
drools规则动态化实践解析
作者:京东云开发者
一 、 规则引擎业务应用背景
业务逻辑中经常会有一些冗长的判断,需要写特别多的if else,或者一些判断逻辑需要经常修改。这部分逻辑如果以java代码来实现,会面临代码规模控制不住,经常需要修改逻辑上线等多个弊端。这时候我们就需要集成规则引擎对这些判断进行线上化的管理
二、规则引擎选型
目前开源的规则引擎也比较多,根据原有项目依赖以及短暂接触过的规则引擎,我们着重了解了一下几个
drools:
-社区活跃,持续更新
-使用广泛
-复杂
-学习成本较高
easy-rule:
-简单易学
-满足使用诉求
-长时间未发布新版
easycode:
-京东物流同事维护的平台
-基于flowable dmn实现
-配置简单直观
-已有大量系统使用
总结:
- 简单配置型规则可以接入easycode,平台提供配置页面,通过jsf交互。
- 复杂规则,需要动态生成规则,easycode目前还不支持。drools从流行度及活跃度考虑,都比easy-rule强,所以选择drools。
三、 drools简单示例
3.1 引入依赖
<dependency>
<groupId>org.kie</groupId>
<artifactId>kie-spring</artifactId>
<version>${drools.version}</version>
</dependency>
3.2 写drl文件
我们写一个简单的demo
规则为:
匹配一个sku对象
0<价格<=100 10积分
100<价格<=1000 100积分
1000<价格<=10000 1000积分
在resources文件夹下新增 rules/skupoints.drl 文件 内容如下
package com.example.droolsDemo
import com.example.droolsDemo.bean.Sku;
// 10积分
rule "10_points"
when
$p : Sku( price > 0 && price <= 100 )
then
$p.setPoints(10);
System.out.println("Rule name is [" + drools.getRule().getName() + "]");
end
// 100积分
rule "100_points"
when
$p : Sku( price > 100 && price <= 1000 )
then
$p.setPoints(100);
System.out.println("Rule name is [" + drools.getRule().getName() + "]");
end
// 1000积分
rule "1000_points"
when
$p : Sku( price > 1000 && price <= 10000 )
then
$p.setPoints(1000);
System.out.println("Rule name is [" + drools.getRule().getName() + "]");
end
3.3 使用起来
@Test
public void testOneSku() {
Resource resource = ResourceFactory.newClassPathResource("rules/skupoints.drl");
KieHelper kieHelper = new KieHelper();
kieHelper.addResource(resource);
KieBase kieBase = kieHelper.build();
KieSession kieSession = kieBase.newKieSession();
Sku sku1 = new Sku();
sku1.setPrice(10);
kieSession.insert(sku1);
int allRules = kieSession.fireAllRules();
kieSession.dispose();
System.out.println("sku1:" + JSONObject.toJSONString(sku1));
System.out.println("allRules:" + allRules);
}
@Test
public void testOneSku2() {
Resource resource = ResourceFactory.newClassPathResource("rules/skupoints.drl");
KieHelper kieHelper = new KieHelper();
kieHelper.addResource(resource);
KieBase kieBase = kieHelper.build();
StatelessKieSession statelessKieSession = kieBase.newStatelessKieSession();
Sku sku1 = new Sku();
sku1.setPrice(10);
statelessKieSession.execute(sku1);
System.out.println("sku1:" + JSONObject.toJSONString(sku1));
}
3.4 输出
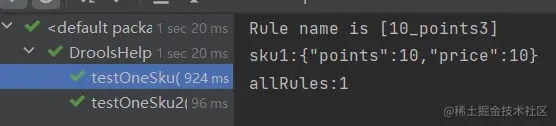
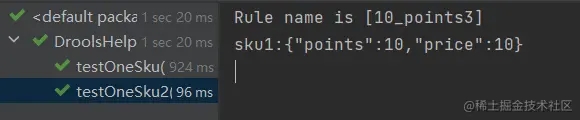
3.5 总结
如上,我们简单使用drools,仅需要注意drl文件语法。根据drl文件生成规则的工作内存,通过KieSession或者StatelessKieSession与工作内存交互。整个流程并不复杂。注意 KieHelper仅是在演示中简单使用,demo中包含使用bean来管理容器的方式,即便在简单使用场景也不应通过 KieHelper来重复加载规则。
但是,这样并不能满足我们线上化判断,或者频繁更改规则的诉求。于是我们在实践中需要对drools更高阶的使用方式。
四、 drools动态化实践
从以上简单demo中我们可以看出,规则依赖drl文件存在。而业务实际使用中,需要动态对规则进行修改,无法直接使用drl文件。
以下是我了解过的四种动态的方案:
- drt文件,创建模板,动态生成drl文件,也是我们目前所用的方式。
- excel文件导入,实际上和模板文件类似,依然无法直接交给业务人员来使用。
- 自己拼装String,动态生成drl文件,网上大多数博文使用方式,过于原始。
- api方式,drools的api方式复杂,使用需要对drl文件有足够的了解。
最后介绍以下drools在项目中的实际使用方式
4.1 配置规则
我们的业务场景可以理解为多个缓冲池构成的一个网状结构。
示例如下:
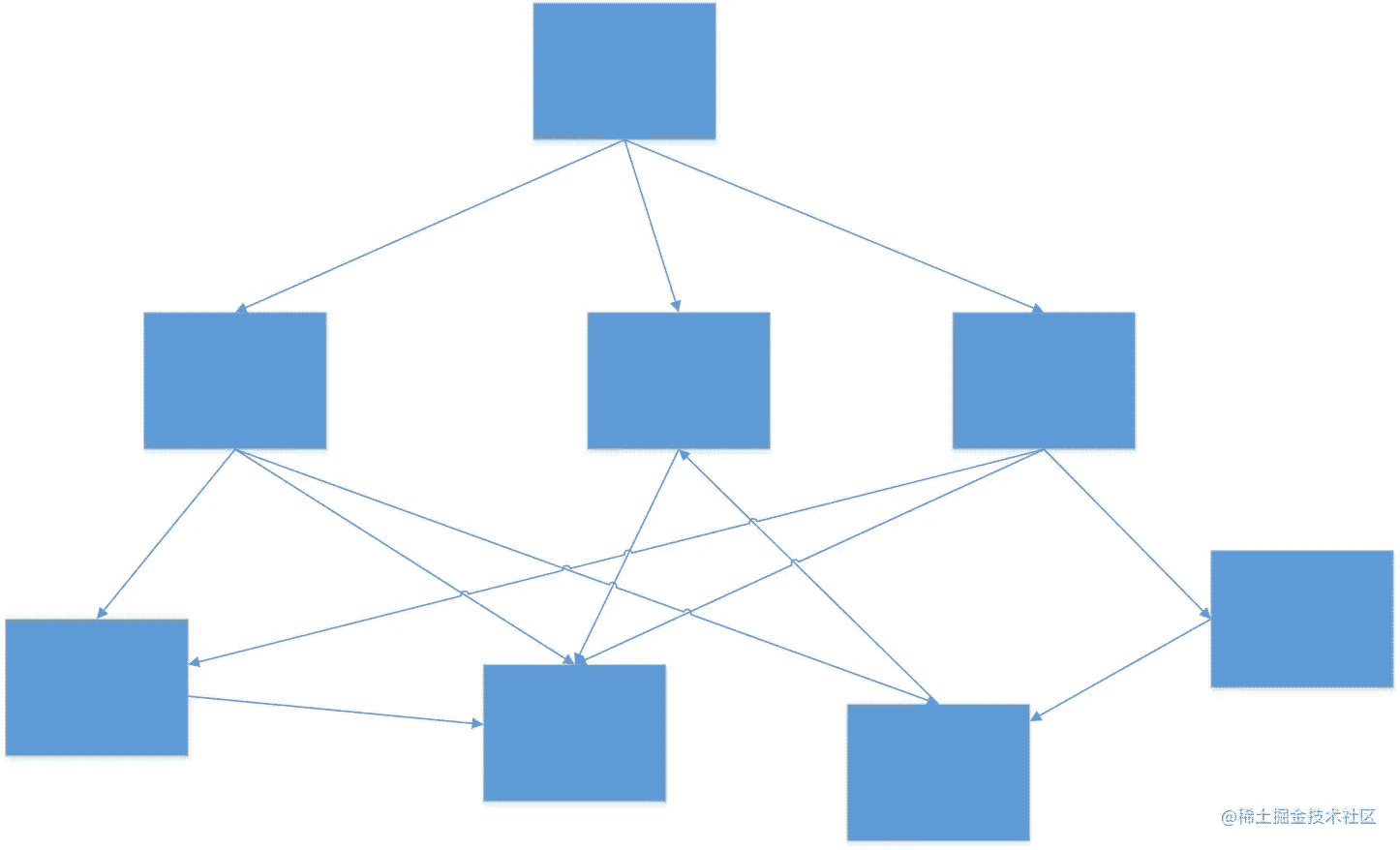
上图中每个方块为一个缓冲池,每条连线为一条从A缓冲池流向B缓冲池的规则。实际场景中缓冲池有数百个,绝大多数都有自己的规则,这些规则构成一张复杂的网络。基于业务诉求,缓冲池的流向规则需要经常变动,我们需要在业务中能动态改变这些连线的条件,或者改变连线。在这种情况下,如果使用静态的drl文件来实现这些规则,需要数百规则文件,维护量大,且每次修改后使规则生效的代价较大。在此背景下,我们尝试drools高阶应用,既规则动态化实践。
我们在创建缓冲池的页面中加入了流向规则的创建环节。每个缓冲池维护自己的流向规则,即为自己的一根连线。如下图:

4.2 动态生成drl
drt文件内容:
(实际业务模板中比这个复杂,有一定校验及业务逻辑,此处做了简化)
template header
// 模板需要使用的参数
id
cluePoolId
sourceList
cooperateTypeList
regionId
secondDepartmentId
battleId
outCluePoolId
amountCompareFlag
amount
salience
package rulePoolOut
// 全局对象
global java.util.List list;
global java.util.List stopIdList;
global java.util.List ruleIdList;
// 引入的java类
import com.example.drools.bean.ClueModel
import org.springframework.util.CollectionUtils
import org.apache.commons.lang3.StringUtils;
import java.lang.Long
template "CluePoolOut"
// 规则名称
rule "clue_pool_@{cluePoolId}_@{id}"
// 参数 标识当前的规则是否不允许多次循环执行
no-loop true
// 参数 优先级
salience @{salience}
// 参数 规则组 本组规则只能有一个生效
activation-group "out_@{cluePoolId}"
// 匹配的LHS
when
$clue:ClueModel(cluePoolId == @{cluePoolId})
ClueModel(CollectionUtils.isEmpty(@{sourceList}) || source memberOf @{sourceList})
ClueModel(CollectionUtils.isEmpty(@{cooperateTypeList}) || cooperateType memberOf @{cooperateTypeList})
ClueModel(secondDepart == @{secondDepartmentId})
ClueModel(regionNo == @{regionId})
ClueModel(battleId == @{battleId})
ClueModel(null != estimateOrderCount && (Long.valueOf(estimateOrderCount) @{amountCompareFlag} Long.valueOf(@{amount})))
// 如果配置要执行的RHS 支持java语法
then
ruleIdList.add(@{id});
$clue.setCluePoolId(Long.valueOf(@{outCluePoolId}));
list.add(@{outCluePoolId});
update($clue);
}
end
end template
生成drl内容: 根据一个队列及模板的路径进行drl内容的生成
List<CrmCluePoolDistributeRuleBusinessBattleVO> ruleCenterVOS = new ArrayList<>();
CrmCluePoolDistributeRuleBusinessBattleVO vo = new CrmCluePoolDistributeRuleBusinessBattleVO();
vo.setCooperateTypeList(Lists.newArrayList(1, 2, 4));
vo.setAmountCompareFlag(">");
vo.setAmount(100L);
ruleCenterVOS.add(vo);
String drl = droolsManager.createDrlByTemplate(ruleCenterVOS, "rules/CluePoolOutRuleTemplate.drt");
public String createDrlByTemplate(Collection<?> objects, String path) {
ObjectDataCompiler compiler = new ObjectDataCompiler();
try (InputStream dis = ResourceFactory.newClassPathResource(path, this.getClass()).getInputStream()) {
return compiler.compile(objects, dis);
} catch (IOException e) {
log.error("创建drl文件失败!", e);
}
return null;
}
4.3 加载drl
上边的简单示例中,我们使用了KieHelper 来加载规则文件至工作内存中。实际上我们不可能在每次匹配中重新加载所有规则文件,所以我们可以单例的使用规则容器,通过以下方式或者也可以使用@Bean等方式来管理容器。
private final KieServices kieServices = KieServices.get(); // kie文件系统,需要缓存,如果每次添加规则都是重新new一个的话,则可能出现问题。即之前加到文件系统中的规则没有了 private final KieFileSystem kieFileSystem = kieServices.newKieFileSystem(); // 需要全局唯一一个 private KieContainer kieContainer;
通过将内容写入 kieFileSystem然后重新加载整个 kieBase即可重新加载规则,但是这种行为比较重,代价较大
也可以通过 kieBase新增一个文件来进行加载,代价小,但是同步各个实例的代价较大。
KnowledgeBaseImpl kieBase = (KnowledgeBaseImpl)kieContainer.getKieBase(kieBaseName);
KnowledgeBuilder builder = KnowledgeBuilderFactory.newKnowledgeBuilder();
Resource resource = ResourceFactory.newReaderResource(new StringReader(ruleContent));
builder.add(resource,ResourceType.DRL);
if (builder.hasErrors()) {
throw new RuntimeException("增加规则失败!" + builder.getErrors().toString());
}
kieBase.addPackages(builder.getKnowledgePackages());
4.4 匹配
通过 StatelessKieSession与规则引擎交互
// 获取一个链接
StatelessKieSession kieSession = droolsManager.getStatelessKieSession(RuleTemplateEnum.CLUE_POOL_OUT_RULE.getKieBaseName());
// 创建全局变量对象
List<Long> list = new ArrayList<>();
List<Long> stopIdList = Lists.newArrayList();
List<String> result = new ArrayList<>();
List<Long> ruleIdList = new ArrayList<>();
// 塞入全局变量
kieSession.setGlobal("ruleIdList", ruleIdList);
kieSession.setGlobal("list", list);
kieSession.setGlobal("stopIdList", stopIdList);
kieSession.setGlobal("result", result);
// 执行规则
kieSession.execute(clueModel);
如果使用 KieSession则需要在使用完成后进行关闭
kieSession.insert(clueModel); kieSession.fireAllRules(); kieSession.dispose();
在执行规则的过程中可以加入各种监听器对过程中各种变化进行监听。篇幅原因交给各位去探索。
五、 总结
从上边的流程中我们体验了动态规则的创建以及使用。动态规则满足了我们规则动态变化,规则统一管理的诉求。
我也总结了在这种使用方式下drools的几个优缺点。
优点:
- 规则动态化方便
- 在工作内存中匹配规则性能好
- 几乎可以满足所有的规则需求
- 内置方法丰富完善
缺点:
- 分布式一致性需要自行处理
- 需要研发了解drl语法
- 学习曲线陡峭
- 匹配过程监控手段需要自行实现
以上就是drools规则动态化实践解析的详细内容,更多关于drools规则动态化的资料请关注脚本之家其它相关文章!