
Kotlin协程Context应用使用示例详解
作者:无糖可乐爱好者
1.Context的应用
Context在启动协程模式中就已经遇到过叫CoroutineContext,它的意思就是协程上下文,线程的切换离不开它。
在启动协程模式中也说明过为什么不用传递Context,因为它有一个默认值EmptyCoroutineContext,需要注意的是这个Context是不可以切换线程的因为它是一个空的上下文对象,如果有这个需求就需要传入具体的Context,例如Dispatchers.IO。
//launch
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
//runBlocking
public actual fun <T> runBlocking(context: CoroutineContext, block: suspend CoroutineScope.() -> T): T {
}
//async
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T> {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyDeferredCoroutine(newContext, block) else
DeferredCoroutine<T>(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
当传入Dispatchers.IO时执行的线程有什么变化呢?
fun main() = runBlocking {
val user = contextTest()
logX(user)
}
suspend fun contextTest(): String {
logX("Start Context")
withContext(Dispatchers.IO) {
logX("Loading Context.")
delay(1000L)
}
logX("After Context.")
return "End Context"
}
fun logX(any: Any?) {
println(
"""
================================
$any
Thread:${Thread.currentThread().name}
================================
""".trimIndent()
)
}
//输出结果:
//================================
//Start Context
//Thread:main @coroutine#1
//================================
//================================
//Loading Context.
//Thread:DefaultDispatcher-worker-1 @coroutine#1
//================================
//================================
//After Context.
//Thread:main @coroutine#1
//================================
//================================
//End Context
//Thread:main @coroutine#1
//================================
从输出结果可以得出一个结论:默认是运行在main线程中当传入Dispatchers.IO之后就会进入到IO线程执行,然后在IO线程执行完毕后又回到了main线程,那么除了这两个线程之外是否还有其他线程呢?答案是有,除了这两个之外还有2个:
public actual object Dispatchers {
/**
* 用于CPU密集型任务的线程池,一般来说它内部的线程个数是与机器 CPU 核心数量保持一致的
* 不过它有一个最小限制2,
*/
public actual val Default: CoroutineDispatcher = DefaultScheduler
/**
* 主线程,在Android中才可以使用,主要用于UI的绘制,在普通JVM上无法使用
*/
public actual val Main: MainCoroutineDispatcher get() = MainDispatcherLoader.dispatcher
/**
* 不局限于任何特定线程,会根据运行时的上下文环境决定
*/
public actual val Unconfined: CoroutineDispatcher = kotlinx.coroutines.Unconfined
/**
* 用于执行IO密集型任务的线程池,它的数量会多一些,默认最大线程数量为64个
* 具体的线程数量可以通过kotlinx.coroutines.io.parallelism配置
* 它会和Default共享线程,当Default还有其他空闲线程时是可以被IO线程池复用。
*/
public val IO: CoroutineDispatcher = DefaultIoScheduler
}
除了上述几个Dispatcher之外还可以自定义Dispatcher
fun main() = runBlocking {
val user = contextTest()
logX(user)
}
suspend fun contextTest(): String {
logX("Start Context")
//使用自定义的dispatcher
// ↓
withContext(myDispatcher) {
logX("Loading Context.")
delay(100L)
}
logX("After Context.")
return "End Context"
}
val myDispatcher = Executors.newSingleThreadExecutor {
Thread(it, "myDispatcher").apply { isDaemon = true }
}.asCoroutineDispatcher()
//输出结果
//================================
//Start Context
//Thread:main @coroutine#1
//================================
//================================
//Loading Context.
//Thread:myDispatcher @coroutine#1
//================================
//================================
//After Context.
//Thread:main @coroutine#1
//================================
//================================
//End Context
//Thread:main @coroutine#1
//================================
通过 asCoroutineDispatcher() 这个扩展函数,创建了一个 Dispatcher。从这里也能看到,Dispatcher 的本质仍然还是线程。那么可以得出一个结论:协程是运行在线程之上的。
前面还有一个线程Unconfined,它是一个特殊的线程,没有指定可运行在哪里,但是这个使用时需要谨慎甚至最好不用,通过下面的的代码对比一下:
//不设置执行线程
fun main() = runBlocking {
logX("Start launch.")
launch {
logX("Start Delay launch.")
delay(1000L)
logX("End Delay launch.")
}
logX("End launch")
}
//输出结果
//================================
//Start launch.
//Thread:main @coroutine#1
//================================
//================================
//End launch
//Thread:main @coroutine#1
//================================
//================================
//Start Delay launch.
//Thread:main @coroutine#2
//================================
//================================
//End Delay launch.
//Thread:main @coroutine#2
//================================
//设置执行线程
fun main() = runBlocking {
logX("Start launch.")
// 变化在这里
// ↓
launch(Dispatchers.Unconfined) {
logX("Start Delay launch.")
delay(1000L)
logX("End Delay launch.")
}
logX("End launch")
}
//输出结果
//================================
//Start launch.
//Thread:main @coroutine#1
//================================
//================================
//Start Delay launch.
//Thread:main @coroutine#2
//================================
//================================
//End launch
//Thread:main @coroutine#1
//================================
//================================
//End Delay launch.
//Thread:kotlinx.coroutines.DefaultExecutor @coroutine#2
//================================
经过对比可以发现加入Dispatchers.Unconfined会导致代码的运行顺序被修改,这种错误的产生一定会对项目调试造成非常大的影响,而且Dispatchers.Unconfined的定义初衷也不是为了修改代码的执行顺序。
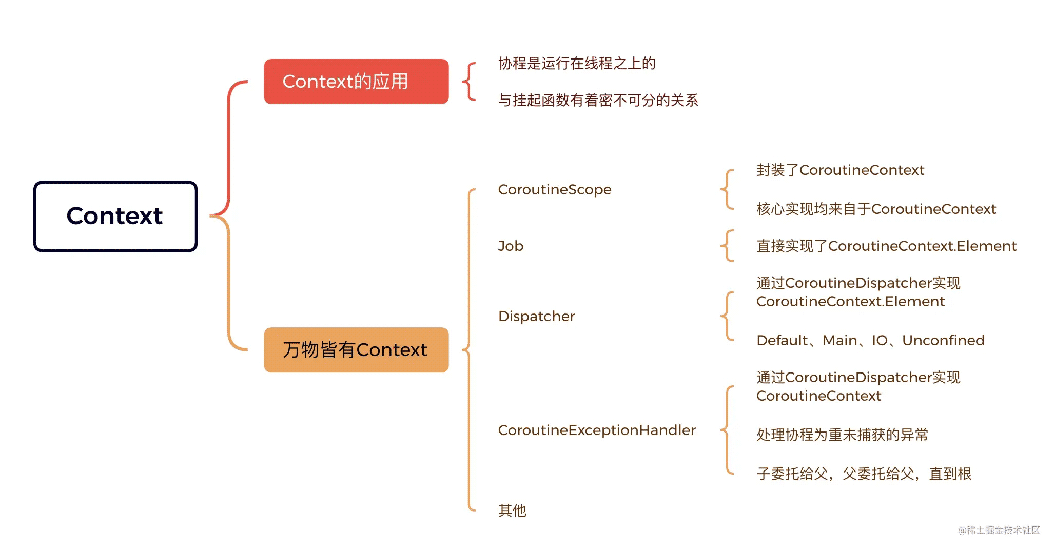
2.万物皆有 Context
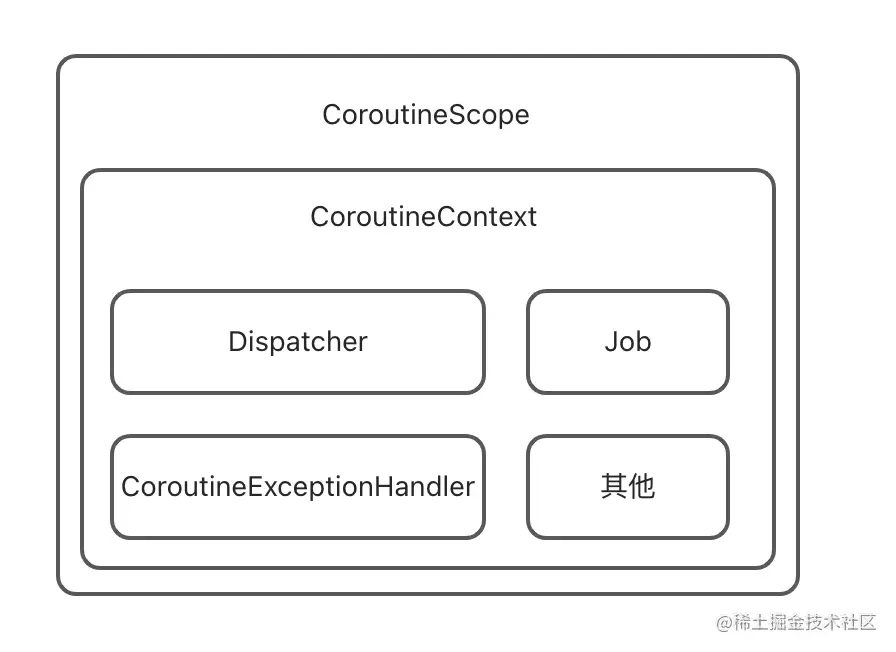
在Kotlin协程中,但凡是重要的概念都直接或间接的与CoroutineContext有关系,例如Job、Dispatcher、CoroutineExceptionHandler、CoroutineScope等
1.CoroutineScope
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
/**
* CoroutineScope的作用域就是把CoroutineContext做了一层封装,核心实现均来自于CoroutineContext
*/
public interface CoroutineScope {
/**
* 此作用域的上下文。上下文被作用域封装,并用于实现作为作用域扩展的协程构建器
*/
public val coroutineContext: CoroutineContext
}
CoroutineScope的源码注释写的很清楚,核心实现在于CoroutineContext,CoroutineScope只是做了封装而已,然后就可以批量的控制协程了,例如下面的代码实现:
fun main() = runBlocking {
val scope = CoroutineScope(Job())
scope.launch {
logX("launch 1")
}
scope.launch {
logX("launch 2")
}
scope.launch {
logX("launch 3")
}
scope.launch {
logX("launch 4")
}
delay(500L)
scope.cancel()
delay(1000L)
}
2.Job
//Job#Job
public interface Job : CoroutineContext.Element {
}
//CoroutineContext#Element
public interface CoroutineContext {
/**
* 从该上下文返回具有给定键的元素,或返回null
*/
public operator fun <E : Element> get(key: Key<E>): E?
/**
* 从初始值开始累积此上下文的条目,并从左到右对当前累加器值和此上下文的每个元素应用操作。
*/
public fun <R> fold(initial: R, operation: (R, Element) -> R): R
/**
* 返回包含该上下文和其他上下文元素的上下文。
* 删除这个上下文中与另一个上下文中具有相同键的元素。
*/
public operator fun plus(context: CoroutineContext): CoroutineContext {}
/**
* 返回包含此上下文中的元素的上下文,但不包含具有指定键的元素。
*/
public fun minusKey(key: Key<*>): CoroutineContext
/**
* CoroutineContext元素的键
*/
public interface Key<E : Element>
/**
* CoroutineContext的一个元素。协程上下文的一个元素本身就是一个单例上下文。
*/
public interface Element : CoroutineContext {
}
}
Job实现了CoroutineContext.Element,CoroutineContext.Element又实现了CoroutineContext那么就可以认为Job间接实现了CoroutineContext,所以可以认定Job就是一个CoroutineContext。
所以在定义Job时下面两种定义方式都可以:
val job: CoroutineContext = Job() val job: Job = Job()
3.Dispatcher
public actual object Dispatchers {
public actual val Default: CoroutineDispatcher = DefaultScheduler
public actual val Main: MainCoroutineDispatcher get() = MainDispatcherLoader.dispatcher
public actual val Unconfined: CoroutineDispatcher = kotlinx.coroutines.Unconfined
public val IO: CoroutineDispatcher = DefaultIoScheduler
public fun shutdown() { }
}
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {}
public interface ContinuationInterceptor : CoroutineContext.Element {
Dispatcher中的每一个线程继承自CoroutineDispatcher,CoroutineDispatcher实现了ContinuationInterceptor接口,ContinuationInterceptor又实现了CoroutineContext接口,由此就可以知道Dispatcher和CoroutineContext是如何产生关联的了,或者说Dispatcher就是CortinueContext。
4.CoroutineExceptionHandler
/**
* 协程上下文中一个可选的元素,用于处理未捕获的异常
*/
public interface CoroutineExceptionHandler : CoroutineContext.Element {
/**
*
*/
public companion object Key : CoroutineContext.Key<CoroutineExceptionHandler>
/**
* 处理给定上下文中未捕获的异常。如果协程有未捕获的异常,则调用它。
*/
public fun handleException(context: CoroutineContext, exception: Throwable)
}
CoroutineExceptionHandler主要用来处理协程中未捕获的异常,未捕获的异常只能来自根协程,子协程未捕获的异常会委托给它们的父协程,父协程也委托给父协程,以此类推,直到根协程。所以安装在它们上下文中的CoroutineExceptionHandler永远不会被使用。
以上就是Kotlin协程Context应用使用示例详解的详细内容,更多关于Kotlin协程Context应用的资料请关注脚本之家其它相关文章!