
Docker部署Ollama搭建本地AI开发环境
江湖人称小鱼哥
前言
“想开发 AI 应用,每次都要调用云端 API?免费额度用完还得付费?跑个 demo 都要担心成本?”
这是很多 AI 应用开发者遇到的痛点。阿里百炼、智谱 AI、OpenAI 等平台虽然提供免费额度,但用完就得付费。而且在开发调试阶段,频繁调用 API 不仅费钱,网络延迟也影响体验。
更好的方案是:本地部署大模型,开发测试随便用,无需担心额度和费用。
今天这篇文章,我会带你用 Docker + Ollama 搭建一个本地 AI 开发环境,让你在开发 AI 应用时,可以快速调用本地模型进行测试。
Ollama 是什么?
Ollama 是一个开源的本地大模型运行工具,让你能够像使用 Docker 管理容器一样,轻松管理和运行各种开源大模型。
核心能力
- 一键拉取模型:类似
docker pull,用ollama pull qwen2.5:7b即可下载模型 - 本地推理运行:在本地机器上运行模型,无需联网
- OpenAI 兼容 API:提供标准的 HTTP API,与 OpenAI 接口兼容
- 多模型支持:支持 Llama、Qwen、DeepSeek、Mistral 等主流开源模型
工业生产中的定位
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 开发测试 | Ollama | 部署简单、API 兼容、快速迭代 |
| 个人/小团队 | Ollama | 资源占用低、开箱即用 |
| 生产环境 | vLLM / 云端 API | 高并发、高吞吐、稳定可靠 |
| 企业私有化 | vLLM + K8s | 可扩展、可监控、高可用 |
总结:Ollama 的定位是本地开发测试工具,而不是生产级推理引擎。如果你需要支撑高并发线上服务,应该考虑 vLLM 等专业方案。
竞品对比
| 工具 | 特点 | 适用场景 |
|---|---|---|
| Ollama | 上手最简单,类 Docker 体验 | 开发测试、个人使用 |
| vLLM | 高性能推理引擎,支持 PagedAttention | 生产环境、高并发 |
| LM Studio | 图形界面,适合非技术用户 | 个人体验、无代码场景 |
| LocalAI | OpenAI API 完全兼容,功能丰富 | 需要完整 OpenAI 替代方案 |
| llama.cpp | 底层推理库,性能极致 | 需要深度定制、嵌入式场景 |
为什么开发阶段选 Ollama?
- 安装最简单:一条命令搞定
- 模型管理方便:拉取、切换、删除都很直观
- API 兼容好:直接用 OpenAI SDK 调用
- 资源占用低:适合日常开发机器运行
本地开发 vs 云端 API
先看下两种方案的对比:
| 对比项 | 云端 API(百炼/OpenAI) | 本地 Ollama |
|---|---|---|
| 调用方式 | HTTP API | HTTP API(兼容 OpenAI 格式) |
| 费用 | 免费额度用完需付费 | 完全免费 |
| 网络 | 依赖网络,有延迟 | 本地调用,毫秒级响应 |
| 隐私 | 数据上传云端 | 数据完全本地 |
| 模型选择 | 平台限定 | 自由选择任意模型 |
| 适用场景 | 生产环境 | 开发测试、跑 Demo |
核心价值:本地 Ollama 提供 OpenAI 兼容的 API 接口,你的代码几乎不用改,只需要换一下 base_url,就能无缝切换。
第一步:安装 Docker Desktop
1. 下载安装
访问 Docker 官网下载安装包:
https://www.docker.com/products/docker-desktop/
根据你的操作系统选择对应版本(Windows / macOS / Linux 都支持)。
2. 验证安装
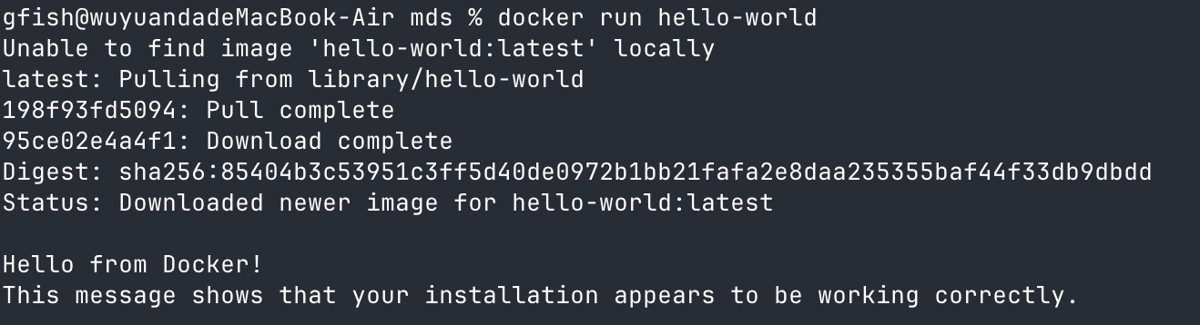
打开终端,执行:
docker --version docker run hello-world
看到 “Hello from Docker!” 说明安装成功。
第二步:部署 Ollama 容器
1. 创建挂载目录
macOS 用户:
mkdir -p /Users/$(whoami)/docker/ollama
Linux 用户:
sudo mkdir -p /home/docker/ollama sudo chmod 777 /home/docker/ollama
说明:macOS 的用户目录是
/Users/用户名,而 Linux 是/home/用户名。macOS 的/home是受保护的系统目录,无法写入。
2. 启动容器
macOS 用户:
docker run -d \ --name ollama \ -p 11434:11434 \ -v /Users/$(whoami)/docker/ollama:/root/.ollama \ ollama/ollama
Linux 用户:
docker run -d \ --name ollama \ -p 11434:11434 \ -v /home/docker/ollama:/root/.ollama \ ollama/ollama
参数说明:
-p 11434:11434:暴露 API 端口,供本地应用调用-v <宿主机目录>:/root/.ollama:挂载宿主机目录,模型数据持久化保存
2. 验证服务
curl http://localhost:11434
返回 Ollama is running 即成功。
第三步:拉取开发测试用模型
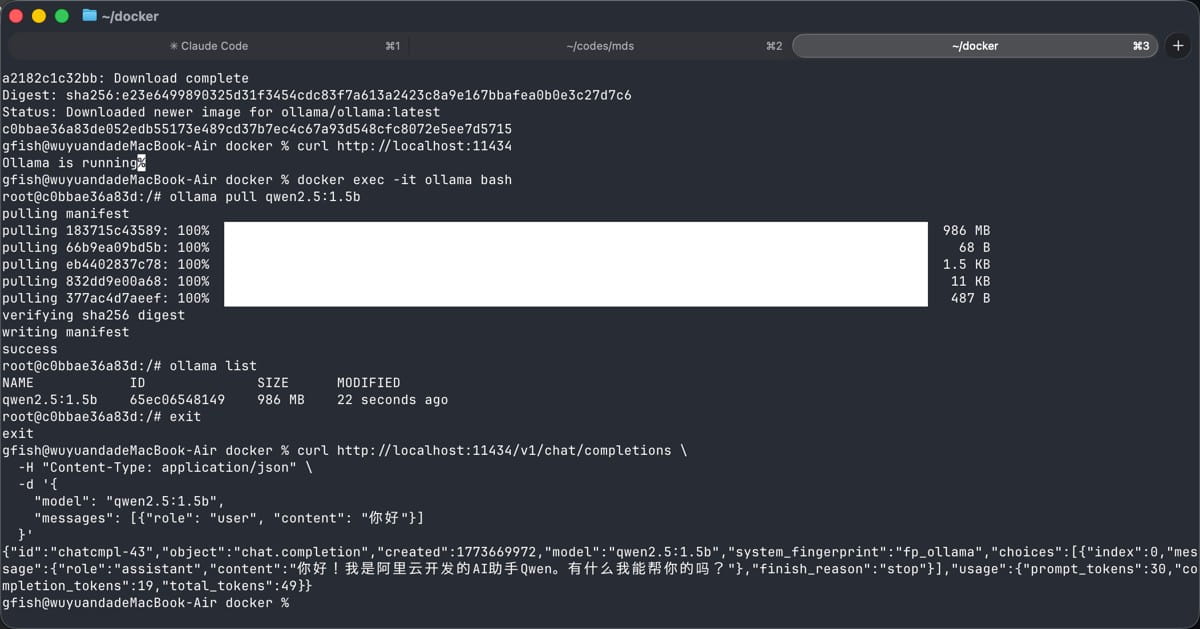
进入容器:
docker exec -it ollama bash
推荐模型
开发测试推荐轻量级模型(响应快,资源占用低):
# 中文场景推荐 ollama pull qwen2.5:7b # 通义千问,中文能力强 ollama pull qwen2.5:1.5b # 更轻量,快速测试用 # 推理场景推荐 ollama pull deepseek-r1:7b # DeepSeek R1,推理能力强 ollama pull deepseek-r1:1.5b # 轻量版 # 英文场景推荐 ollama pull llama3.2:3b # Llama 3.2,平衡性能和速度 ollama pull llama3.1:8b # 经典版本
常用命令
ollama list # 查看已下载模型 ollama ps # 查看运行中的模型 ollama rm <模型名> # 删除模型
第四步:在代码中调用本地模型
Ollama 提供 OpenAI 兼容的 API,这意味着你可以直接复用现有代码,只需修改 base_url。
API 端点
Base URL: http://localhost:11434/v1 API Key: ollama(随便填,本地不需要验证)
Python 示例
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama" # 本地部署,随便填
)
response = client.chat.completions.create(
model="qwen2.5:1.5b",
messages=[
{"role": "user", "content": "你好,介绍一下你自己"}
]
)
print(response.choices[0].message.content)JavaScript/Node.js 示例
import OpenAI from 'openai';
const client = new OpenAI({
baseURL: 'http://localhost:11434/v1',
apiKey: 'ollama'
});
const response = await client.chat.completions.create({
model: 'qwen2.5:1.5b',
messages: [
{ role: 'user', content: '你好,介绍一下你自己' }
]
});
console.log(response.choices[0].message.content);cURL 测试
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2.5:1.5b",
"messages": [{"role": "user", "content": "你好"}]
}'
第五步:Spring Boot 集成 Spring AI
如果你是 Java 开发者,Spring AI 对 Ollama 有原生支持,通过 OllamaChatModel 可以直接注入使用。
1. 添加依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama</artifactId>
<version>1.1.0</version>
</dependency>2. 添加自动配置 Starter
踩坑提醒:网上很多教程推荐使用 spring-ai-ollama-spring-boot-starter,但它的最新版是 1.0.0-M6。如果你的项目中 Spring AI 版本较新(如 1.1.0),直接引入会导致启动报错。
原因:Spring AI 新版本将 spring-ai-spring-boot-autoconfigure 拆分成了多个模块,而旧的 starter 依赖的自动配置类与新版本存在 Bean 冲突。
解决方案:使用新版单独的自动配置模块:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-autoconfigure-model-ollama</artifactId>
<version>1.1.0</version>
</dependency>3. 配置 application.yml
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
model: deepseek-r1:7b4. 注入 OllamaChatModel
配置完成后,可以直接注入 ollamaChatModel:
@Autowired
@Qualifier("ollamaChatModel")
private ChatModel ollamaChatModel;5. 完整调用示例
@RestController
@RequestMapping("/ai/ollama")
public class OllamaChatController {
@Autowired
@Qualifier("ollamaChatModel")
private ChatModel ollamaChatModel;
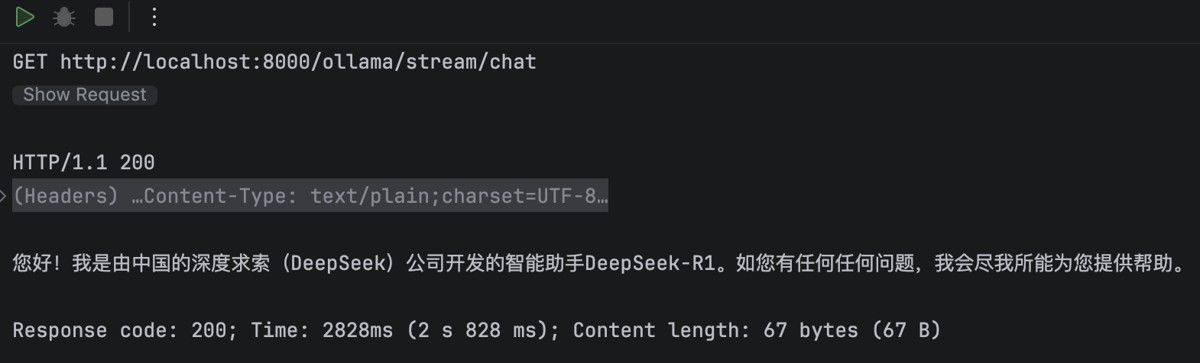
@GetMapping("/stream/chat")
public Flux<String> streamChat(HttpServletResponse response) {
response.setCharacterEncoding("UTF-8");
Flux<ChatResponse> stream = ollamaChatModel.stream(new Prompt("你是谁?"));
return stream.map(resp -> resp.getResult().getOutput().getText());
}
}启动应用后,访问这个接口,就能调用到本地部署的 DeepSeek 模型了。
开发工作流建议
推荐的开发流程:
1. 本地开发 → 调用 Ollama(localhost:11434)
2. 本地测试 → 继续用 Ollama,快速迭代
3. 部署上线 → 切换到云端 API(阿里百炼/智谱/OpenAI)
切换只需改配置:
# 开发环境
spring.ai.ollama.base-url: http://localhost:11434
# 生产环境
spring.ai.openai.base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
spring.ai.openai.api-key: ${DASHSCOPE_API_KEY}常见问题
Q1:模型响应太慢?
选择更小的模型参数,如 qwen2.5:1.5b 或 deepseek-r1:1.5b,响应速度会快很多。
Q2:内存不够?
8GB 内存建议用 7B 以下的模型,16GB 可以尝试 14B 模型。
Q3:如何查看 API 是否正常?
curl http://localhost:11434/v1/models
返回模型列表即正常。
Q4:容器重启后模型还在吗?
是的,模型存储在挂载的宿主机目录中(macOS: /Users/用户名/docker/ollama,Linux: /home/docker/ollama),容器重启或重建都不会丢失。
总结
搭建本地 AI 开发环境,核心就三步:
- 安装 Docker Desktop → 容器运行环境
- 部署 Ollama 容器 → 本地模型服务
- 代码中调用 API → OpenAI 兼容接口
核心价值:
- 开发调试阶段,无需担心 API 额度和费用
- 本地调用,毫秒级响应,迭代更快
- OpenAI 兼容接口,代码几乎不用改
- 部署上线时,只需切换 base_url 即可
参考资料:
- Ollama 官方文档:
https://ollama.com/docs - Ollama OpenAI 兼容 API:
https://github.com/ollama/ollama/blob/main/docs/openai.md - Spring AI 文档:
https://docs.spring.io/spring-ai/reference/
到此这篇关于Docker部署Ollama搭建本地AI开发环境的文章就介绍到这了,更多相关Docker部署Ollama搭建AI环境内容请搜索脚本之家以前的文章或继续浏览下面的相关文章,希望大家以后多多支持脚本之家!