
PaddleX 飞桨全流程开发工具 v3.1.0
- 大小:1.77MB
- 分类:其它源码
- 环境:Python
- 更新:2025-06-29
热门排行












简介
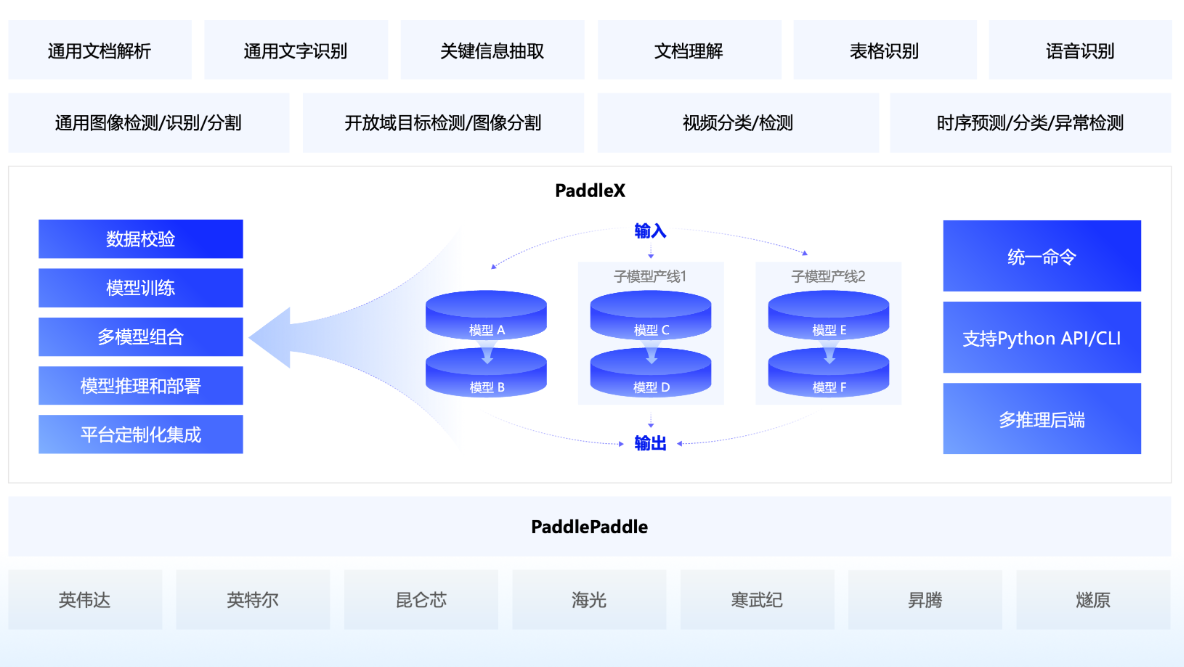
PaddleX -- 飞桨全流程开发工具,以低代码的形式支持开发者快速实现产业实际项目落地。
PaddleX 集成飞桨智能视觉领域图像分类、目标检测、语义分割、实例分割任务能力,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,并提供统一任务API接口及图形化开发界面Demo。开发者无需分别安装不同套件,以低代码的形式即可快速完成飞桨全流程开发。
PaddleX 经过质检、安防、巡检、遥感、零售、医疗等十多个行业实际应用场景验证,沉淀产业实际经验,并提供丰富的案例实践教程,全程助力开发者产业实践落地。
安装:
PaddleX提供三种开发模式,满足用户的不同需求:
1、Python开发模式:
通过简洁易懂的Python API,在兼顾功能全面性、开发灵活性、集成方便性的基础上,给开发者最流畅的深度学习开发体验。
前置依赖
paddlepaddle >= 1.8.4
python >= 3.6
cython
pycocotools
pip install paddlex -i https://mirror.baidu.com/pypi/simple
详细安装方法请参考PaddleX安装
2、Padlde GUI模式:
无代码开发的可视化客户端,应用Paddle API实现,使开发者快速进行产业项目验证,并为用户开发自有深度学习软件/应用提供参照。
前往PaddleX官网,申请下载PaddleX GUI一键绿色安装包。
前往PaddleX GUI使用教程了解PaddleX GUI使用详情。
PaddleX GUI安装环境说明
3、PaddleX Restful:
使用基于RESTful API开发的GUI与Web Demo实现远程的深度学习全流程开发;同时开发者也可以基于RESTful API开发个性化的可视化界面
前往PaddleX RESTful API使用教程
PaddleX 更新日志:
v3.1.0版本,新增PP-OCRv5种多语种文字识别模型和文档翻译产线,优化PP-StructureV3中的PP-Chart2Table模型:
重要模型:
新增PP-OCRv5多语种文本识别模型,支持法语、西班牙语、葡萄牙语、俄语、韩语等37种语言的文字识别模型的训推流程。平均精度涨幅超30%。
升级PP-StructureV3中的PP-Chart2Table模型,图表转表能力进一步升级,在内部自建测评集合上指标(RMS-F1)提升9.36个百分点(71.24% -> 80.60%)
重要产线:
新增基于PP-StructureV3和ERNIE 4.5 Turbo的文档翻译产线PP-DocTranslation,支持翻译Markdown文档、各种复杂版式的PDF文档和文档图像,结果保存为Markdown格式文档。
修复和优化3.0.0版本的部分问题,升级修复点如下:
优化部分模型和模型配置:
PP-OCRv5默认模型配置,检测和识别均改为server模型。为了改善大多数的场景默认效果,配置中的参数limit_side_len由736改为64
新增PP-LCNet_x1_0_textline_ori模型,精度99.42%,OCR、PP-StructureV3、PP-ChatOCRv4产线的默认文本行方向分类器改为该模型
优化PP-LCNet_x0_25_textline_ori模型,精度提升3.3个百分点,当前精度98.85%
优化和修复部分问题:
修复由于公式识别、表格识别模型无法使用mkldnn导致PP-StructureV3在部分cpu推理报错的问题
修复在部分GPU环境中推理报FatalError: Process abort signal is detected by the operating system错误的问题
修复部分Python3.8环境的type hint的问题
修复默认设备获取逻辑,使程序实际行为与文档中的说明一致。在GPUtil不可用时默认使用CPU,同时支持通过CUDA_VISIBLE_DEVICES环境变量控制使用的默认GPU设备
修复重新安装paddlex whl时,由于历史字体文件未删除引发的安装错误
去除表格识别和表格识别v2产线服务接口中的无效参数
优化使用CPU版本Paddle并试图安装GPU版本高性能推理插件时的错误提示
更新依赖的Paddle2ONNX版本为2.0.2rc3
 chrome下载
chrome下载 知乎下载
知乎下载 Kimi下载
Kimi下载 微信下载
微信下载 天猫下载
天猫下载 百度地图下载
百度地图下载 携程下载
携程下载 QQ音乐下载
QQ音乐下载