
深入解析pandas数据聚合和重组
作者:西西弗斯推石头
介绍pandas数据聚合和重组的相关知识,仅供参考。
1GroupBy技术
1.1简介
简介:根据一个或多个键进行分组,每一组应用函数,再进行合并
分组的键有多种形式:
- 列表或数组,长度与待分组的轴一样
- 表示DataFrame某个列名的值
- 字典或Series,给出待分组轴上的值与分组名之间的对应关系
- 函数,用于处理轴索引或索引中的各个标签
实例:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
df =DataFrame({'key1':list('aabba'),'key2':['one','two','one','two','one'],\
'data1':np.random.randn(5),'data2':np.random.randn(5)})
#根据key1进行分组,并计算data1的均值。
#注意下面的方式,取出来进行分组,而不是在DataFrame中分组,这种方式很灵活
#可以看到这是一个GroupBy对象,具备了应用函数的基础
#这个过程是将Series进行聚合,产生了新的Series
grouped = df['data1'].groupby(df['key1'])
print(grouped,'\n') 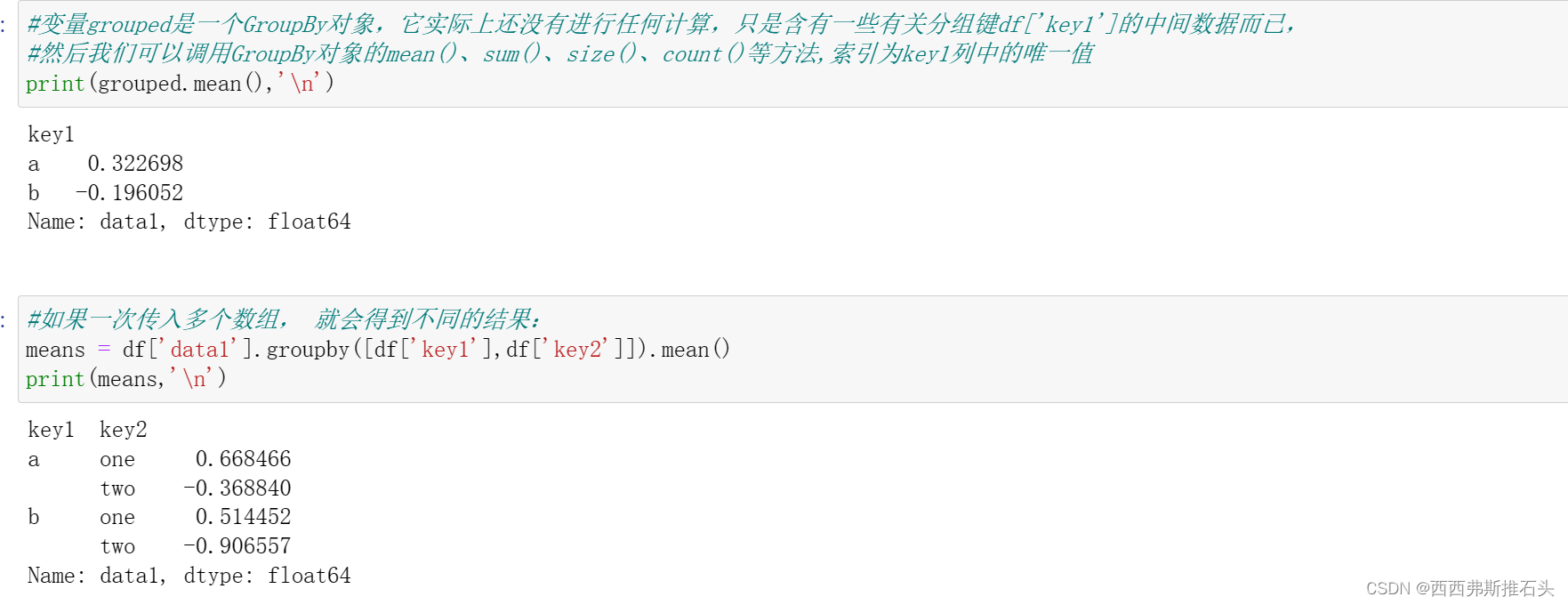
注:
取出来进行分组,而不是在DataFrame中分组分组键中的缺失值被排除在外 1.2对分组进行迭代
GroupBy对象支持迭代,可以产生一组二元元组(由分组名和数据块组成)


groupby默认在axis=0上进行分组,但可以设置在任何轴上分组

1.3选取一个或一组列
对于由DataFrame产生的GroupBy对象,如果用一个或一组列名进行索引,可实现选取部分列进行聚合的目的,即下面语法效果相同。

1.4通过字典或Series进行分组
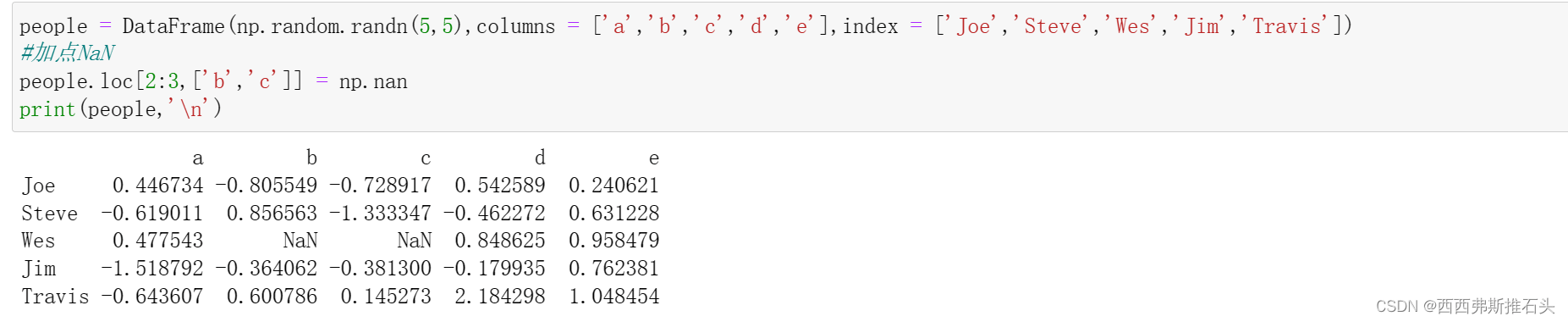
假设已经知道列的分组方式,现在需要利用这个信息进行分组统计。
下面为groupby传入一个已知信息的字典:

相当于将每一个列重设名,再按新的名字进行求和。
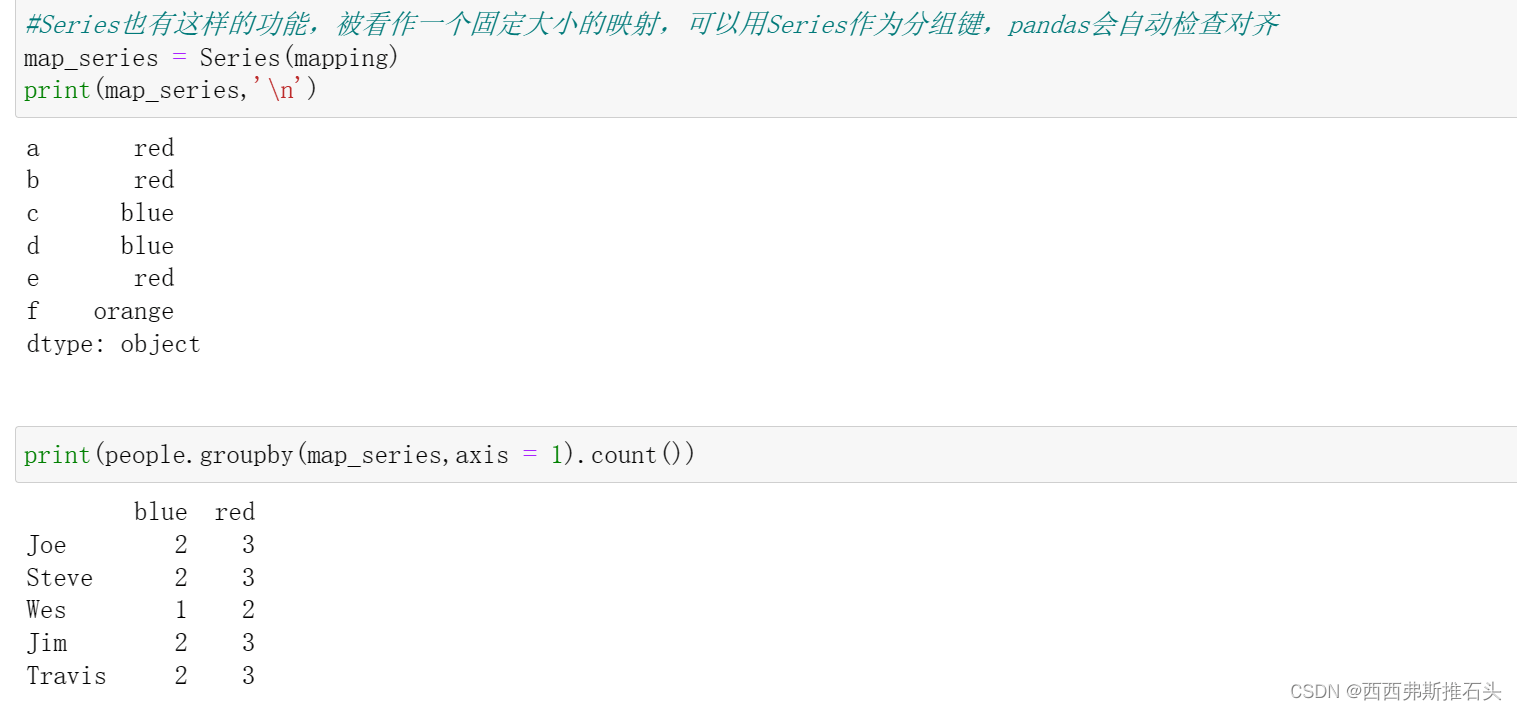
Series也有这样的功能,被看作一个固定大小的映射,可以用Series作为分组键,pandas会自动检查对齐。
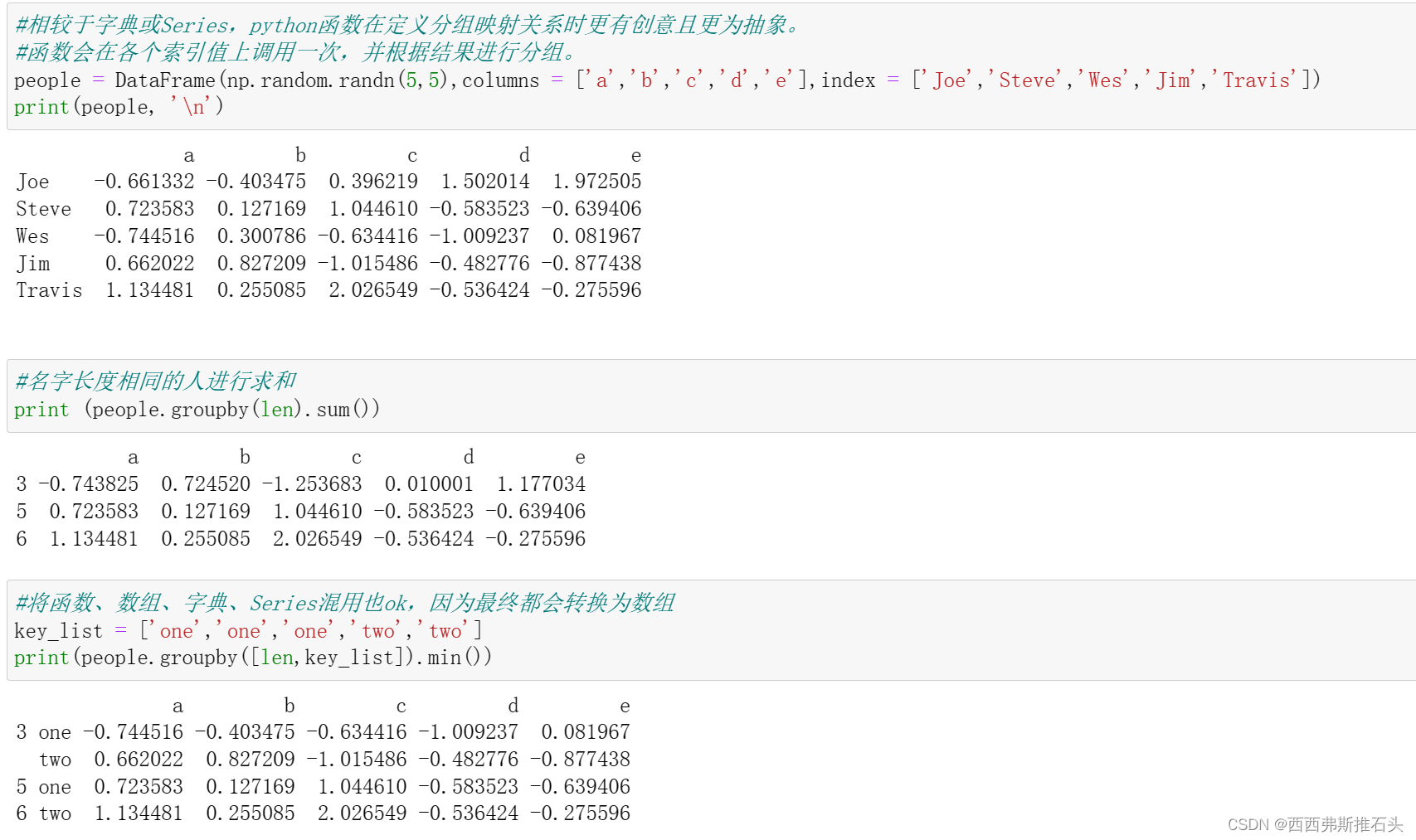
1.5利用函数进行分组
将函数、数组、字典、Series混用也ok,因为最终都会转换为数组
2数据聚合
2.1简介
简介:
这里的数据聚合是说任何能够从数组产生标量值的过程常见的聚合运算都有就地计算数据集统计信息的优化实现。当然不止这些,可以用自己定义的运算,还可以调用分组对象上已经定义好的任何方法。
例:quantile可计算Series或DataFrame列的样本分位数。

对于自己定义的聚合函数,只需将其传入aggregate或agg即可:

有些方法(describe)也可应用

自定义函数比经过优化的函数要慢得多,这是因为在构造中间分组数据块时存在非常大的开销(函数调用、数据重排等)
可使用的函数:

2.1面向列的多函数应用
有时候需要对不同的列应用不同的函数 ,或者对一列应用不同的函数

若传入一组函数或函数名,得到的DataFrame列就会以相应的函数命名

上面有个问题就是列名是自动给出的,以函数名为列名,若传入元组(name,function)组成的列表,就会自动将第一个元素作为列名

对两列都应用functions:
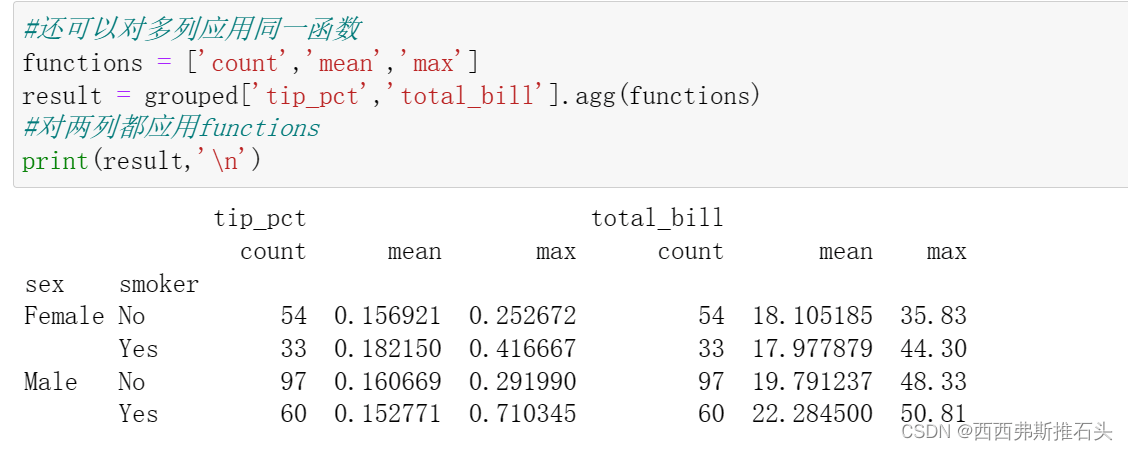
得到的结果的列名是层次化索引,可以直接用外层索引选取数据:

如果想对不同的列应用不同的函数,具体的办法是向agg传入一个从列映射到函数的字典:

2.2以‘无索引’的方式返回聚合数据
到目前为止,示例中的聚合数据都是由唯一的分组键组成的索引(可能还是层次化的)
由于并不是总需要如此,可以向groupby传入as_index = False禁用该功能

到此这篇关于pandas数据聚合和重组的文章就介绍到这了,更多相关pandas数据聚合内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!