我终于理解透了! 深入浅出wps正则表达式中的边界\b和\B概念
脚本之家
有的小伙伴反馈WPS表格“正则表达式 \b与\B 单词边界概念太抽象了”,我咋理解不了呢?不用怕,我们再来深入的研究一下。


\b(单词边界)含义:
匹配单词的开始或结束位置,即单词与非单词字符(如空格、标点符号、字符串首尾)之间的“零宽度”边界。
\B(非单词边界)含义:
匹配不在单词边界的空字符串,即单词字符之间或非单词字符之间的位置。
单看两者的概念,我们好像云里雾里,不明其所以然。
其实我们可以这样理解:
单词边界 \b 就像贴在单词首尾的“隐形标签”,用来标记单词的开始或结束位置。非单词边界 \B 正好互补,匹配不在单词边界的字符,只匹配连续字符内部的位置。常用于连续文本中的子串提取。两者定位的只是位置,本身不占用字符。
我知道你还没听懂,话不多说,上例子。
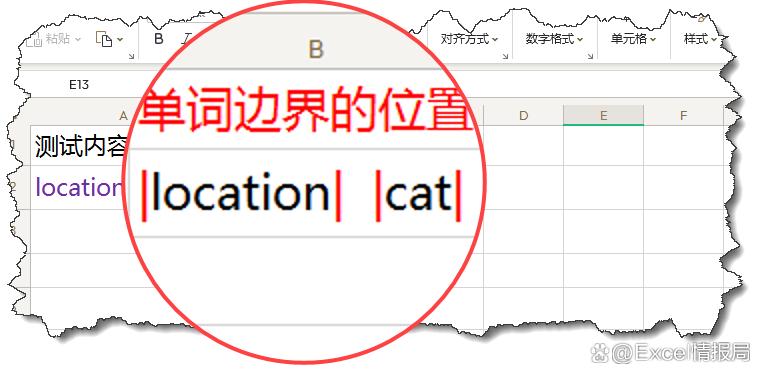
我们先来看\b(单词边界)占用的位置。
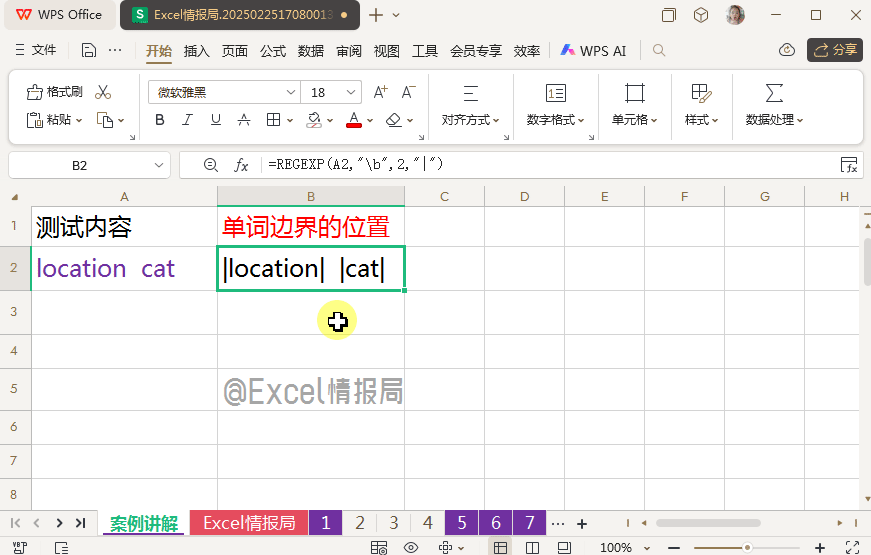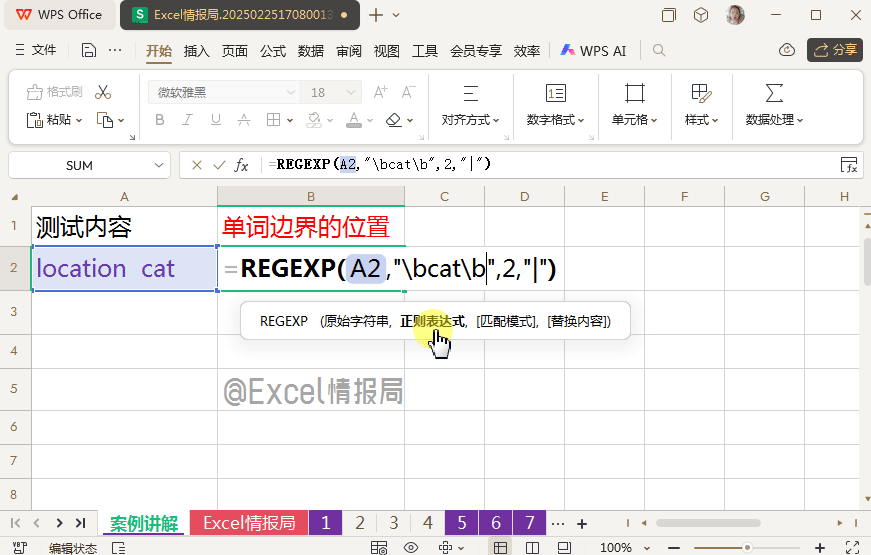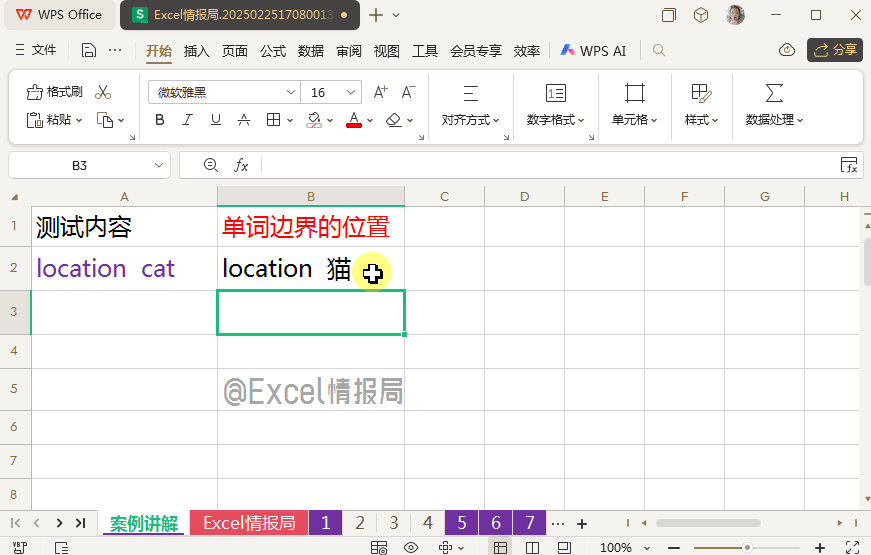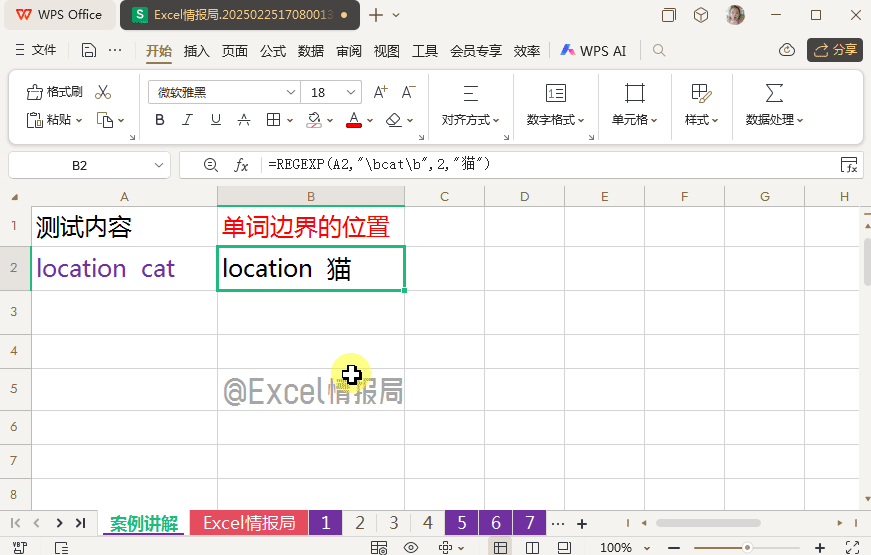
输入公式:
=REGEXP(A2,"\b",2,"|")
我们利用"\b"定位A2中的单词边界,找到边界后,用替换模式,在定位到的单词边界处替换为分隔符“|”,这样我们可以更加直观的看到单词边界在哪里。
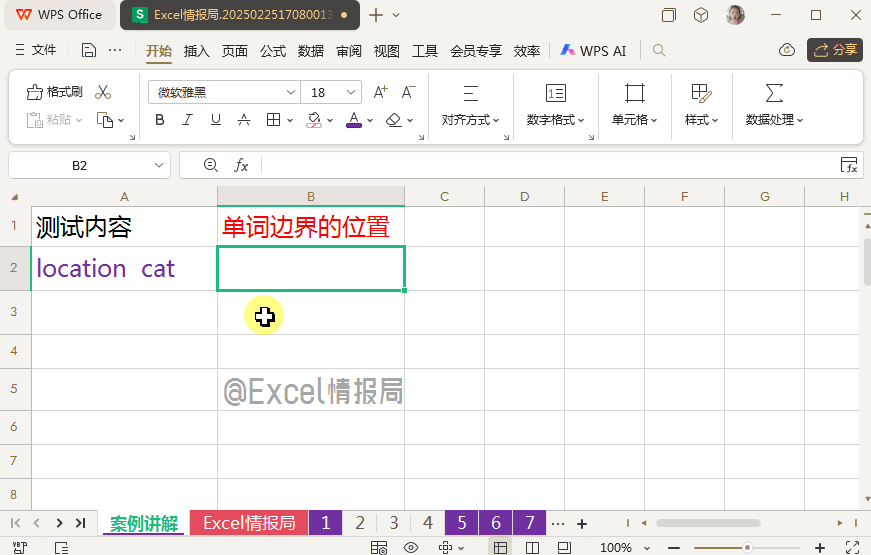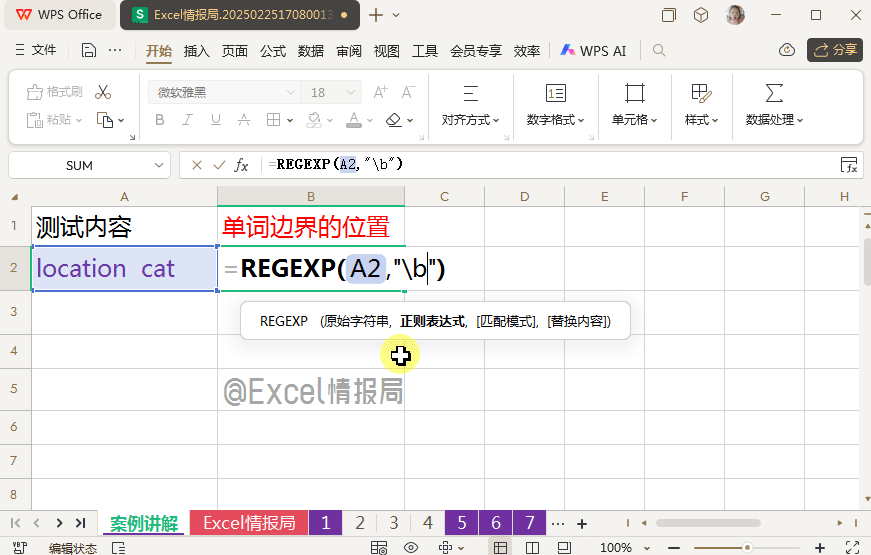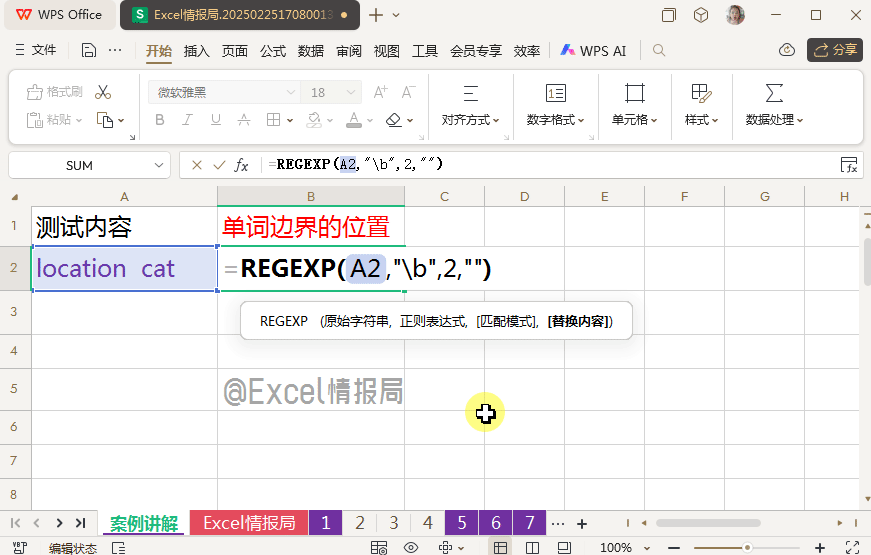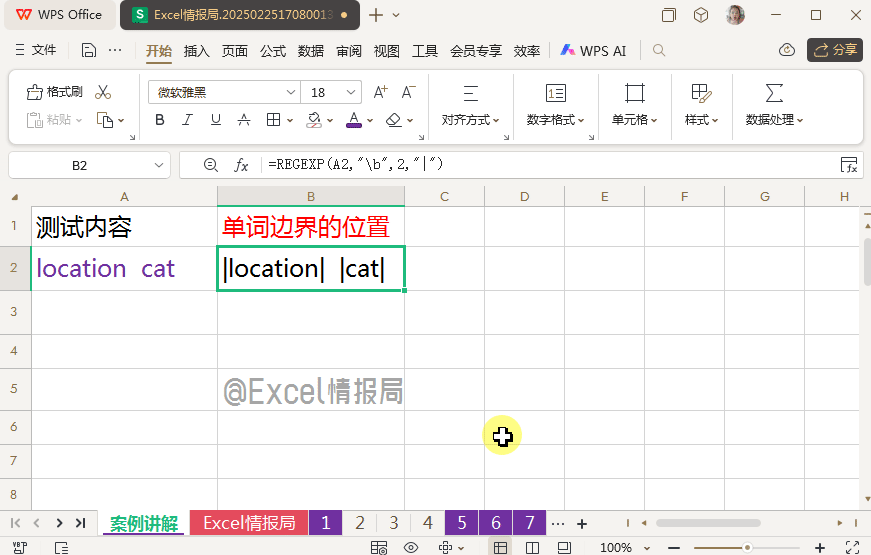
很明显:“location”的首尾处分别是单词边界,“cat”的首尾处分别是单词边界。
印证了我们之前抽象的概念:匹配单词的首尾边界。
应用理解1:
我们要将单独的单词“cat”,替换为“猫”,而“location”中的“cat”则无需替换。这时候就用到了单词边界的概念。
我们输入公式:
=REGEXP(A2,"\bcat\b",2,"猫")
这样我们将左右单词边界\b之间为单纯“cat”的部分,即单独的单词“cat”定位提取,然后替换为"猫"。“location”中的“cat”部分自动忽略。
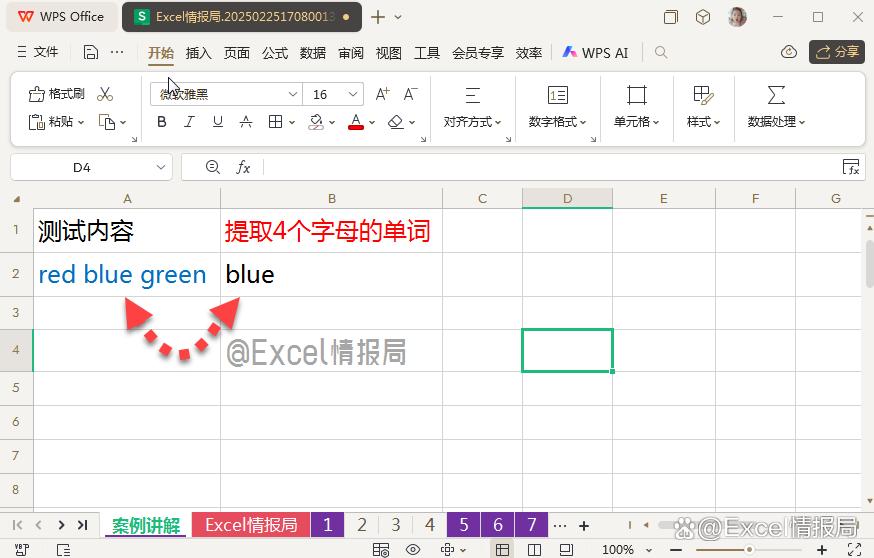
应用理解2:
我们想要将A2单元格内,单独是4个字母的单词提取出来。很明显只有单词“blue”符合这个要求。那么我们就可以利用\b(单词边界)的思路解决。
我们输入公式:
=REGEXP(A2,"\b",2,"|")
首先我们先来观察一下A2单元格内容的单词边界。利用"\b"定位单词边界,然后将边界位置暂时替换为分隔符“|”,有助于我们肉眼直接观察,将抽象具象化。
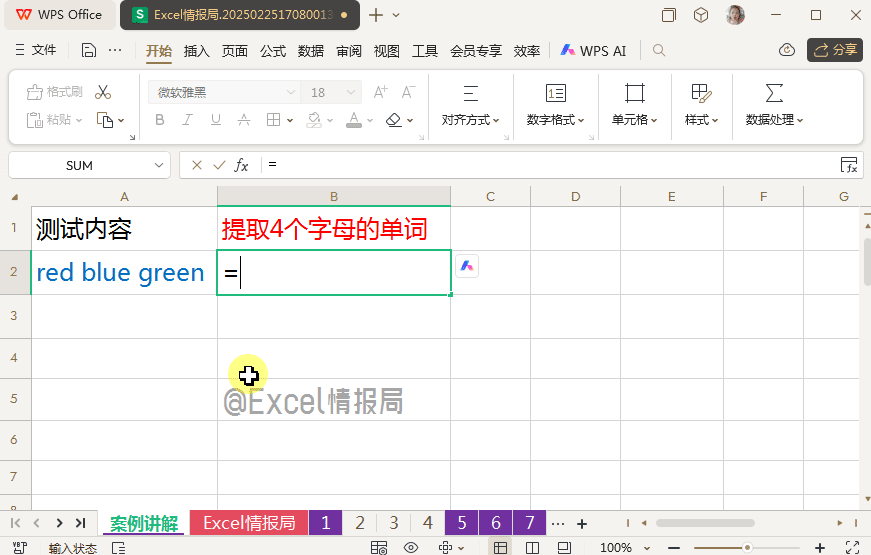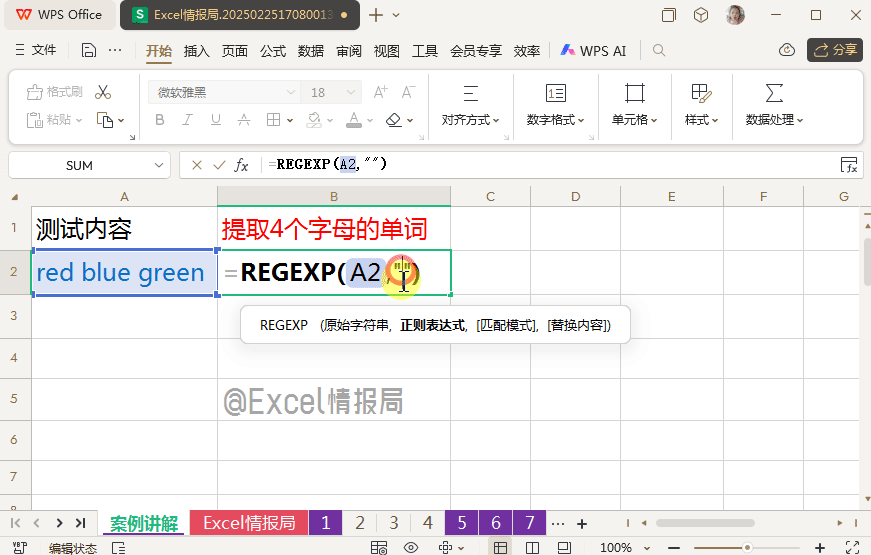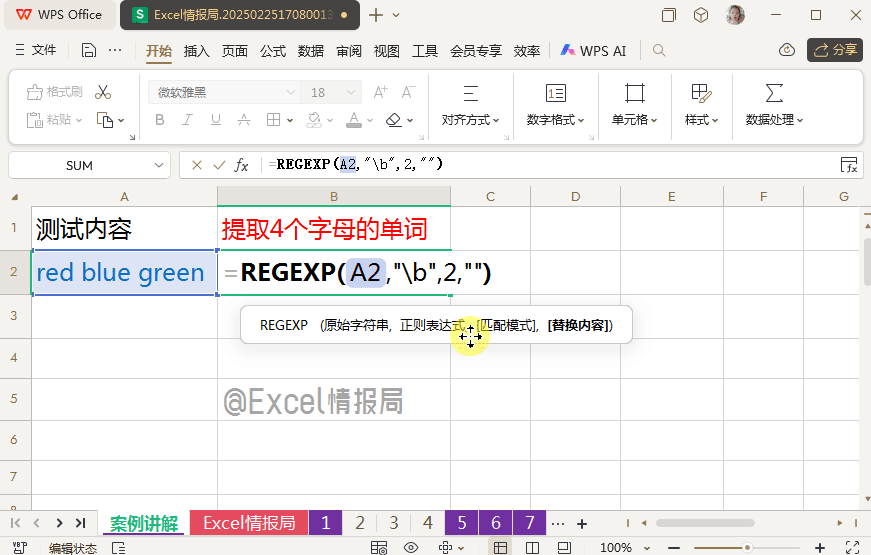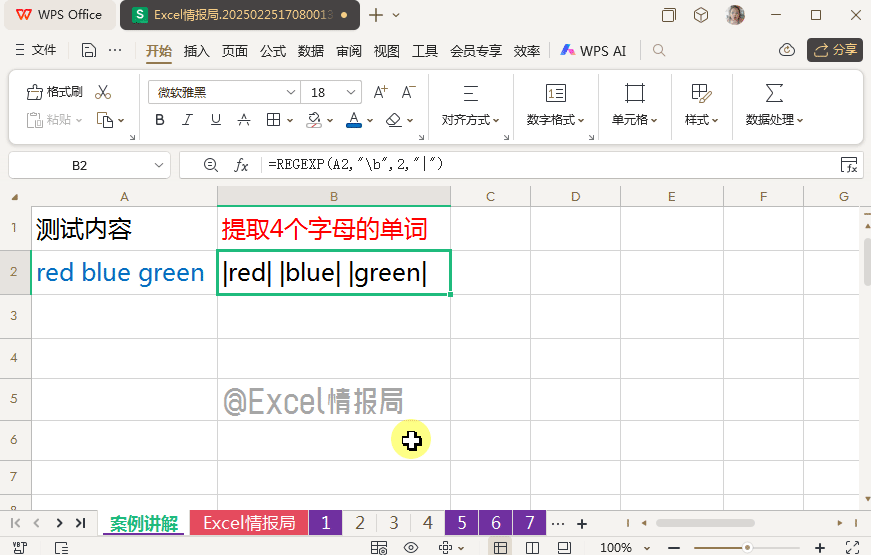
我们观察到了单词边界的位置,其实就是3个单词它们分别的首尾处。又一次印证了我们之前抽象的概念:匹配单词的首尾边界。\b是“单词保镖”,专管独立内容。

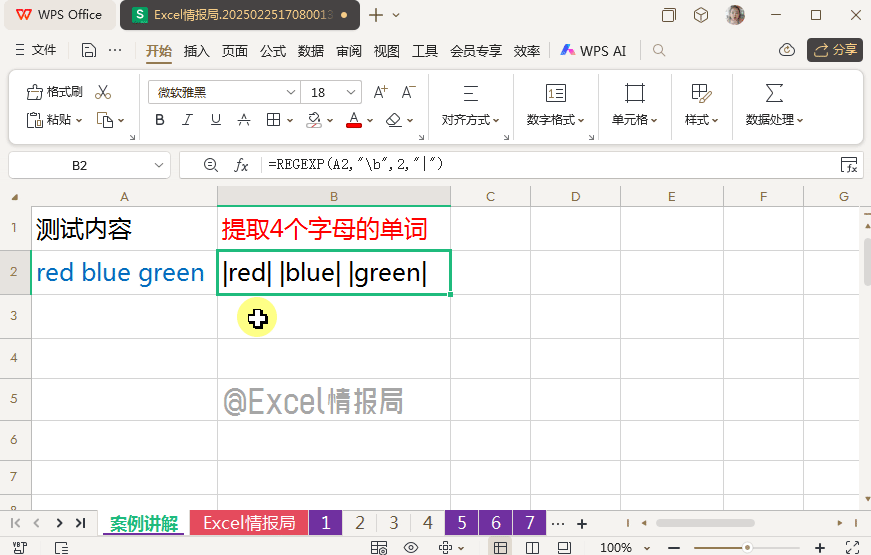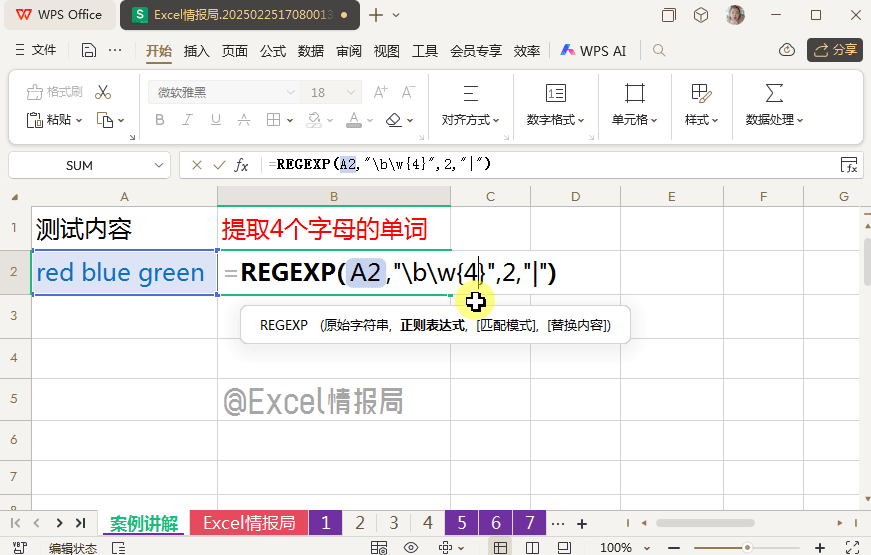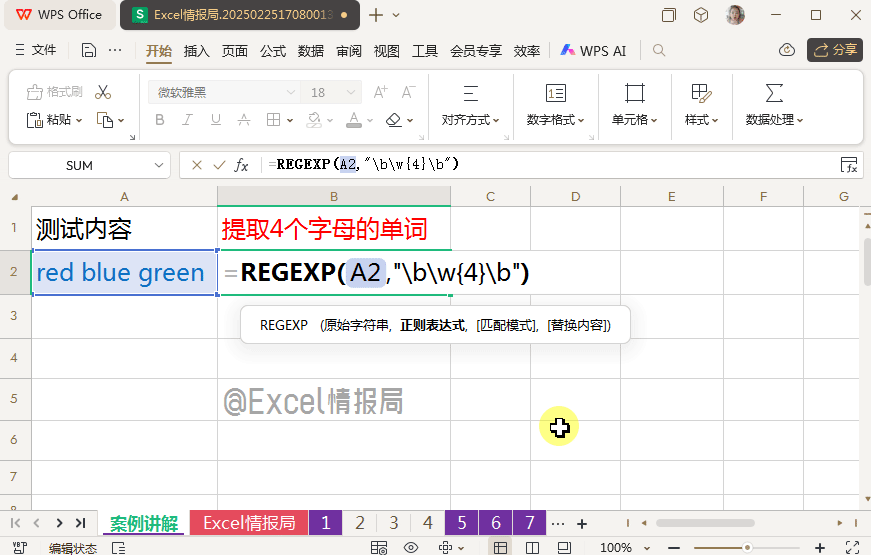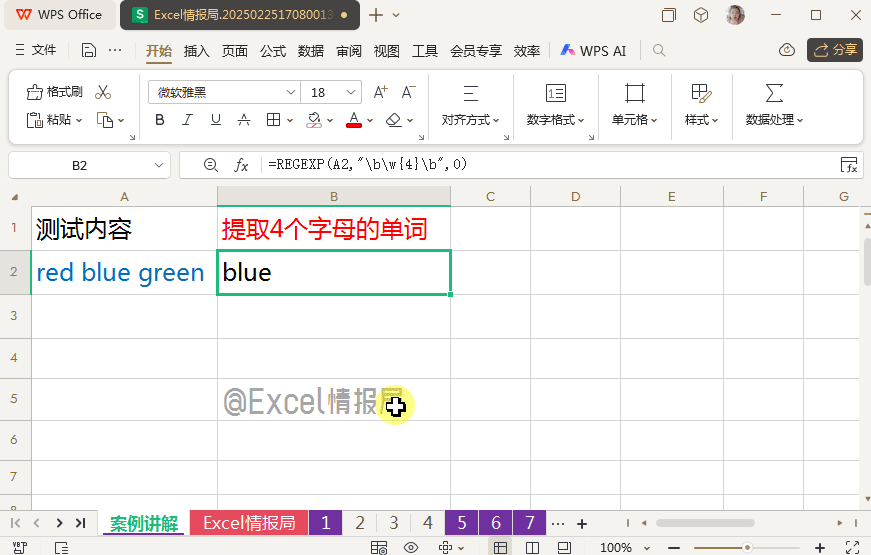
我们完善单词边界:
=REGEXP(A2,"\b\w{4}\b",0)
\w{4}:表示精确到4个字符长度的任意字母
在上面3组单词边界的首尾处,符合\b\w{4}\b,即首尾单词边界\b中间为“4个字母”的只有“blue”了。所以用提取模式,将“blue”提取出来就好了。
我们再来看\B(非单词边界)占用的位置。
输入公式:
=REGEXP(A2,"\B",2,"|")
利用"\B",定位非单词边界位置,然后用替换模式,将定位到的非单词边界位置,用分隔符"|"替换。这样做的好处仍然是化抽象为具象,更容易被肉眼观察具体位置。
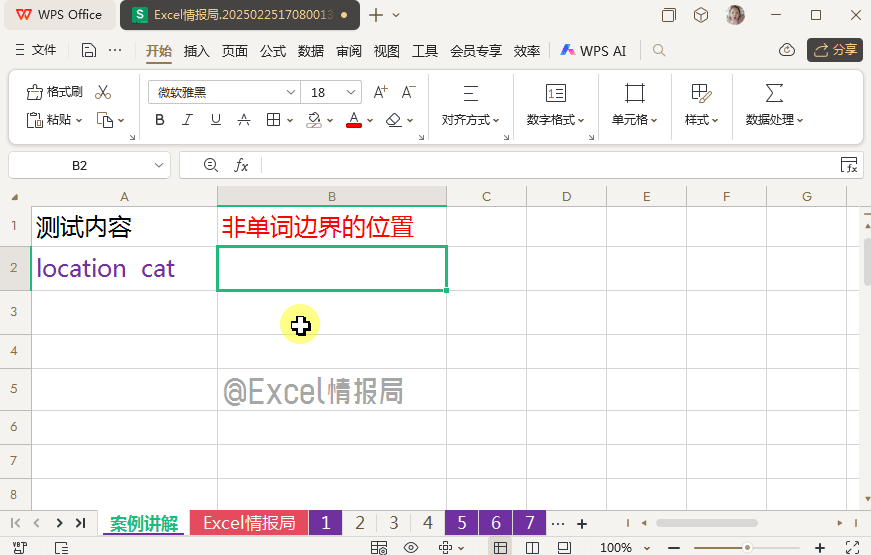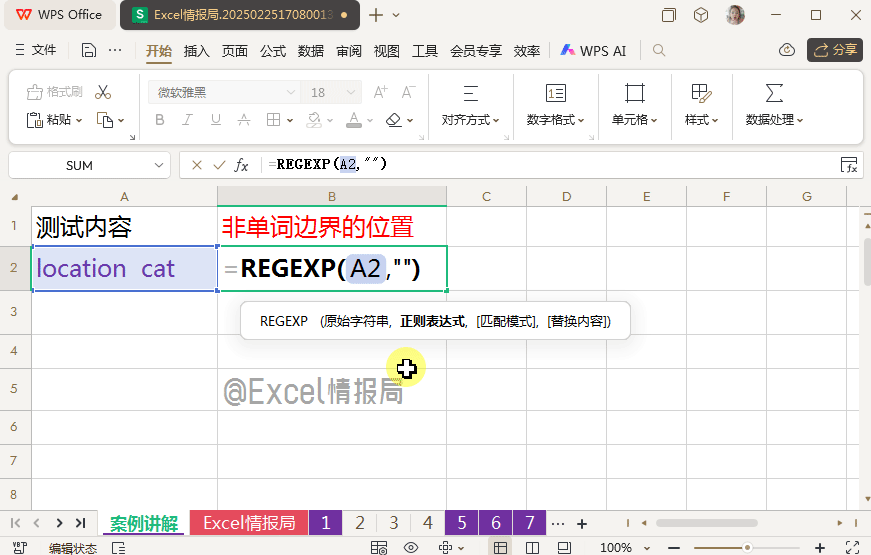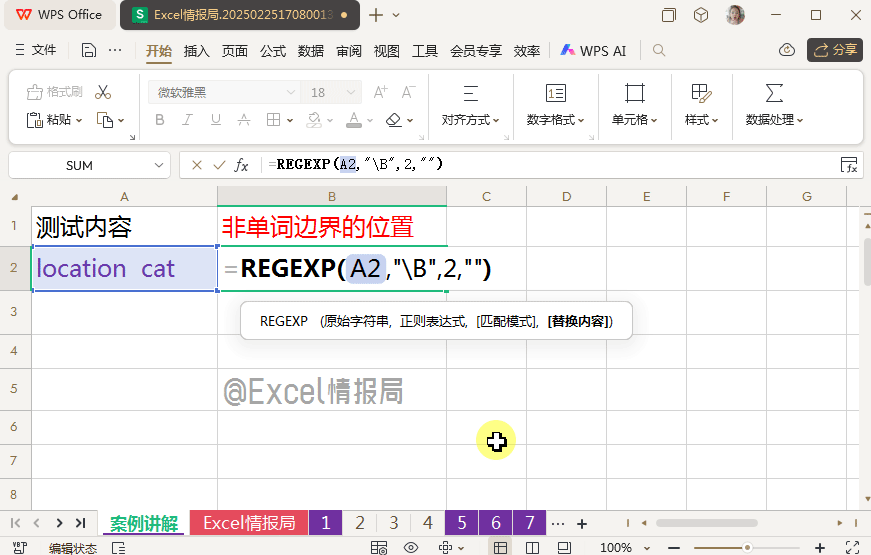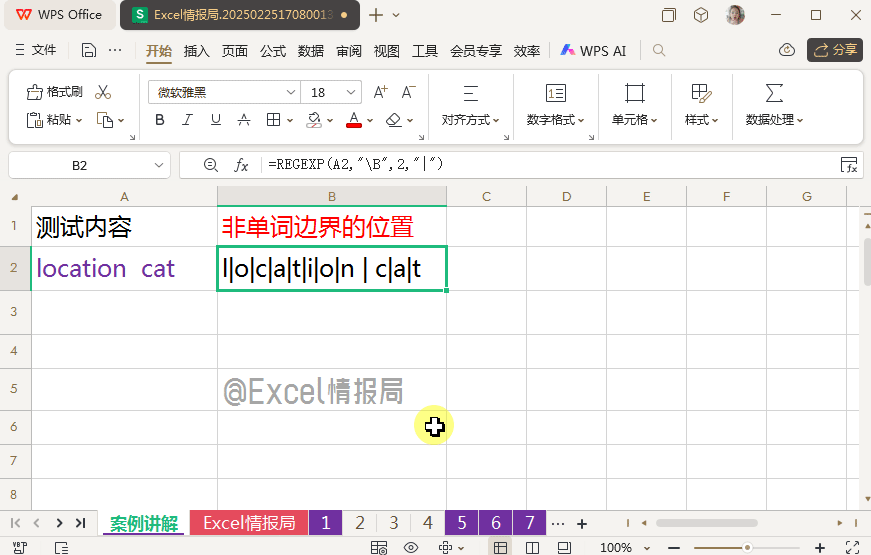
很明显,我们观察到:单词非边界位置,正好是单词边界位置的剩余位置,即排除了独立单词“location”与“cat”各首尾部分位置后,剩余的单词内部,字母之间,符号之间的位置。

应用理解1:
我们要将连续内容“location”中的“cat”替换为“猫”。而单独的单词“cat”不做处理。这时候就用到了非单词边界。
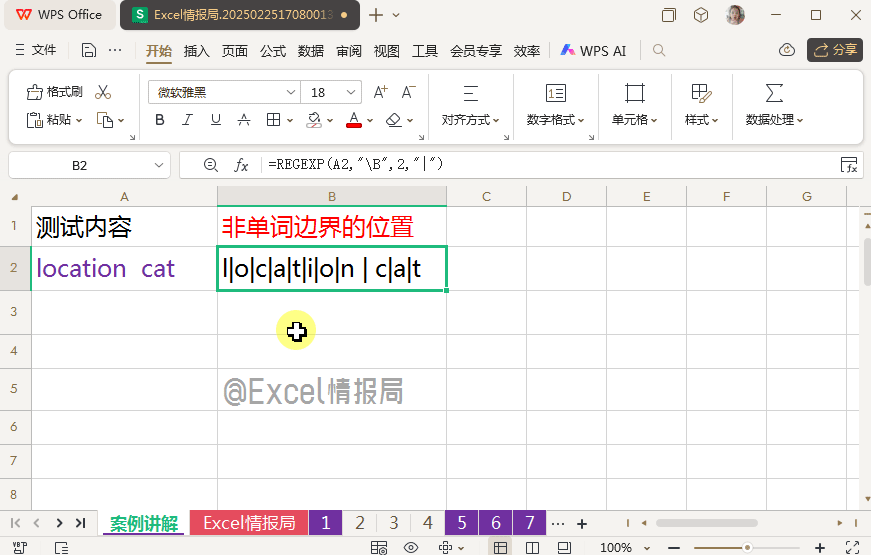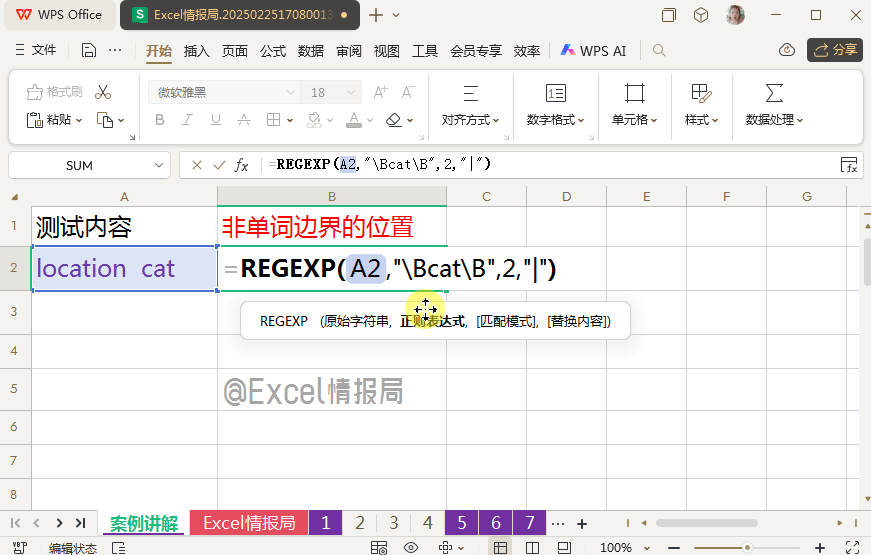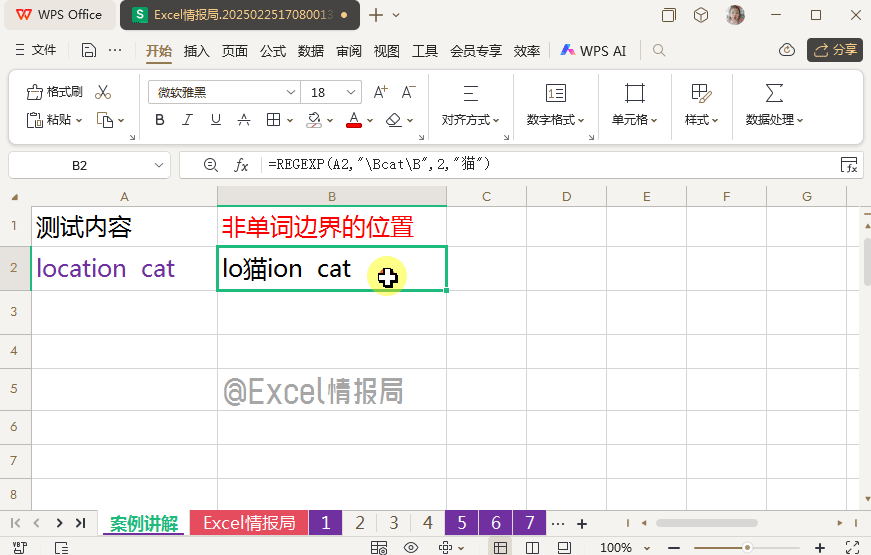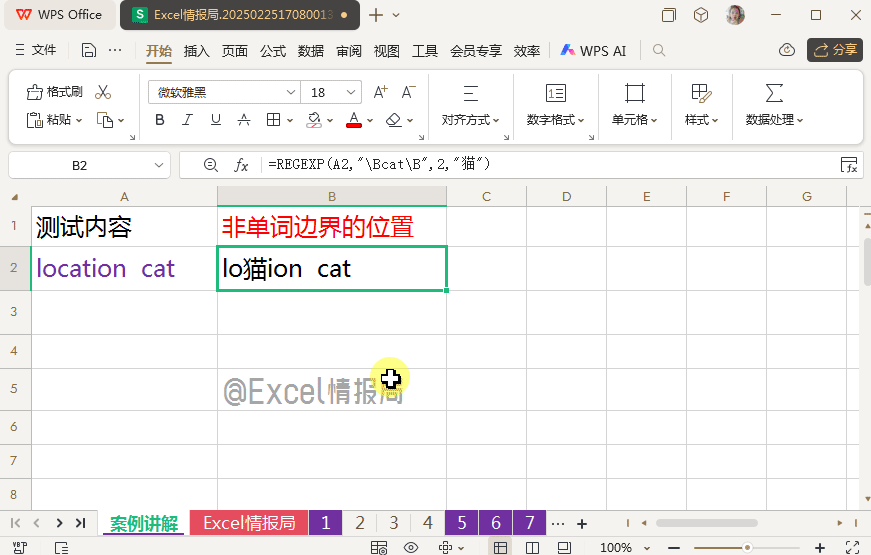
输入公式:
=REGEXP(A2,"\Bcat\B",2,"猫")
被非单词边界\B左右包围起来的“cat”,只存在于“location”这个连续字母之中。所以用替换模式,将“location”中包含的“cat”替换为“猫”,独立单词“cat”将不做处理。
应用理解2:
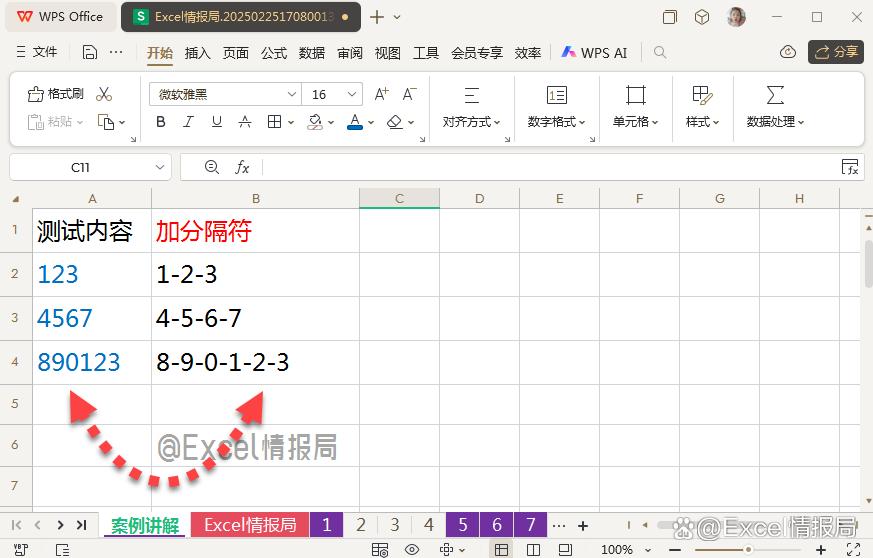
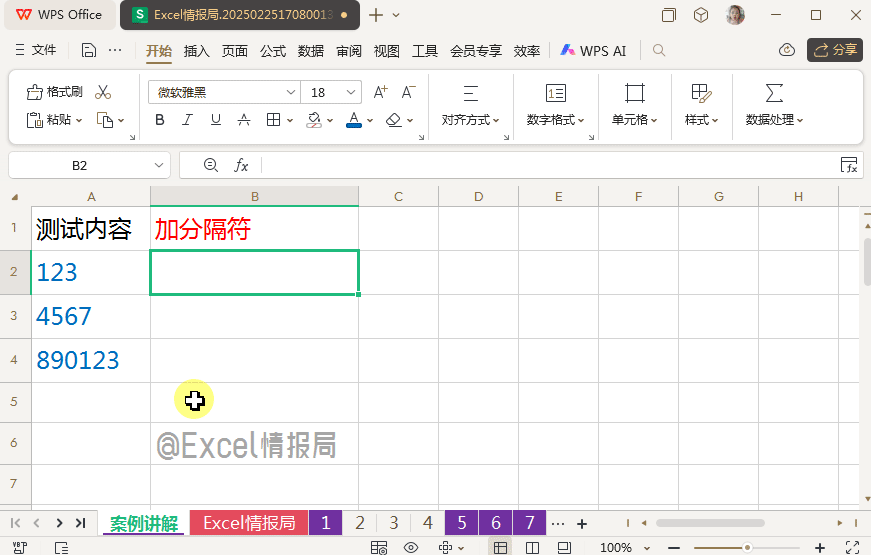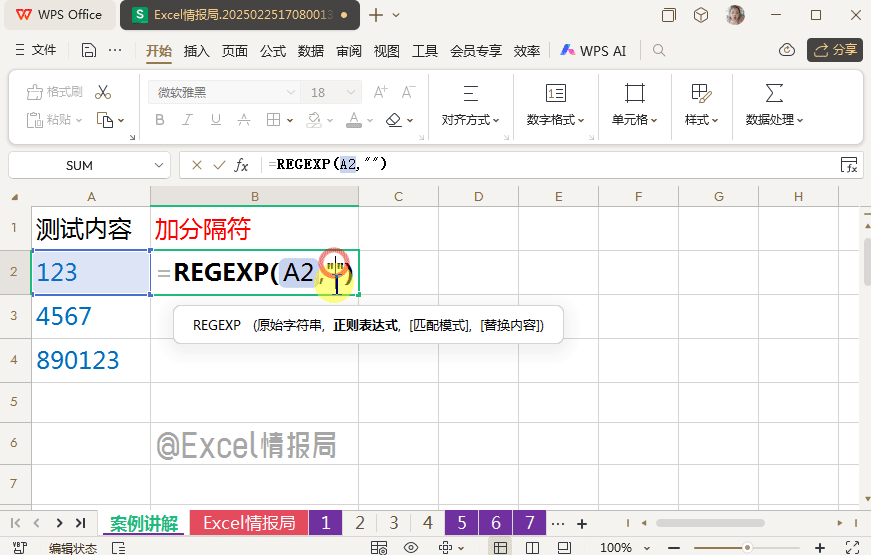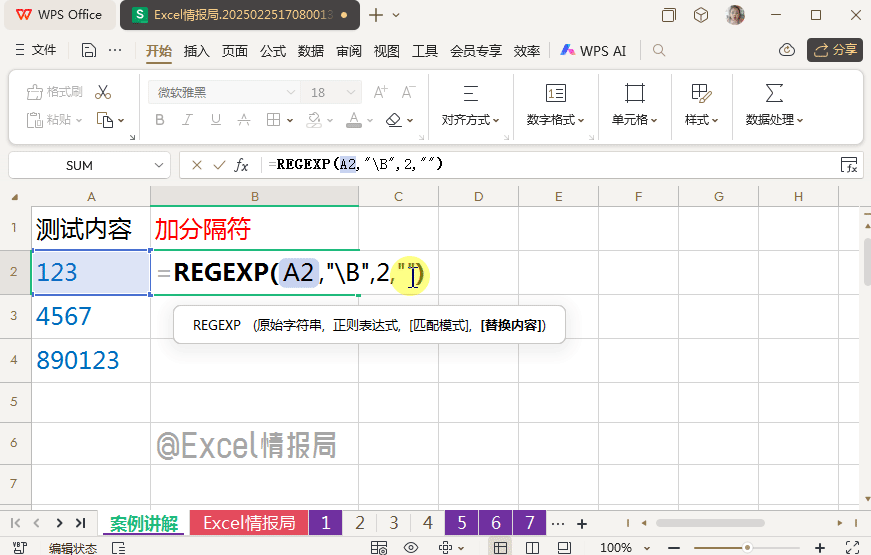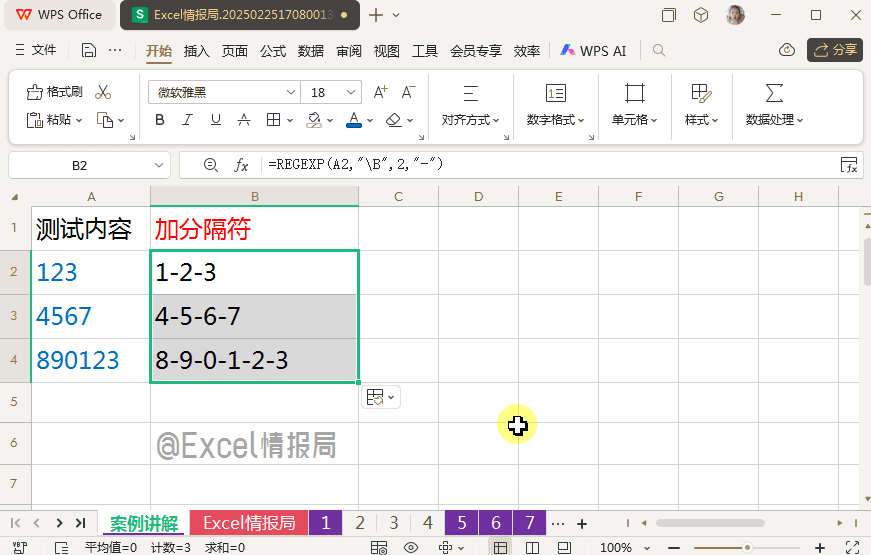
我们想要在数字之间批量加上符号“-”。
输入公式:
=REGEXP(A2,"\B",2,"-")
用非单词边界"\B",定位到数字字符串中的非单词边界位置,即除了首尾位置后,字符内部中间部分的位置,也就是内部数字与数字之间的位置,用替换模式,将这些位置替换为“-”即可。
应用理解3:
我们想要提取任意统一4位数字的中间2位数字。
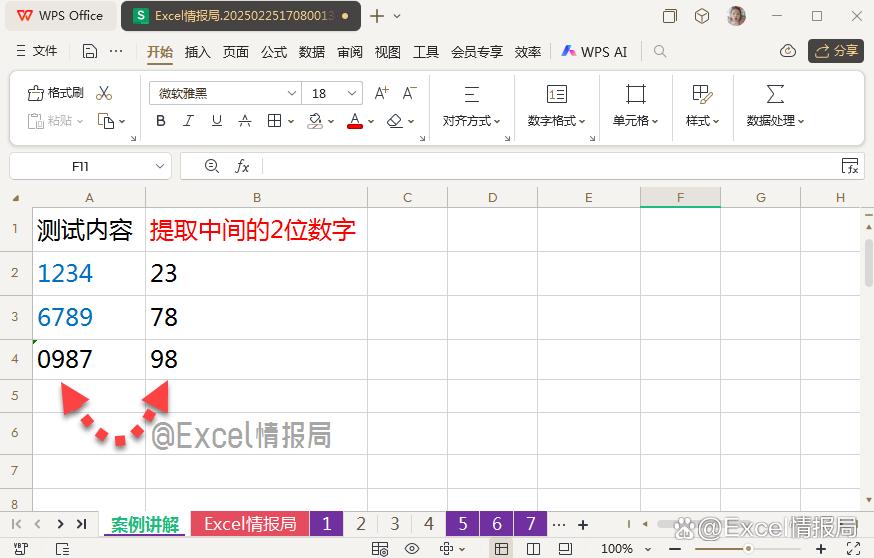
输入公式:
=REGEXP(A2,"\B",2,"|")
利用非单词边界\B,将定位到的非单词边界位置先暂时用"|"替换,化抽象为具象,更容易被肉眼观察非单词边界位置。
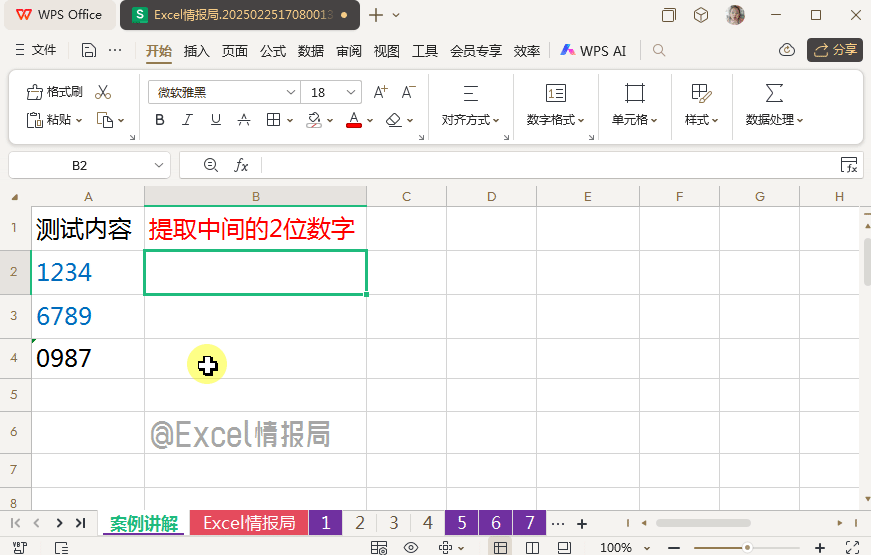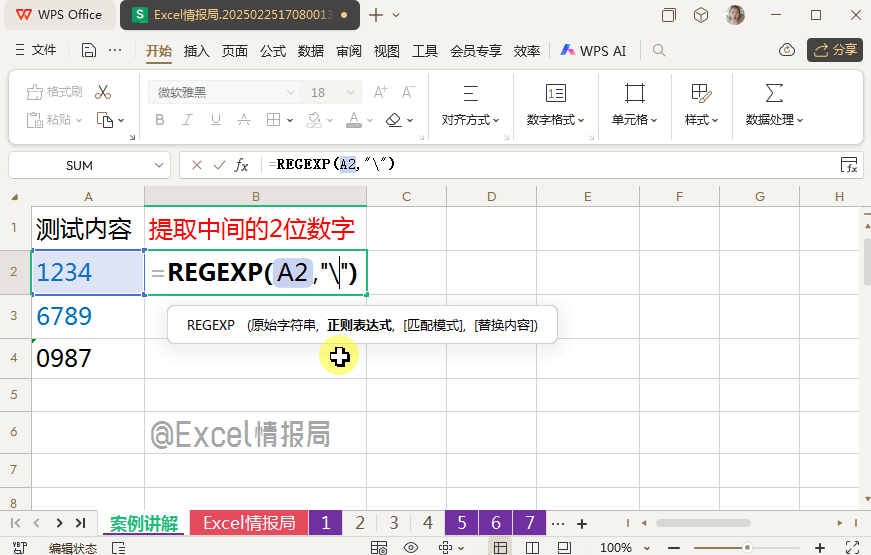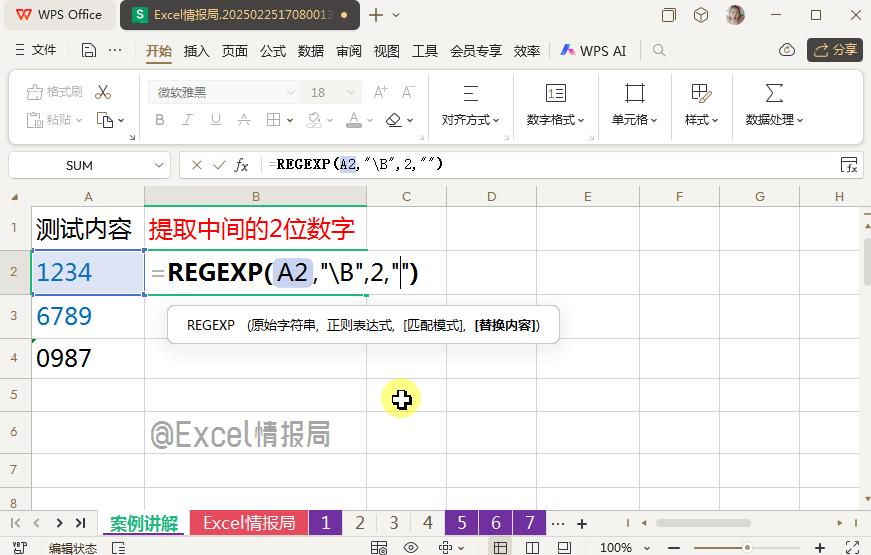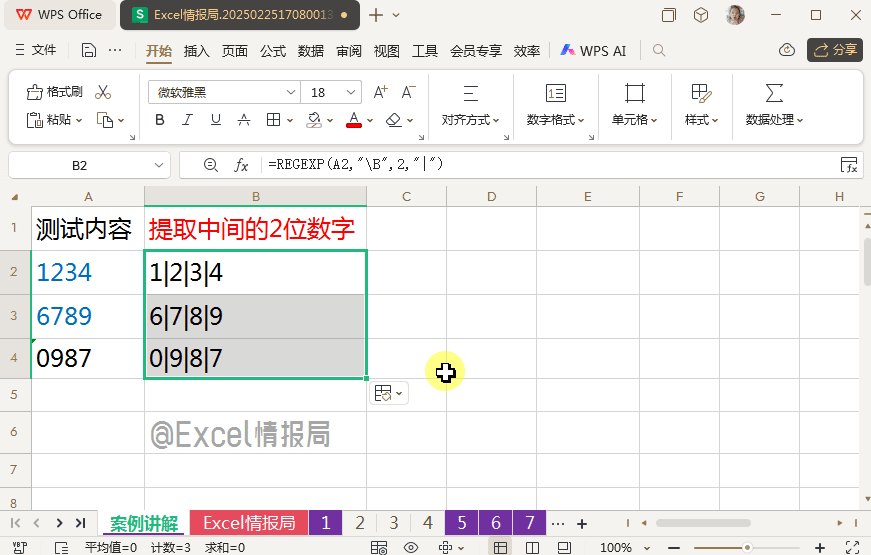
我们观察到非单词边界位置,位于数字字符串内部的数字之间的位置。

我们继续完善非单词边界:
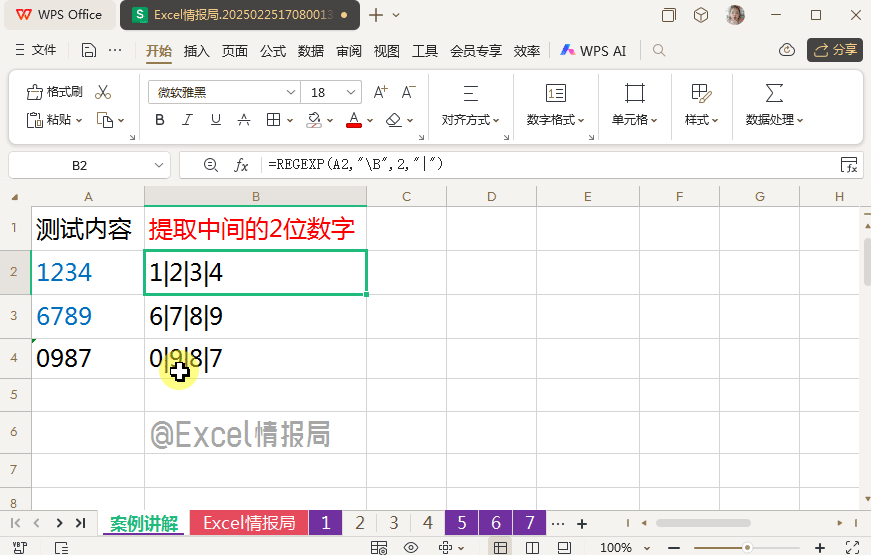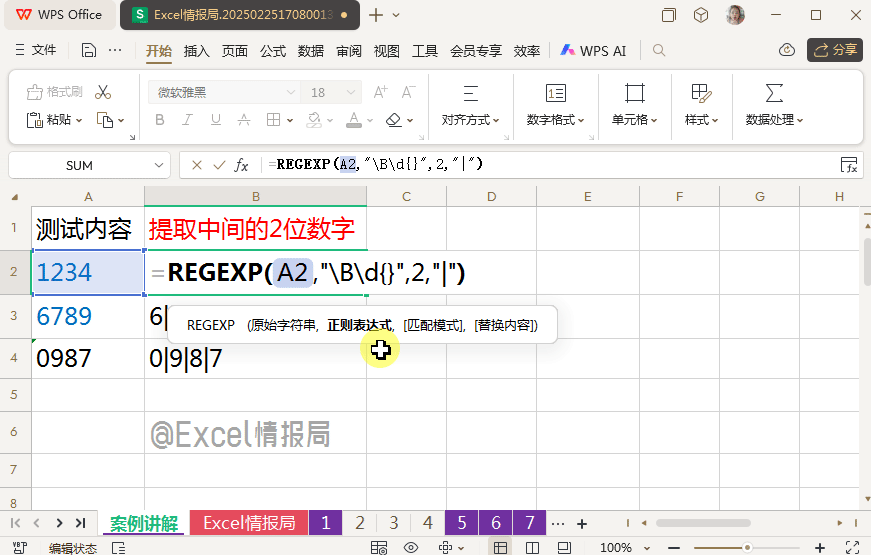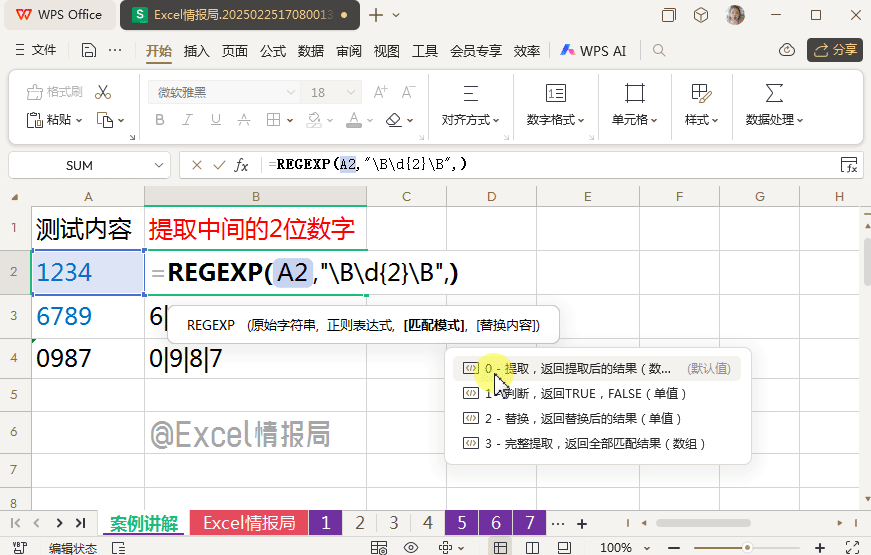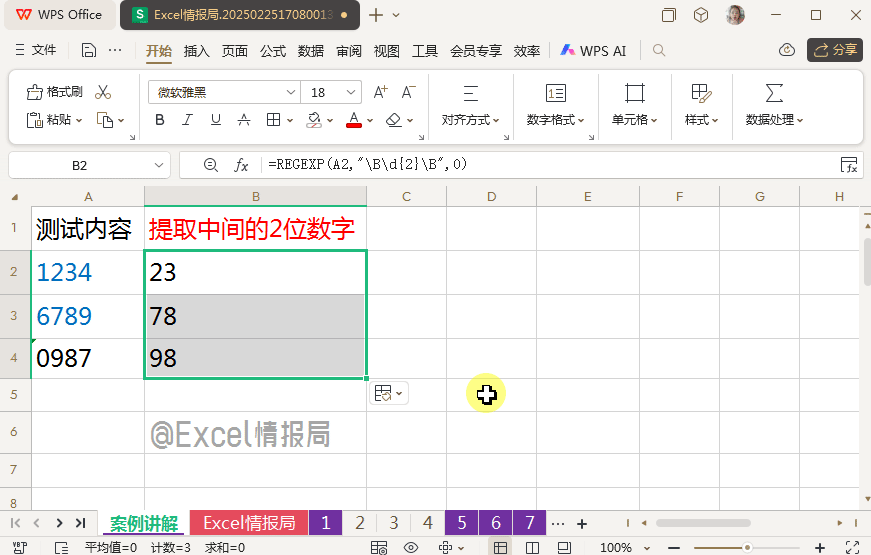
=REGEXP(A2,"\B\d{2}\B",0)
d{2}:为任意的2位数字。
符合左右被非单词边界\B包围的任意的2位数字,只有数字字符串中间的2位数字。用提取模式进行提取即可。