
Nodejs 中文分词常用模块用法分析
作者:多比熊
ㅤㅤㅤ
ㅤㅤㅤ
ㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ(生活只有在平淡无味的人看来才是空虚而平淡无味的。 —— 车尔尼雪夫斯基)
ㅤㅤㅤ
ㅤㅤㅤ
ㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ
中文分词器
引用百度的说明 ~~
中文分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂得多、困难得多
- 与英文为代表的拉丁语系语言相比,英文以空格作为天然的分隔符,而中文由于继承自古代汉语的传统,词语之间没有分隔。 古代汉语中除了连绵词和人名地名等,词通常就是单个汉字,所以当时没有分词书写的必要。而现代汉语中双字或多字词居多,一个字不再等同于一个词。
- 在中文里,“词”和“词组”边界模糊
现代汉语的基本表达单元虽然为“词”,且以双字或者多字词居多,但由于人们认识水平的不同,对词和短语的边界很难去区分。
例如:“对随地吐痰者给予处罚”,“随地吐痰者”本身是一个词还是一个短语,不同的人会有不同的标准,同样的“海上”“酒厂”等等,即使是同一个人也可能做出不同判断,如果汉语真的要分词书写,必然会出现混乱,难度很大。
中文分词的方法其实不局限于中文应用,也被应用到英文处理,如手写识别,单词之间的空格就不很清楚,中文分词方法可以帮助判别英文单词的边界
NodeJS中的中文分词器
mmseg-node
https://github.com/zzdhidden/mmseg-node
一个基于 libmmseg 的 NodeJS 驱动
安装流程
sudo apt-get install make gcc g++ automake libtool wget http://www.coreseek.cn/uploads/csft/3.2/mmseg-3.2.14.tar.gz sudo tar zxvf mmseg-3.2.14.tar.gz cd mmseg-3.2.14 ./bootstrap ./configure make && make install npm install mmseg
示例代码
const mmseg = require("mmseg");
const q = mmseg.open('/usr/local/etc/');
console.log(q.segmentSync("我是中文分词"));从该包的下载量和issue的解决程度来看,不推荐使用,很容易碰到问题,而没有得到有效的解决
nseg
https://github.com/mountain/nseg
Chih-Hao Tsai发明的MMSG,一种非常流行的中文分词算法。许多实现可在不同的平台上使用,包括Python,Java等
安装流程
npm install nseg
示例代码
const dict = require('../data/dict'),
freq = require('../data/freq'),
date = require('../lex/datetime'),
sina = require('../lex/sina');
const opts = {
dict: dict,
freq: freq,
lexers: [date, sina],
};
const nseg = require('nseg').normal(opts);
nseg('研究生源计划', (result) => {
console.log(result);
});同mmseg一样,虽然在其他环境(比如Java,Python)有着较为成熟的应用和场景,但包的维护者重心可能不在nodejs上,所以还是不太建议使用…
node-segment
https://github.com/leizongmin/node-segment
以盘古分词组件中的词库为基础, 算法设计也部分参考了盘古分词组件中的算法
具有以下特点
- 纯JavaScript编写,可以在任何支持ECMAScript5的引擎上执行(需要稍微修改部分代码)
- 基于词性进行联想识别
- 可使用JavaScript编写自定义的分词模块
安装流程
npm install segment --save
示例代码
const Segment = require('segment');
const segment = new Segment();
segment.useDefault(); // 载入默认词典
segment.loadDict('test.text'); // 载入字典,详见dicts目录,或者是自定义字典文件的绝对路径
const text = "欢迎来到CSDN开发者博客论坛~~";
console.log(segment.doSegment(text, {
stripPunctuation: true //去除标点符号
}));
定制化示例文件 .text
0x00100000代表16进制的词性,但在返回时转换为了十进制来标识
- 名词 十进制:1048576 十六进制:0x00100000
- 动词 十进制:4096 十六进制:0x00001000
- 机构团体 十进制:20 十六进制:0x00000020
- 时间 十进制:16384 十六进制:0x00004000
- 人名 十进制:128 十六进制:0x00000080
- 标点符号 十进制:2048 十六进制:0x00000800
- …
101代表了这个词语的权重,在后续匹配词语时,若匹配到近似词,则以权重优先匹配
架构师|0x00100000|101 程序员|0x00100000|101 运维工程师|0x00100000|101
该包使用纯JavaScript编写,github上的star量有1k,但通过查看issue,该包的维护着似乎已经不太关心这个包了。但如果对性能要求没那么高,且多关注内存,使用得当的话,还是可以考虑的
nodejieba
https://github.com/yanyiwu/nodejieba
NodeJieba是"结巴(jieba)"中文分词的 Node.js 版本实现, 由CppJieba提供底层分词算法实现, 是兼具高性能和易用性两者的 Node.js 中文分词组件
具有以下特点
- 词典载入方式灵活,无需配置词典路径也可使用,需要定制自己的词典路径时也可灵活定制。
- 底层算法实现是C++,性能高效。
- 支持多种分词算法,各种分词算法见CppJieba的README.md介绍。
- 支持动态补充词库。
安装流程
npm install nodejieba
但在安装该包的时候可能会遇到npm下载权限的问题,因为底层使用了CppJieba,当使用sudo npm安装时会提示权限不足
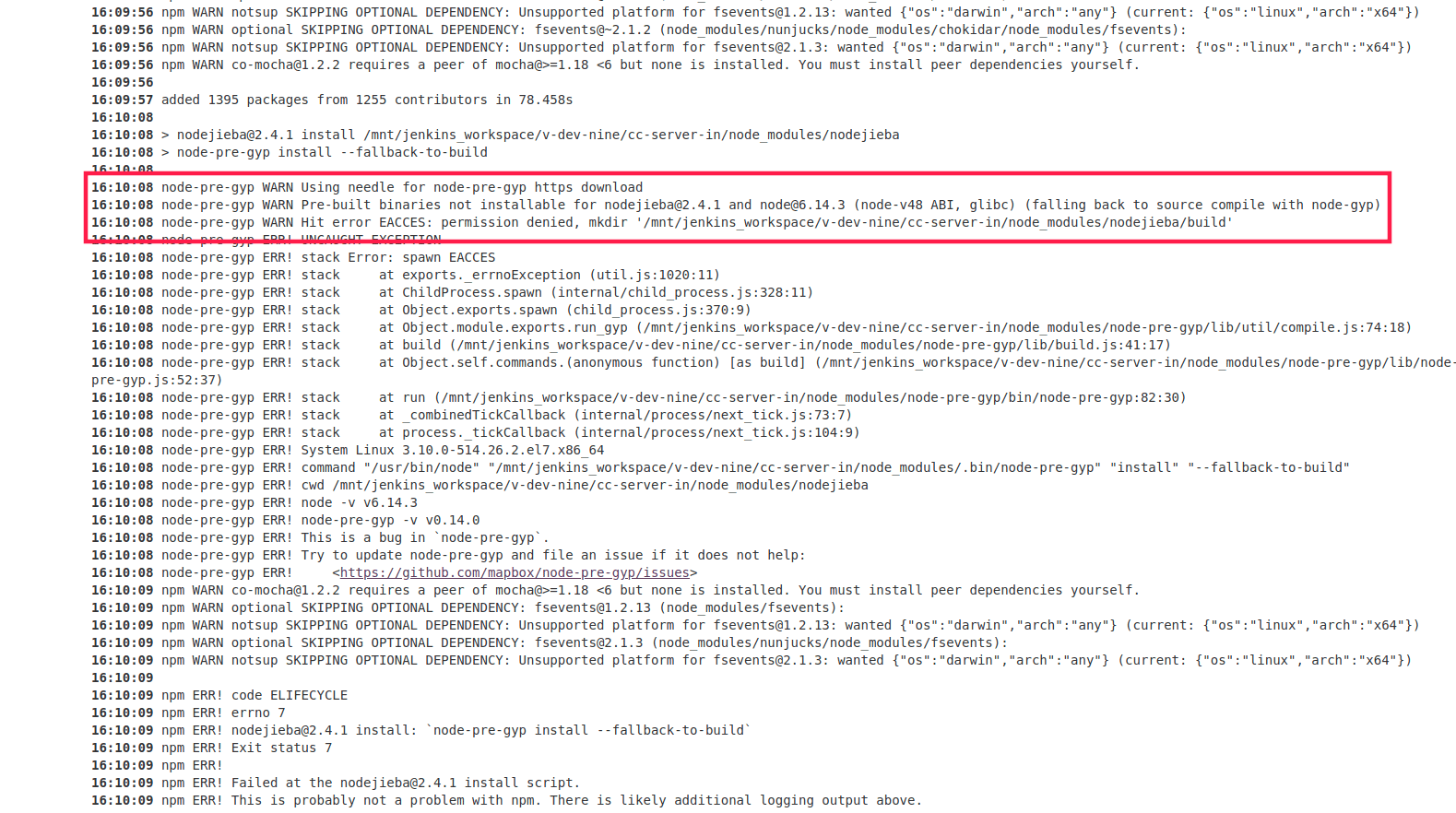
github issue问题
npm 官方解释
解决办法
- 单独下载该包文件
sudo npm install nodejieba --unsafe-perm- 将该包缓存至全局
sudo npm install nodejieba -g --unsafe-perm- 配置npm
sudo su -
npm config set unsafe-perm- 切换至root身份运行
sudo su -
npm i
示例代码
jieba词性
- 获取文本分词标注结果
- n 名词
- v 动词
- nt 机构名称
- t 时间
- nr 人名
…
示例自定义文件 .utf-8
客户模板 n 客户状态 n 客户手机号 n 自定义 n 自定义字段 n 云通讯 n
const nodejieba = require("nodejieba");
jieba.load({ userDict: `self.utf-8`}); // 自定义词典
const text = '红掌拨清波';
const tags = ['n', 'v', 'nt', 'nr', 't'];
const docuemnt = jieba.tag(text).filter((v) => tags.includes(v.tag)).map((v) => v.word);
console.log(docuemnt);
目前NodeJS中性能最强的分词器,且github上star量达到2k+,但开发者可能会遇到安装的问题,因为底层依赖了python g++,如果版本过低或者过高,在安装时会比较棘手。但如果能够将机器环境配置好的话,还是推荐使用该工具的,毕竟性能很强~~
性能对比
起初在使用nodejieba时,遇到了很多安装的问题,比如npm权限,g++版本不匹配等等,期间也尝试了node-segment,但因为服务对性能的要求较高,所以还是选择克服机器配置的问题,使用了nodejieba

node-sgement和nodejieba的性能对比以及代码分析
示例代码
'use strict';
const express = require('express');
const app = express();
const bodyParser = require('body-parser');
const Segment = require('segment');
const segment = new Segment();
const nodejieba = require('nodejieba');
app.use(bodyParser.urlencoded({ extended: false }));
app.use(bodyParser.json());
segment.useDefault();
segment.loadDict('test.text');
app.post('/', function (req, res, next) {
const text = req.body.text;
const type = req.body.type;
const num = req.body.num;
let str = '';
let array = [];
for (let index = 0; index < num; index++) {
str += text;
}
const tags = ['n', 'v', 'nt', 'nr', 't'];
if (type === 'nodejieba') {
array = nodejieba.tag(str).filter((v) => tags.includes(v.tag)).map((v) => v.word)
} else {
array = segment.doSegment(str).map((v) => v.w);
}
console.log(array);
res.send(array);
});
app.listen(3000);示例请求文件 .text
{
"text": "生活只有在平淡无味的人看来才是空虚而平淡无味的。",
"type": "segment",
"num": 1
}
- 使用apach bench进行测试
测试方法:ab -n 1000 -p post.txt -c 200 -T application/json localhost:3000
- -n 请求总数
- -p post请求文件
- -c 并发量
- -T 请求格式
…
- 请求返回参数说明
- Document Path: /phpinfo.php #测试的页面
- Document Length: 50797 bytes #页面大小
- Concurrency Level: 200 #测试的并发数
- Time taken for tests: 11.846 seconds #整个测试持续的时间
- Complete requests: 1000 #完成的请求数量
- Failed requests: 0 #失败的请求数量
- Write errors: 0
- Total transferred: 204586997 bytes #整个过程中的网络传输量
- HTML transferred: 203479961 bytes #整个过程中的HTML内容传输量
- Requests per second: 337.67 [#/sec] (mean) #最重要的指标之一,每秒处理请求数
- Time per request: 2961.449 [ms] (mean) #最重要的指标之二,平均等待时长
- Time per request: 2.961 [ms] (mean, across all concurrent requests) #每个连接请求实际运行时间的平均值
- Transfer rate: 16866.07 [Kbytes/sec] received #平均每秒网络上的流量,可以帮助排除是否存在网络流量过大导致响应时间延长的问题
- …
- 测试版本
- node v12
- segment v0.1.3
- nodejieba v2.4.1
- 测试结果
| 分词类型 | 字符长度 | 请求总数 | 并发条数 | 平均每秒处理 | 平均等待时长(ms) | 是否包含分隔符(标点符号等) |
|---|---|---|---|---|---|---|
| segment | 60 | 1000 | 20 | 129.47 | 154.474 | 是 |
| nodejieba | 60 | 1000 | 20 | 2662.83 | 7.511 | 是 |
| segment | 60 | 1000 | 50 | 137.51 | 363.598 | 是 |
| nodejieba | 60 | 1000 | 50 | 2660.41 | 17.222 | 是 |
| segment | 60 | 1000 | 100 | 134.56 | 753.688 | 是 |
| nodejieba | 60 | 1000 | 100 | 2774.89 | 36.038 | 是 |
| segment | 60 | 1000 | 200 | 134.05 | 1491.937 | 是 |
| nodejieba | 60 | 1000 | 200 | 2846.30 | 70.267 | 是 |
| ---- | ---- | — | – | – | – | – |
| segment | 180 | 1000 | 200 | 67.40 | 2967.466 | 是 |
| nodejieba | 180 | 1000 | 200 | 2390.53 | 83.664 | 是 |
| segment | 360 | 1000 | 200 | 42.55 | 4700.340 | 是 |
| nodejieba | 360 | 1000 | 200 | 1801.97 | 110.989 | 是 |
| ---- | ---- | — | – | – | – | – |
| segment | 60 | 1000 | 200 | 88.26 | 2265.952 | 否 |
| nodejieba | 60 | 1000 | 200 | 2860.95 | 69.907 | 否 |
| segment | 60 | 200 | 50 | 101.18 | 494.188 | 否 |
| nodejieba | 60 | 200 | 50 | 2688.39 | 18.598 | 否 |
| segment | 120 | 200 | 50 | 1.73 | 28933.129 | 否 |
| nodejieba | 120 | 200 | 50 | 1551.11 | 32.235 | 否 |
| segment | 360 | 200 | 50 | error(栈溢出) | error(栈溢出) | 否 |
| nodejieba | 360 | 200 | 50 | 1117.46 | 44.744 | 否 |
- 测试结果点评
- 从测试结果来看,nodejieba是node-sgement的20-30倍,这得益于nodejieba依赖的CppJieba,而node-sgement使用的纯JS编写,所以性能要逊色很多
- nodejieba和node-sgement在处理分词的请求都比较稳定,但面对长文本,即便性能很强的nodejieba依然会有性能瓶颈问题
- 面对不包含标点符号的文本,nodejieba和node-sgement性能都会有所影响
- node-sgement在对长文本(360个无标点符号的字符)进行分词时会导致栈溢出
- 测试过程说明
查看node-sgement源码发现 作者建议不要对较长且无任何标点符号的文本进行分词的是发生在字典分词阶段
因为分词是通过空格换行,通配符,特殊字符进行分离处理的(正是因为有了分离,所以每次分词的文本不会很长)
而segment处理一串字符是通过循环每一个字符进行递增匹配的,从而导致匹配的的次数是成倍的增长
…一开始想问原作者没有特殊符号的长文导致时间倍增的具体原因,但是他可能很久没有维护这个包了,就没有提供有用的信息,然后只能看源码去了解了
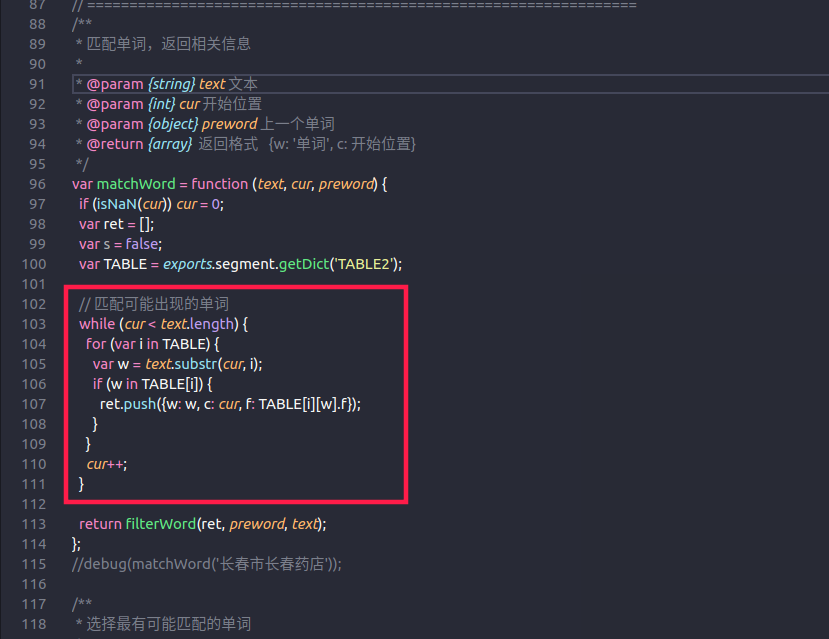
- node-segment 分词逻辑
- 例子 你好我是七陌,循环次数是6+5+4+3+2+1 = (1+n)*n/2
- 第一轮对比
你
你好
你好我
…- 第二轮对比
好
好我
好我是
好我是七
…
一共分为12个分词模块
- 6个分词模块
url识别
通配符识别
标点符号
字母/数字识别
字典识别- 6个优化模块
中文姓
人名
中文人名
日期时间
词典
邮箱地址
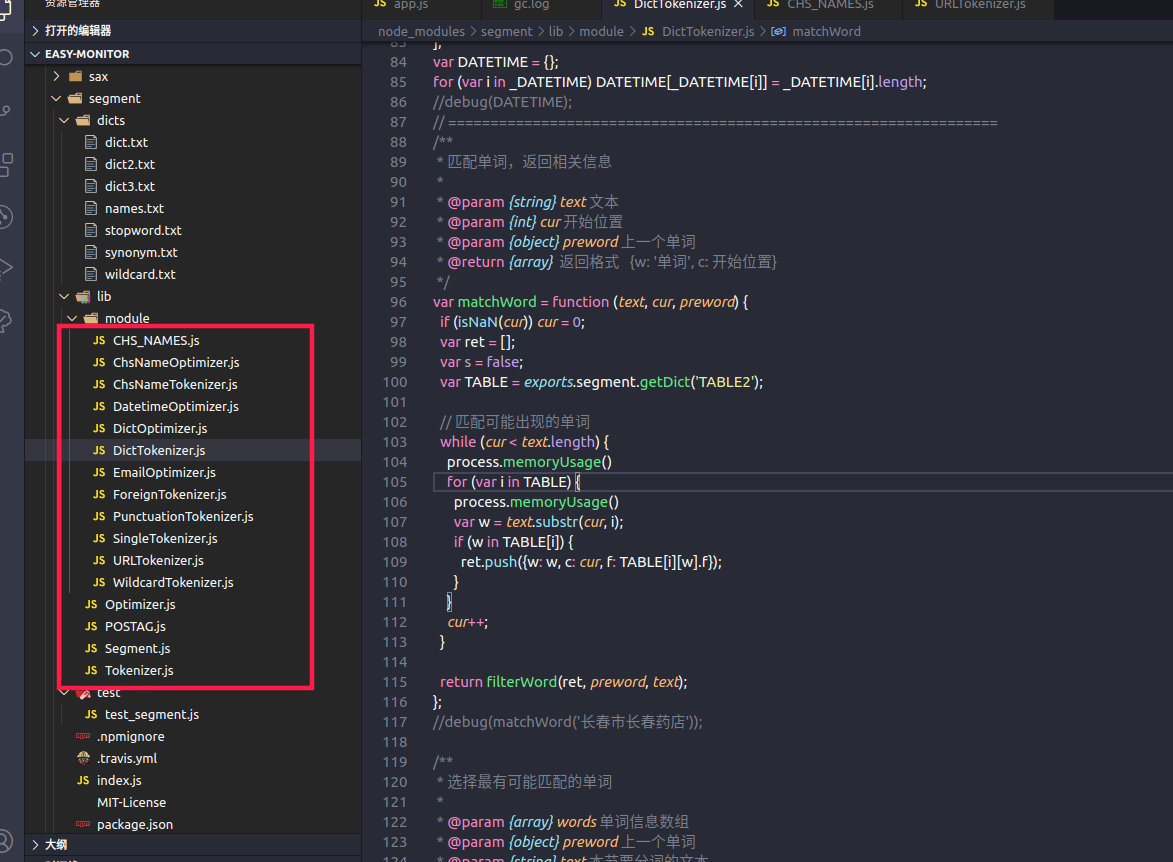
- 整体执行逻辑
每次分词会把红框中的所有模块文件执行一遍
- 将(空格/换行)进行分组,用于后续循环匹配字符和词性,然后进行六个阶段的分词计算
- url识别 地址匹配,https/http… 如果命中则进行转换,并返回数据和词性,每次从当前下标开始截取协议名称字符数,如果是http则是7个。将截取的字符进行对比,直到循环非url字符时结束。此时将这段字符的前后分成三段返回
- 通配符识别 通过循环遍历将命中的通配符返回,并在上层匹配通配符词性
- 标点符号 和通配符识别逻辑相同
- 字母/数字识别 将匹配的英文和数字字符使用ASCII转换,如果命中ASCII区间,则将区间对应的16进制转换为10进制作为词性并分离返回,分离后的结构和请求协议的结构相同
- 字典识别 将字符串的字符循环和每一个字典的内的字符进行包含性对比
第一次先从0下标开始查找,如果未命中则字符串截取数++,如果都没有命中就将对比下标向前进一位,其中重复命中的会经过一层优化(去重打分),留下词频率最高,未识别词最少的等等- 中文人名识别
- 人名优化
…
总结
当然是推荐使用nodejieba了,毕竟是目前nodejs性能最强的分词,但对机器环境依赖较为苛刻,所以建议使用docker将分词服务单独部署,进行环境依赖的隔离。
但如果更改机器配置对其他服务影响较大,且服务对性能要求没那么高的话,可以考虑使用node-segment,然后加一些避免栈溢出的代码,效果还是不错的~~
PS:笔者比较喜欢实用nodejieba分词工具,但是针对某些领域(如:区块链相关)的专业术语会出现分词错误的情况,这个时候就需要去寻找相关的词库并手动加载进来使用。