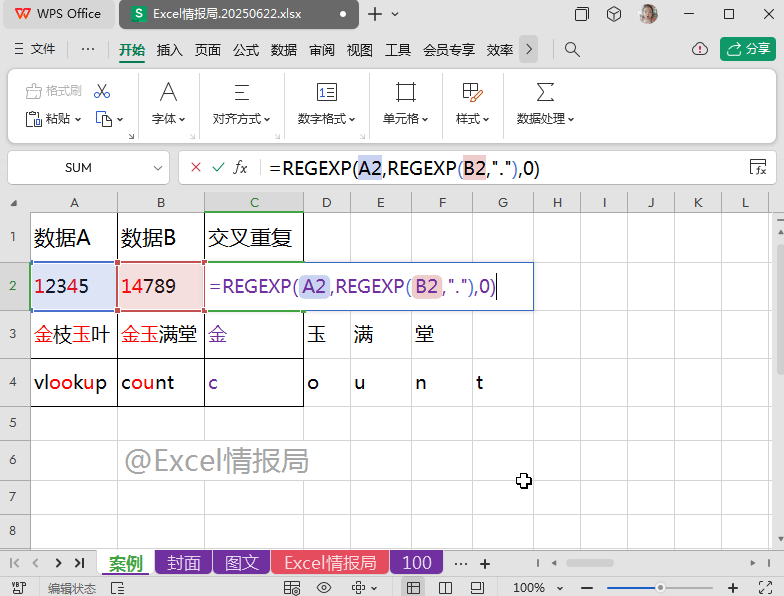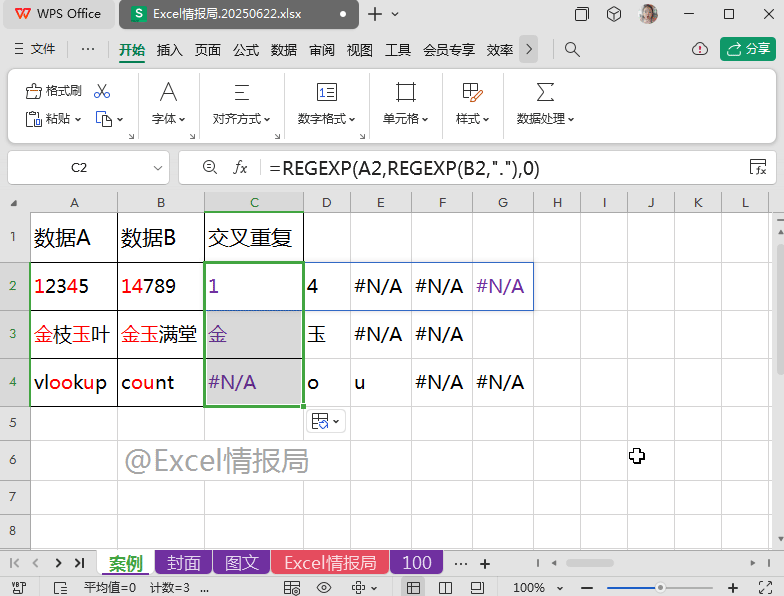
=REGEXP(A2,REGEXP(B2,"."),0)
我们将上一步REGEXP提取到B2单元格的每个字符在A2单元格内容中进行查找,如果出现过,则被提取显示出来;没有出现过的,则显示成错误值。
比如B2单元格中的字符“1”与“4”,在A2单元格“12345”内容中出现过,故显示为“1”与“4”,而B2单元格中的字符“7”与“8”与“9”,在A2单元格“12345”内容中未出现过,故显示为错误值。
原理很容易理解。
第三步:规避错误值
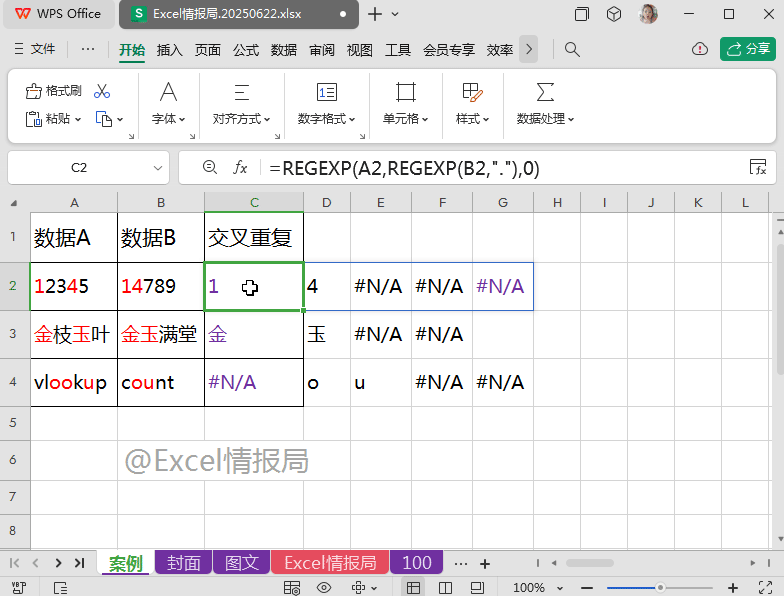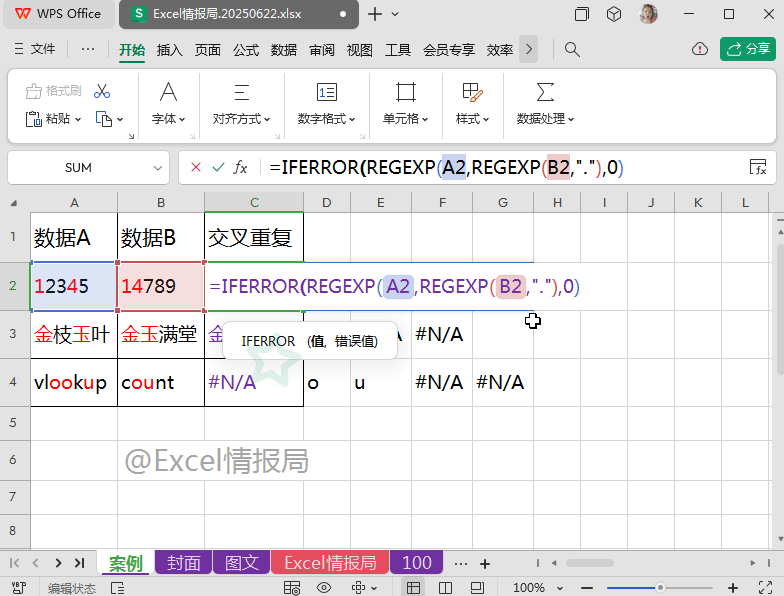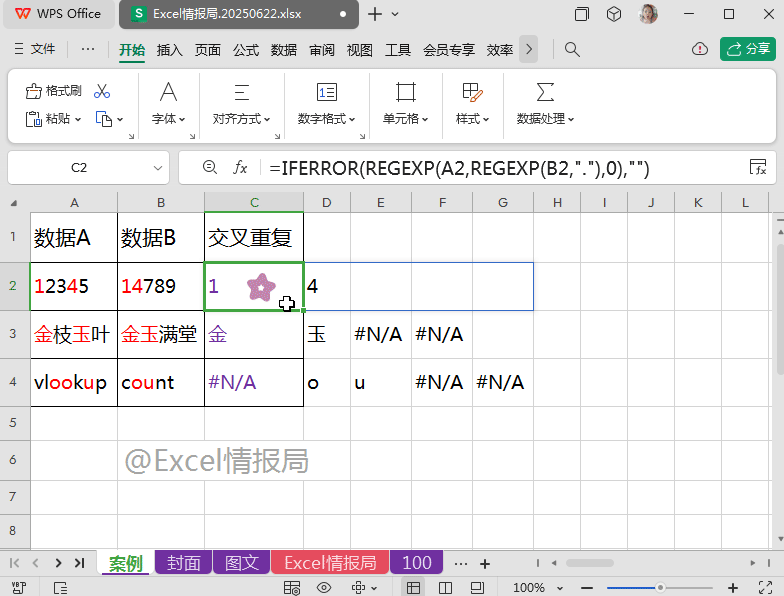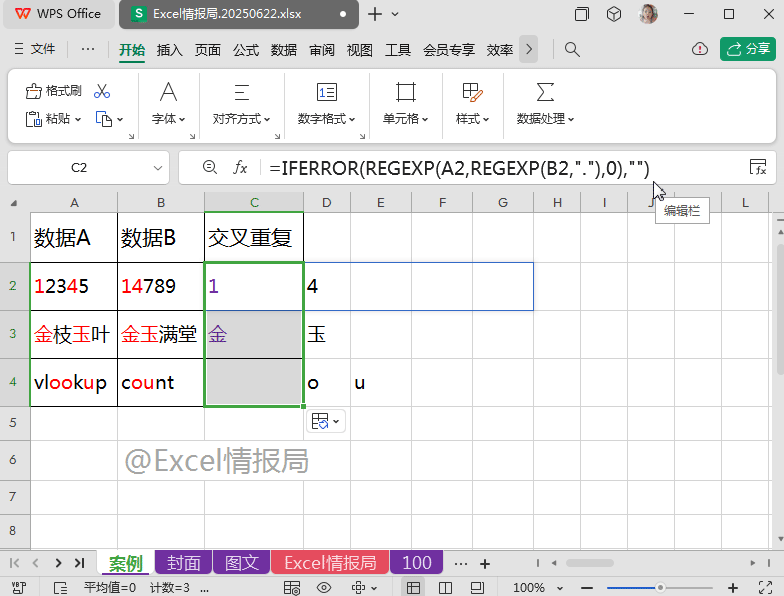
使用常见的规避错误值函数IFERROR函数:
=IFERROR(REGEXP(A2,REGEXP(B2,"."),0),"")
将上一步的公式,作为IFERROR函数的第一参数判断条件,如果第一参数返回错误值,则强制执行显示为第二参数空值;否则返回第一参数本身。
第四步:合并
使用常规的CONCAT合并类函数:
=CONCAT(IFERROR(REGEXP(A2,REGEXP(B2,"."),0),""))
将上一步提取到的、散落在不同单元格的“交叉重复值”,合并到一个单元格中显示。
如果想用间隔符进行间隔的话,可以用TEXTJOIN函数代替CONCAT函数。
下面我们继续说说第二种解题思路。
第一步:正则字符拆分
使用REGEXP函数:
=REGEXP(B2,".")
与第一种方法的第一步原理完全相同。核心目的:按1个字符的长度进行数据分列。
第二步:查找
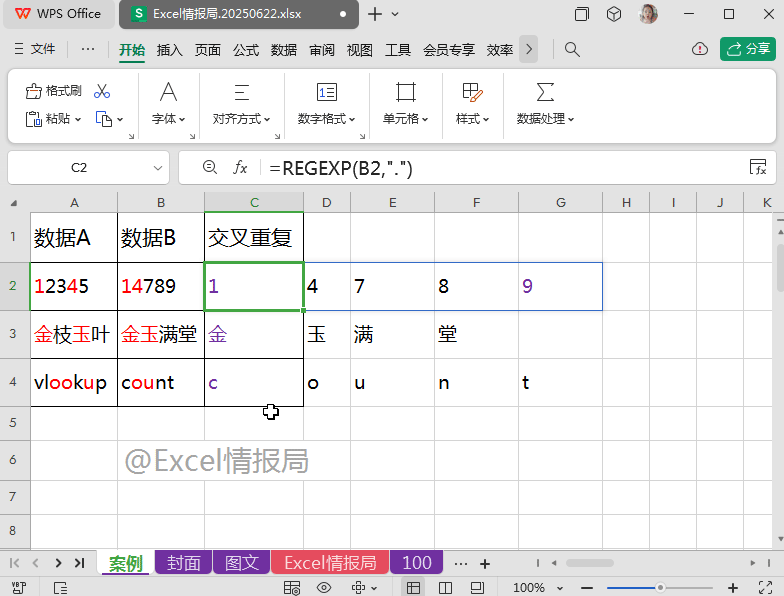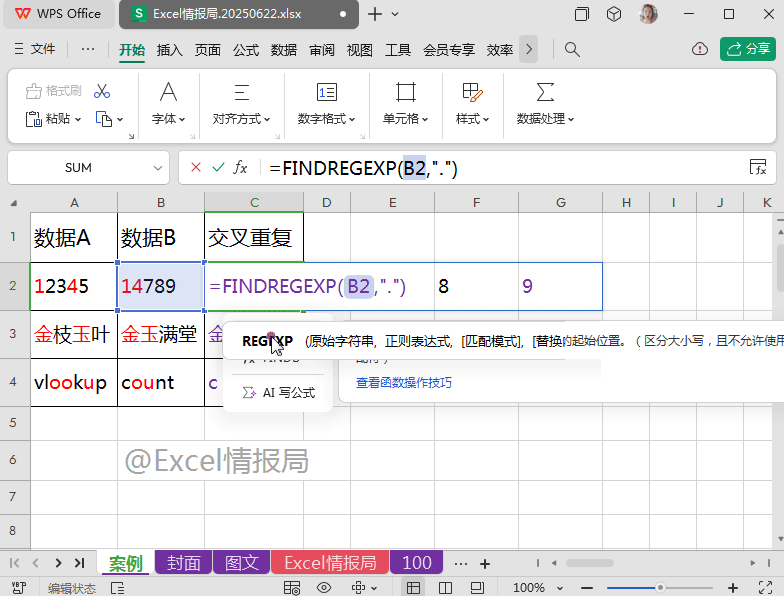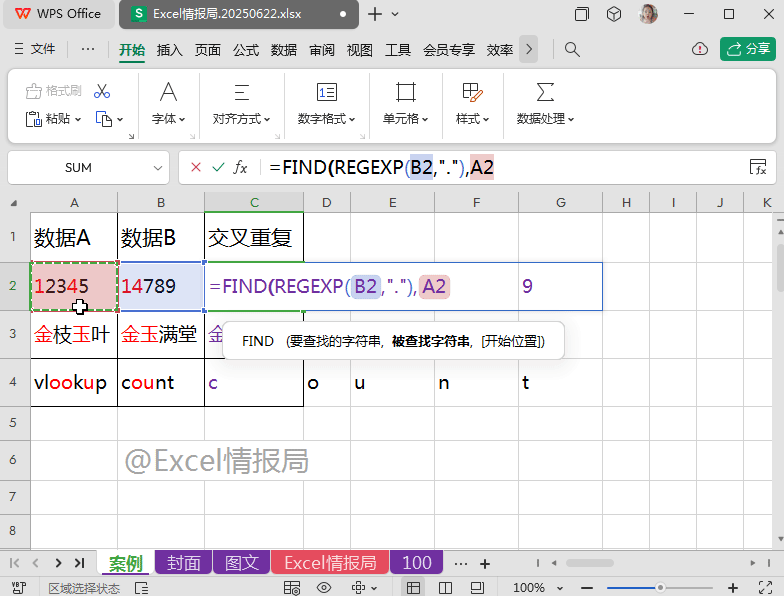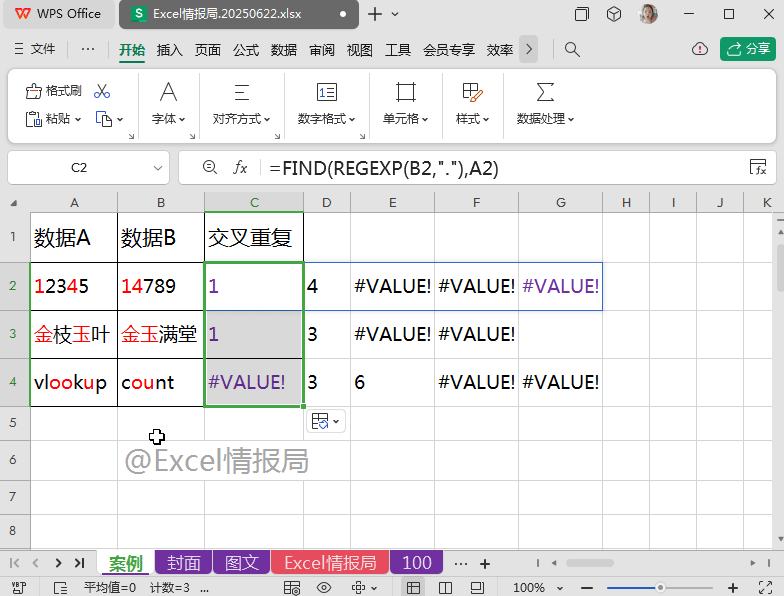
使用FIND查找函数:
=FIND(REGEXP(B2,"."),A2)
查找B2单元格中的每个字符,依次在A2单元格中出现的起始位置。
比如B2单元格中的“1”与“4”在A2单元格中的起始位置依次是第1个位置与第4个位置,故返回“1”与“4”;而“7”、“8”、“9”在A2单元格中均未出现过,所以查找不到对应的位置,显示错误值。
第三步:提取
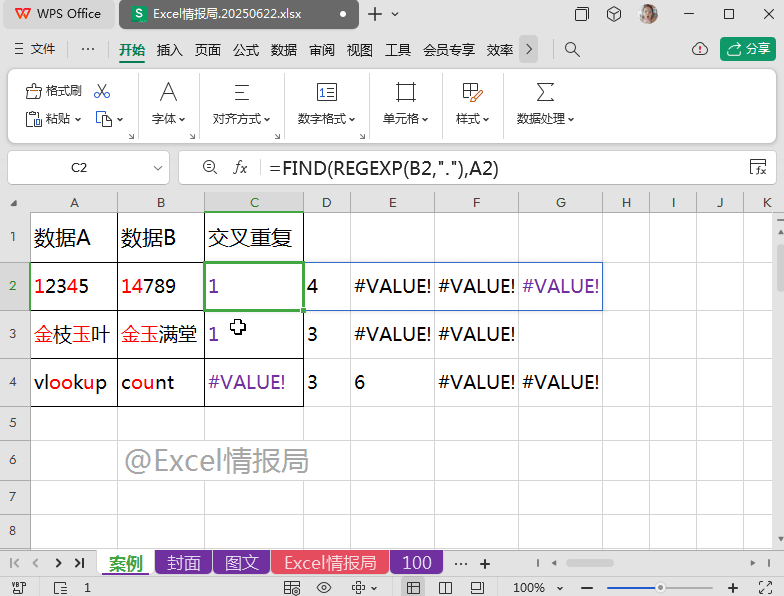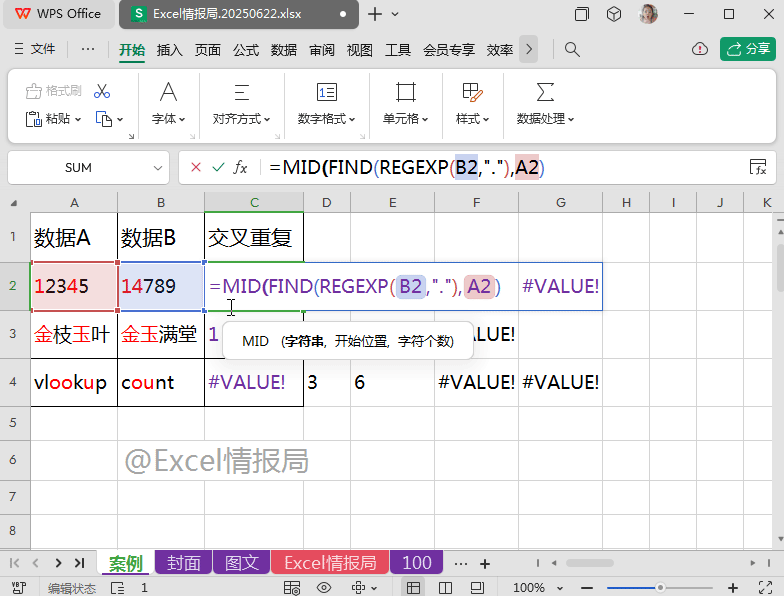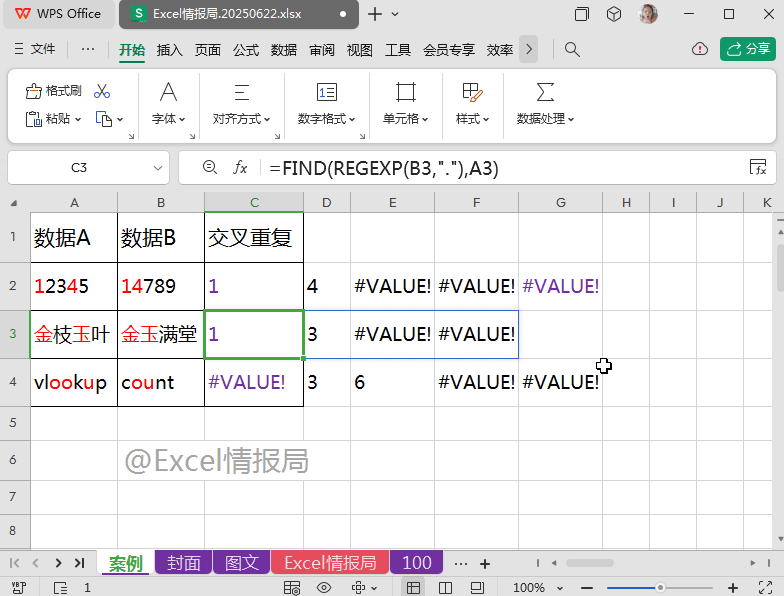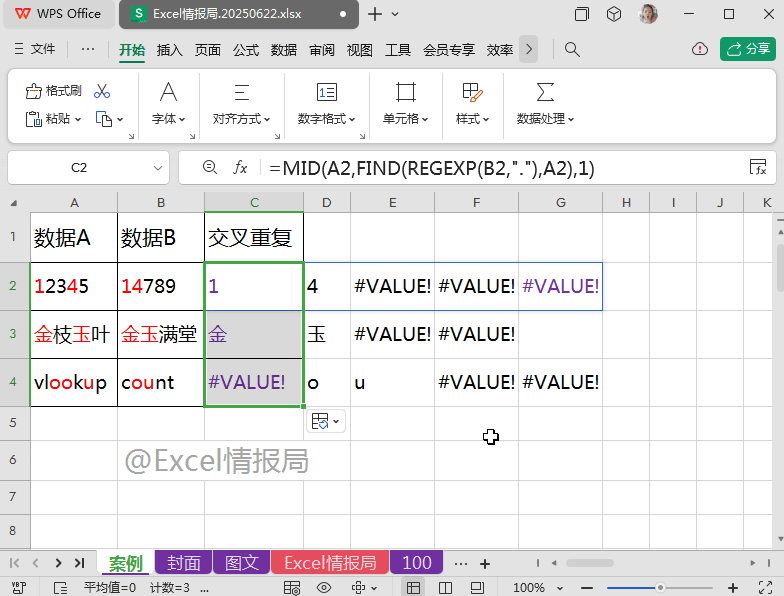
使用MID提取类函数:
=MID(A2,FIND(REGEXP(B2,"."),A2),1)
以A2、B2单元格为例:
在A2单元格内,分别从第1个起始位置处、第4个起始位置处,提取字符长度为1的字符串,故返回“1”与“4”。
第四步:规避错误值
使用IFERROR函数:
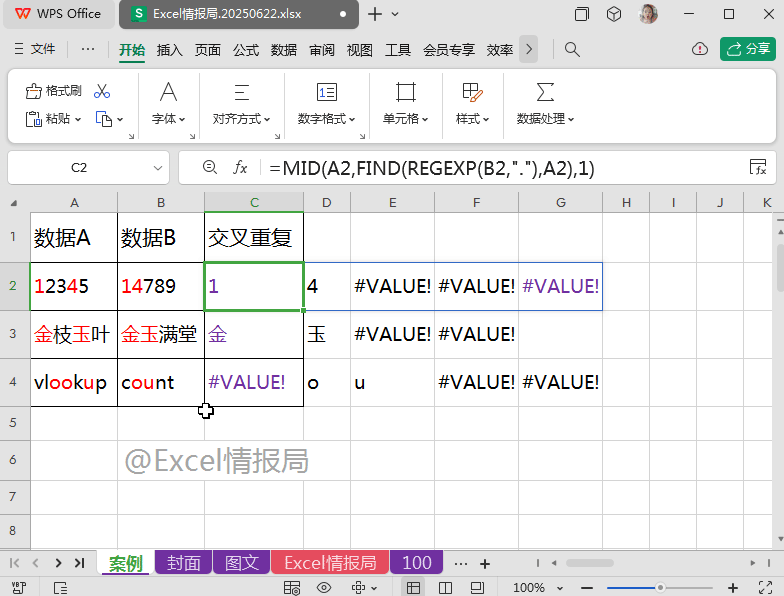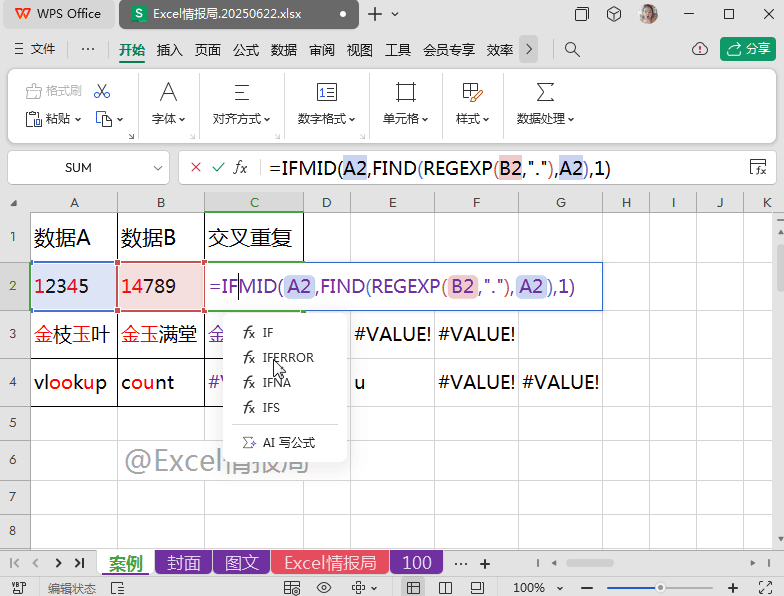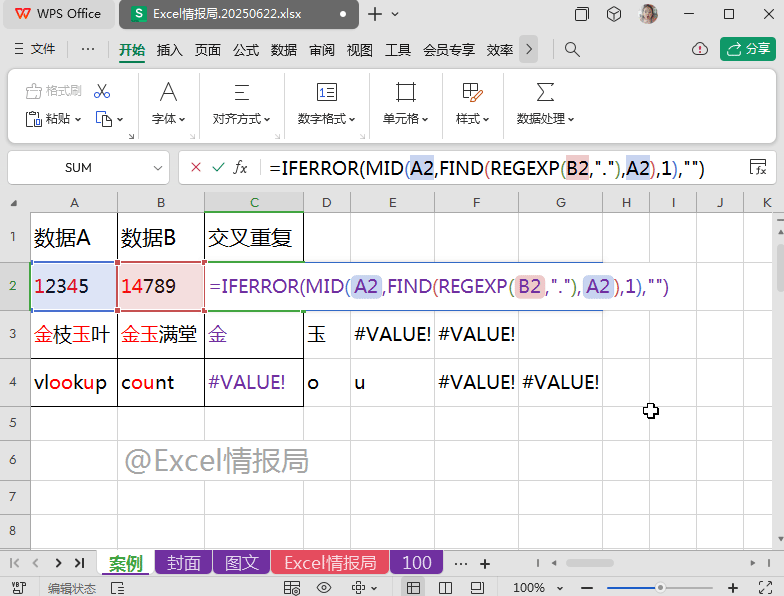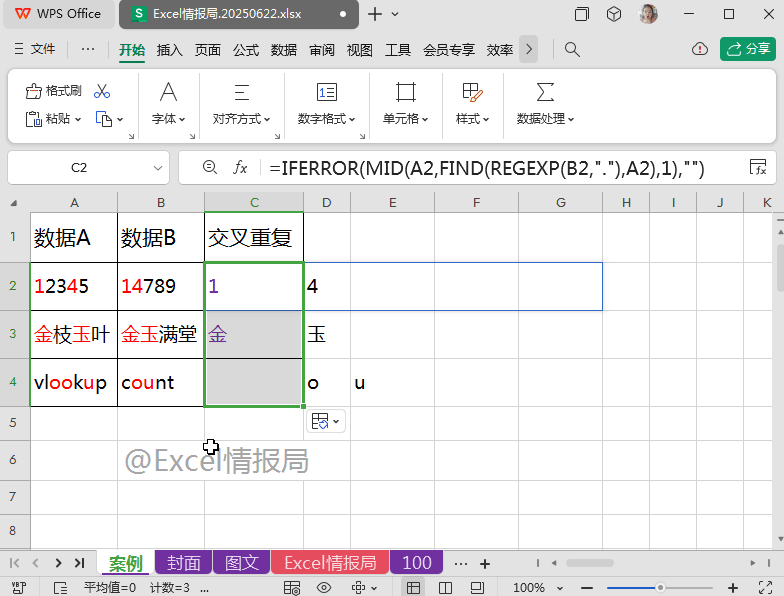
=IFERROR(MID(A2,FIND(REGEXP(B2,"."),A2),1),"")
如果第一参数(上一步公式返回结果)为错误值,则显示为第二参数指定的固定值空值。否则返回第一参数本身。
第五步:合并
使用CONCAT合并类函数:
=CONCAT(IFERROR(MID(A2,FIND(REGEXP(B2,"."),A2),1),""))
将上一步返回的“交叉重复值”合并到一个单元格中显示。