
Http学习之组装报文
作者:CrazyDragon_King
前面介绍了一些,基本的概念和需要具备的编程知识。下面开始来进行代码的编写,前面已经提到了最终的代码会是一个的http服务器的小demo–一个图床网站。
主要目标介绍
这里主要涉及的知识点就是解析报文和组装报文。 解析报文就是指解析HTTP请求报文,你需要知道报文请求的资源是什么。 组装报文就是指组装HTTP响应报文,你需要返回客户请求的相应资源。
目标分析
解析报文,需要获取完整的报文,利用报文的特定结构,获取报文里面的信息。然后依据这些信息,先客户端返回响应报文。这里涉及到自己解析报文,比较有难度,因为需要报文的结构特定。上一篇博客已经简单介绍过了(这里只是处理一些简单的请求和响应报文,不是那种特别复杂的,毕竟只是学习,没有必要自己和自己过不去!)
组装报文,需要将客户需要的信息组装好,然后发送给客户端。报文会由客户端(通常是浏览器)自动解析,这里就不需要解析了,只是把报文发送给客户端。对于编程来说,只是涉及到IO流的处理而已。所以,组装报文比较简单一些。
所以,这篇博客就先只介绍如何组装报文(注意这里虽然是简单的报文,但也是符合规定的报文)。
组装报文
我们来回顾一下前面介绍的知识,通常一个完整的报文包括报文头和报文体。(当然了,GET请求方式是没有请求体的。)
主要的代码就是下面三行了。
out.write(header); //写入Http报文头部部分 out.write(content); //写入Http报文数据部分 out.flush(); //刷新输出流,确保缓冲区内数据已经发送完成
是不是感觉很神奇,所谓的HTTP报文,在TCP这个层次来看,不过就是一个字节流。(这里 header 和 content 在网络上是可以看成串行的流。)
启动服务类
这个类和平时使用的 ServerSocket 类用法没有什么区别,就是使用多线程来处理每一个客户端的连接。启动一个ServerSocket,监听10000端口。
package com.dragon;
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class HttpServer {
private static ServerSocket server;
/**
* 启动服务
* */
public void start() {
try {
server = new ServerSocket(10000);
System.out.println("服务启动成功...");
this.receiveRequest();
} catch (IOException e) {
e.printStackTrace();
System.out.println("服务启动失败!");
}
}
/**
* 接收请求
* */
public void receiveRequest() {
ExecutorService pool = Executors.newFixedThreadPool(10);
while (true) {
try {
Socket client = server.accept();
System.out.println("用户"+client.getInetAddress().toString()+"建立连接" + client.toString());
pool.submit(new Connection(client)); //使用线程处理每一个请求。
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 停止服务
* 注:一般是不需要关闭服务的。
* */
public void stop() {
try {
if (server != null) {
server.close();
}
} catch (IOException e) {
e.printStackTrace();
System.out.println("服务器关闭失败!");
}
}
}
连接类
对于每一个客户端的连接,获取用户的请求,并返回响应。因为只是一个简单的模拟,这里其实获取用户的请求也不进行处理(因为处理需要解析请求报文),对于任何的请求返回的响应都是同一个。所以,它实际上还具有一个非常有趣的特点–消灭了404。 相信经常使用浏览器的人应该都知道404这个错误吧,404的意思是对于当前的请求没有找到请求的资源。所以,通常可以看到 Not Found 这两个英文单词,当然了也可以自定义成其它的形式。因为这个程序,只具有接收请求,返回响应的基本功能,所以,我间接消灭了404,哈哈!
注:头部字段中,我只是返回了几个必要的头部。因为HTTP头部还是比较多的,有些也不是必要的。具体的信息,可以参考一些专业的书籍来了解更多的知识或者直接阅读这方面的权威–RFC文档,哈哈(不过我也没有看,就是瞅了一眼。)。
package com.dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import java.util.TimeZone;
public class Connection implements Runnable {
private static final String BLANK = " ";
private static final String CRLF = "\r\n";
private byte[] content;
private byte[] header;
private Socket client;
public Connection(Socket client) {
this.client = client;
}
@Override
public void run() {
//这里不对请求进行处理,只是收到请求之后会进行响应,而不管是什么请求
//这里模拟服务器最原始的功能:请求、响应。
this.response();
System.out.println("线程执行结束了!");
}
/**
* 接收请求信息,这里只是一个简单的模拟,这里只能接收get请求。
* @throws IOException
* */
public String getRequestInfo(InputStream in) throws IOException {
//只读取第一行,这是我们需要的全部内容
StringBuilder requestLine = new StringBuilder(80);
while (true) {
int c = in.read();
if (c == '\r' || c == '\n' || c == -1) break;
requestLine.append((char)c);
}
return requestLine.toString();
}
/**
* 响应信息
* */
public void response() {
InputStream in = null;
OutputStream out = null;
try {
in = new BufferedInputStream(client.getInputStream());
out = new BufferedOutputStream(client.getOutputStream()); //获取输出流
String requestInfo = this.getRequestInfo(in); //如果不读取客户端发来的数据,服务器就会出错。
System.out.println(requestInfo);
} catch (IOException e1) {
e1.printStackTrace();
} //获取输入流
//响应体数据
File file = new File("D:/DragonFile/target/attitude.jpg");
String contentType = null; //文件的 MIME 类型
try {
content = Files.readAllBytes(file.toPath()); //使用 Files 工具类,一次性读取文件
contentType = Files.probeContentType(file.toPath()); //获取文件的 MIME 类型
long length = file.length(); //获取文件字节长度
header = this.getHeader(contentType, length); // 填充响应头
} catch (IOException e) {
e.printStackTrace();
}
try {
out.write(header); //写入Http报文头部部分
out.write(content); //写入Http报文数据部分
out.flush(); //刷新输出流,确保缓冲区内数据已经发送完成
System.out.println("报文总大小(字节):" + (header.length + content.length));
} catch (IOException e) {
e.printStackTrace();
System.out.println("客户断开连接或者发送失败!");
} finally {
//此处关闭 client 会导致程序出现问题,但是原因不清楚。
try {
if (client != null) {
client.close();
}
System.out.println("请求结束了");
} catch (IOException e) {
e.printStackTrace();
}
}
}
//响应头
private byte[] getHeader(String contentType, long length) {
return new StringBuilder()
.append("HTTP/1.1").append(BLANK).append(200).append(BLANK).append("OK").append(CRLF) // 响应头部
.append("Server:"+"CrazyDragon").append(CRLF)
.append("Date:").append(BLANK).append(this.getDate()).append(CRLF)
.append("Content-Type:").append(BLANK).append(contentType).append(CRLF) //文件的 Content-Type 可通过Java获取。
.append("Content-Length:").append(BLANK).append(length).append(CRLF).append(CRLF)
.toString()
.getBytes(Charset.forName("UTF-8"));
}
//获取时间
private String getDate() {
Date date = new Date();
SimpleDateFormat format = new SimpleDateFormat("EEE, d MMM yyyy HH:mm:ss 'GMT'", Locale.US);
format.setTimeZone(TimeZone.getTimeZone("GMT")); // 设置时区为GMT
return format.format(date);
}
}
主类
package com.dragon;
public class Test {
public static void main(String[] args) {
HttpServer httpServer = new HttpServer();
httpServer.start();
}
}
运行结果
打印输出:
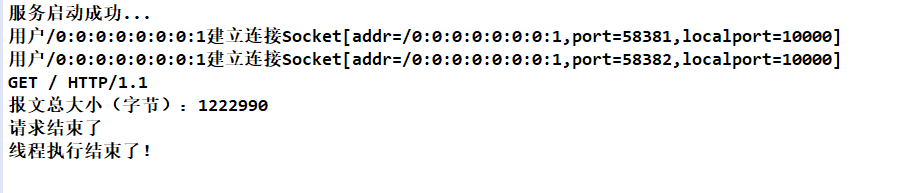
浏览器访问:

注:上面可以看到会有两个请求,这是因为浏览器访问的时候,会请求网站的图标,通常的路径为 /favicon.ico,这里似乎是因为缓存,没有看到它的请求,如果存在请求行应该为:GET /favicon.ico HTTP/1.1。
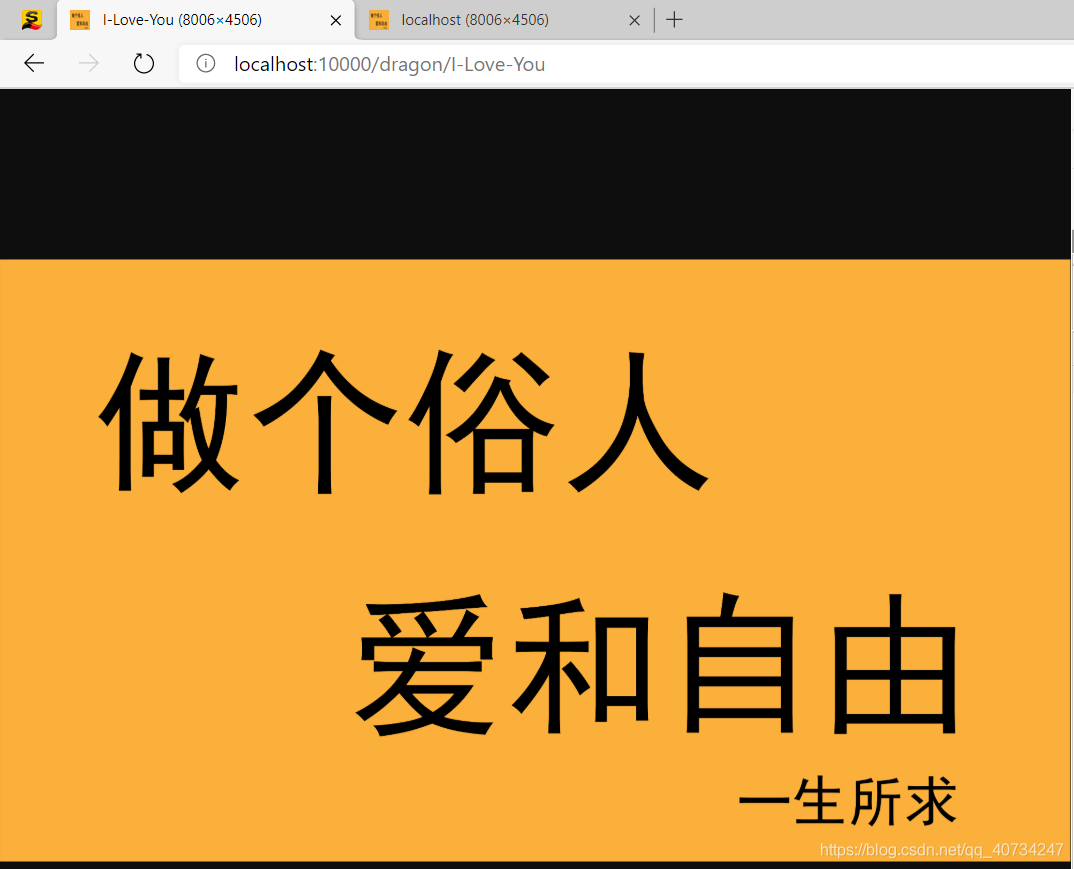
随便访问一个地址,看一看没有404的网站!

访问结果
注意:这里可能会遇到异常。 但是这个对于程序的运行结果没有影响。报错的原因处在这句话:out.wirte(content);

可能的原因有一下几点:
①:服务器的并发连接数超过了其承载量,服务器会将其中一些连接Down掉;
②:客户关掉了浏览器,而服务器还在给客户端发送数据;
③:浏览器端按了Stop 按钮。
④:用servlet的outputstream输出流下载图片时,当用户点击取消也会报这个错误。
总结
目前,组装报文这个功能已经实现了,现在已经很有意思了吧。通过这个简单的程序,已经可以真正理解为什么HTTP是建立在TCP协议之上的了吧。这里我特别选了一张图片来进行展示,效果应该还是很不错的。
到此这篇关于Http学习之组装报文的文章就介绍到这了,更多相关Http组装报文内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!