
使用python爬虫实现子域名探测问题
作者:微雨停了
子域名枚举是为一个或多个域查找子域的过程,它是信息收集阶段的重要组成部分,这篇文章主要介绍了使用python实现子域名探测,需要的朋友可以参考下
前言
意义:子域名枚举是为一个或多个域查找子域的过程,它是信息收集阶段的重要组成部分。
实现方法:使用爬虫与字典爆破。
一、爬虫
1.ip138
def search_2(domain):
res_list = []
headers = {
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36',
'Connection': 'keep-alive',
'Referer': 'http://www.baidu.com/'
}
results = requests.get('https://site.ip138.com/' + domain + '/domain.htm', headers=headers)
soup = BeautifulSoup(results.content, 'html.parser')
job_bt = soup.findAll('p')
try:
for i in job_bt:
link = i.a.get('href')
linkk = link[1:-1]
res_list.append(linkk)
print(linkk)
except:
pass
print(res_list[:-1])
if __name__ == '__main__':
search_2("jd.com")返回结果:

2.bing
def search_1(site):
Subdomain = []
headers = {
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36',
'Connection': 'keep-alive',
'Referer': 'http://www.baidu.com/'
}
for i in range(1, 16):
url = "https://cn.bing.com/search?q=site%3A" + site + "&go=Search&qs=ds&first=" + str(
(int(i) - 1) * 10) + "&FORM=PERE"
# conn = requests.session()
# conn.get('http://cn.bing.com', headers=headers)
# html = conn.get(url, stream=True, headers=headers)
html = requests.get(url, stream=True, headers=headers)
soup = BeautifulSoup(html.content, 'html.parser')
# print(soup)
job_bt = soup.findAll('h2')
for i in job_bt:
link = i.a.get('href')
print(link)
if link in Subdomain:
pass
else:
Subdomain.append(link)
print(Subdomain)
if __name__ == '__main__':
search_1("jd.com")
返回结果:

二、通过字典进行子域名爆破
def dict(url):
for dict in open('dic.txt'): # 这里用到子域名字典文件dic.txt
dict = dict.replace('\n', "")
zym_url = dict + "." + url
try:
ip = socket.gethostbyname(zym_url)
print(zym_url + "-->" + ip)
time.sleep(0.1)
except Exception as e:
# print(zym_url + "-->" + ip + "--error")
time.sleep(0.1)
if __name__ == '__main__':
dict("jd.com")返回结果:
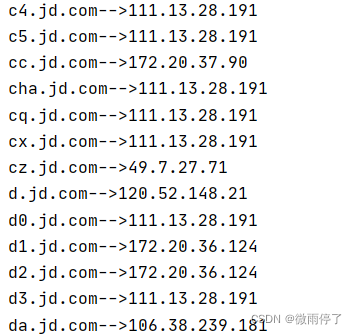
三、python爬虫操作步骤
1.写出请求头headers与目标网站url
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240"
}
url = "https://site.ip138.com/"2.生成请求
get:res = requests.get(url + domain, headers=headers) post:res = requests.post(url + domain, headers=headers, data=data)
3.抓取数据
soup = BeautifulSoup(res.content, 'html.parser') # 以html解析器解析res的内容
此时print(soup),返回结果:

4.分析源码,截取标签中内容
1.通过分析源码,确定需要提取p标签中的内容:
job_bt = soup.findAll('p')此时print(job_bt),返回结果:

2.继续提取a标签内属性为href的值:
try:
for i in job_bt:
link = i.a.get('href')
linkk = link[1:-1]
res_list.append(linkk)
print(linkk)
except:
pass得结果:
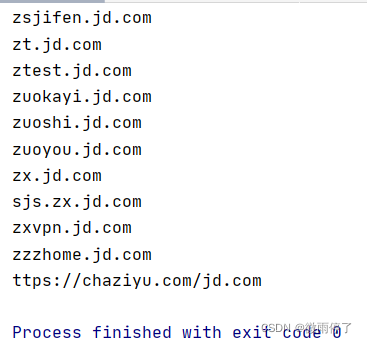
3.再进行截取:
res_list[:-1]
得结果:

四、爬虫一些总结
1.抓取数据,生成soup
soup = BeautifulSoup(res.content, 'html.parser') # 以html解析器解析res的内容
2.从文档中获取所有文字内容
print(soup.get_text())
3.从文档中找到所有< a >标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
到此这篇关于使用python实现子域名探测的文章就介绍到这了,更多相关python子域名内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:
- Python7个爬虫小案例详解(附源码)中篇
- Python7个爬虫小案例详解(附源码)上篇
- Python爬虫程序中使用生产者与消费者模式时进程过早退出的问题
- Python爬虫库urllib的使用教程详解
- Python利用yield form实现异步协程爬虫
- python爬虫之requests库使用代理方式
- python 基于aiohttp的异步爬虫实战详解
- Python爬虫框架NewSpaper使用详解
- 通过python爬虫mechanize库爬取本机ip地址的方法
- Python爬虫学习之requests的使用教程
- python爬虫beautiful soup的使用方式
- Python爬虫之超级鹰验证码应用
- Python爬虫Requests库的使用详情
- python爬虫模拟登录之图片验证码实现详解
- Python爬虫eval实现看漫画漫画柜mhgui实战分析
- python爬虫实战项目之爬取pixiv图片
- python爬虫之代理ip正确使用方法实例
- Python7个爬虫小案例详解(附源码)下篇