

开源AI中文语音克隆工具MockingBird 2023 最新绿色免费版
- 大小:5.44GB
- 分类:音频处理
- 环境:Windows
- 更新:2023-07-05
热门排行












简介
开源免费的AI语音克隆工具,只需要5秒钟就可以轻松克隆出你的声音,MockingBird软件很神奇,可以根据任意文字克隆出你的声音,听起来就像是你在说这段文字一样,很多用户觉得安装麻烦,特意分享MockingBird绿色整合版,欢迎免费下载。

软件特色
一个实时克隆中文声音的AI工具,只需5秒,就能用AI 技术来模拟声音来生成任意语音内容。程序依赖Python、Pytorch、FFmpeg等库,如下快速开始文档有详细介绍。可以下载预训练好的合成模型(synthesizer),也可训练自己的合成模型。从体验和视频demo上看,确实能复制目标用户的音色,不过生成的效果也不是特别理想,可能需要针对性的训练效果会更好些。
操作步骤
1.record,录入声音
2.自动加载模型
3.写一段文本
4.等待生成
5.播放、导出录音文件
绿色版说明
绿色整合版,无需手动安装python,开箱即用,打开运行.bat即可
五秒克隆你的声音
已整合训练好的模型,不需要特别高的配置和IT水平
环境要求
它支持中文。它可以支持普通话,并使用多种中文语音数据集进行训练,如 aidatatang_200zh、magicdata、aishell3 等。
基于 PyTorch。它适用于 PyTorch 深度学习框架,并在 PyTorch 1.9.0 版本(2021 年 8 月最新版本)进行了测试。它可以运行在带有 GPU(如 Tesla T4 和 GTX 2060)的系统上。

python3.7及以上
理论支持Windows 7及以上 (建议 win8+,过老版本不保证兼容性)
亲测win2012,win10完美运行
如果在用 pip 方式安装的时候出现 ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2) 这个错误可能是 python 版本过低,3.9 可以安装成功。
最让人觉得神奇的是,这AI生成的语音听上去就像真人录制的,简直无法分别!在线试听一下,绝对会让你眼前一亮,赶忙想用一用。
没有任何编程基础的用户也可以直接上手,界面简单明了,支持中文语音,能运行在各大平台,还可以直接部署成 Web 服务,实在是开发者和语音爱好者的良心之作!
因为官网写的教程太详细,我就不嫌丑了,图片是来自官网的,软件和教程全部给你们打包好了文末自取!
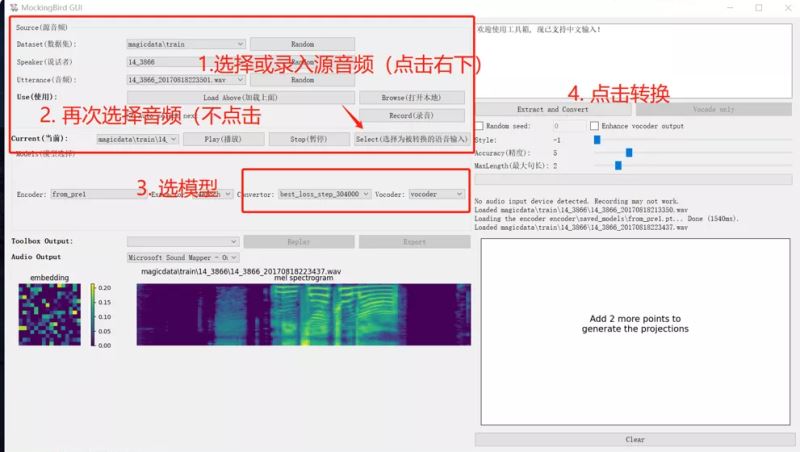
0 为什么不需要安装环境即可使用?
这次我用了便携版的python,把需要的环境、依赖、模型都打包进去了,不需要手动安装任何东西。
1 如何使用
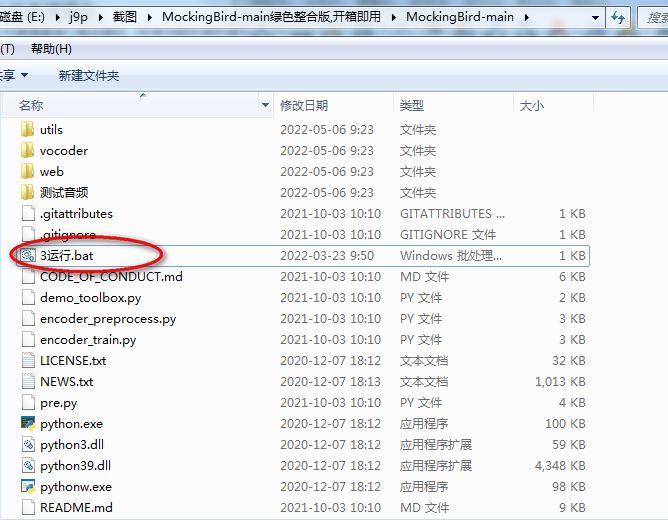
下载压缩包后找一个还有至少5G空间的盘,解压压缩包,注意不能有中文路径!进入后双击运行工具箱/运行工具箱-vc模式/运行web程序 即可游玩项目
在【Utterance(音频)】位置选择我内置的某一条音频,点击【Load Above(加载上面)】选中一条音频,此时你能在左边的【Current(当前)】位置看到这条音频。或者你也可以点击【打开本地】打开一条你自己要模仿的音频,再或者点击录音,录制你自己的声音作为输入。
接下来点击【Synthesizer】选择声学模型,pretrained-11-7-21_75k是作者提供的模型,下面的qh开头的是用海子姐的语音微调过的模型,rty开头的是用然天一大佬的合作音娘三七的语音微调过的模型。微调后的模型更适合模仿对应角色的语音。如果你上面选择的是qh或者rty开头的输入音频,你可以在下面选择对应的模型来获取更好的合成效果。如果你选择的是别的语音,选择作者提供的模型可能效果会更好。
关于【Vocoder】即声码器的选择可以先使用g_hifigan来快速合成音频听效果,如果效果还可以则可以选择pretrained获取更慢但更好的效果。
合成音频分为两步,一是声学模型合成梅尔图,你可以点击【Synthesize only】来进行合成,如果你合成的梅尔图效果比较清晰,则可以继续下一步,如果不清晰则可以尝试多合成几次。
第二步是合成音频,你可以点击【Vocode only】来进行合成,当你想更换声码器时你可以在更换后点击【Vocode only】避免重复合成梅尔图。【Synthesize and Vocode】则是同时进行这两步。
合成完毕后左下角【Toolbox Output】位置会出现新的音频,你合成过的音频都会放在这里,你可以选择【Replay】重听,或点击【Export】导出。
下面的【Audio Output】可以选择播放的音频设备
右侧的其它选项:【Random seed】:可能是固定每次合成中的随机种子。【Enhance vocoder output】:自动裁剪输入音频中的非语音部分以获得更好的模仿效果。【Style/Accuracy】:不知道(可以问问作者)【最大句长】:拉满,不然合成长句的时候可能会有截断的现象。
其他:
更换声学模型或声码器等情况下点击合成,可能会有窗口布局改变且合成失败的情况,再次点击合成即可。
当出现颤音的时候重新运行声码器基本都能解决
软件亮点
1、中文 支持普通话并使用多种中文数据集进行测试:aidatatang_200zh, magicdata, aishell3, biaobei, MozillaCommonVoice, data_aishell 等
2、PyTorch 适用于 pytorch,已在 1.9.0 版本(最新于 2021 年 8 月)中测试,GPU Tesla T4 和 GTX 2060
3、 Windows + Linux 可在 Windows 操作系统和 linux 操作系统中运行(苹果系统M1版也有社区成功运行案例)
4、Easy & Awesome 仅需下载或新训练合成器(synthesizer)就有良好效果,复用预训练的编码器/声码器,或实时的HiFi-GAN作为vocoder
5、Webserver Ready 可伺服你的训练结果,供远程调用。
安装教程
请勾选add python to path,否则需要手动配置环境变量
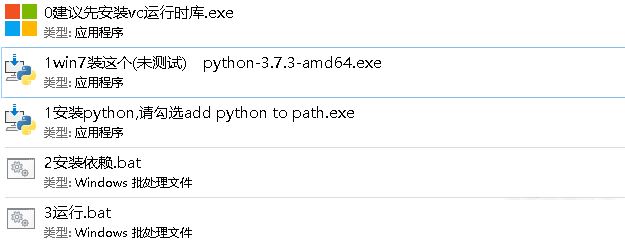
请保持网络畅通,若断网报错请重新执行安装依赖.bat
使用教程
1.browse选择一段3-15秒的语音,wav格式,最好单声道,吐字清晰,没有杂音,不宜过长
亲测网课直播录屏,发语音,在安静条件录音等音质较好,而在公共环境比如舞台,KTV等录音音质较差
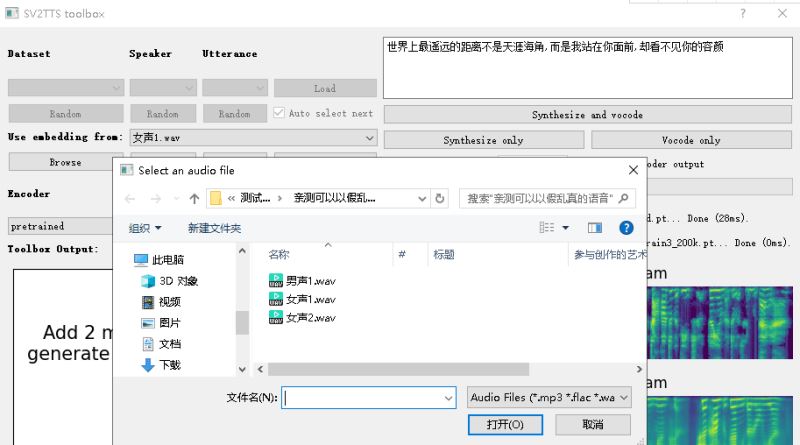
不是所有语音都能够完美克隆,亲测在网课放老师的声音以假乱真,但像麦小兜派蒙雷米等萝莉音效果不理想
可以使用音频编辑工具例如au进行预处理降噪
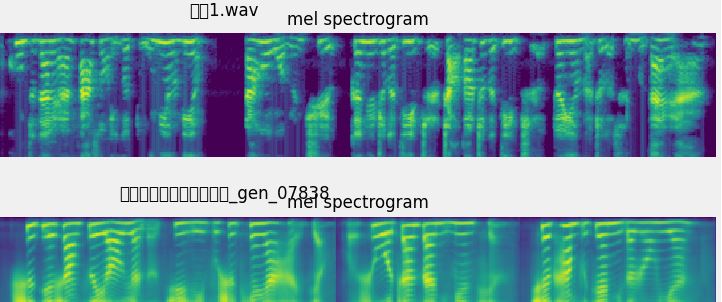
如图所示,频谱规则的音频克隆效果较好
2.在右上角输入文本,仅支持中文,不要有阿拉伯数字,英文请使用谐音自行解决哈
3.选择vocoder,推荐Griffin-Lim,点击Synthesize and vocode试听,之后点击export导出音频
 chrome下载
chrome下载 知乎下载
知乎下载 Kimi下载
Kimi下载 微信下载
微信下载 天猫下载
天猫下载 百度地图下载
百度地图下载 携程下载
携程下载 QQ音乐下载
QQ音乐下载