
基于ArrayList源码解析(基于JDK1.8)
作者:Lframe
ArrrayList是Java中经常被用到的集合,弄清楚它的底层实现,有利于我们更好地使用它。
下图是ArrayList的UML图
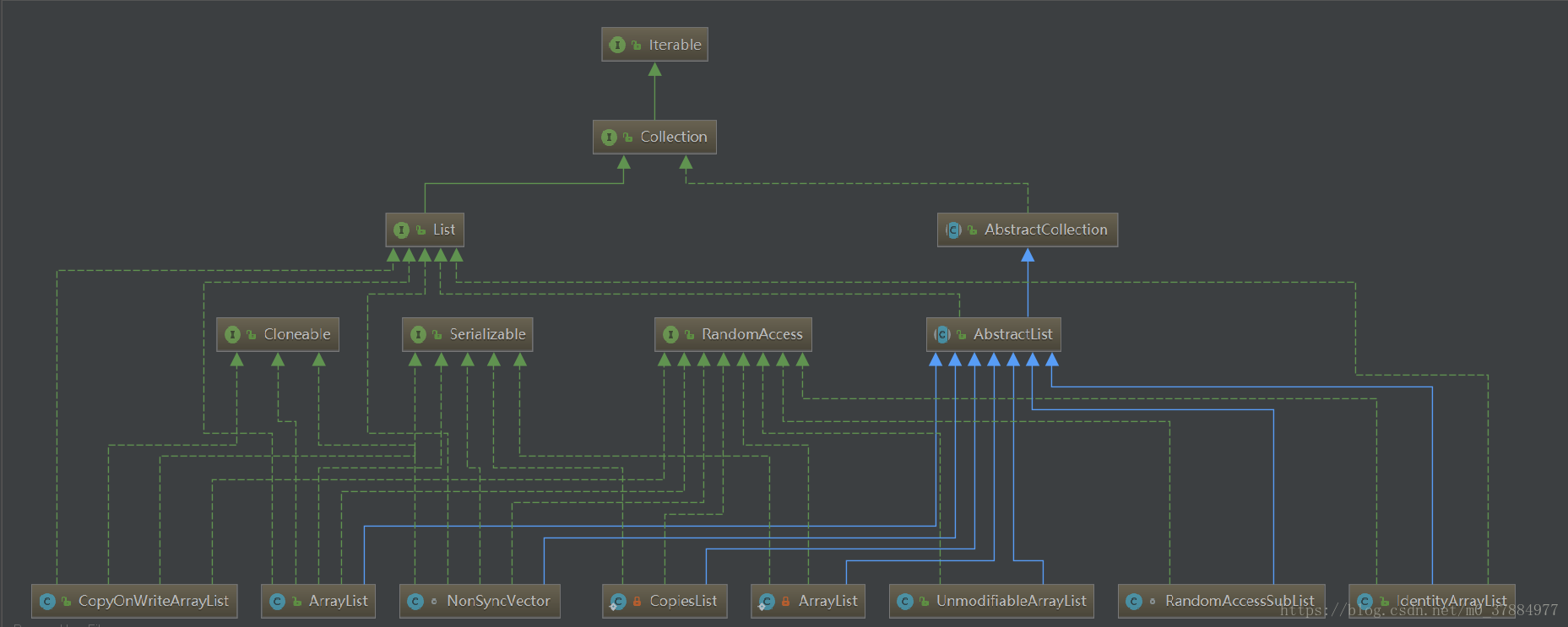
从图中我们可以看出
1: 实现了RandomAccess接口:表面ArrayList支持快速(通常是常量时间)的随机访问。官方源码也给出了解释:(因为底层实现是一个数组,所以get()方法要比迭代器快,后面还会更有更加详细的源码解析)

2:实现了Cloneable接口,表明它支持克隆。可以调用clone()进行浅拷贝。
3:实现了Serializable接口,表明它支持序列化。
4:它还实现了List接口,并且继承自AbstractList抽象类。
代码分析部分太多了,我直接把总结弄到最上面了,可以方便查看。
总结:
- ① ArrayList在我们日常开发中随处可见,所以建议大家可以自己手动实现一个ArrayList,实在写不出来可以模仿一下ArrayList么。
- ② 由于ArryList随机存储,底层是用的一个数组作为存放元素的,所以在遍历ArrayList的时候,使用get()方法的效率要比使用迭代器的效率高。
- ③在ArrayList中经常使用的一个变量modCount,它是在ArrayList的父类AbstractList中定义的一个protected变量,该变量主要在多线程的环境下,如果使用迭代器进行删除或其他操作的时候,需要保证此刻只有该迭代器进行修改操作,一旦出现其他线程调用了修改modCount的值的方法,迭代器的方法中就会抛出异常。究其原因还是因为ArrayList是线程不安全的。
- ④ 在ArrayList底层实现中,很多数组中元素的移动,都是通过本地方法System.arraycopy实现的,该方法是由native修饰的。
- ⑤ 在学习源码的过程中,如果有看不懂的方法,可以自己写一个小例子调用一下这个方法,然后通过debug的方式辅助理解代码的含义。当然啦,有能力的最好自己实现一下。(不过有些方法确实设计的超级精巧,直接读代码还看不懂,只能通过debug辅助学习源代码,更别提写这些方法了。。。。)
- ⑥ 不过我们在操作集合的过程中,尽量使用使用基于Stream的操作,这样能够不仅写起来爽,看起来更爽!真的是谁用谁知道。简直不要太爽!
下面是源码解析的部分
①首先我们先看一下JDK中ArrayList的属性有哪些:
private static final long serialVersionUID = 8683452581122892189L;
//默认的容量
private static final int DEFAULT_CAPACITY = 10;
//定义了一个空的数组,用于在用户初始化代码的时候传入的容量为0时使用。
private static final Object[] EMPTY_ELEMENTDATA = {};
//同样是一个空的数组,用于默认构造器中,赋值给顶层数组elementData。
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//底层数组,ArrayList中真正存储元素的地方。
transient Object[] elementData;
//用来表示集合中含有元素的个数
private int size;②看看我们的JDK中提供的构造器:(提供了三种构造器,分别是:需要提供一个初始容量、默认构造器、需要提供一个Collection集合。)
// 如果我们给定的容量等于零,它就会调用上面的空数组EMPTY_ELEMENTDATA。
// 如果大于零的话,就把底层的elementData进行初始化为指定容量的数组。
// 当然啦,如果小于零的话,就抛出了违法参数异常(IllegalArgumentException)。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* 默认的情况下,底层的elementData使用DEFAULTCAPACITY_EMPTY_ELEMENTDATA数组。
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
*
* 传入一个集合,首先把集合转化为数组,然后把集合的底层数组elementData指向该数组,
* 此时,底层数组有元素了,而size属性表示ArrayList内部元素的个数,所以需要把底层数组
* element的大小赋值给size属性,然后在它不等于0 的情况
* 下(也就是传进来的集合不为空),再通过判断保证此刻底层数组elementData数组的类型
* 和Object[]类型相同,如果不同,则拷贝一个Object[]类型的数组给elementData数组。
* 如果参数collection为null的话,将会报空指针异常。
*
* @param 一个Collection集合。
* @throws 如果参数collection为null的话,将会报异常(NullPointerException)
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}③缩至“最简洁”的容量:把ArrayList的底层elementData数组大小调整为size(size是ArrayList集合中存储的元素的个数)
那为什么会有这个方法呢?
因为我们在ArrayList中添加元素的时候,当ArrayList容量不足的时候,ArrayList会自动扩容,(调用的是ensureCapacityInternal()方法,这个方法后续会讲解。),一般扩充为原来容量的1.5倍,我们可能用不了那么多的空间,所以,有时需要这个来节省空间。
//modCount这个变量从字面意思看,它代表了修改的次数。实际上它就是这个意思。
//它是AbstractList中的 protected修饰的字段。
//我们首先解释一下它的含义:顾名思义,修改的次数(好像有点废话了)
//追根溯源还是由于ArrayList是一个线程不安全的类。这个变量主要是用来保证在多线程环境下使用
//迭代器的时候,同时在对集合做修改操作时,同一时刻只能有一个线程修改集合,如果多于一个
//线程进行对集合改变的操作时,就会抛出ConcurrentModificationException。
//所以,这是为线程不安全的ArrayList设计的。
//
//接着判断一下,如果ArrayList中元素的个数小于底层数组的长度,说明此时需要缩容。
//最后通过一个三位运算符判断,如果ArrayList中没有元素,则把底层数组设置为空数组。
//否则的话,就使用数组拷贝把底层数组的空间大小缩为size(元素个数)的大小。
//
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
④增加ArrayList实例的容量,如果有需要的话,以确保它至少能容纳元素的数量由传入的参数决定。
//官方的JDK中首先:需要确定一个最小的预期容量(minCapacity):
//它通过判断底层数组是否是DEFAULTCAPACITY_EMPTY_ELEMENTDATA(也就是说是不是使用了
//默认的构造器,),如果没有使用默认的构造器的话,它的最小预期容量是0,如果使用了默认
//构造器,最小预期容量(minCapacity)为默认容量(DEFAULT_CAPACITY:10),
//最后判断一下,如果参数大于最小预期的话,则需要调用ensureExplicitCapacity()方法
//扩容。该方法讲解,请看下面。
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
? 0
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
//因为需要进行扩容,也就是ArrayList发生了变化,所以需要modCount++.
//接着判断一下,如果我们传进来的参数(需要扩充的容量)大于底层数组的长度elemntData
//的时候,就需要扩容了。 扩容见下面的grow()方法。
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
//首先是新建一个变量oldCapacity,把底层数组的长度保存起来,然后通过oldCapacity做
//移位运算,向右移移位,就变成了oldCapacity的1.5倍了(可能小于1.5倍,后面就当做1.5倍
//对移位运算不懂的童鞋们可以上网查查移位运算的资料)。
//接着判断一下,如果newCapacity(它是底层数组容量的1.5倍)的大小仍然小于我们
//自定义传进来的参数minCapacity的大小,就把minCapacity的值赋值给newCapacity。
//接着再判断一下如果newCapacity的大小超过了最大数组容量(MAX_ARRAY_SIZE),
//MAX_ARRAY_SIZE代表了要分配数组的最大大小,如果试图分配更大的长度时,超出了虚拟机的限制。可能会导致OutOfMemoryError。
//该值是一个常量,源码中是:private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//就调用hugeCapacity进行扩容。最后把底层数组的容量扩充进行扩容为newCapacity的容量。
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
//如果超出MAX_ARRAY_SIZE,会调用该方法分配Integer.MAX_VALUE的空间。
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
⑤求ArrayList的大小。(一目了然的代码就不解释了。)
直接返回size即可,因为属性size代表了ArrayList的大小。
public int size() {
return size;
}
⑥判断ArrayList是否为空:
public boolean isEmpty() {
return size == 0;
}
⑦判断某一元素在ArrayList中的位置(从前向后遍历):
源码通过两次for循环遍历ArrayList,第一次用于判断当参数是空的时候,判断其位置,第二次用于不为空的时候,判断其位置,这两次循环中,如果找到了就返回元素在集合中的位置,如果没有找到则返回-1。可以看出,都是判断位置时都是通过底层数组elementData的遍历进行判断。
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
⑧判断是否包含某个元素:
通过调用上面的indexof()方法,如果该方法返回大于0,则存在该元素。
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
⑨判断某一元素在ArrayList中的位置(从后向前遍历):
和indexOf()方法差不多,就不解释了。(只不过这次是从后向前遍历)
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
⑩克隆方法。(实现了Cloneable接口)
直接调用超类Object的clone方法,然后强制转化一下类型,然后把底层数组拷贝一下,切记要将modCount设置为0,最后返回即可。(当抛出不支持克隆的异常的时候,将派出一个系你的内部错误的异常。)
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
11:转化为数组。(无参的方法)
这里调用了Arrays中的方法,不属于ArrayList的范畴,所以不细剖析内部的实现。后续的Arrays将会讲解。
(其实最顶层是调用的本地方法(本地方法是指用native修饰的方法,即是用其他语言实现的逻辑),这里数组拷贝使用的是System.arraycopy()方法。)
(其实,你看ArrayList的源码实现的时候,会发现很多涉及数组移动、数组复制的操作都是用System.arraycopy()处理的。)
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
12:转化为数组(传入一个和该方法返回值类型相同的数组)
前半段代码含义很清晰:首先判断一下传进来的数组a的大小是否小于需要转化为数组的ArrayList的数组元素的个数,如果小于的话,返回原来ArrayList底层存储元素的数组elementData,并且它的大小设置为ArrayList中元素的个数,且类型为传进来的类型参数a。(传进来的参数和返回值类型必须一致)
如果传进来数组a的带下不小于ArrayList中元素的个数的话,则先把底层数组elementData中的元素全部复制到a中。
接下来比较奇怪的一点是:如果a的长度大于size的话,则把a[size]设置为空。
我通过代码测试和查看官方解释得出如下结论:
- 如果数组a的length大于ArrayList中元素的个数size,则把a[size]置为空,从结果目的是为了区分ArrayList和转化后的数组的大小以及内容有哪些区别。
- 如果是等于的话,它和小于的结果显示一样。都是输出了转化后的数组,且元素和元素的个数与ArrayList中元素和元素个数完全一致。
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
13:查看底层elementData数组的某个元素:(直接通过数组访问)
E elementData(int index) {
return (E) elementData[index];
}
14:检查底层数组是否越界:
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
15:获取某个位置上的元素:(直接通过数组操作)
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
16:设置某一位置上的元素,并且返回该位置的旧值:(都是很简单,一目了然,不解释了)
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
17:添加一个元素:(这里和扩容用的是同样的辅助方法(辅助方法就是指private修饰的方法)。最后一次分析这些辅助方法。)
首先调用ensureCapacityInternal()方法,传入当前ArrayList中元素的个数+1;
进入该方法后,调用 ensureExplicitCapacity();在该方法的参数中调用calculateCapacity(elementData, minCapacity)进行容量的计算,如果我们的ArrayList是通过默认的构造器创建的话(就是代码中的elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA),则把minCapacity(也就是我们的size+1)和DEFAULT_CAPACITY(默认容量是10)比较,取较大者返回,否则的话,就返回minCapacity,接着调用ensureExplicitCapacity(int minCapacity)方法,如果minCapacity大于底层数组的长度,则需要调用grow(minCapacity)进行扩容,否则的话,add()方法中的ensureCapacityInternal(size + 1)什么也不做。(其实ensureCapacityInternal(size + 1)方法就是为了判断数组用不用扩容。)
如果需要扩容的话,则调用grow()方法:
下面解释一下grow()方法:
此时先定义一个变量oldCapacity,先把elementData数组的长度存储起来,然后定义一个新的变量newCapacity,用来存储扩容后的容量,即oldCapacity + (oldCapacity >> 1)(大概是oldCapacity)的1.5倍。接着判断一下,如果新容量小于我们设置的minCapacity的话,就把minCapacity赋值给newCapacity,
接着继续判断一下newCapacity是否大于MAX_ARRAY_SIZE,(这个MAX_ARRAY_SIZE代表了所能设置的数组的最大容量,如果超过这个值,可能导致内存溢出的错误(OutOfMemoryError),当然啦,如果超过的话,会将数组的容量设置为INTEGER.MAX_VALUE)。
总结:
添加一个元素之前,需要先判断一下容量(底层elementData数组的大小是否满足条件),如果容量不足, 足需要扩容,然后扩大后的容量取决于size+1,最后给elementData[size++]赋值就可以了,最后返回true。
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
18:为进行增加操作的方法添加范围检查。
如果index大于size或者小于0,则抛出IndexOutOfBoundsException。
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
19:在指定位置的地方添加新的元素:
先检查一下参数是否符合要求。
然后和上面通过ensureCapacityInternal(size + 1)判断是否需要增加容量,如果需要则扩容,如果不需要则什么也不做。
然后进行数组拷贝(其实就是移动底层数组elementData的元素),最后把要添加的元素添加到指定的位置,然后size++(size代表了ArrayList中元素的个数)。
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
20:移出指定位置上的元素:
老规矩,但凡是改变添加或者删除元素,都需要先检查参数是否合法,因为此方法需要返回就的值,所以需要先定义一个oldValue来存储旧的值。
重要的学习点:
在移动元素的时候,仍然选择进行数组的拷贝。但是,这里涉及到一个数组边界的问题:我们在计算出要移动的元素的个数后(这里可能有的童鞋看不懂为什么移动的个数是size-index-1,你可以画个图一下子就出来了,其实就是因为我们的index指代的是数组的下标,所以index位置处的元素以及它前面的元素的和是index+1,所以剩下的元素就是size-index-1,而剩下的元素,也就是index位置后的所有元素都需要向前移动,所以numMoved=size-index-1),移动的元素的个数大于0,我们下面数组拷贝(其实就是起到了移动元素的功能)才有意义,否则的话直接在elementData[–size]处设置为空就可以了。记住最后需要返回移除了的值。
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null;
return oldValue;
}
21:移除具体的元素:
提供两种方法,一种是应对参数为空的情况,另一种是应对参数不为空的情况。
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
22:快速删除指定位置上的元素:(这是一个辅助方法)(不提供给用户使用。)
这个是JDK提供的删除指定位置上元素的更快的方法。(从它的名字就看出来了。)
它直接跳过范围检查,并且不返回值。
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
23:清空ArrayList:
从代码中看,非常简单,通过for循环把底层数组中的元素全部置为null,然后把size设置为0就可以了。
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
24:把一个集合中的所有元素添加到ArrayList中:
首先把Collection参数转化为一个数组,该toArray()方法调用了Arrays类的copyOf()方法,最底层调用的System.arraycopy()方法。
然后把它的容量加上ArrayList的大小,然后和上面添加元素的方式一样,继续判断一下容量够不够。最后进行数组的拷贝,把参数中的所有元素添加到底层数组elementData中,然后把代表ArrayList中元素个数的size重新设置一下。最后如果参数的元素不为空,则返回true,表明把元素添加了进去,如果为空的话,说明没有添加元素,则返回false。
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
25:在ArrayList的指定位置上添加一个新的集合:
上面的一个方法同样是添加一个集合到ArrayList中,为什么不需要进行边界检查?这里就需要呢?
因为这个方法多传了一个参数index,它用来指代插入ArrayList中的位置,如果index是一个负值或其他不合法的值时,就无法进行后面的操作,而上面那个方法,默认直接插入ArrayLisr底层数组的后面,所以不需要检查。
numMoved=size-index;表示除了index位置前面的元素,Index位置上的元素以及index后面的元素都需要移动,如果size-index小于或等于0,则说明添加的位置在ArrayList中所有元素的后面,所以就无需第一个数组拷贝了(System.arraycopy(elementData, index, elementData, index + numNew,numMoved);)只需要进行第二个数组拷贝,通过System.arraycopy(a, 0, elementData, index, numNew);数组拷贝即可,最后返回numNew!=0,和上面的套路一样,不解释了。
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
26:移除某一个范围的元素:
进行修改操作还是得考虑为迭代器服务的modCount。
这个方法是protected修饰的,所以只有它的子类或者同一个包下才可以使用,所以,一般我们也用不到,但还是分析一下吧:
先给个结论吧:它删除下标从fromIndez到toIndex的元素,但是不删除下标为toIndex的元素。
首先求出要移动的元素,也就是说,toIndex位置的元素以及它后面的元素都要移动,然后通过System.arraycopy()把toIndex位置的元素以及它后面的元素移动到了fromIndex的位置上。最后把新的底层数组elementData的对应的原来的底层数组的最后一个位置的元素的后面所有元素都设置为null,然后调整数组的大小。
protected void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = size - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// clear to let GC do its work
int newSize = size - (toIndex-fromIndex);
for (int i = newSize; i < size; i++) {
elementData[i] = null;
}
size = newSize;
}
27:移除集合中包含的所有元素:
首先需要调用Objects类保证参数不为空,然后调用battchRemove()方法。
在battchRemove方法中,首先把底层数组elementData赋值给一个Object数组。接着通过遍历底层数组elementData和传进来的参数c,判断一下如果集合中不包含依次遍历的底层数组的元素,首先通过遍历底层数组elementData,判断参数集合c是否包含遍历过程中的每个元素,如果集合c不包含遍历的元素时,就把底层数组的该元素赋值给底层数组的前面的一个,如果包含,则什么也不做,最后底层数组变成了前面不包
含集合c中含有的元素。后面就是用来通过判断进行修改底层数组,最后返回即可。
这里的代码比较细,童鞋们可以自行debug一下, 学习起来就容易很多了,下面给的逻辑超清晰。
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, false);
}
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}
28:只保留参数中的元素和底层数组elementData中相同的元素,剩下的全部删除。
这个实现和上面的removeAll()差不多,调用的是同一个辅助方法。
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}
29:把ArrayList的状态保存为流。(序列化)writeObject(java.io.ObjectOutputStream s)。
30:从流中重新构建为ArrayList。(反序列化)readObject(java.io.ObjectInputStream s)。
31:返回List的专有迭代器(这个方法有个参数:用来表示从哪个位置迭代):
其中ListItr是ArrayList中的内部类。
ArrayList共有4个内部类,分别是:Itr、ListItr、SubList、ArrayListSpliterator。
public ListIterator<E> listIterator(int index) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index);
return new ListItr(index);
}
32:返回List的专有迭代器(这个方法没有参数,直接从开始位置进行迭代。)
public ListIterator<E> listIterator() {
return new ListItr(0);
}
33:普通迭代器:
public Iterator<E> iterator() {
return new Itr();
}
34:Itr内部类的分析:(代码中解释)
cursor:代表了返回的下一个元素的下标。lastRet:代表了返回最后一个元素的下标,如果没有最后一个元素,则返回-1。expectedModCount:期望的ArrayList修改的次数。
private class Itr implements Iterator<E> {
int cursor;
int lastRet = -1;
int expectedModCount = modCount;
Itr() {}
// 如果下一个元素的下标和底层数组elementData的数组大小不相等,则返回true。
public boolean hasNext() {
return cursor != size;
}
//首先调用checkForComodification()方法,检查一下modCount是否等于内部类定义的expectedModCount,如果不等于,则抛出ConcurrentModificationException。
//那个方法的作用是什么呢?
//由于ArrayList自身是线程不安全的,如果当前线程使用迭代器迭代ArrayList的时候,其他线程如果调用改变ArrayList的方法时候,而这些方法中都会修改modCount这个值,而这个值是在AbstractList中定义的protected变量,所以这里验证如果expectedModCount不等于modeCount的时候,说明有其他线程在修改ArrayList,所以该方法是用来保证带迭代的时候其他线程不能修改modeCount的值。
然后定义一个变量i保存下一个元素的下标,如果i>size,则抛出NoSuchElementException异常。
接着定义一个Object数组的引用指向底层数组,接着判断一下如果i>size就抛出异常,接着把让cursor自增,并通过elementData返回当前元素。
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
//在remove方法中,首先判断lasrRest是否小于0,如果小于0,表面它没有进行next操作,就
//会抛出IllegalStateException。因此我们在迭代的时候,必须保证每次都要先进行next()
//方法,然后进行删除remove()操作。
//接着继续检查一下是否有其他线程修改了ArrayList。
//接着再try语句中删除lastRet位置上的元素。接着把lastRet赋值给cursor,以便下一个next()方法使用,然后expectedModCount = modCount。
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
35:对ArrayList中的元素进行排序。
需要传入一个比较器,以实现自定义排序规则。
因为ArrayList底层是用数组实现的,所以ArrayList就直接使用了Arrays.sort()方法进行了ArrayList的排序。
@Override
@SuppressWarnings("unchecked")
public void sort(Comparator<? super E> c) {
final int expectedModCount = modCount;
Arrays.sort((E[]) elementData, 0, size, c);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。