
探析如何使用SystemTap观测TCP Backlog
作者:解月月的bug
什么是TCP Backlog
本文所使用的Linux内核版本信息
5.15.0-56-generic #62-Ubuntu SMP Tue Nov 22 19:54:14 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
backlog的中文含义是 积压 的意思,在Linux网络中,意味着网络数据包的积压,在Linux表现为半连接队列和全连接队列存储这些积压的数据包。backlog参数的大小,则会影响半连接队列和全连接队列缓存数据包的多少。
其中,半连接队列和全连接队列的含义如图所示(此处引用张师傅博客中的图)
- 半连接队列(Incomplete connection queue),又称 SYN 队列
- 全连接队列(Completed connection queue),又称 Accept 队列

从服务端角度看待TCP三次握手的过程,有以下几步:
- 调用 listen 函数时,TCP 的状态被从 CLOSE 状态变为 LISTEN,此时内核就创建了半连接队列和全连接队列。backlog参数就是在
listen的时候指定的。
int listen(int sockfd, int backlog);
- 在TCP进行三次握手的时候,收到SYN报文会先将数据包放到半连接队列,然后发出SYN+ACK
- 接着当收到对端的SYN+ACK的时候,再将这个连接请求的数据包移动到全连接队列,等待应用程序通过
accept()函数读取。
我们可以通过listen函数传入backlog参数值,且backlog参数值会影响到半连接队列和全连接队列的大小,但是我们该怎么观测到最终操作系统使用的backlog的大小呢?又怎么观测到半连接队列、全连接队列中的缓存的包数量呢?backlog参数和半连接队列、全连接队列的大小之间又有什么关系呢?
实验环境搭建
先在本地电脑上启动了两个虚拟机,Linux虚拟机1(命名为L1,ip: 10.211.55.6)和Linux虚拟机2(命名为L2,ip: 10.211.55.8),以 L1 作为服务器,L2作为客户端。
观测Linux最终采用的backlog大小
为确定backlog值通过listen函数设置进去之后,操作系统最终采用的数值,可以通过systemtap工具来确定。安装好systemtap工具之后,编写探测脚本如下:
probe kernel.function("tcp_v4_conn_request") {
tcphdr = __get_skb_tcphdr($skb);
dport = __tcp_skb_dport(tcphdr);
if (dport == 9090)
{
printf("reach here\n");
printf("socket struct: %s \n", $sk$);
syn_qlen = @cast($sk, "struct inet_connection_sock")->icsk_accept_queue->qlen;
max_backlog=$sk->sk_max_ack_backlog;
printf("qlen: %d, max_backlog: %d \n", syn_len, max_backlog);
}
}
这个脚本做的事情,就是对linux中 tcp_v4_conn_request 这个内核函数做了探针,只要调用到这个内核函数,且端口号为9090,就会执行一系列的打印操作。其中,会将socket对象打印出来,也会将socket对象中的 sk_max_ack_backlog 变量打印出来,这个变量正是linux最终采用的backlog值。
将这个脚本放到机器L1中的任一用户目录下,脚本命名为 tcp_backlog.stp,然后用命令执行:
sudo stap -v tcp_backlog.stp
如果运行成功,则会看到在终端上显示正在运行的提示:

此时,为避免编程语言的干扰,用C语言准备一段服务器的启动代码,backlog值可以通过修改常量来更改,这里使用backlog值为20
// main.c
#include <sys/socket.h>
#include <stdio.h>
#include <netinet/in.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <sys/shm.h>
#define MYPORT 9090
#define BACKLOG 20
#define BUFFER_SIZE 1024
int main()
{
///定义sockfd
int server_sockfd = socket(AF_INET,SOCK_STREAM, 0);
///定义sockaddr_in
struct sockaddr_in server_sockaddr;
server_sockaddr.sin_family = AF_INET;
server_sockaddr.sin_port = htons(MYPORT);
server_sockaddr.sin_addr.s_addr = htonl(INADDR_ANY);
///bind,成功返回0,出错返回-1
if(bind(server_sockfd,(struct sockaddr *)&server_sockaddr,sizeof(server_sockaddr))==-1)
{
perror("bind");
exit(1);
}
///listen,成功返回0,出错返回-1
if(listen(server_sockfd, BACKLOG) == -1)
{
perror("listen");
exit(1);
}
///客户端套接字
char buffer[BUFFER_SIZE];
char message[100] = "已成功接收!";
struct sockaddr_in client_addr;
socklen_t length = sizeof(client_addr);
///成功返回非负描述字,出错返回-1
int conn = accept(server_sockfd, (struct sockaddr*)&client_addr, &length);
if(conn<0)
{
perror("connect");
exit(1);
}
while(1)
{
memset(buffer,0,sizeof(buffer));
int size = read(conn, buffer, 1024);
if(strcmp(buffer,"exit\n")==0)
break;
strncat(buffer, message, 100);
fputs(buffer, stdout);
write(conn,buffer,strlen(buffer)+1);
}
close(conn);
close(server_sockfd);
return 0;
}
在L1上通过命令编译sk.c 并启动:
gcc main.c -o sk.o && ./sk.o
启动后,在L2上通过nc命令连接L1的9090端口:
nc 10.211.55.6 9090
接着观察 tcp_backlog.stp 探针脚本的输出:
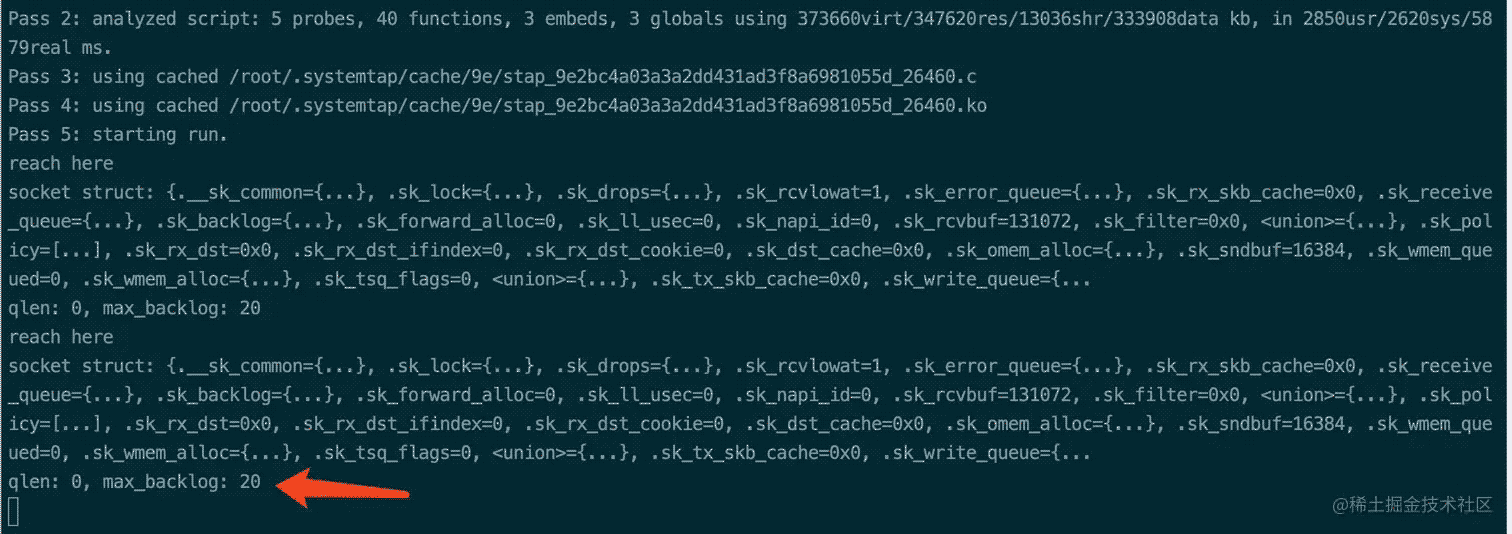
可见此时使用的backlog值为20,通过这个方法,我们可以观测到linux最终采用的 backlog值的大小是多少了。
<>系统变量对backlog大小的影响
backlog虽然可以通过listen设置进去,但是按照张师傅的博客所说,最终的大小会受到操作系统的配置影响。可通过sysctl命令查看这两个系统变量:
sysctl net.ipv4.tcp_max_syn_backlog # net.ipv4.tcp_max_syn_backlog = 128 sysctl net.core.somaxconn # net.core.somaxconn = 4096
按照上述观测的方法,函数传入的backlog值分别在 小于128,大于128但小于4096,大于4096这三个区间取一个值。设置backlog大小为 20、200、6000,分别观测操作系统最终采用的backlog值如下:
listen backlog值为200时,操作系统采用的backlog值为200

listen backlog值为6000时,操作系统采用的backlog值为4096,和系统变量 net.core.somaxconn 保持一样。

将上述测试数据总结如下:
| listen backlog值 | 操作系统实际采用的backlog值 | |
|---|---|---|
| 20 | 20 | |
| 200 | 200 | |
| 6000 | 4096 |
在张师傅的博客中提到, Linux内核版本在3.10.0的时候,会受到 net.ipv4.tcp_max_syn_backlog 和 net.core.somaxconn 的影响,且受这两个变量影响的逻辑还比较复杂。但是在 5.15.0版本中,已经做了简化,代码如下:
// net/socket.c
int __sys_listen(int fd, int backlog)
{
struct socket *sock;
int err, fput_needed;
int somaxconn;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
# sysctl_somaxconn对应系统变量net.core.somaxconn的值
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
err = security_socket_listen(sock, backlog);
if (!err)
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}
再简化一下核心逻辑,核心逻辑的伪代码如下:
backlog = listen_backlog;
somaxconn = valuOf(`net.core.somaxconn`);
if(backlog > somaxconn) {
backlog = somaxconn;
}
按张师傅的博客所说,在内核版本为3.10.0中, backlog 值会在这个时候依次传递给 __sys_listen() -> inet_listen()->inet_csk_listen_start()->reqsk_queue_alloc(),最终在 reqsk_queue_alloc函数中根据这两个系统变量经历一系列复杂的计算,最终得到操作系统使用的backlog值。但是这些操作,在5.x版本的内核都去掉了,reqsk_queue_alloc函数中不再对backlog做过任何处理:
// net/ipv4/inet_connection_sock.c
// 在这个函数中,虽然传入了backlog,但是在后续的处理中完全没有用上,由此证明backlog的赋值,在 __sys_listen 函数中已经完成
int inet_csk_listen_start(struct sock *sk, int backlog)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet = inet_sk(sk);
int err = -EADDRINUSE;
reqsk_queue_alloc(&icsk->icsk_accept_queue);
sk->sk_ack_backlog = 0;
inet_csk_delack_init(sk);
/* There is race window here: we announce ourselves listening,
* but this transition is still not validated by get_port().
* It is OK, because this socket enters to hash table only
* after validation is complete.
*/
inet_sk_state_store(sk, TCP_LISTEN);
if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
inet->inet_sport = htons(inet->inet_num);
sk_dst_reset(sk);
err = sk->sk_prot->hash(sk);
if (likely(!err))
return 0;
}
inet_sk_set_state(sk, TCP_CLOSE);
return err;
}
// net/core/request_sock.c
void reqsk_queue_alloc(struct request_sock_queue *queue)
{
spin_lock_init(&queue->rskq_lock);
spin_lock_init(&queue->fastopenq.lock);
queue->fastopenq.rskq_rst_head = NULL;
queue->fastopenq.rskq_rst_tail = NULL;
queue->fastopenq.qlen = 0;
queue->rskq_accept_head = NULL;
}
观测半连接队列大小
在三次握手的过程中,服务端收到握手请求包之后,会先把它放到半连接队列中,然后回复SYN+ACK。接着接收到客户端返回的ACK报文时,再把这个数据包从半连接队列移动到全连接队列中。在正常情况下,SYN报文在半连接队列逗留的时间会很快,观测半连接队列大小要做点处理。
按照张师傅博客提供的方法,可以在客户端设置防火墙,把服务端返回的ACK包都扔掉,这样在服务端就不会收到ACK报文了。
// 在L2机器上设置这条防火墙规则 sudo iptables --append INPUT --match tcp --protocol tcp --src 10.211.55.6 --sport 9090 --tcp-flags SYN SYN --jump DROP // 查看防火墙规则是否设置成功 sudo iptables -L
接着用上述的服务端代码启动服务后,在L2上通过nc命令连接上:
nc 10.211.55.6 9090
接着可以通过以下命令观察到,当前有多少个连接处于SYN_RECV状态:
sudo netstat -lnpa | grep :9090 | awk '{print $6}' | sort | uniq -c | sort -rn

处于SYN_RECV状态的连接,意味着接收到了客户端的SYN报文但未接收到ACK报文。此时连接就处于SYN_RECV状态。通过这个点可以观测到半连接队列此时的大小是多少。你也可以在L2上通过程序发起多次连接,看看SYN_RECV状态的连接数是否有变化,此处就不再叙述了。
观测全连接队列大小
当请求收到ACK之后,就会从半连接队列挪到全连接队列,此时连接已经完全建立,连接状态就会从LISTEN变成ESTABLISHED状态,等待应用程序调用accept函数从全连接队列中取走数据。所以,要观察全连接队列的大小,只要观察ESTABLISHED状态的连接数即可。同样可以采用netstat命令:
netstat -lnpa | grep :9090 | awk '{print $6}' | sort | uniq -c | sort -rn
也可以使用ss命令来进行观测。使用命令如下:
ss -lnt | grep :9090
- 处于 LISTEN 状态的 socket,Recv-Q 表示 accept 队列排队的连接个数,Send-Q 表示全连接队列(也就是 accept 队列)的总大小
- 对于非 LISTEN 状态的 socket,Recv-Q 表示 receive queue 的字节大小,Send-Q 表示 send queue 的字节大小
总结
SystemTap是一个很有力的工具,用好这个工具,可以实实在在地观测到Linux内部的状态,让自己对操作系统有个更深刻的认识。
以上就是使用SystemTap观测TCP Backlog过程解析的详细内容,更多关于SystemTap观测TCP Backlog的资料请关注脚本之家其它相关文章!