

LM Studio本地部署大模型(支持DeepSeek-R1) v0.4.14-4 中文绿色版
- 大小:596MB
- 分类:办公软件
- 环境:Windows
- 更新:2026-05-31
热门排行












简介
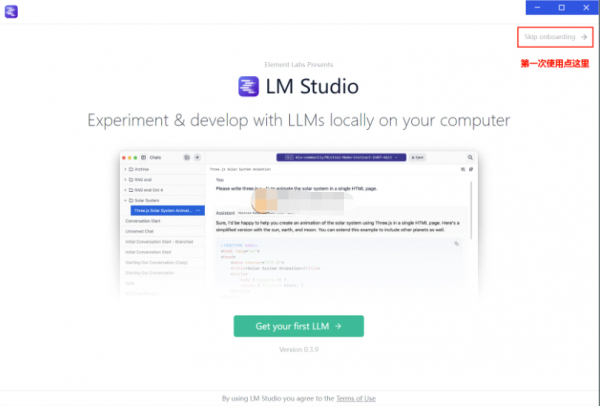
LM Studio是一个专注于本地大语言模型交互的桌面应用程序,为在本地设备上运行大型语言模型提供了创新且高效的解决方案。LM Studio基于llama.cpp开发,提供图形界面,无需命令行操作,专注桌面端用户体验。
什么是LM Studio?
LM Studio 是一个创新的人工智能平台,专注于提供快速、安全的本地大型语言模型运行和下载服务。它支持多种先进的语言模型,如LLaMa、MPT和Gemma等,并且具备优越的离线运行能力。通过这个工具,用户可以在本地机器上高效地运行模型,从而避免了数据隐私问题和网络延时所带来的困扰。
软件特色
模型管理:支持从Hugging Face等资源库中拉取、存储、运行各类GGUF格式模型,用户可以在软件内方便地浏览、搜索和选择自己需要的模型。
硬件协同优化:依托llama.cpp底层架构,针对NVIDIA系列GPU运用GPU卸载技术,合理分配运算任务,突破显存局限;在内存管理方面,借助模型量化手段降低内存占用量,确保设备内存有限的情况下也能平稳加载运行大型模型。
参数调控:用户可灵活调整“温度”“重复惩罚”等参数,精准定制模型输出。比如“温度”参数可调整输出文本的灵活度,“重复惩罚”参数可把控文本多样性。
文本嵌入强化检索:借助POST/v1/embeddings端点生成文本嵌入向量,融入检索增强生成(RAG)架构体系,在海量文档、知识库搜索场景表现卓越。
内置兼容OpenAI的本地服务器功能:无缝衔接既有基于OpenAI API搭建的应用与本地模型,极大缩短开发适配周期,助力创新应用高效落地。
使用教程
1、打开LM studio程序

2、点击右下角的设置,里面把语言选择成为“简体中文”

模型存放及部署设置
1、需要下载Deepseek-R1模型,当我们下载好模型文件后,需要注意,不能随便存放,因为需要让安装好的LM Studio来加载,而它对文件加载是有规定的,在客户端里选择”模型目录“,然后我们选择”更改“

2、这里我们把文件举例放在D盘,新建一个文件夹,取名:models000,注意,这里的文件夹也不能有任何符号及中文

3、我们在models000下再建立一个文件夹001,在001里继续建立一个文件夹 002,这样002就处于三级目录下了,我们把刚才下载的R1模型文件,复制在这个002文件夹内就可以了

4、然后我们回到刚才LM studio的模型目录里,就直接可以看到刚才已经复制的模型了

5、点击聊天界面,再点击上面的模型选择按钮

6、选择刚才的模型后,点击加载等待完成即可,注意:这里可以选择加一个“快速注意力”
更新日志
0.4.14 - 版本说明
版本 4
MTP 推测解码稳定版发布!
使用内置多令牌预测头的模型可加快生成速度
要试用,请下载支持 MTP 的模型
修复了启用 MTP 时非 MTP 推测解码错误的问题
修复了 `lms get gemma4` 命令不显示任何结果的错误
`lms chat` 现在会显示每个远程模型所在的 LM Link 设备
版本 3
修复了使用 MTP 时聊天 UI 可能删除空格的错误
版本 2
MTP 推测解码 Beta 版发布
修复了 OAuth 流程中部分 MCP 的令牌交换失败问题
版本 1
LM Studio Engine 协议 Beta 版
0.4.12 - 发布说明
构建1
Qwen 3.6 的支持
聊天PDF导出中风格改进
修复了带有 OAuth 的 MCP 服务器在某些 Windows 环境中无法正常工作的漏洞
Qwen 3.5性能提升,兼容OpenAI和Anthropic/v1/chat/completions/v1/responses/v1/messages
0.4.2 - 发布说明
构建2
引入MLX中的并行请求!🎉
MLX-engine 1.0.0 中新增对连续批处理的支持
目前该功能仅支持文本,VLM支持正在开发中
修复了插件列表中的滚动bug。
修复了在聊天输入中显示角色和插入按钮时的响应式布局bug。
引入了消息文件附件的新样式
构建1
修复了一个 Qwen3-Coder-Next 可能因不支持 jinja 模板过滤器而出错的错误safe
修复了一个bug,删除带有附件的对话有时会导致文件相关的应用作失败,直到重启
修复了一个导致的bug。Cannot read properties of null (reading 'visionAdapter')
修复了一个bug,即某些交互命令中选定选项颜色不正确lms
修复了一个大贴图无法保留换行格式的bug。lms chat
LM Studio 0.4.1 - 发布说明
构建1
新增:Anthropic API 兼容性端点:/v1/messages
在LM Studio 👾中使用Claude代码
为用户界面添加了新的“深暗”主题选项
在命令中增加了标志,允许加载指定数量的最大并行预测的模型--parallel <N>lms load
[麦克]修复了模型加载时“库中找不到kernel_mul_mv_bf16_f32_4”的错误
修复了一个LMS聊天无法使用非ASCII字符的bug。
修复了一个 bug,就是加载模型被移除后 UI 有时会崩溃
修复了一个 LM Studio 有时会为模型索引缓存创建多个备份的 bug。
修复了聊天终端图标的响应式处理
修复了一个导致界面崩溃的bug,显示“无法读取空属性”。
修复了一个bug,可以在整个会话中持久化扩展配置部分的选项
修复了分割和折叠窗格以及替换聊天标签页的bug。
修复了一个 Codex 在将不支持的工具传递给 LM Studio 时会遇到错误的
修复了一个模型加载器有时无法正确覆盖模型默认值的bug
修复了一个 和 有时在 API 中错误报告的 bug。input_tokenscached_tokens/v1/responses
修复了开发者模式在更新0.3 - > 0.4时不会自动开启的边缘情况
0.3.37 - 版本说明
构建版本 1
支持 LFM2 工具调用格式
修复使用生成器时出现的“无法读取 null 的属性(读取'architecture')”错误
LM Studio 0.3.23 - 完整发行说明
构建 3
[llama.cpp][教育部]通过高级负载设置中的“将模型专家权重强制到 CPU”,添加将专家权重卸载到 CPU/GPU RAM 的功能
工具名称在提供给模型之前进行规范化(替换空格、特殊字符)
构建 2
修复下载员工挑选的模型时有时“完成下载”按钮不起作用的问题
修复“修复”按钮不适用于扩展包(如 Harmony)
修复了某些包含工具的请求的“无法读取未定义的属性(读取'properties')”的问题/v1/chat/completions
修复自动更新和谐时的问题Error: EPERM: operation not permitted, unlink
构建 1
错误修复,显著提高了聊天工具调用的可靠性
修复了一些旧对话无法在应用程序中加载的错误
修复了在非流式模式下通过 OpenAI 兼容 API 使用时工具调用有时会失败的错误
修复模型不输出v1/chat/completions
对于 gpt-oss:
message.content不会包含推理内容或特殊标签
这与 的行为相匹配。o3-mini
推理内容将位于 (stream=false) 和 (stream=true) 中choices.message.reasoningchoices.delta.reasoning
修复“TypeError: Invalid Version”导致在配备 AMD+NVIDIA GPU 的机器上出现应用程序功能问题的问题
修复了 MCP 插件芯片名称在用户模式下未渲染的错误
修复了搜索结果在单击时刷新的错误
LM Studio 0.3.20 - 完整发行说明
构建 4
通过llama.cpp引擎改进 Qwen3-Coder-480B-A35B 工具调用生成
修复了由于 jinja 模板问题导致的部分 MCP 服务器无法与 Qwen3-Coder 一起使用的问题
添加聊天外观选项,可将新消息滚动到顶部或保留在底部
构建 3
Qwen3-Coder-480B-A35B 工具支持
构建 2
修复了应用程序无法打开的错误
构建 1
修复选择模型后模型加载器闪烁的问题
LM Studio 0.3.18 - 完整的发布说明
构建3
修复了从OpenAI兼容端点流式传输时的错误格式,以匹配预期格式
为Mistral v13 tokenizer模型添加了工具调用支持(使用适当的聊天模板)
构建2
使用OpenAI兼容端点进行流式传输时,添加了对“stream_options”: { "include_usage": true }的支持
将@huggingface/jinja升级到0.5.0版本,以支持更多提示模板
修复了一个错误,即应用程序会为只能进行CPU推断的计算机推荐过大的第一个模型
修复了您无法禁用错误插件的错误
添加印地语和马拉地语翻译
构建1
MCP:在•••菜单下强制重新启动MCP服务器的选项
MCP:添加了用于刷新工具列表的按钮
狭窄窗口上任务控制的响应式用户界面
当应用程序窗口狭窄时,在弹出窗口中显示聊天屏幕边栏
在mcp.json的条目中添加了一个超时字段,该字段可用于以毫秒为单位指定每个工具调用的最大时间
添加了使用Deno的实验性JavaScript代码解释器插件
对插件感兴趣吗?在此注册插件私人测试版:https://forms.gle/ZPfGLMvVC6DbSRQm9
各种用户界面和颜色调整
修复了聊天消息草稿和附加文件无法延续到新创建的聊天的错误
修复了一个错误,即工具使用不适用于骆驼模型(this.endToolCallStrings不可迭代)
修复了OpenAI兼容端点的错误,即response_format.type不支持文本
修复了一个错误,即跨多个“块”拆分的并行工具调用被无声丢弃
修复了SSE MCP服务器无法正常工作的错误
修复了根级$defs在工具定义中被剥离的错误
0.3.17 - 完整发行说明
版本 10
添加了 Chat Appearance 设置,以仅在最后一条消息、仅在工具提示中或在所有适用的消息上显示消息生成统计信息
令牌计数现在包括系统提示符和工具定义
为内容中包含 URL 的 LLM 消息显示“在浏览器中打开”按钮。
请注意:LLM 可能会生成不受信任的 URL。点击前始终验证链接。
构建 9
默认启用 MCP
Cmd + Shift + E在 Mac 或 PC 上始终打开当前聊天的系统提示编辑器Ctrl + Shift + E
版本 8
当下载面板在新窗口中打开时,添加一个选项以将其固定在其他窗口的顶部(右键单击正文)
添加以下语言,感谢我们的社区本地化人员!
马拉雅拉姆语 (ml) @prasanthc41m
泰语 (th) @gnoparus
波斯尼亚语 (bs) @0haris0
保加利亚语 (bg) @DenisZekiria
匈牙利语 (胡) @Mekemoka
孟加拉语 (bn) @AbiruzzamanMolla
加泰罗尼亚语 (ca) @Gopro3010
芬兰语 (fi) @reinew
希腊语 (gr) @ilikecatgirls
罗马尼亚语 (ro) @alexandrughinea
瑞典语 (sv) @reinew
修复了在选择草稿模型进行推测解码时条目可能重复的错误
构建 7
添加了思考块预览“晕影”,并在聊天外观设置中提供了禁用选项
将 “Qwen3 Embedding” 模型的默认域设置为 Text Embedding
添加了命令到命令以显示预测统计信息(感谢@Yorkie--statslms chat)
[视窗][ROCm]Strix Halo (AMD Ryzen AI PRO 300 系列) 支持
[视窗]将 CPU 名称添加到硬件页面
版本 6
在生成工具调用参数令牌时将其流式传输到 UI
修复了在模型生成时向上滚动的错误
修复了工具权限对话框不会自动滚动到聊天底部的错误
构建 5
为了减少新用户的混淆,“change role”和“insert”按钮现在将在新安装时默认隐藏。您可以右键单击发送按钮以打开或关闭它们。
修复了不提供参数对象的 MCP 工具无法正常工作的错误。
修复了如果 MCP 服务器重新加载,正在进行的工具调用将无限期挂起的错误。
版本 4
[MCP 测试版]修复了当工具调用的参数包含数组或对象时崩溃的问题
构建 3
修复了引擎更新有时会卡住的错误
构建 2
改进了全尺寸 DeepSeek-R1 工具调用的可靠性
按钮弹出下载面板到新窗口。
版本 1
新主题:Solarized Dark。
在“设置”>“常规”中设置它,或按[⌘/Ctrl K + T]
修复了模型目录时间戳、点赞、下载排序未按预期工作的问题。
修复了模型删除对话框中的占位符文本。
修复了 MLX 模型在 Windows 上显示的问题。
修复了标题栏重新出现在 No chats 页面上的错误。
修复了快速转义时删除聊天对话框会阻止聊天 UI 的错误。
LM Studio 0.3.15:RTX 50 系列 GPU 和改进
LM Studio 0.3.15 现已作为稳定版本提供。此版本包括对 NVIDIA RTX 50 系列 GPU (CUDA 12) 的支持,UI 修饰包括新的系统提示编辑器 UI。此外,我们还改进了对工具使用(参数)的 API 支持,并添加了一个新选项,用于将每个生成的片段记录到 API 服务器日志中。tool_choice
支持采用 CUDA 12 的 RTX 50 系列 GPU
LM Studio 现在支持 RTX 50 系列 GPU (CUDA 12.8) 以及 Windows 和 Linux 上的引擎。此更改使 RTX 50 系列 GPU 上的首次模型加载时间如预期般快。对于配备 RTX 50 系列 GPU 的机器,如果 NVIDIA 驱动程序版本兼容,LM Studio 将自动升级到 CUDA 12。llama.cpp
最低驱动程序版本为:
Windows:551.61 或更高版本
Linux:550.54.14 或更高版本
如果您有 RTX 50 系列 GPU 并且驱动程序版本兼容,LM Studio 将自动升级到 CUDA 12。 如果您有 RTX 50 系列 GPU,并且驱动程序版本不兼容,LM Studio 将继续使用 CUDA 11。在 中管理此功能。Ctrl + Shift + R
新的 System Prompt Editor UI
系统提示符是自定义模型行为的强大方法。它们可以只有几个字,有时也可以长达数页。LM Studio 0.3.15 引入了更大的视觉空间来编辑更长的提示。您仍然可以使用侧边栏中的迷你提示编辑器。
改进的工具使用 API 支持
类似 OpenAI 的 REST API 现在支持该参数,该参数允许您控制模型使用工具的方式。该参数可以采用三个值:tool_choicetool_choice
"tool_choice": "none"- 模型不会调用任何工具
"tool_choice": "auto"- 模型决定是否调用工具
"tool_choice": "required"- 强制模型仅输出工具 (仅限 llama.cpp 引擎)
我们还修复了 LM Studio 的 OpenAI 兼容模式中的一个错误,即数据块“finish_reason”在适当时未设置为“tool_calls”。
还有......社区预设(预览版)
预设是将系统提示和模型参数打包在一起的便捷方法。
从 LM Studio 0.3.15 开始,您可以与社区共享您的预设,并通过 Web ☁️ 下载其他用户制作的预设。您还可以点赞和分叉其他人制作的预设。
在“设置”>“常规”中启用此功能>启用发布和下载预设。打开后,当您右键单击侧边栏中的预设时,您会发现一个新的“发布”按钮。这将允许您将预设发布到社区。
在 https://lmstudio.ai/login 获取您的用户名并开始分享您的预设!您不需要帐户即可下载预设,只需发布即可。
LM Studio 0.3.9
LM Studio 0.3.9 包括一个新的空闲 TTL 功能,支持 Hugging Face 存储库中的嵌套文件夹,以及一个实验性 API,用于在聊天完成响应的单独字段中接收。reasoning_content
早期版本的 0.3.9 在流式处理 DeepSeek R1 聊天完成响应时存在错误。请更新到最新版本 (5) 以解决此问题。
空闲 TTL 和自动移出
用例:假设您正在使用 Zed、Cline 或 Continue.dev 等应用程序与 LM Studio 提供的 LLM 进行交互。这些应用程序利用 JIT 在您首次使用模型时按需加载模型。
问题:当您没有主动使用模型时,您可能不希望它继续加载到内存中。
解决方案:为通过 API 请求加载的模型设置 TTL。每次模型收到请求时,空闲计时器都会重置,因此在您使用它时它不会消失。如果模型未执行任何工作,则认为模型处于空闲状态。当空闲 TTL 过期时,模型会自动从内存中卸载。
您可以在请求负载中设置以秒为单位的 TTL,或用于命令行使用。lms load --ttl <seconds>
在文档文章中阅读更多内容:TTL 和自动驱逐。
在聊天完成响应中分离reasoning_content
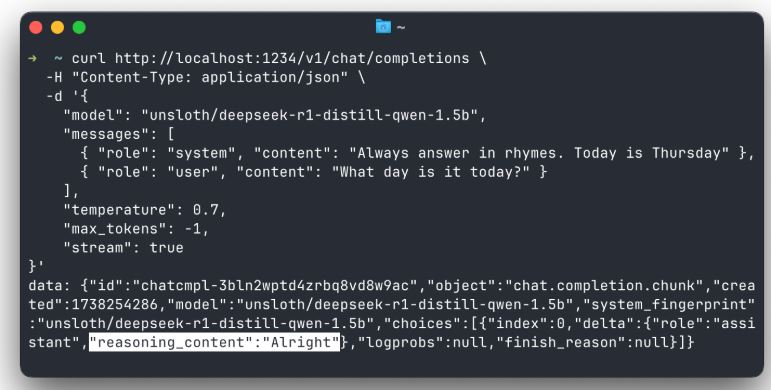
对于 DeepSeek R1,在单独的字段中获取推理内容
DeepSeek R1 模型在标签内生成内容。此内容是模型的 “推理” 过程。在聊天完成响应中,您现在可以在一个名为 following the pattern in DeepSeek API 的单独字段中接收此内容。<think></think>reasoning_content
这适用于流式和非流式完成。您可以在 App Settings > Developer 中打开此功能。此功能目前处于试验阶段。
注意:根据 DeepSeek 的文档,您不应在下一个请求中将推理内容传回给模型。
LM 运行时的自动更新
LM Studio 支持多种引擎变体(仅 CPU、CUDA、Vulkan、ROCm、Metal)以及 Apple MLX 引擎。这些引擎会频繁更新,尤其是在发布新模型时。llama.cpp
为了减少手动更新多个片段的需要,我们为运行时引入了自动更新。默认情况下,此功能处于启用状态,但您可以在 App Settings 中将其关闭。
更新运行时后,您将看到一条通知,其中显示了发行说明。您也可以在 runtimes 选项卡中自行管理:在 Windows/Linux 上,在 macOS 上。Ctrl + Shift + RCmd + Shift + R

LM 运行时将自动更新到最新版本。您可以在设置中关闭此功能
支持 Hugging Face 存储库中的嵌套文件夹
一个期待已久的功能:您现在可以从 Hugging Face 存储库中的嵌套文件夹下载模型。如果您最喜欢的模型发布者将其模型组织在子文件夹中,您现在可以直接在 LM Studio 中下载它们。
这使得下载 https://huggingface.co/unsloth/DeepSeek-R1-GGUF 等模型变得容易。也适用于。lms get <hugging face url>
# Warning: this is a very large model
lms get https://huggingface.co/unsloth/DeepSeek-R1-GGUF
0.3.9 - 完整更改日志
版本 6
修复了在包含图像的聊天中使用纯文本模型时出现的“无法读取 undefined 的属性”
修复了 Windows 上的路径解析问题,该问题导致某些计算机上的 LM 运行时意外运行
CUDA 模型加载崩溃,“llm_engine_cuda.node.系统无法访问该文件”
ROCm 乱码模型生成
修复了使用旧版本应用程序创建的聊天中的 RAG 消息不显示的错误
修复了输入法编辑器 (IME) 错误:现在,按 Enter 键时,除非完成合成,否则不会发送消息
构建 5
修复了在流式传输 DeepSeek R1 聊天完成响应时不遵循设置的 API 错误reasoning_content
版本 4
新的实验性 API:在聊天完成响应(流式和非流式)中的单独字段中发送reasoning_content
适用于在标签内生成内容的模型(如 DeepSeek R1)<think></think>
在 App Settings > Developer 中打开
构建 3
新增内容:添加聊天外观选项以自动扩展新添加的 Thinking UI 块
新增内容:当应用程序提供 insufficient system resources 错误通知时,显示对护栏配置的快速访问
修复了如果删除非默认 models 目录,则不会为新模型编制索引的错误
修复了硬件检测中的一个错误,该错误在使用 Vulkan 后端时有时会错误地过滤掉多 GPU 设置中的 GPU
修复了模型加载 UI 中的一个错误,该错误导致没有 Flash 注意的 F32 缓存类型无法被识别为 llama.cpp Metal 运行时的有效配置
构建 2
新增内容:添加了对从 Hugging Face 存储库中的嵌套文件夹下载模型的支持
改进了对直接使用 Hugging Face URL 进行搜索的支持
新增内容:自动更新选定的运行时扩展包(您可以在设置中关闭此功能)
新增内容:添加了使用 LM Studio 的 Hugging Face 代理的选项。这可以帮助无法直接访问 Hugging Face 的用户
新功能:MLX 模型的 KV 缓存量化(需要 mlx-engine/0.3.0)
我的模型选项卡刷新:更整洁的模型名称和模型类型的侧边栏类别
可以切换回在“应用程序设置”>“常规”中显示完整文件名
要查看原始模型元数据(以前为:(i) 按钮),请右键单击模型名称,然后选择“查看原始元数据”
修复了清除 Sampling Settings 中的 Top K 会触发错误的 bug
版本 1
新增内容:TTL - 可选择在一定时间后自动卸载未使用的 API 模型(请求有效负载中的字段)ttl
对于命令行使用:lms load --ttl <seconds>
API 参考:https://lmstudio.ai/docs/api/ttl-and-auto-evict
新增内容:自动驱逐 - 可选择在加载新 API 模型之前自动卸载之前加载的 API 模型(在应用程序设置中控制)
修复了模型思维块内的方程式有时会在块下方生成空白空间的错误
修复了 Toast 通知中的文本不可滚动的问题
修复了取消选中和选中 Structured Output JSON 会使架构值消失的错误
修复了生成时自动滚动有时不允许向上滚动的错误
[开发商]将日志记录选项移动到 Developer Logs 面板标题(••• 菜单)
修复了聊天外观字体大小选项在思考区块中不缩放文本的问题
 chrome下载
chrome下载 知乎下载
知乎下载 Kimi下载
Kimi下载 微信下载
微信下载 天猫下载
天猫下载 百度地图下载
百度地图下载 携程下载
携程下载 QQ音乐下载
QQ音乐下载