

Constme-Whisper(离线语音识别转文字) v1.12 绿色免费版(含完整模型)
- 大小:4.9GB
- 分类:音频处理
- 环境:Windows
- 更新:2023-07-24
热门排行












简介
Constme-Whisper是一款本地离线语音转文字工具,支持 GPU、支持实时语音转换。Whisper是由 OpenAI 训练并开源的神经网络,在英语语音识别方面的稳健性和准确性接近人类水平whisper.cpp 项目是将 Whisper 移植到 C/C++ 中,而今天介绍的 Const-me/Whisper 项目则是 whisper.cpp 在 Windows 上的实现,并增加了显卡的支持,使得速度大幅提升。欢迎需要此款工具的朋友前来下载使用。
软件介绍
Constme-Whisper是OpenAI的Whisper自动语音识别ASR模型的衍生项目。
Constme-Whisper可以在Windows上使用,支持高性能GPGPU处理,可以利用GPU加速处理。
本体是个启动器,需要结合一个语言识别模型文件(ggml-tiny、ggml-small、ggml-base、ggml-medium、ggml-large)使用,模型越大,效果越好,但相对的速度也更慢。
软件特点
基于DirectCompute的与供应商无关的GPGPU;该技术的另一个名称是“Direct3D 11 中的计算着色器”
纯C++实现,除了基本的操作系统组件外,没有运行时依赖关系
比OpenAI的实现快得多。
混合 F16 / F32 精度:Windows 需要自 D3D 版本 10.0 起支持缓冲区R16_FLOAT
内置性能探查器,用于测量单个计算着色器的执行时间
内存使用率低
用于音频处理的媒体基础,支持大多数音频和视频格式(Ogg Vorbis除外), 以及大多数在Windows上运行的音频捕获设备(除了一些专业设备,它们只实现ASIO API)。
用于音频捕获的语音活动检测。
易于使用的 COM 样式 API,nuget 上提供的惯用 C# 包装器
提供预构建的二进制文件
下载 Whisper 模型
而 Const-me 的这个名为 Whisper 的项目,目前仅提供 Windows 版本,使用简单,需要先下载模型:
开发者推荐 ggml-medium.bin,因为一直在使用这个模型进行测试,1.53 GB 大小。
使用 Whisper
在 Model Path 里面选择你下载的模型,然后选择 GPU 就能进入软件了。
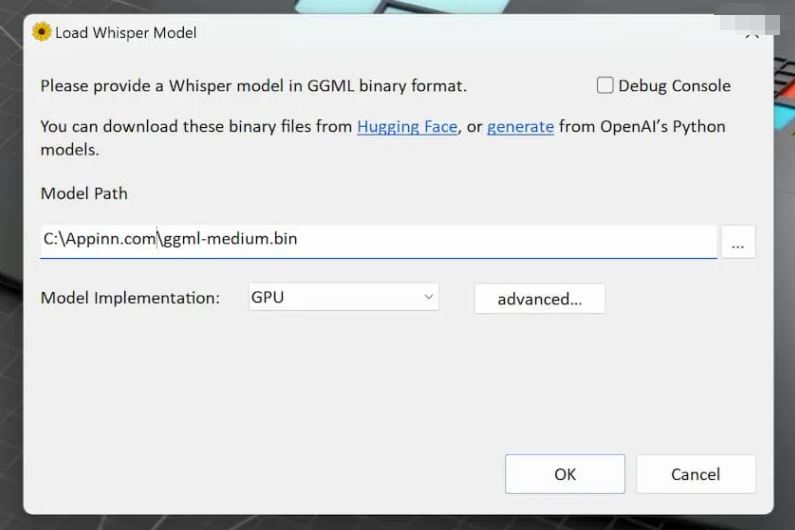
之后,就可以选择通过麦克风实时转换,或者使用音频文件比如 MP3 来转换为文字了:
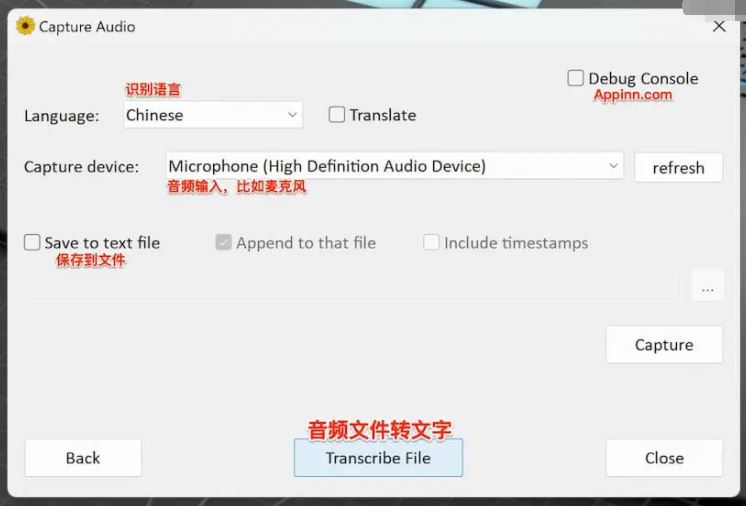
青小蛙随便测试了一个极客湾的视频(仅下载了音频),效果如下:
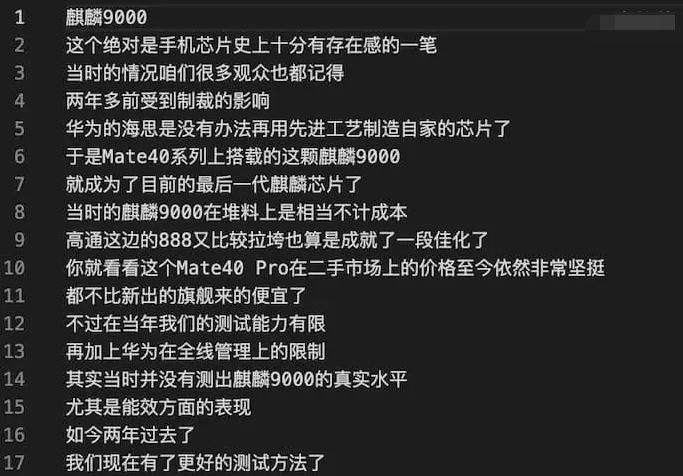
准确度很高,基本上比较满意。
由于是在虚拟机中测试,显卡性能有限,所以时间不具有参考性。
不过,开发者的测试是在装有 GeForce 1080Ti GPU 的台式电脑上,中型模型,3 分 24 秒语音使用 PyTorch 和 CUDA 转录需要 45 秒,但使用这个和 DirectCompute 只需要 19 秒。而 @JoeCubber 同学测试的是 11:31 分钟的音频,耗时1分26秒完成。
当然,你需要有显卡。
实在是没想到,挖矿之后,显卡又有了用武之地。
更新日志
更新了文档和 GUI 中的模型源 URL
可靠性增强,麦克风捕获不太可能转换到“停滞”状态并丢弃音频
注意:
需要不低于Win8.1的64位Windows
文件main.exe为命令行调用工具
 chrome下载
chrome下载 知乎下载
知乎下载 Kimi下载
Kimi下载 微信下载
微信下载 天猫下载
天猫下载 百度地图下载
百度地图下载 携程下载
携程下载 QQ音乐下载
QQ音乐下载