可是通过一系列底层测试,我们注意到了两个不同之处:整数乘法和浮点加法。Cyclone 的整数乘法单元只有一个,需要四个周期去执行,但 Enhanced Cyclone 只需要三个。但更让人惊讶的是,后者的整数乘法效能翻了一倍多。尽管这个事实不足以揭开其整个的真面目,但这些数据指出 Enhanced Cyclone 的整数乘法单元翻倍了,也就是说现在它有两个。
与此同时浮点加法这块也有了提升,但不如整数乘法的变化大。Enhanced Cyclone 可能仍是三个浮点 ALU 单元,但与整数乘法这边一样,指令延迟降低了。苹果同样减少了浮点加法的执行周期,从五个下降到了四个。这些变化证明 Enhanced Cyclone 和它的前辈其实并不相同,特别是在整数乘法单元这部分。这种变化令两者十分相似,但在微妙的地方却又是不同的两个架构。
如果不提底层结构,Enhanced Cyclone 的其他方面似乎是原封不动。L1 cache 仍旧保持每个核心 64KB I$ + 64KB D$,这个参数之前在 Cyclone 架构上对比 Swift 是翻倍了的。L2 cache 方面,每个 CPU 核心应该拥有独立的 L2 cache。尽管Enhanced Cyclone在 L2 cache 带宽方面比 Cyclone 要好一点,但这还不足以成为独立 L2 cache 存在的确凿证据。当然了, L3 cache 仍是 4MB,就和上文提到的那样,访问延迟有微小进步。
让我们再一次借用英特尔的概念,Enhanced Cyclone 和 Cyclone 之间的区别就好像英特尔 Tick-Tock 策略的后一步,也就是升级工艺,架构仅是略微增强。这一点很容易看出来:A8 工艺提升到 20nm,同时架构上的改动使得其性能在某些情况下得到加强。另外这颗芯片的主频也提高了 100MHz。总体来说没有兴奋点。如果苹果也想借鉴 Tick-Tock 这个策略,那么这就是具体表现。
在结束了底层测试之后,接下来要通过一些表层测试来对两个架构进行对比。底层测试可以告诉我们单个操作上的进步,而表层测试则可以揭示在实际工作环境下的性能变化。
第一次表层测试首先使用的是 SPECint2000,它由标准性能评估公司开发,是其 SPEC CPU2000 测试平台的整数部分。SPEC CPU2000 开发于本世纪初,对于 PC 处理器来说它早已被淘汰,但对移动处理器却正好合适。因此,SPEC CPU2000 评估 Cyclone 和 Enhanced Cyclone 再好不过了。
SPECint2000 包括 12 个基准测试子项,用于计算出最终的最高分数,尽管在这次测试里单独的每一次结果更吸引人。
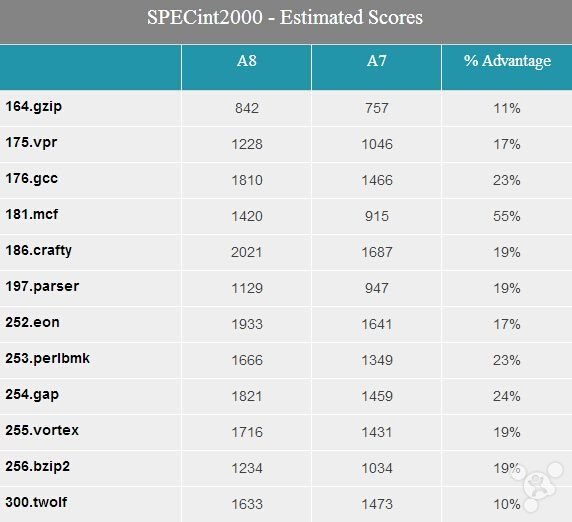
如图所示,需要记住的是 A8 的主频要比 A7 高 7.7%,但 SPECint2000 的测试结果却显示 12 个子项的提升均大于这个比例,证明它们在某些方面都得到了额外的加强。在这些子项里 MCF、GCC、PerlBmk 和 GAP 提升最大,幅度从 20% 至 55% 不等。大略来说,这应该是多个小提升相乘所得到的结果。
MCF 是所谓的综合优化基准,提升比例最高,达到 55%。鉴于这些全部都是整数方面的测试,MCF 很有可能受益于整数乘法单元的增强,因为其性能在乘法吞吐量上的提升接近两倍。这个事实暗示任何与整数乘法性能相关的工作都能得到类似的提升,尽管这样的任务我们在现实中用智能手机很少会用到。
除了 SPECint2000 外,另一个要使用的测试平台是 Geekbench 3。与前者不同,后者的测试包括和整数和浮点数两部分内容,因此我们可以双管齐下。
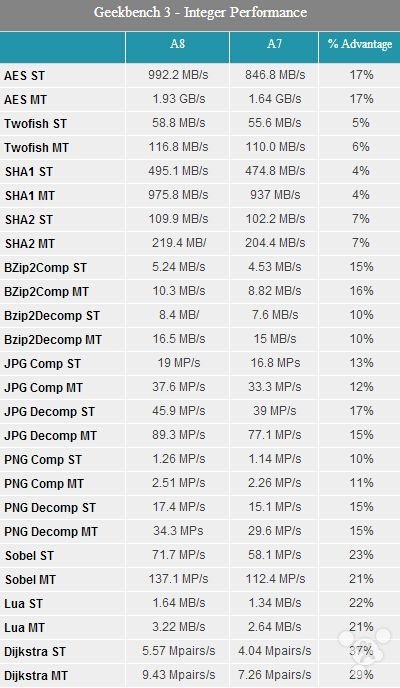
Geekbench 的整数部分测试结果总体来说没有 SPECint2000 那么“激进”,但也出现了一些特别高和特别低的分数。Crypto 在其中是得分最低的,而 Sbel 和 Dijkstra 则最高,分别有 21% 和 37%。有趣的是 Dijkstra,Cyclone 由于 64 位这个因素在 Geekbench 有些性能损失,而 Dijkstra 的提升将这个损失弥补了回来。
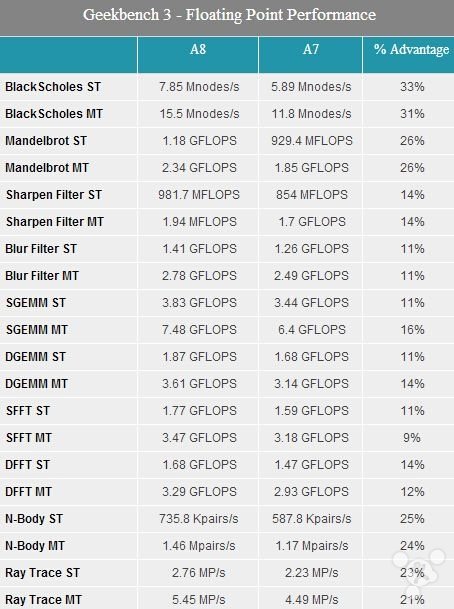
之前的底层浮点数测试指出 A8 在浮点数性能上的提升并没有整数性能的大,而表层浮点数测试却显示出不错的结果,说明底层测试并不能代表一切,尤其是像指令窗口这样比较抽象的方面。更重要的是,表层测试证明 Enhanced Cyclone 的性能提升并不仅止于整数运算,而是还包括浮点数这块。
总的来说,尽管在架构上变化不大,但多亏了主频提升、架构优化、内存延迟降低这几方面的加强,Enhanced Cyclone 也就是 A8 在性能上相比 A7 又进步了。明年苹果将面对来自 Cortex-A57 和其他高性能竞争对手的真正威胁,虽然现在来预测它们将如何争斗还为时过早,但至少我们可以说苹果也将会强势应对。更让人兴奋的是,所以的这些性能提升都是建立在苹果本已十分强大的单线程 IPC 的基础上的,这意味着即使是那些对多核心支持不好的任务苹果也能处理得得心应手。
GPU 性能提升详解

苹果在今年的新iPhone发布会中曾向我们介绍A8 SoC(System-on-a-Chip,系统级芯片)时,宣称A8 GPU性能最高提升近50%。对于如此重大的性能提升,芯片专家ChipWorks自然十分期待。根据掌握的信息和事实,苹果已将芯片的制造工艺转向更密集的20nm制程,同时鉴于A7整合的是四核心PowerVR G6430,而且考虑到新iPhone 对屏幕分辨率的要求更高,因此他们初步推测A8可能已经升级到顶级型号的六核心PowerVR GX6650,认为这样的设计似乎更为合理,而且对芯片内核的初步观察也隐约看到了六个簇。
尽管这样的设想看似合情合理,但苹果公司向来对产品的技术参数三缄其口,唯有对新品硬件自行挖掘才能一探究竟。然而,结果证明连ChipWorks这样的顶级专业团队这回也栽了。经过进一步细致研究发现,A8芯片上的GPU组其实只有四个,并非此前推测的六个,这也就排除了拥有6核心GX6650的说法。基于四核心的事实,说明苹果在A8上仍然只采用四核心PowerVR GX6450,那么这将意味着它只是A7 PowerVR G6430的简单升级版。GX6450拥有一定的性能优化和功能升级,如支持ASTC纹理压缩技术,这一点在苹果的文档中已有说明。

GX6450作为A7芯片G6430的直接升级版,它采用了基于Imagination公司推出的PowerVR Series6XT架构。该新型架构是Imagination公司在今年CES展会上首次对外展示的,然而仅在短短8个月之后,我们就已经看到搭载这一全新架构的苹果产品进入市场。
从技术角度上来分析,全新的Series6XT已经成为PowerVR图形处理器架构的新一代产品,它对于前一代Series 6图形处理单元是一个直接的进化,而GX6450同样也成为G6430最直接的继任者。苹果仍然在A8中采用四核心GPU,虽然在其20nm制程上,配置面积仅为19.1mm2的GX6450比22.1mm2的G6430更能节省不少空间,但GX6450相比G6430的硬件规格拥有更高的复杂性以及额外的ALU/SRAM。显然Series6XT重点在增加功能以及提高性能,那么它需要通过对架构进行各种调整和优化才能得以实现。相比之下,两年前问世的Series6架构在这一点已经过时。
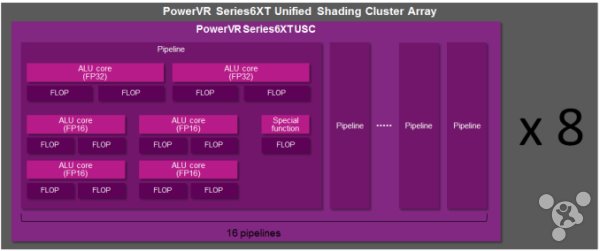
在 Series6XT 架构中最接近选取框功能能的就是自适应可扩展纹理压缩(ASTC)技术,这是新一代的纹理压缩技术,它目前正在逐渐被许多厂商采用支持。ASTC的设计是为了提供更好的纹理压缩,它比现有的纹理压缩格式可获得更细粒度的质量,同时还支持所有GPU采用的通用格式。苹果产品一直采用PowerVR图形处理单元,因而其所有产品都支持PVRTC以及更多采用了PVRTC2。但是采用ASTC技术可以令他们的产品的质量改善和提升获得更大的优势,同时也能够让游戏开发和平台移植变得更加容易。
对用户而言不太明显但于苹果来说十分重要的是,Series6XT还包含了新的电源管理功能,能够减少空闲和轻负载功耗。通过更细粒度的功率门控技术,Imagination升级了“PowerGearing G6XT”,GX6450依托于遮光集群(USCs)可以独自断电,它能允许部分重要的关键组件继续负荷工作。随着苹果继续调整产品的设计,这种技术可以帮助设备在闲置时保持较低的功率状态,这将可以提高电池寿命甚至或者增加A8 GPU在较高功率状态使用的效率以及延长使用寿命。
