
浅谈Go连接池的设计与实现
作者:亚洲第一中锋_哈达迪
为什么需要连接池
如果不用连接池,而是每次请求都创建一个连接是比较昂贵的,因此需要完成3次tcp握手
同时在高并发场景下,由于没有连接池的最大连接数限制,可以创建无数个连接,耗尽文件描述符
连接池就是为了复用这些创建好的连接
连接池设计
基本上连接池都会设计以下几个参数:
初始连接数:在初始化连接池时就会预先创建好的连接数量,如果设置得:
- 过大:可能造成浪费
- 过小:请求到来时需要新建连接
最大空闲连接数maxIdle:池中最大缓存的连接个数,如果设置得:
- 过大:造成浪费,自己不用还把持着连接。因为数据库整体的连接数是有限的,当前进程占用多了,其他进程能获取的就少了
- 过小:无法应对突发流量
最大连接数maxCap:
- 如果已经用了maxCap个连接,要申请第maxCap+1个连接时,一般会阻塞在那里,直到超时或者别人归还一个连接
最大空闲时间idleTimeout:当发现某连接空闲超过这个时间时,会将其关闭,重新去获取连接
避免连接长时间没用,自动失效的问题
连接池对外提供两个方法,Get:获取一个连接,Put:归还一个连接
大部分连接池的实现大同小异,基本流程如下:
Get
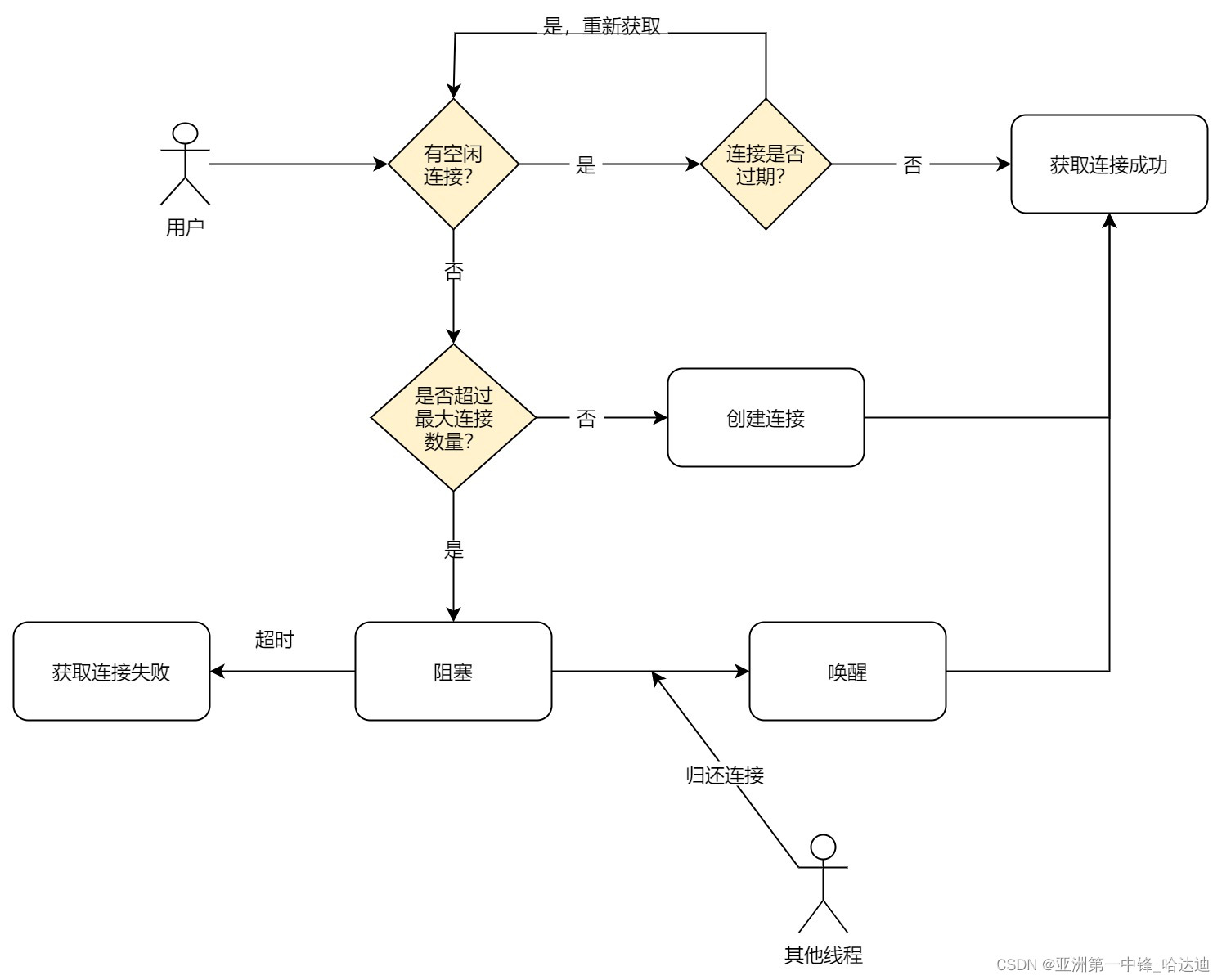
需要注意:
- 当有空闲连接时,需要进一步判断连接是否有过期(超过最大空闲时间idleTimeout)
- 这些连接有可能很久没用过了,在数据库层面已经过期。如果贸然使用可能出现错误,因此最好检查下是否超时
- 当陷入阻塞时,最好设置超时时间,避免一直没等到有人归还连接而一直阻塞
Put
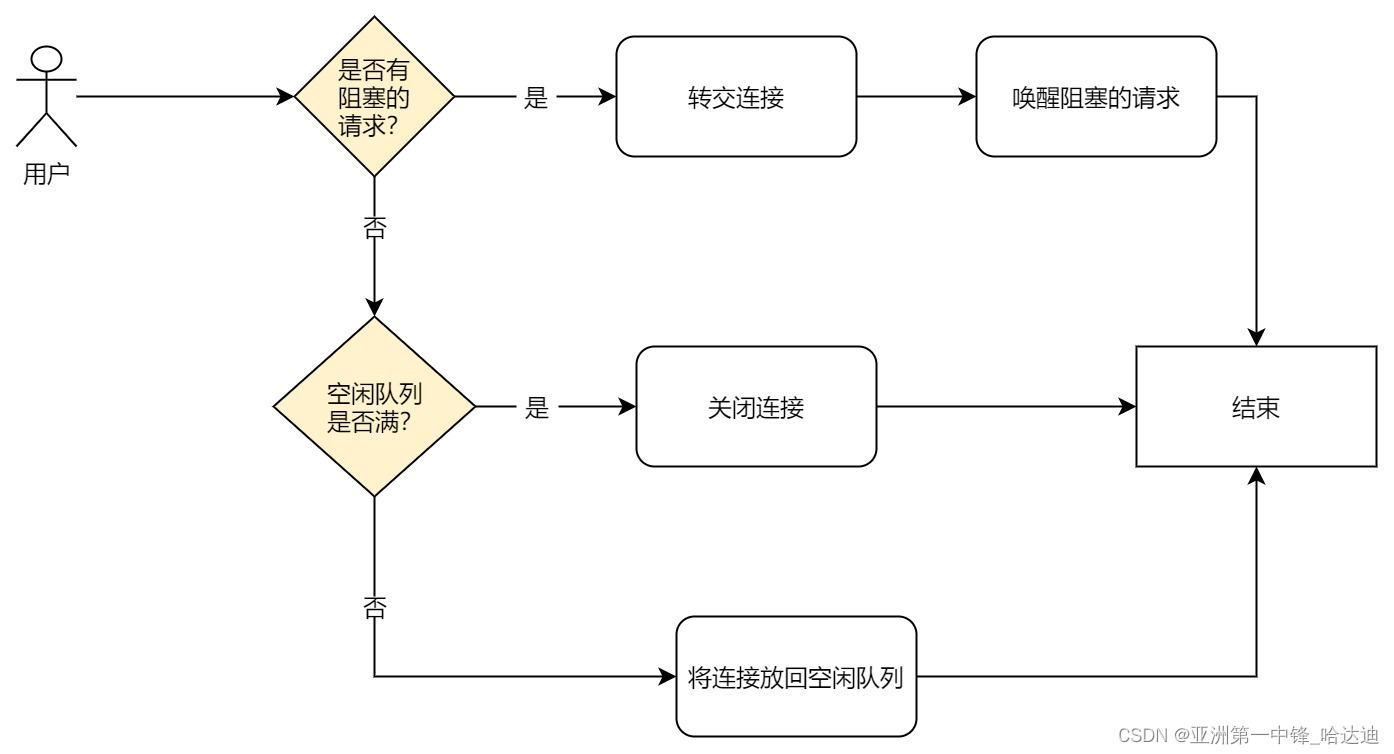
归还连接时:
- 先看有没有阻塞的获取连接的请求,如果有转交连接,并唤醒阻塞请求
- 否则看能否放回去空闲队列,如果不能直接关闭请求
总结
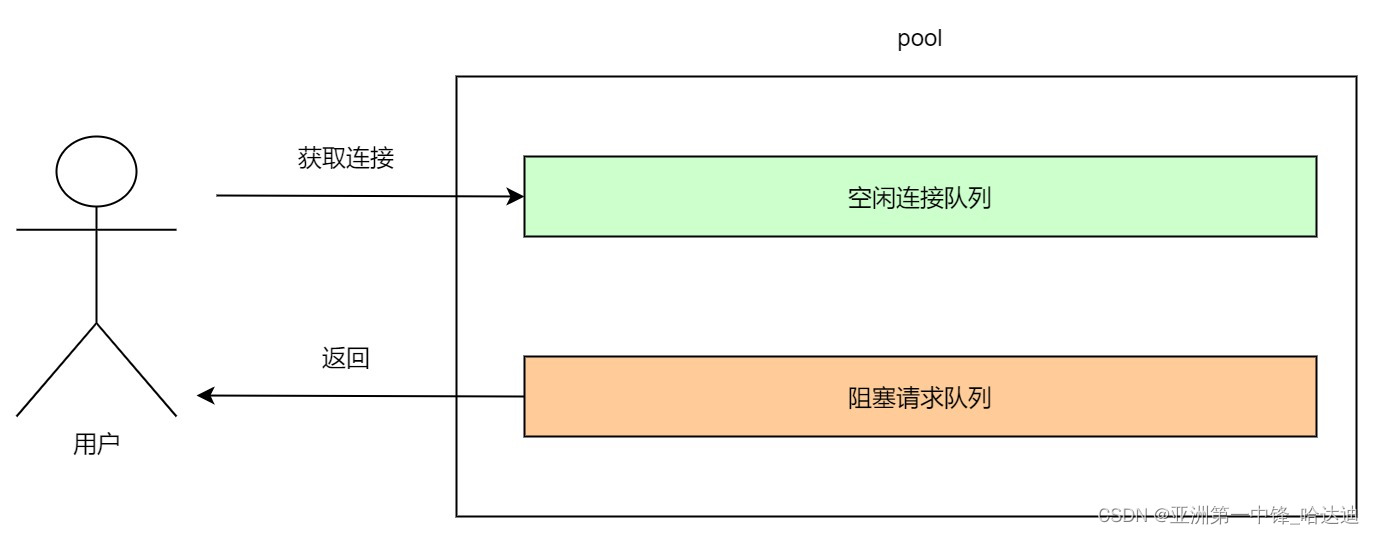
根据上面总结的流程,连接池还需要维护另外两个结构:
- 空闲队列
- 阻塞请求的队列
开源实现
接下来看几个开源连接池的实现,都大体符合上面介绍的流程
silenceper/pool
代码地址:https://github.com/silenceper/pool
数据结构:
// channelPool 存放连接信息
type channelPool struct {
mu sync.RWMutex
// 空闲连接
conns chan *idleConn
// 产生新连接的方法
factory func() (interface{}, error)
// 关闭连接的方法
close func(interface{}) error
ping func(interface{}) error
// 最大空闲时间,最大阻塞等待时间(实际没用到)
idleTimeout, waitTimeOut time.Duration
// 最大连接数
maxActive int
openingConns int
// 阻塞的请求
connReqs []chan connReq
}
可以看出,silenceper/pool:
- 用channel实现了空闲连接队列
conns - 为每个阻塞的请求创建一个channel,加入
connReqs中。这样请求会阻塞在自己的channel上
Get:
func (c *channelPool) Get() (interface{}, error) {
conns := c.getConns()
if conns == nil {
return nil, ErrClosed
}
for {
select {
// 如果有空闲连接
case wrapConn := <-conns:
if wrapConn == nil {
return nil, ErrClosed
}
//判断是否超时,超时则丢弃
if timeout := c.idleTimeout; timeout > 0 {
if wrapConn.t.Add(timeout).Before(time.Now()) {
//丢弃并关闭该连接
c.Close(wrapConn.conn)
continue
}
}
//判断是否失效,失效则丢弃,如果用户没有设定 ping 方法,就不检查
if c.ping != nil {
if err := c.Ping(wrapConn.conn); err != nil {
c.Close(wrapConn.conn)
continue
}
}
return wrapConn.conn, nil
// 没有空闲连接
default:
c.mu.Lock()
log.Debugf("openConn %v %v", c.openingConns, c.maxActive)
if c.openingConns >= c.maxActive {
// 连接数已经达到上线,不能再创建连接
req := make(chan connReq, 1)
c.connReqs = append(c.connReqs, req)
c.mu.Unlock()
// 将自己阻塞在channel上
ret, ok := <-req
if !ok {
return nil, ErrMaxActiveConnReached
}
// 再检查一次是否超时
if timeout := c.idleTimeout; timeout > 0 {
if ret.idleConn.t.Add(timeout).Before(time.Now()) {
//丢弃并关闭该连接
c.Close(ret.idleConn.conn)
continue
}
}
return ret.idleConn.conn, nil
}
// 没有超过最大连接数,创建一个新的连接
if c.factory == nil {
c.mu.Unlock()
return nil, ErrClosed
}
conn, err := c.factory()
if err != nil {
c.mu.Unlock()
return nil, err
}
c.openingConns++
c.mu.Unlock()
return conn, nil
}
}
}
这段代码基本符合上面介绍的Get流程,应该很好理解
需要注意:
- 当收到别人归还的连接狗,这里再检查了一次是否超时。但我认为这次检查是没必要的,因为别人刚用完,一般不可能超时
- 虽然在pool的数据结构定义中有
waitTimeOut字段,但实际没有使用,即阻塞获取可能无限期阻塞,这是一个优化点
Put:
// Put 将连接放回pool中
func (c *channelPool) Put(conn interface{}) error {
if conn == nil {
return errors.New("connection is nil. rejecting")
}
c.mu.Lock()
if c.conns == nil {
c.mu.Unlock()
return c.Close(conn)
}
// 如果有请求在阻塞获取连接
if l := len(c.connReqs); l > 0 {
req := c.connReqs[0]
copy(c.connReqs, c.connReqs[1:])
c.connReqs = c.connReqs[:l-1]
// 将连接转交
req <- connReq{
idleConn: &idleConn{conn: conn, t: time.Now()},
}
c.mu.Unlock()
return nil
} else {
// 否则尝试是否能放回空闲连接队列
select {
case c.conns <- &idleConn{conn: conn, t: time.Now()}:
c.mu.Unlock()
return nil
default:
c.mu.Unlock()
//连接池已满,直接关闭该连接
return c.Close(conn)
}
}
}
值得注意的是:
put方法唤醒阻塞请求时,从队头开始唤醒,这样先阻塞的请求先被唤醒,保证了公平性
sql.DB
Go在官方库sql中就实现了连接池,这样的好处在于:
- 对于开发:就不用像java一样,需要自己找第三方的连接池实现
- 对于driver的实现:只用关心怎么和数据库交互,不用考虑连接池的问题
sql.DB中和连接池相关的字段如下:
type DB struct {
/**
...
*/
// 空闲连接队列
freeConn []*driverConn
// 阻塞请求的队列
connRequests map[uint64]chan connRequest
// 已经打开的连接
numOpen int // number of opened and pending open connections
// 最大空闲连接
maxIdle int // zero means defaultMaxIdleConns; negative means 0
// 最大连接数
maxOpen int // <= 0 means unlimited
// ...
}
继续看获取连接:
func (db *DB) conn(ctx context.Context, strategy connReuseStrategy) (*driverConn, error) {
// 检测连接池是否被关闭
db.mu.Lock()
if db.closed {
db.mu.Unlock()
return nil, errDBClosed
}
select {
default:
// 检测ctx是否超时
case <-ctx.Done():
db.mu.Unlock()
return nil, ctx.Err()
}
lifetime := db.maxLifetime
db.numOpen++ // optimistically
db.mu.Unlock()
ci, err := db.connector.Connect(ctx)
if err != nil {
db.mu.Lock()
db.numOpen-- // correct for earlier optimism
db.maybeOpenNewConnections()
db.mu.Unlock()
return nil, err
}
db.mu.Lock()
dc := &driverConn{
db: db,
createdAt: nowFunc(),
ci: ci,
inUse: true,
}
db.addDepLocked(dc, dc)
db.mu.Unlock()
return dc, nil
}
接下来检测是否有空闲连接:
numFree := len(db.freeConn)
// 如果有空闲连接
if strategy == cachedOrNewConn && numFree > 0 {
// 从队头取一个
conn := db.freeConn[0]
copy(db.freeConn, db.freeConn[1:])
db.freeConn = db.freeConn[:numFree-1]
conn.inUse = true
db.mu.Unlock()
if conn.expired(lifetime) {
conn.Close()
return nil, driver.ErrBadConn
}
// Reset the session if required.
if err := conn.resetSession(ctx); err == driver.ErrBadConn {
conn.Close()
return nil, driver.ErrBadConn
}
return conn, nil
}
以上代码是1.14版本,但是到了1.18以后,获取空闲连接的方式发生了变化:
last := len(db.freeConn) - 1
if strategy == cachedOrNewConn && last >= 0 {
// 从最后一个位置获取连接
conn := db.freeConn[last]
db.freeConn = db.freeConn[:last]
conn.inUse = true
if conn.expired(lifetime) {
db.maxLifetimeClosed++
db.mu.Unlock()
conn.Close()
return nil, driver.ErrBadConn
}
可以看出,1.14版本从队首获取,1.18改成从队尾获取连接
为啥从队尾拿连接?
因为队尾的连接是才放进去的,该连接过期的概率比队首连接小
继续看:
// 如果已经达到最大连接数
if db.maxOpen > 0 && db.numOpen >= db.maxOpen {
req := make(chan connRequest, 1)
reqKey := db.nextRequestKeyLocked()
db.connRequests[reqKey] = req
db.waitCount++
db.mu.Unlock()
waitStart := time.Now()
// 阻塞当前请求,要么ctx超时,要么别人归还了连接
select {
case <-ctx.Done():
db.mu.Lock()
// 把自己从阻塞队列中删除
delete(db.connRequests, reqKey)
db.mu.Unlock()
atomic.AddInt64(&db.waitDuration, int64(time.Since(waitStart)))
select {
default:
case ret, ok := <-req:
if ok && ret.conn != nil {
db.putConn(ret.conn, ret.err, false)
}
}
return nil, ctx.Err()
case ret, ok := <-req:
// 别人归还连接
atomic.AddInt64(&db.waitDuration, int64(time.Since(waitStart)))
if !ok {
return nil, errDBClosed
}
if strategy == cachedOrNewConn && ret.err == nil && ret.conn.expired(lifetime) {
ret.conn.Close()
return nil, driver.ErrBadConn
}
if ret.conn == nil {
return nil, ret.err
}
return ret.conn, ret.err
}
}
这里需要注意,在ctx超时分支中:
- 首先把自己从阻塞队列中删除
- 再检查一下req中是否有连接,如果有,将连接放回连接池
奇怪的是为啥把自己删除后,req还可能收到连接呢?
因为put连接时,会先拿出一个阻塞连接的req,如果这里删除req在put拿出req:
- 之前:那没问题,put不可能再放该req发送连接
- 之后:那有可能put往该req发送了连接,因此需要再检查下req中是否有连接,如果有归还
也解释了为啥阻塞队列要用map:
- 用于快速找到自己的req,并删除
最后看看put:
func (db *DB) putConnDBLocked(dc *driverConn, err error) bool {
if db.closed {
return false
}
if db.maxOpen > 0 && db.numOpen > db.maxOpen {
return false
}
// 有阻塞的请求,转移连接
if c := len(db.connRequests); c > 0 {
var req chan connRequest
var reqKey uint64
for reqKey, req = range db.connRequests {
break
}
delete(db.connRequests, reqKey) // Remove from pending requests.
if err == nil {
dc.inUse = true
}
req <- connRequest{
conn: dc,
err: err,
}
return true
// 判断能否放回空闲队列
} else if err == nil && !db.closed {
if db.maxIdleConnsLocked() > len(db.freeConn) {
db.freeConn = append(db.freeConn, dc)
db.startCleanerLocked()
return true
}
db.maxIdleClosed++
}
return false
}
到此这篇关于浅谈Go连接池的设计与实现的文章就介绍到这了,更多相关Go连接池内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!