
Python基于HOG+SVM/RF/DT等模型实现目标人行检测功能
作者:Together_CZ
当下基本所有的目标检测类的任务都会选择基于深度学习的方式,诸如:YOLO、SSD、RCNN等等,这一领域不乏有很多出色的模型,而且还在持续地推陈出新,模型的迭代速度很快,其实最早实现检测的时候还是基于机器学习去做的,HOG+SVM就是非常经典有效的一套框架,今天这里并不是说要做出怎样的效果,而是基于HOG+SVM来实践机器学习检测的流程。
这里为了方便处理,我是从网上找的一个数据集,主要是行人检测方向的,当然了这个用车辆检测、火焰检测等等的数据集都是可以的,本质都是一样的。
首先看下数据集,数据集主要分为两个类别,一个类别是包含行人的,另一个类别是不包含行人的,首先看下不包含行人的:

接下来看下包含行人的:

看到这里,其实就不难理解,这里的SVM扮演的主要作用就是二分类模型了。
接下来我们需要对原始图像的数据集进行特征提取计算,这里是基于HOG的方式实现的,可以自行实现HOG特征向量提取方法,也可以直接使用skimage提供的HOG提取器来一步实现,这里为了方便,我是直接使用的skimage提供的HOG方法,核心实现如下:
def img2Feature(dataDir="data/",save_path="feature.json"):
"""
特征提取计算
"""
feature=[]
for one_label in os.listdir(dataDir):
print("one_label: ", one_label)
oneDir=dataDir+one_label+'/'
for one_pic in os.listdir(oneDir):
one_path=oneDir+one_pic
print("one_path: ", one_path)
#加载图像
one_img = imread(one_path, as_gray=True)
one_vec = hog(one_img, orientations=orientations, pixels_per_cell=pixels_per_cell, cells_per_block=cells_per_block,
visualize=visualize, block_norm=normalize)
one_vec=one_vec.tolist()
one_vec.append(one_label)
feature.append(one_vec)
print("feature_length: ", len(feature))
with open(save_path,"w") as f:
f.write(json.dumps(feature))HOG提取得到的向量维度很大,这里就不进行展示了。
之后就可以训练模型了,核心实现如下:
resDir = "results/"
if not os.path.exists(resDir):
os.makedirs(resDir)
data = "feature.json"
dict1 = DTModel(data=data, rationum=0.25, model_path=resDir + "DT.model")
dict2 = RFModel(data=data, rationum=0.25, model_path=resDir + "RF.model")
dict3 = SVMModel(data=data, rationum=0.25, model_path=resDir + "SVM.model")
res_dict = {}
res_dict["DT"], res_dict["RF"], res_dict["SVM"] = dict1, dict2, dict3
with open(resDir + "res_dict.json", "w") as f:
f.write(json.dumps(res_dict))
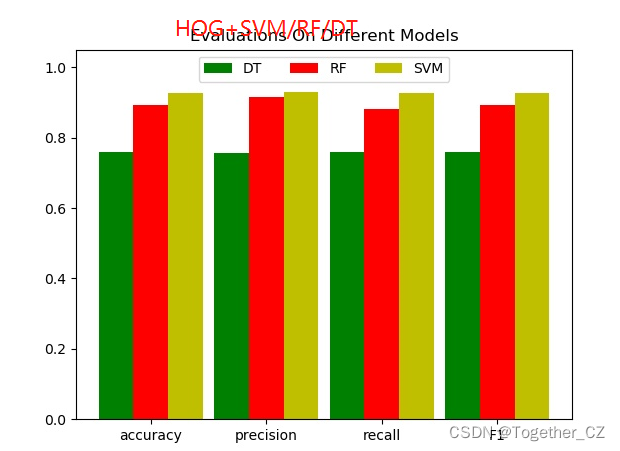
comparePloter(dict1, dict2, dict3, save_path=resDir + "comparePloter.jpg")这里,我是同时使用了决策树DT、随机森林RF、支持向量机SVM三种模型来进行分类和对比可视化,对比结果如下:
{
"DT": {
"precision": 0.7573482282561567,
"recall": 0.7597846737437716,
"F1": 0.7584933696379963,
"accuracy": 0.7584933696379963
},
"RF": {
"precision": 0.9156160607479066,
"recall": 0.8801773928046967,
"F1": 0.893107332148193,
"accuracy": 0.893107332148193
},
"SVM": {
"precision": 0.9281402443868877,
"recall": 0.9272928963585789,
"F1": 0.9277128372009962,
"accuracy": 0.9277128372009962
}
}为了直观展示,这里对三种模型的性能进行可视化展示,如下所示:
接下来我们对训练好的模型调用进行测试,查看具体的效果,随机选取了几张网上的图像,测试结果如下:



整体看下来,效果表现一般,不过这个也只是主要以实践流程为目的,并不是实际做项目的,而且各个环节都有优化提升的空间,模型的参数也都没有调过。
到此这篇关于Python基于HOG+SVM/RF/DT等模型实现目标检测[行人检测]的文章就介绍到这了,更多相关Python目标检测内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!