
Invoke AI 可视化AI绘图工具 V3.0.2 一键安装中文版(详细教程)
- 大小:53.6MB
- 分类:图像处理
- 环境:Windows
- 更新:2023-09-18
热门排行












简介
invokeAI简介及原理
自Stable Diffusion模型发布以来,一组人(从Lstein开始)一直致力于将生成高质量图像的最佳工具汇集到单个易于使用的存储库中。2022 年9月,InvokeAI 团队正式成立。Invoke.Ai是一个创新的文本到图像 AI 平台软件,它利用尖端的深度学习模型将文本描述转换为具有视觉吸引力的图像。通过向 Invoke.Ai 提供特定提示,用户可以生成与他们想要的概念、场景或对象相对应的独特且高质量的图像。这项革命性技术为艺术家、设计师、内容创作者和任何需要迷人视觉效果的人开启了激动人心的可能性。
InvokeAI只是一个目前完全免费且开源的可视化绘图工具,它提供一个AI绘画的基本框架、插件接口和UI界面,具体的绘制模型和lora模型等还需要下载和导入。InvokeAI已经加入了controlnet、lora、动态提示词等功能,极大的提高了绘画结果的可控性、稳定性和必要时的随机性(比如想抽卡生存随机的图片时)InvokeAI对比类似功能的WebUI,InvokeAI有着更简单上手,部署条件更简单,学习成本更低的优点,并且随着开发者的更新InvokeAI的功能也已经逐渐追上了WebUI的步伐,如果需要安装插件或者导入新的文转图训练、模型CHECK_POINT、lora、vae等,InvokeAI也在操作页面有很方便快捷的可视化添加方式。支持SDXL 1.0,该模型拥有更多的参数,并且对色彩的鲜艳和准确程度做了优化,全部采用原生的 1024×1024 分辨率(之前只有 512×512)。新模型只需更简单的语言就能生成更智能的图片。
丨其他功能
同时支持 ckpt 和扩散器模型
SD 1.5、2.0、2.1 支持
噪音控制与Tresholding
热门采样器支持
升级和面部修复工具
嵌入管理器和支持
模型管理器和支持
自动安装:以下安装比较复杂,如果不会可联系客服远程(另收费)
先下载安装包到本地,并解压到本地。安装包支持多环境(Windows/MacOS/Linux)
如果是 Windows 操作系统,双击 install.bat 脚本安装。
如果在苹果电脑macOS系统,支持M1,M2 系统下,打开终端窗口,将 install.sh 文件从 Finder 拖到终端,然后按回车键。
Linux 操作系统执行 install.sh
开始安装后会询问是否安装默认路径安装(Y为按默认路径安装,N为自定义安装路径)选择完路径后会开始安装Invoke本体,本体安装完成后会进入下一步让你选择你想下载的绘画模型(如果没有出现这一步,请把CMD窗口最大化然后等一会)选择完模型后会开始下载模型,下载完成可能会遇到错误无法正常完成安装,只需要关闭窗口即可完成安装。
您运行安装程序的文件夹现在将被许多文件填满。如果您在 Windows 上,双击 invoke.bat 文件。在macOS 上,打开终端窗口,将 invoke.sh 从文件夹中拖到终端中,然后按回车键。Linux 操作系统执行 invoke.sh
我只说一下比较重要的几个选项,第1个选项是用网页启动InvokeAI,一般无法直接启动,可先按7下载相关组件,第3个是启动图转文训练,第5个是下载其他绘图模型,第9个是检查Invoke升级,Q选项是退出。(此处为InvokeAI Windows版3.0.2post1版本号的内容,不同版本可能顺序有所不同,具体选项可以自己对照窗口内文本翻译一下)
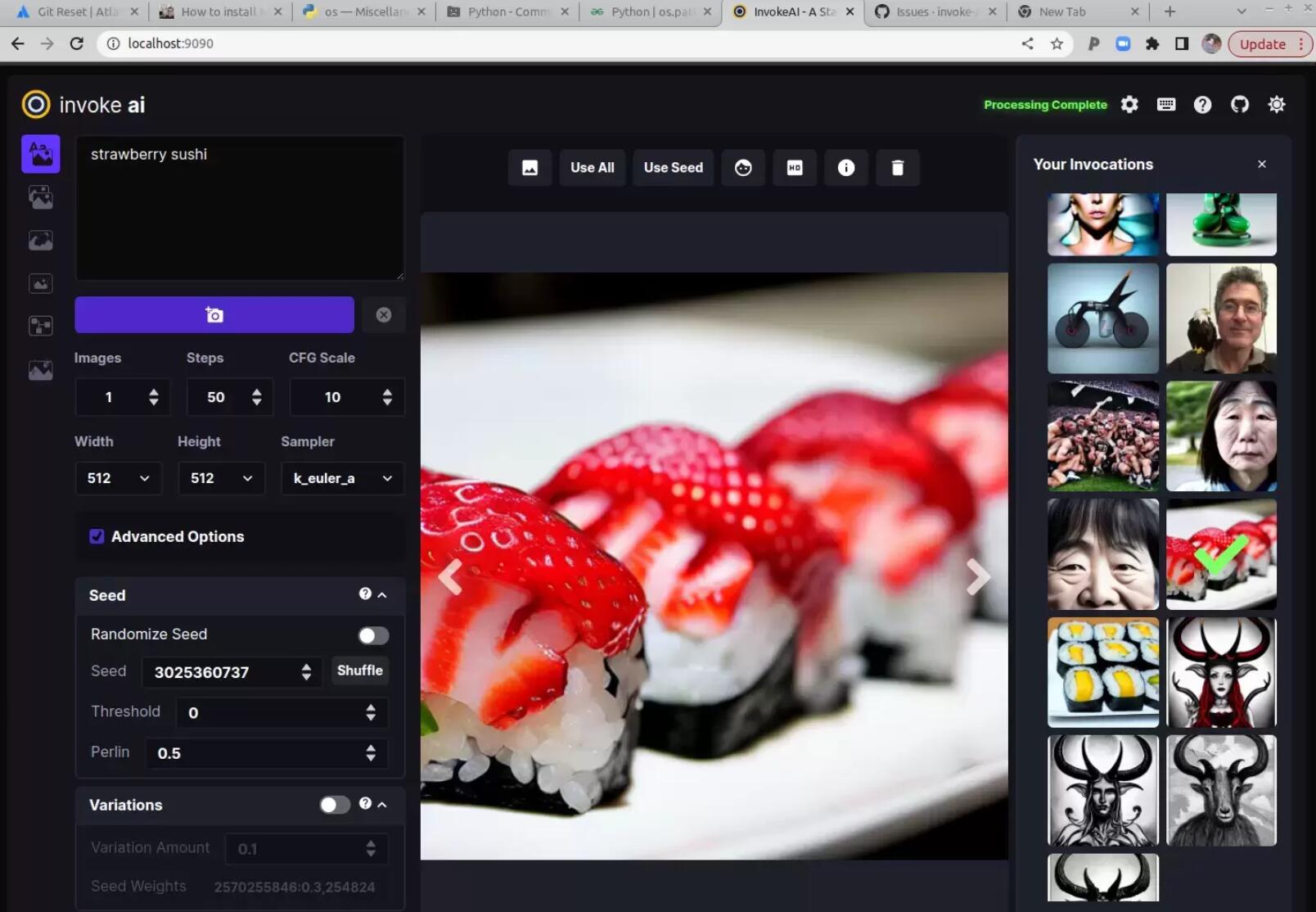
打开浏览器,然后转到 http://localhost:9090
在左上角的框中,单击 Invoke
(安装过程需要联网,部分下载内容可能无法使用国内网络下载。)
手动安装教程
手动安装有两种方式,第一种使用基本的 Python 虚拟环境 venv 命令和 PIP 包管理器。第二个基于 Anaconda3 包管理器 conda。这两种方法都需要在终端上输入命令。
需注意 conda 安装方法目前已弃用,在将来的某个时候将不受支持,因此我们也不推荐你使用该方式进行安装。
在 Windows 系统上,鼓励您安装和使用 Powershell,它提供了与 Linux 和 Mac shell 的兼容性,以及命令行补全等不错的特性。
我们主要介绍 PIP 方式的安装:
确保您使用的是 Python 3.9 或 3.10
克隆源源源源源源源源源源源源代码
git clone https://github.com/invoke-ai/InvokeAI.git
在 InvokeAI 顶级目录中,创建并激活名为 InvokeAI 的虚拟环境
python -mvenv invokeai source invokeai/bin/activate
确保 PIP 安装在虚拟环境中并且是最新的
python -mensurepip --upgrade python -mpip install --upgrade pip
为您的硬件和操作系统选择正确的需求 *.txt 文件
确保 InvokeAI 环境处于活动状态并启动 PIP
pip install --prefer-binary -r requirements.txt
设置运行时目录
运行命令行
invoke.py --root ~/Programs/invokeai
选择放弃,随后重新启动脚本
项目地址
https://github.com/invoke-ai/InvokeAI
一、主要功能及特点
1、功能介绍
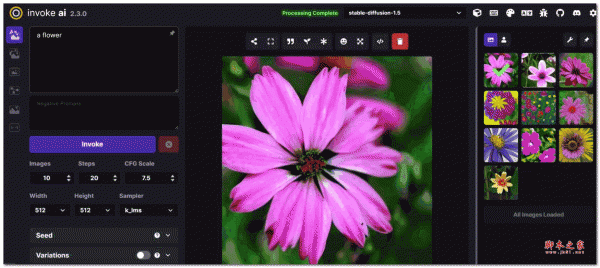
使用界面:比较美观的使用界面,最左侧是功能栏,分为三个已有功能和三个未上线功能;旁边是调节栏,用来输入和调节参数;中间是生成的图像展示,最右侧是你最近生成的图像库:
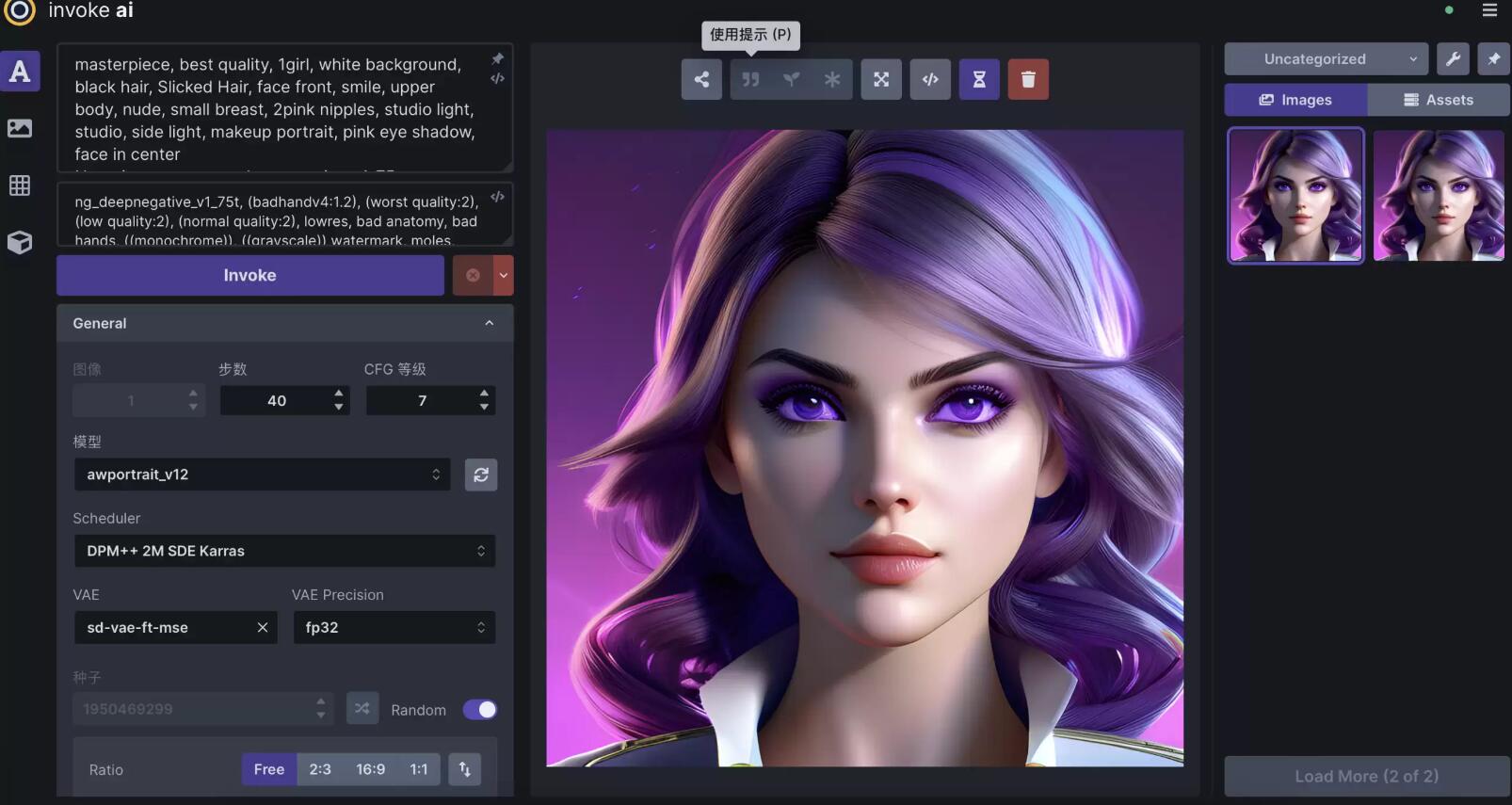
上面的屏幕截图显示了WebUI的文本到图像选项卡。有三个主要部分:
左侧的控制面板,其中包含从文本到图像生成的各种设置。最重要的部分是用于输入正文本提示的文本字段(目前显示fantasy painting, horned demon),正下方的另一个文本字段用于可选的负文本提示(要排除的概念),以及用于开始图像渲染过程的调用按钮。
中间的当前图像部分,显示您当前正在处理的图像的大格式版本。顶部的一系列按钮允许您以各种方式修改和操作图像。
左侧的图库部分包含您生成的图像的历史记录。这些图像被读取并写入 INVOKEAIROOT/invokeai.yaml 初始化文件中指定的目录,通常是 INVOKEAIROOT 中名为outputs 的目录。
除了这三个元素外,右上角还有一系列用于更改全局设置、报告错误和更改主题的图标。
控制面板左侧还有一系列图标(请参阅下面屏幕截图中的突出显示区域),这些图标在一系列选项卡中进行选择,以执行不同类型的操作。
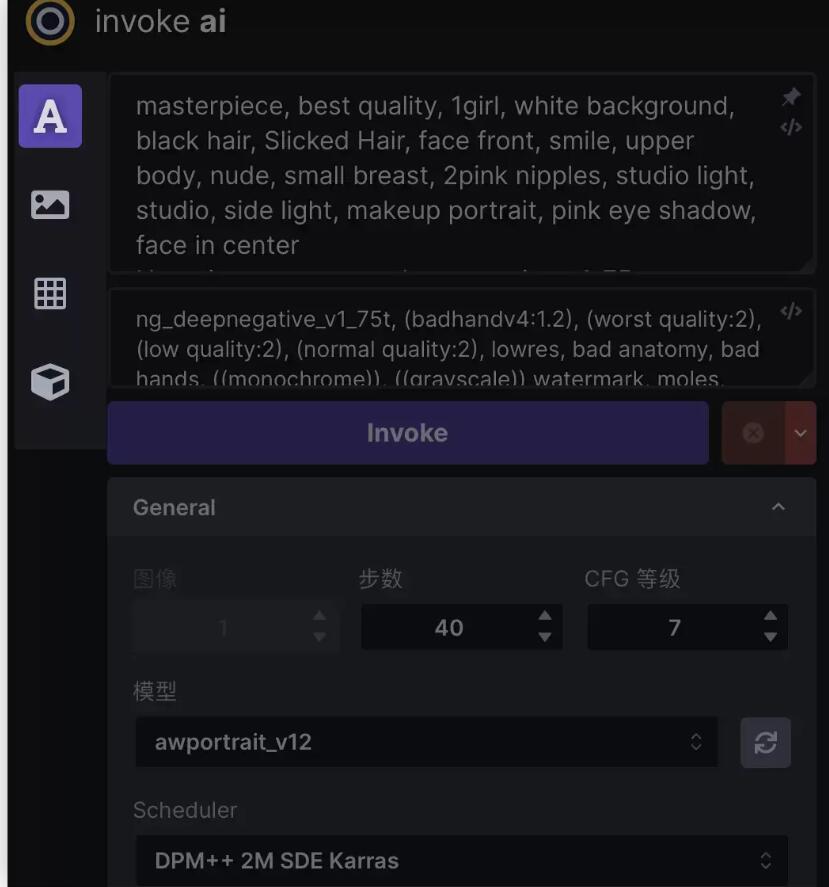
从上到下,这些是:
文本到图像-从文本生成图像
图像到图像-从上传的起始图像(绘图或照片)生成一个新的图像,由文本提示进行修改
统一画布-交互式组合多个图像,用外绘扩展它们,用内绘修改图像的内部部分,擦除起始图像的部分,并让AI从文本提示符填充擦除的区域。
节点编辑器-(实验性)此面板允许您创建常见操作的管道,并将其合并到工作流程中。
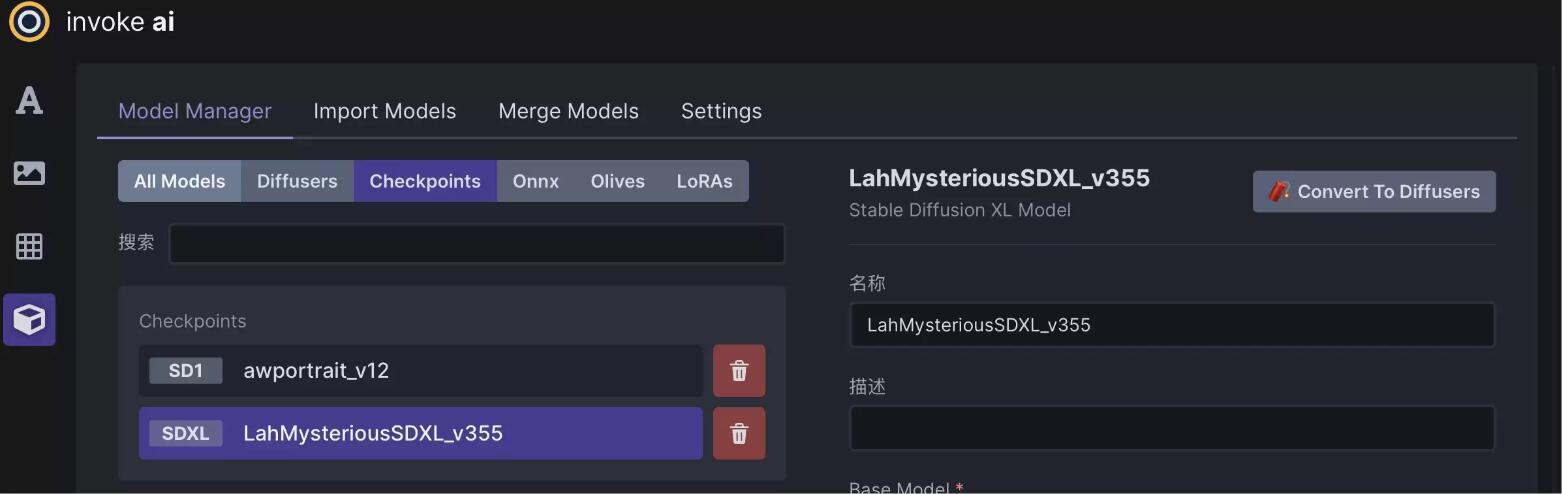
模型管理器-此面板允许您使用URL、本地路径或HuggingFace diffusers repo_ids导入和配置新模型。
功能栏:文字生成图片:像大多数AI图像生成工具一样,输入文字并产出图片;图片生成图片:类似于垫图功能,基于上传的图片和文字生成对应的图片;画布拓展:先生成较小的图片,然后生成可以自由地拓展你的画布,将图像延展出去。在invokeai中,若硬件合适,这一功能似乎可以延展出无穷的画布。
预计推出:节点:目前正在开发基于节点的图像生成系统。请继续关注有关此惊人功能的更新。后处理:调用 AI 提供了多种后处理功能。图像放大和面部恢复已经在WebUI中可用。您可以从“文本到图像”和“图像到图像”选项卡的“高级选项”菜单访问它们。您还可以使用当前图像显示上方或查看器中的图像操作按钮直接处理图像。不久将发布专用 UI,以促进更高级的后处理工作流程。Invoke AI 命令行界面提供了各种其他功能,包括 Embiggen。训练:一个专用的工作流程,用于从 Web 界面使用文本反转和 Dreambooth 训练您自己的嵌入和检查点。InvokeAI 已经支持使用主脚本使用文本反转来训练自定义嵌入。
2.自动模型安装(需梯子):
有两种方法可以安装和管理模型:
invokeai-model-install脚本将为您下载并安装它们。除了支持主要模型外,您还可以安装ControlNet、LoRA和文本反转模型。
Web界面(WebUI)有一个用于导入和管理模型的GUI。
通过将模型(或模型的符号链接)放置在InvokeAI根目录的autoimport文件夹之一中(主要方法)。
通过安装invokeai-model-install
从invoke启动器中,选择选项[5]“下载并安装模型”。这将启动相同的脚本,提示您在安装时选择模型。您可以使用它来添加您第一次跳过的模型。可以指定之前下载的模型;脚本只会确认文件是否完整。
安装程序有不同的面板,用于安装来自HuggingFace的主要模型、来自Civitai和其他任意网站的模型、ControlNet模型、LoRA/LyCORIS模型和文本反转嵌入。每个部分都有一个文本框,您可以在其中输入要安装的新模型。您可以使用其参考模型:
本地机器上.ckpt、.safetensors或扩散器文件夹的本地路径
计算机上包含多个模型的目录
指向可下载模型的URL
A HuggingFace repo id
以前安装的型号显示有复选框。取消选中复选框以从InvokeAI取消注册模型。物理安装在InvokeAI根目录中的模型将被删除和清除(在确认警告后)。位于InvokeAI根目录之外的模型将被取消注册,但不会被删除。
注意:安装程序脚本使用基于控制台的文本界面,需要大量的水平和垂直空间。如果显示器看起来乱七八糟,只需放大终端窗口和/或重新启动脚本。
手动安装模型
请执行以下操作:
在模型网站下载需要的模型。
放到对应的路径。
刷新模型窗口,选择对应模型即可。
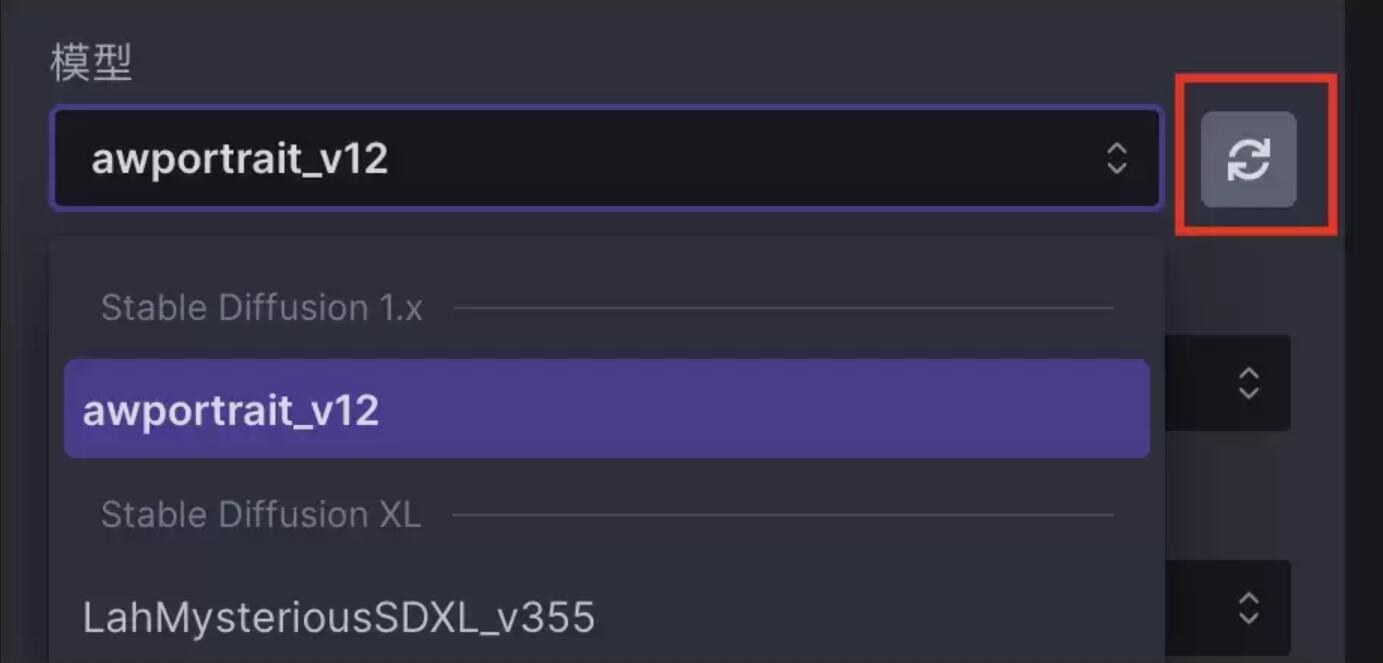
模型仓库
常见的模型下载仓库为以下几种,点击可直接前往仓库地址:
HuggingFace:Stable Diffusion、ControlNet的官方仓库。
Civitai:里面多是Lora或其它NSFW等模型的仓库。
Discord:公共聊天软件,如果有需要可行前往搜索相应频道。
四比三备份站:国内备份模型和参考图的网站,可以直接下载。
Reddit:公共交流社区,如果有需要可行前往搜索相应频道。
在HuggingFace仓库中下载所需的模型时,将会看到各种各样格式的文件。对于一般的使用者来说,仅下载常用CKPT格式模型文件即可。
模型种类
1. sdxl (Stable Diffusion XL)
描述:Stable Diffusion XL (SDXL) 是最新的图像生成模型,专为生成更真实、细节更丰富的图像而设计。
特点:
更真实的图像:与之前的模型相比,SDXL可以生成更真实的图像,特别是在面部生成方面。
可读的文本:SDXL与其他AI图像生成模型的最大区别是它可以生成可读的文本。
更好的人体解剖:之前的SD模型在生成正确的人体解剖方面存在问题。SDXL在一定程度上修复了这个问题。
艺术风格:SDXL为图像生成提供了多种艺术风格。
更短的提示:与之前的模型相比,SDXL更好地理解短提示。
改进的构图:增强的图像构图允许为几乎任何类型的提示创建令人惊叹的视觉效果。
2. sdxl-refiner
描述:这可能是与sdxl模型相关的微调或细化模型,用于进一步优化生成的图像。
特点:
图像优化:可能用于进一步细化和改进sdxl生成的图像,提高图像的质量和真实感。
特定场景调整:可能用于特定的场景或需求,以满足用户的特定要求。
3. SD 1.5 (Stable Diffusion 1.5)
描述:SD 1.5是Stable Diffusion的一个早期版本,它的开源时间较早,因此相应的生态已经建立起来。大部分人目前都是基于SD 1.5进行finetune模型。
特点:
生成效果稳定。
生态丰富,有许多配套的基底模型、LoRA模型以及插件。
学会使用SD 1.5基本上也就等于会用SD 2.1。
4. SD 2.1 (Stable Diffusion 2.1)
描述:SD 2.1是Stable Diffusion的一个更新版本,其生成效果相对于1.5有所提升,但并没有带来质的飞跃。
特点:
初级技术:在sd-2.1和sdxl之前的技术,可能在多个方面都不如后续版本。
基础应用:可能主要用于基础的图像生成任务,没有太多的高级功能。
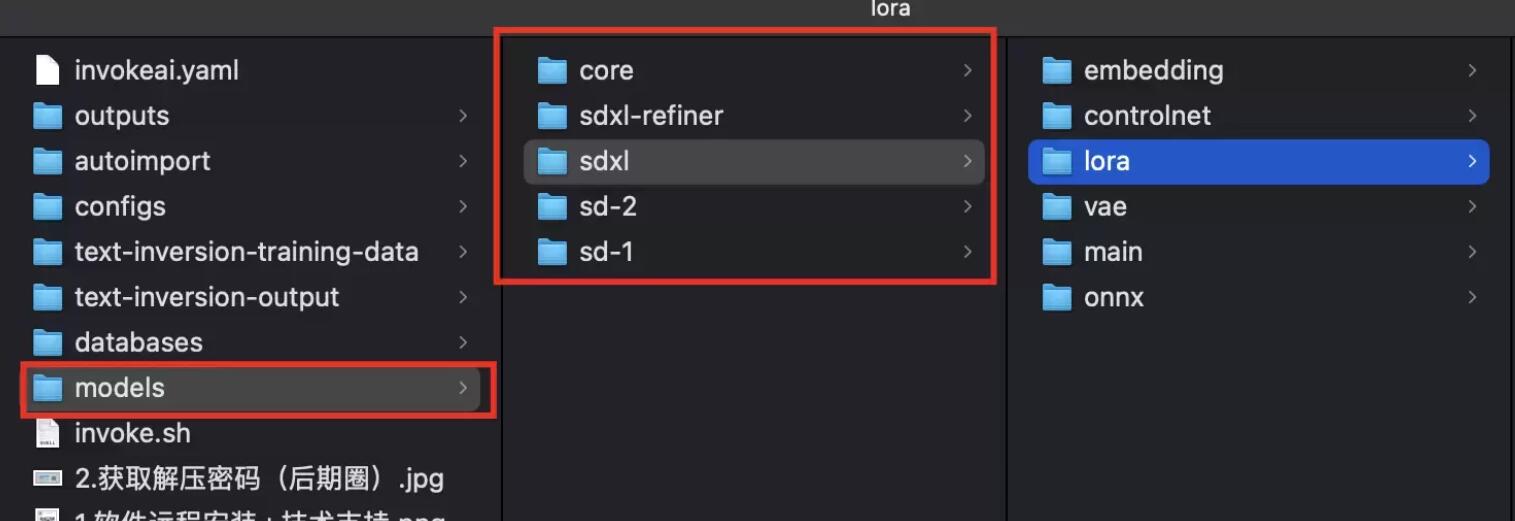
模型存放路径
请先确定您下载的是SD1.5还是SDXL模型,在根据不同类型存放在不同位置。
1. 大模型
描述:大模型特指标准的latent-diffusion模型,拥有完整的TextEncoder、U-Net、VAE。由于训练大模型需要高显卡算力,所以许多人选择训练小型模型。
CKPT
描述:CKPT格式的全称为CheckPoint(检查点),是完整模型的常见格式一般扩展名:.ckpt或.safetensors。
文件大小:一般在7GB左右。
文件位置:*\InvokeAI\models\*\main目录内。
2. 小模型
描述:小模型是截取大模型的某一特定部分,虽然不如大模型那样完整,但在生成特定内容时效果更佳。
常见微调模型:Textual inversion (Embedding)、Hypernetwork、VAE、LoRA等。
VAE (Variational autoencoder)
Embedding
3. LoRA
LoRA是什么?
如果说模型是一大包食材,那 LoRA 可以理解为一个调料包。通过一些简单的学习,您可以批量生成想要的图案、姿势、情境等等。
比如我们想用自己的孩子做主角生成图片,那么通过制作孩子的 LoRA,就可以在 Prompt 中用一个命令调用,从而获得孩子的图片。
另外,由于有许多不同的 LoRA 可供使用,因此可以轻松地尝试各种有趣的图片生成。
LoRA 有很多种类型,看起来很复杂?
LyCORIS,LoHa,LoRA,LoCon,(IA)^3,LoKR,DyLoRA 等等,是什么意思!
其实这些是微调技术的分类和其算法。
LoRA、LyCORIS、LoCon是一些技术项目的名称。
LoCon 已被 LyCORIS合并,过去需要的扩展 LoCon 现在不再需要,只需安装 LyCORIS 的扩展即可。 LoHa,(IA)^3,LoKR,DyLoRA 是 LyRORIS 的学习算法之一。在算法学习时指定使用。 这些基本上在使用时不需要担心,但是如果要使用LyCORIS和LoCon学习的LoRA,则需要注意使用LyCORIS专用的扩展程序(稍后会提到)
描述:LoRA模型有基础模型和变体两种。
使用方法:在首页界面下图标 ->Lora选项卡。基础模型:
名称:一般为chilloutmix*。
后缀:safetensors或CKPT。
文件位置:*\InvokeAI\models\*\Lora目录内。
模型后缀解析
描述:风格模型,针对一个风格或主题。
常见格式:pt、png、webp。
使用方法:加载对应Embedding模型,在Prompt中使用对应TAG。
文件位置:*\InvokeAI\models\*\embeddings目录内。
描述:变分自编码器,将潜空间的数据转换为正常图像。影响出图的色彩和细节。
后缀格式:.pt
使用方法:设置 -> 模型的 VAE (SD VAE)。
文件位置:*\InvokeAI\models\*\VAE目录内。
格式描述
.ckptPytorch的标准模型保存格式,容易遭受Pickle反序列化攻击。
.ptPytorch的标准模型保存格式,容易遭受Pickle反序列化攻击。
.pthPytorch的标准模型保存格式,容易遭受Pickle反序列化攻击。
.safetensorssafetensors格式可与Pytorch的模型相互格式转换,内容数据无区别。
其它webui 特殊模型保存方法:PNG、WEBP图片格式。
Safetensors格式
Safetensors格式所生成的内容与ckpt等格式完全一致(包括NFSW)。
Safetensors格式拥有更高的安全性,
Safetensors比ckpt格式加载速度更快
该格式必须在2023年之后的Stable Diffusion内才可以使用,在此之间的SD版本内使用将无法识别。
Safetensors格式由Huggingface推出,将会逐渐取代ckpt、pt、pth等格式,使用方法上与其它格式完全一致。
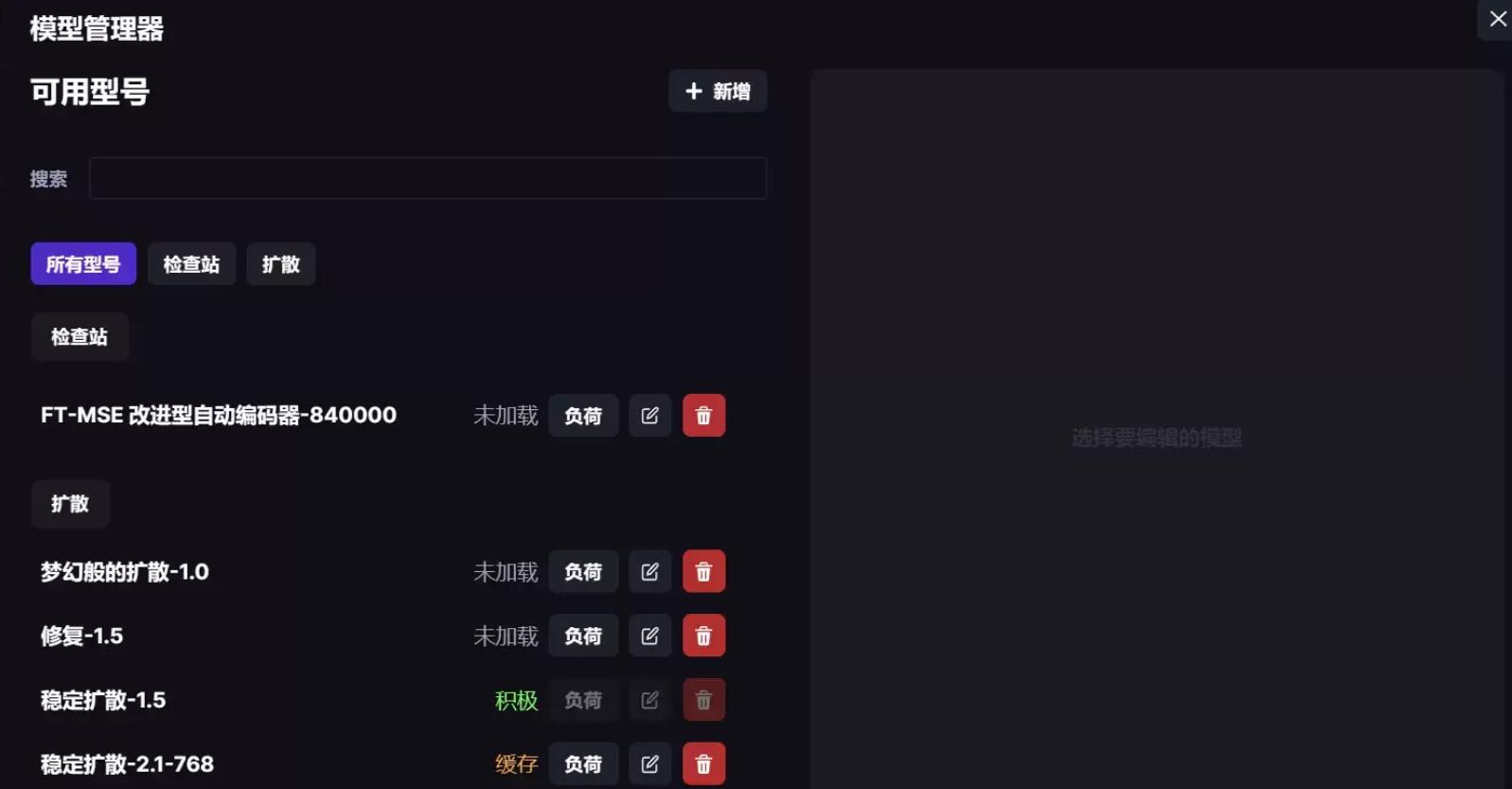
2、特点功能
invokeAI中拥有大部分的基本AI绘画生成功能,例如文生图,图生图、种子值、放大图像等等,下面拿了invokeAI的一些特别的功能进行了测评。不过invokeAI中的功能虽然在界面中都可以调节,但是如果当前使用的模型算法不支持,可能会不起作用。
面部修复:
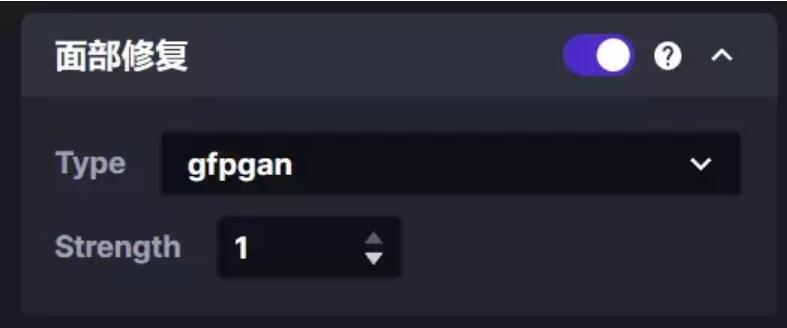
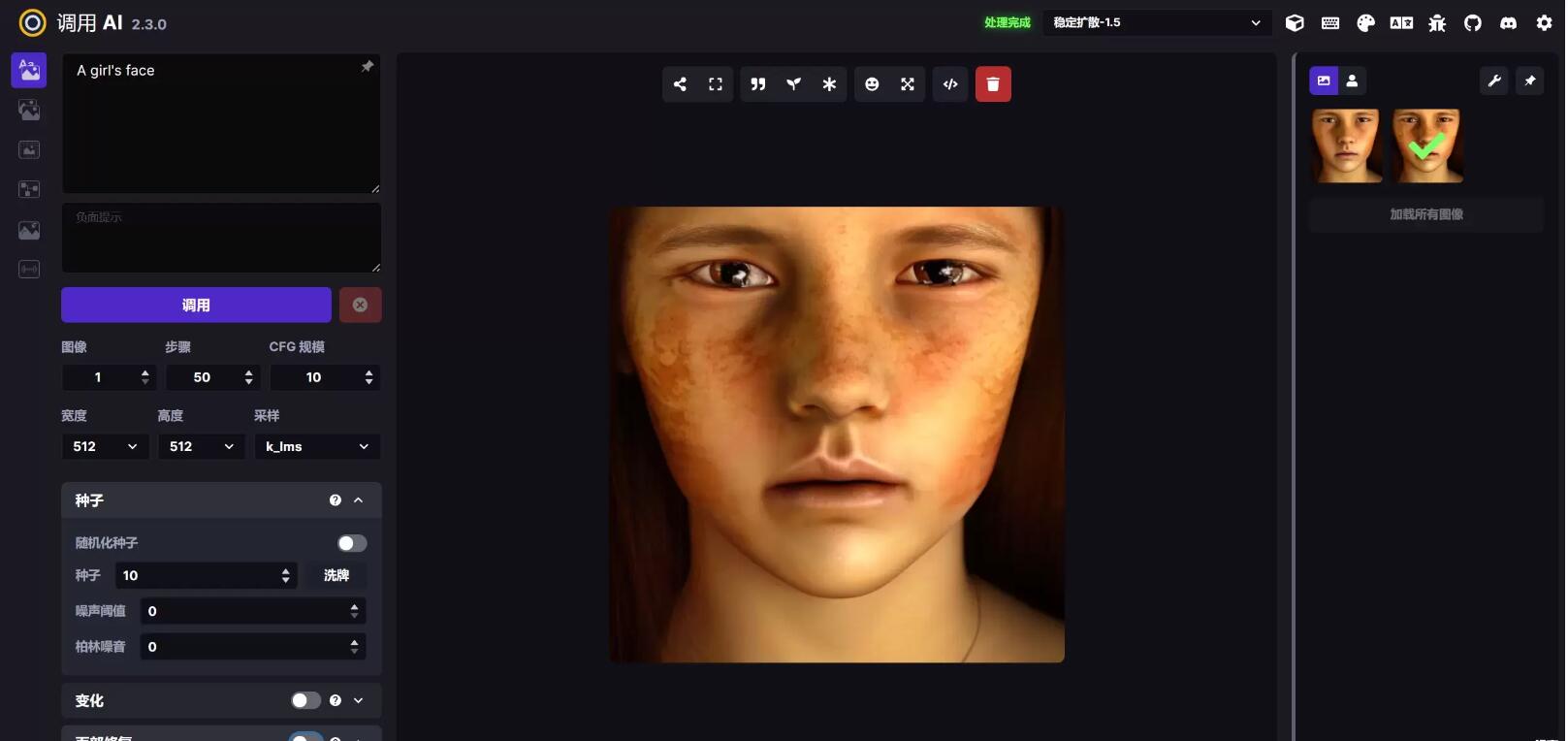
其中Strength表示修复强度:值范围从0到1,范围内值越高修复效果越强;下面两张是多组测试中效果较明显的一组,他们有相同的种子值,关键词为“A girl’s face”:第一张,没有打开面部修复时的生成效果:
打开面部修复后:
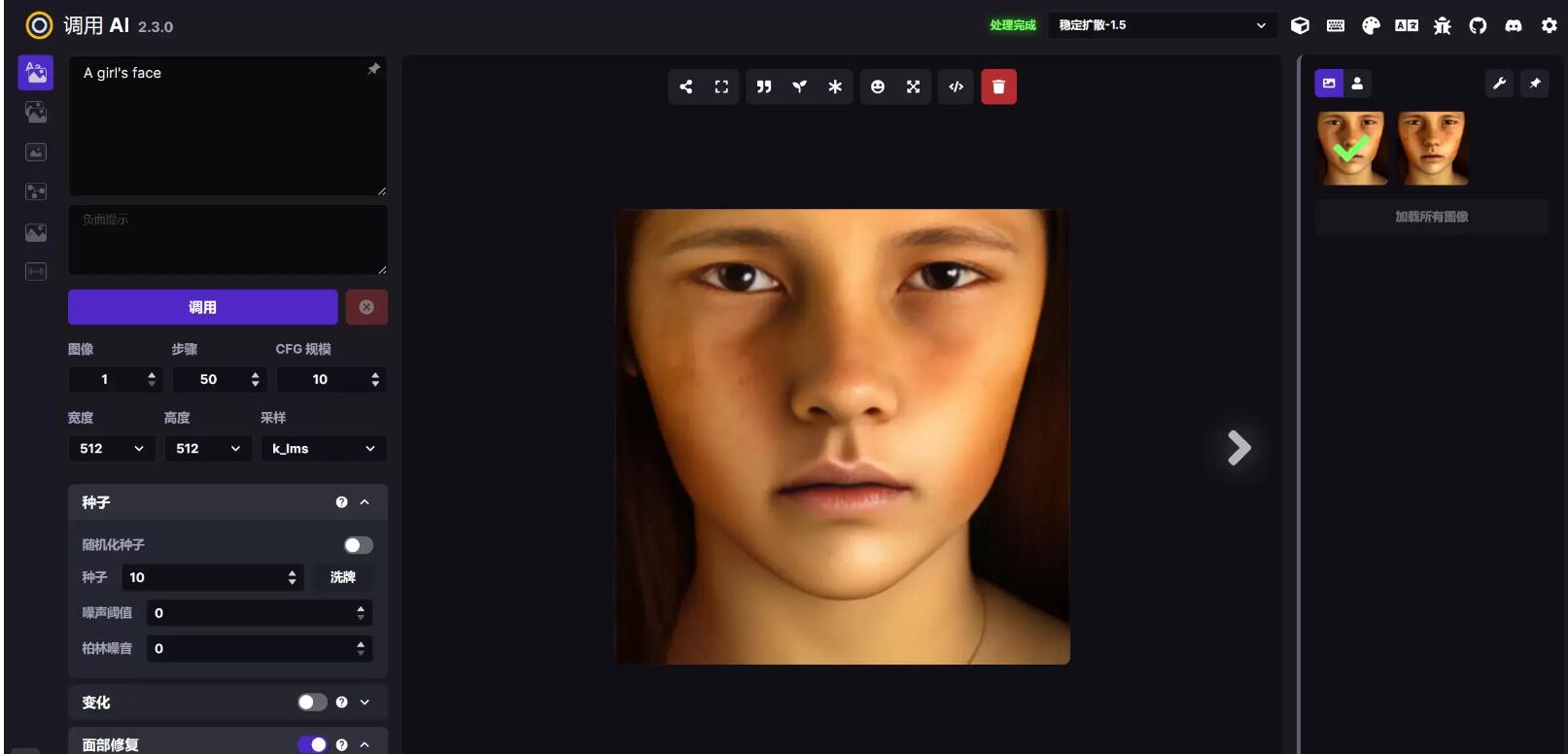
这一功能主要是略微优化脸部结构,同时图片的锐度下降,并产生一定的磨皮、平滑效果。画布拓展:几乎可以将画布无限延展,这是这个功能最吸引人的特点。你可以在这个界面里自定义延展框的大小、比例、甚至创建遮罩等,将你原来的模型进行放大:
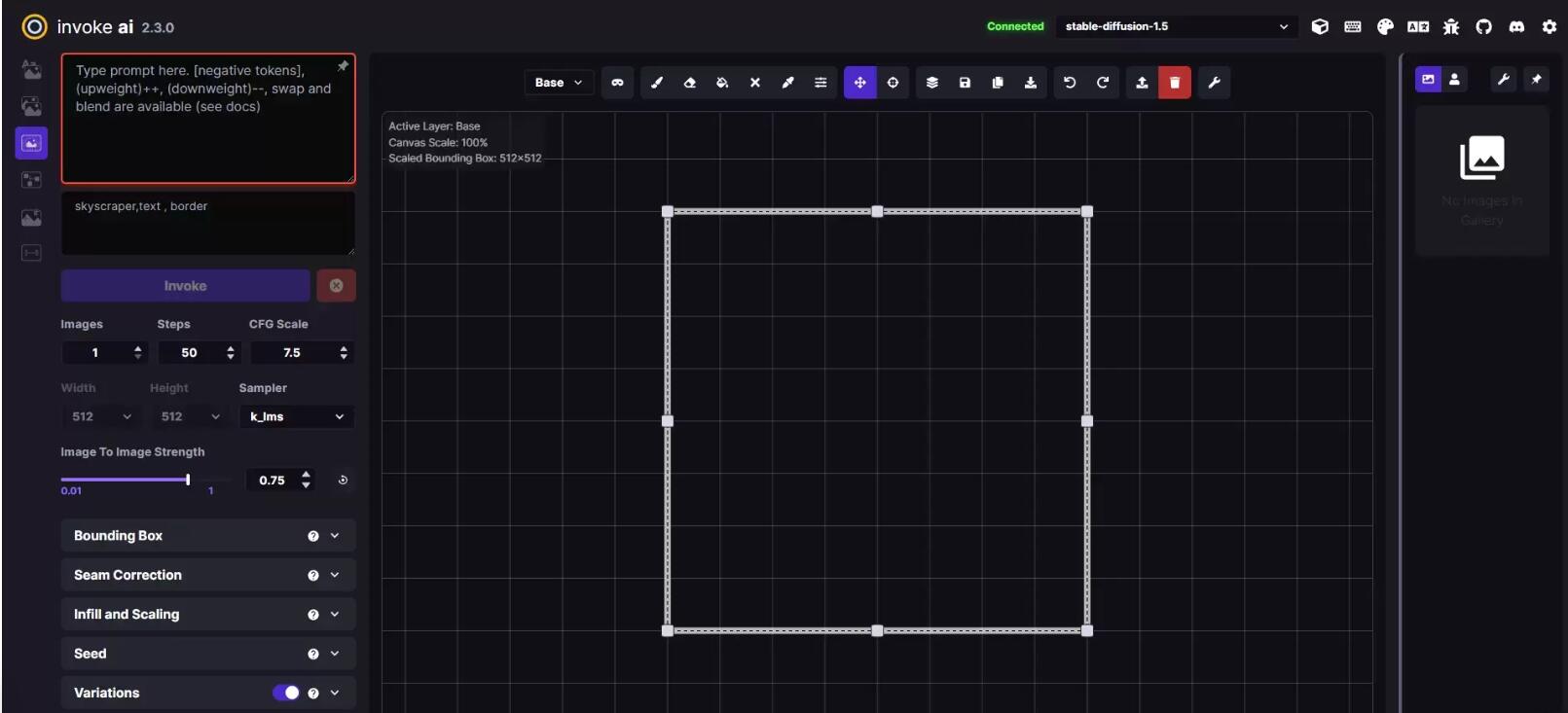
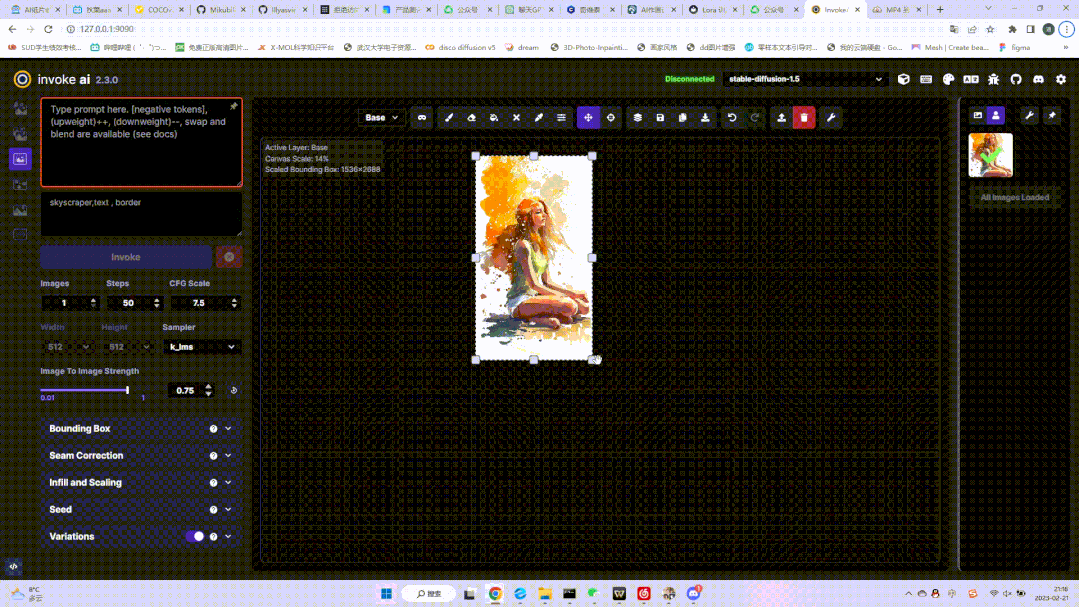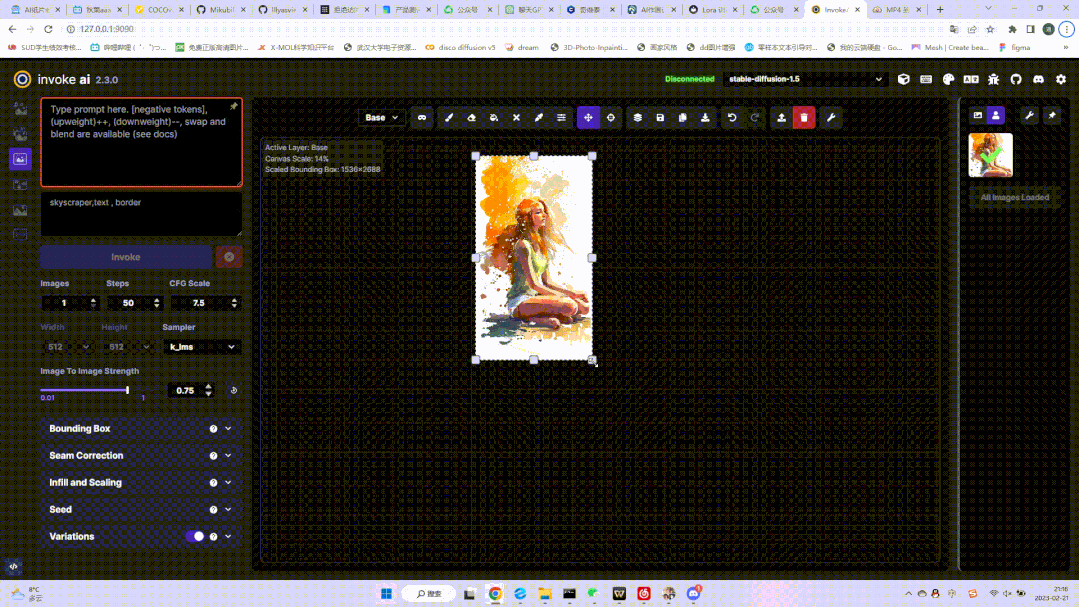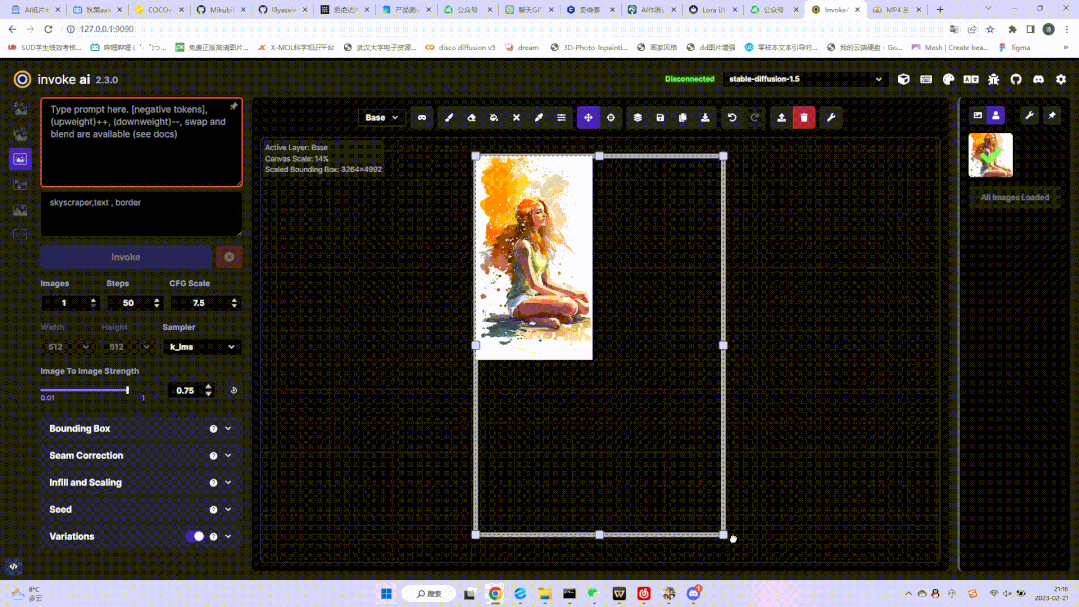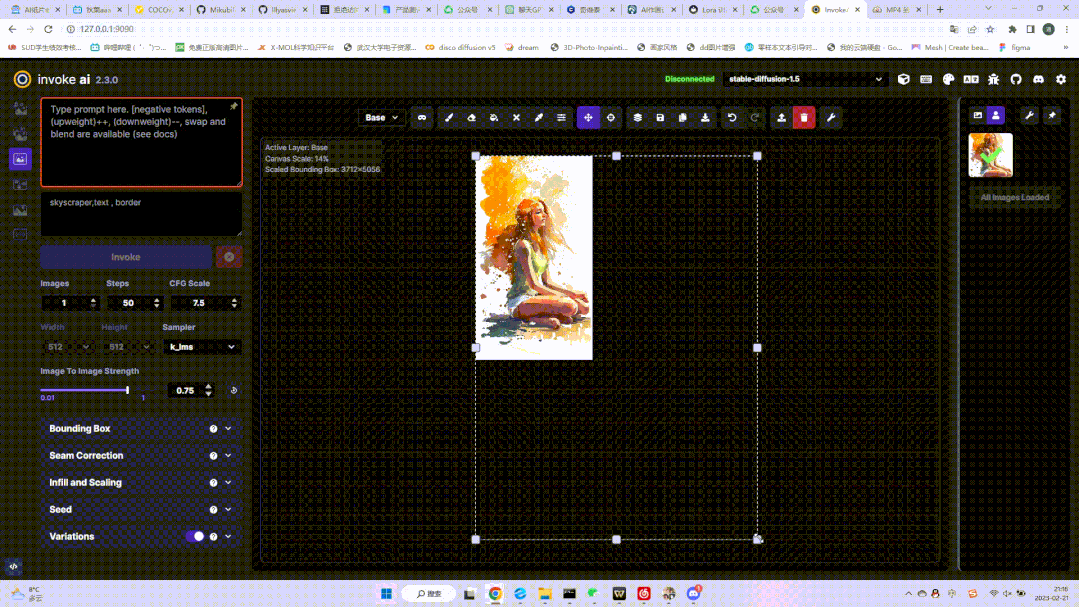
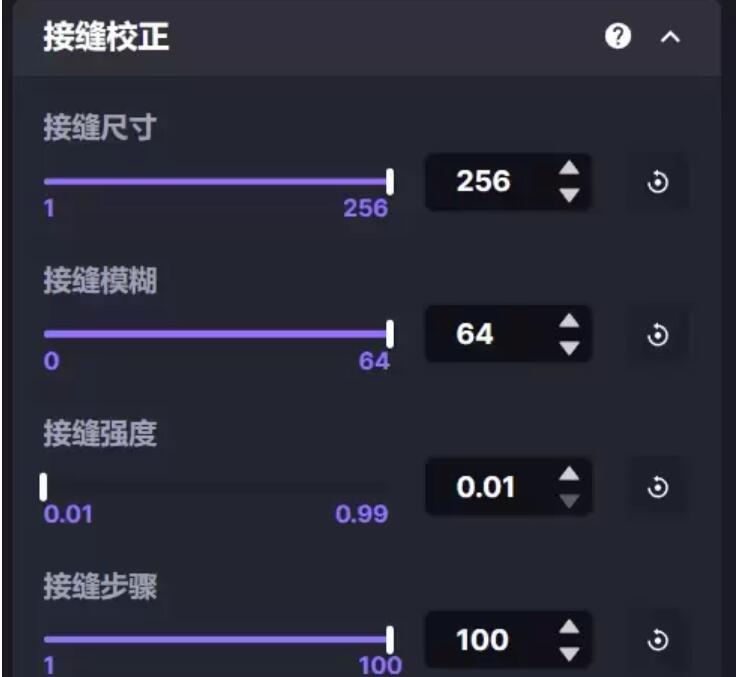
考虑到每次图像拓展可能会产生接缝线,官方在左侧的调节栏里设置了接缝校正功能如下,但是模型不同,这个调节的效果也会不同:
二、对比其他模型的优劣势
invokeAI主要是基于开源模型的界面设计,它与著名的非开源AI图像生成模型midjourney相比,有哪些优缺点呢?在进行大量的出图时,midjourney采用的是上下滚动的翻阅设计,而invokeAI采用的是将图片集中放在右侧栏中的设计,invokeAI在直接选取之前的图像上更加方便。invoke将所有的图像集中右侧:
midjourney的滚动浏览:
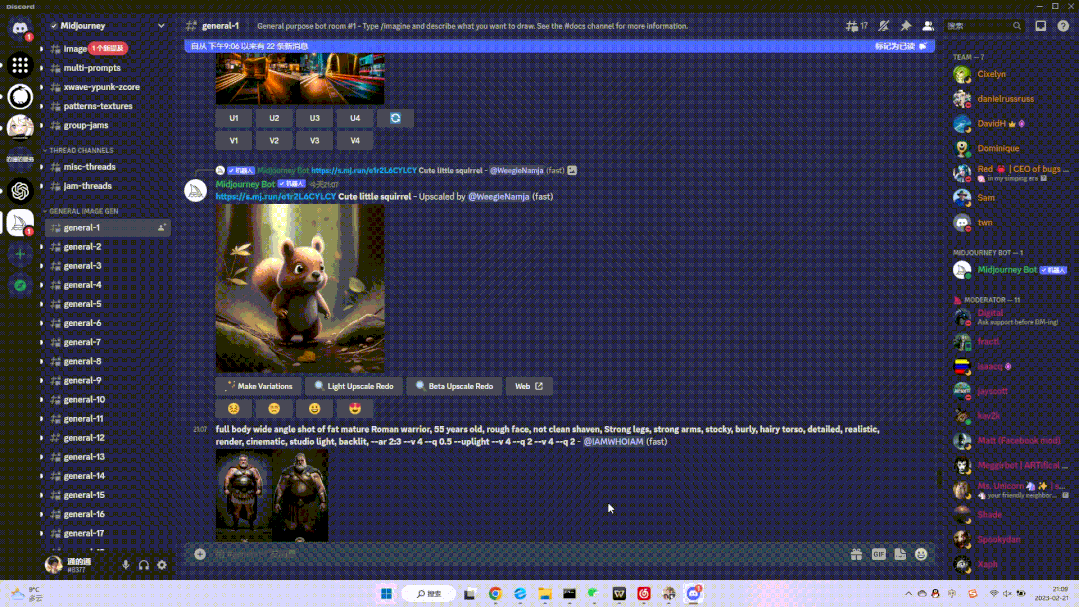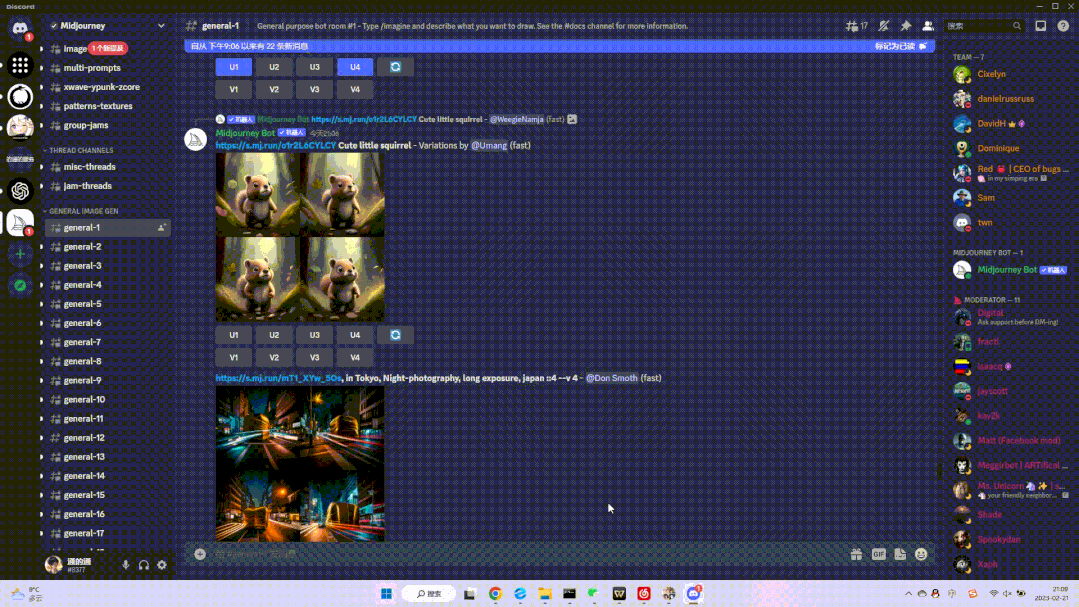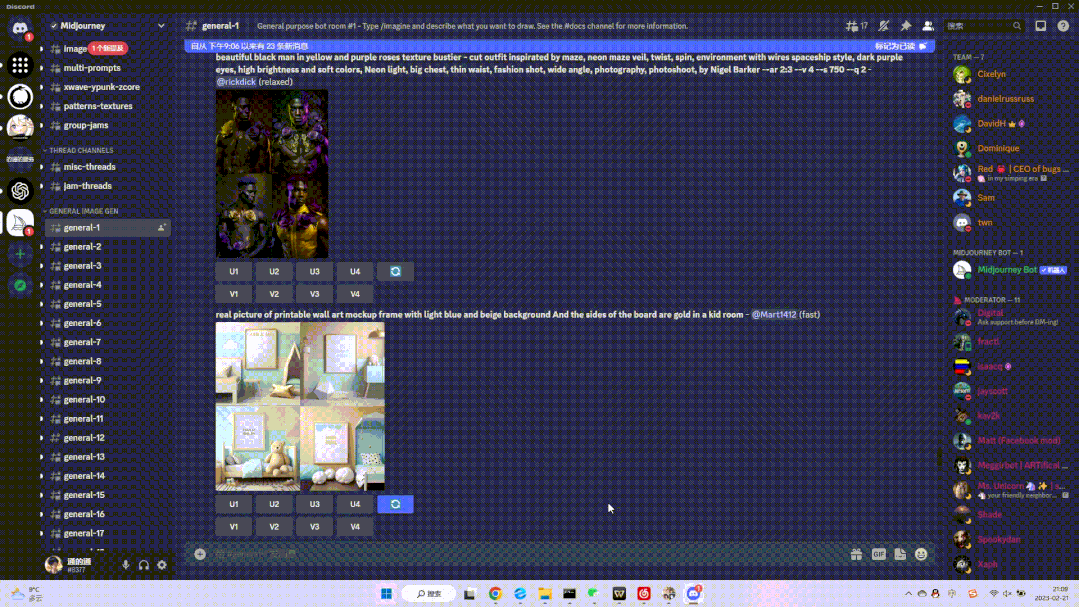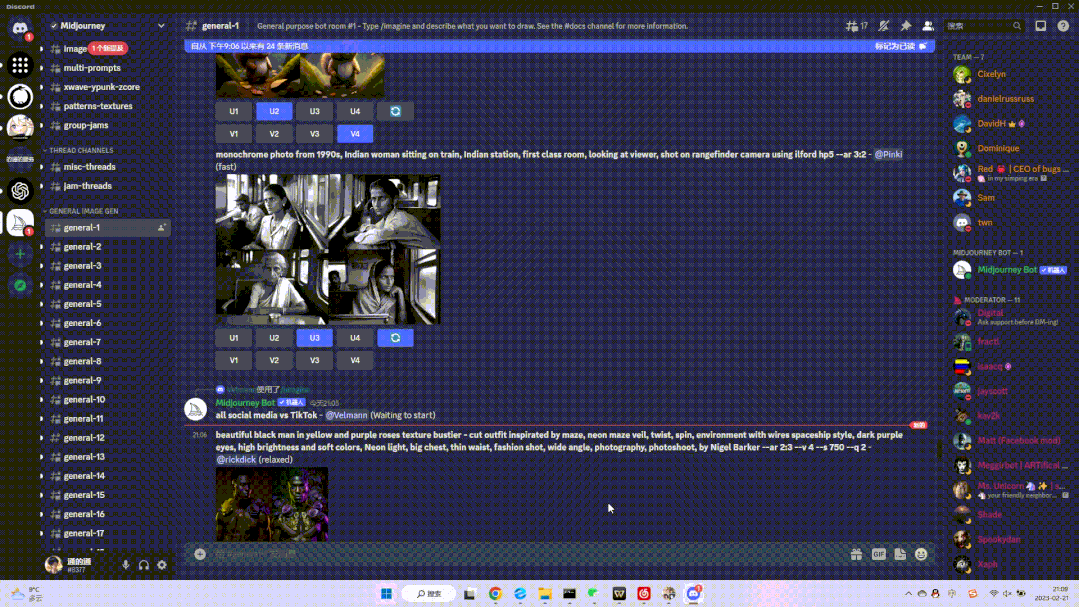
在对于生成的一些微调功能方面,midjourney需要在输入框中将所有的指令通过指定格式表达出来,但是invokeAI采用了部分使用滑块等调节的方式,交互方式更加直观便捷。同时有的开源模型没有较为完善的界面设计,对于编程基础较弱的用户不是很友好。但是如果将模型导入invokeAI,就可以在统一的界面中使用模型,也节省了熟悉新模型的时间。invokeAI在每个功能按钮旁都有一个小问号,鼠标停留时会有详细的功能说明,这是非常人性化的交互体验。例如invokeAI中对种子值的说明:

相比于midjourney,invokeAI将文生图、图生图、画布拓展三个大功能拆分开并将其作为主结构向下细分的结构设计也是不错的,相对应的功能在颜色上也做出了区分。但在图片储存上midjourney使用频道的方式,在进行图片分类、储存方面更加完善,可以将不同的图片分配到不同的频道内进行储存,目前invokeAI还没有将图片分类储存的功能。midjourney丰富的频道系统:
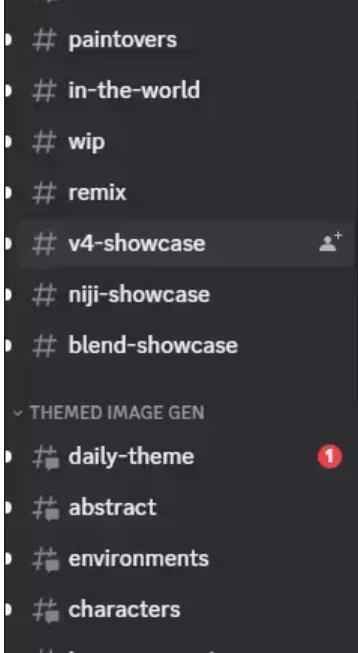
在社交属性上,midjourney能更快地直达社区和看见他人生成的内容,invokeAI更像单独使用的工具。
对于一般开源软件同样地,下面两张界面图对比,相比stable diffusion比较单调并且没有功能说明,invokeai使用起来更人性化:
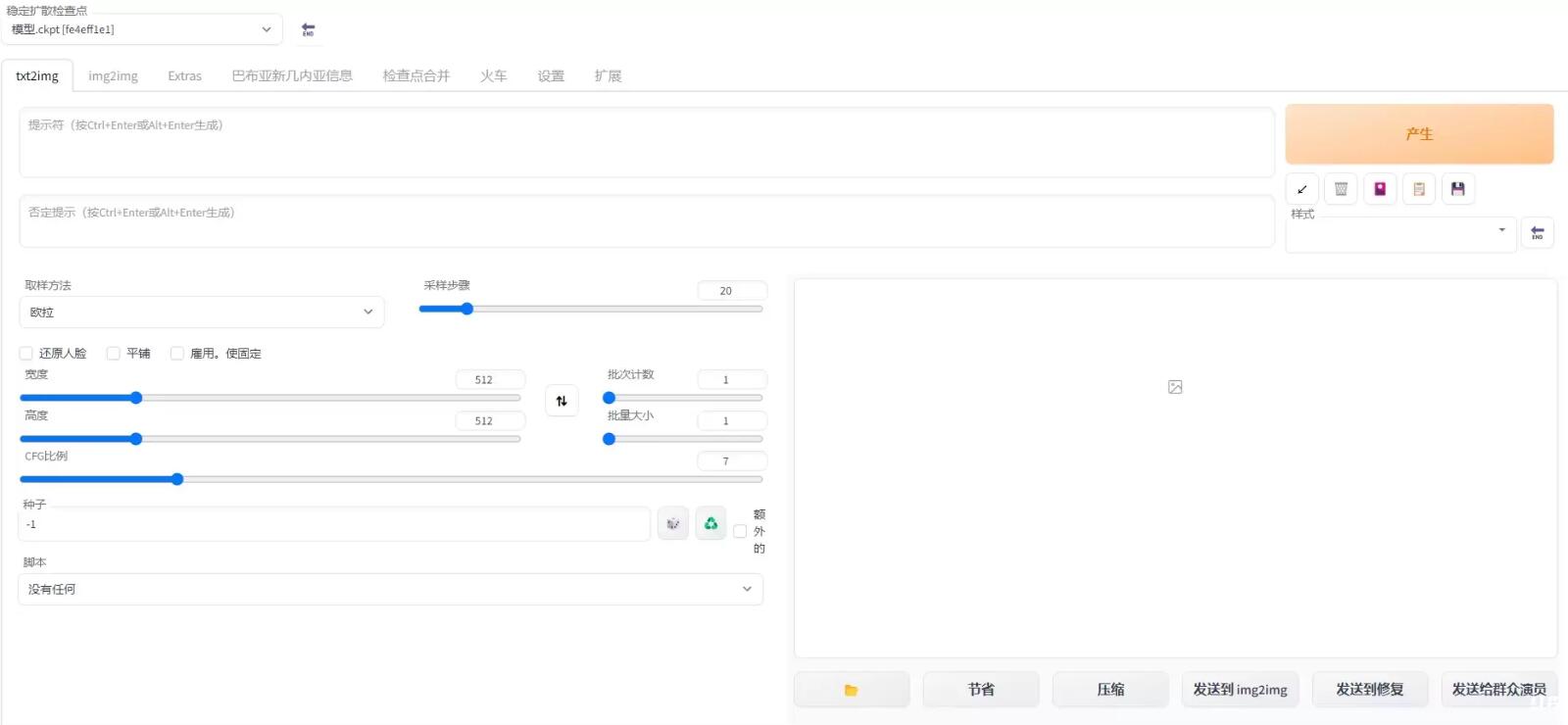
对于本地配置要求来说,相比midjourney完全云端的优势,invokeIA安装对于本地配置的要求较高。而且目前为止使用invokeai的成员较少,网上相对应的使用教程也比较少,需要根据官方说明书一步步执行。invokeAI下载时携带了五个模型包,占用很大的内存,并且运行在本地对于显卡的要求也比较高,有条件可以尝试在云端服务器运行。
统一UI在提供便利的同时也会带来一些缺点,固定的UI界面可能无法完全适配自定义模型的功能。而且invoke目前功能比较基础,如果可以自定义增加调节模块并出相应的官方教程就更好了。
 chrome下载
chrome下载 知乎下载
知乎下载 Kimi下载
Kimi下载 微信下载
微信下载 天猫下载
天猫下载 百度地图下载
百度地图下载 携程下载
携程下载 QQ音乐下载
QQ音乐下载