
python爬虫之请求模块urllib的基本使用
作者:hacker707
前言
💖在实现网络爬虫的爬取工作时,就必须使用网络请求,只有进行了网络请求才可以对响应结果中的数据进行提取,urllib模块是python自带的网络请求模块,无需安装,导入即可使用。下面将介绍如果使用python中的urllib模块实现网络请求💖
urllib的子模块
| 模块 | 描述 |
|---|---|
| urllib.request | 用于实现基本HTTP请求的模块 |
| urllib.error | 异常处理模块,如果在发送网络请求的过程时出现错误,可以捕获异常进行有效处理 |
| urllib.parse | 用于解析URL的模块 |
| urllib.robotparser | 用于解析robots.txt文件,判断网站是否可以爬取信息 |
HttpResponse常用方法与属性获取信息
通过urllib.request() 获取的对象类型是HttpReponse,有以下几种常用的方法,示例如下:
import urllib.request
# 定义一个url(你要爬取的网址)
url = 'https://www.baidu.com'
# 添加请求头信息
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
# 创建Request对象
res = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送网络请求
response = urllib.request.urlopen(res)
# read()函数可以获取响应,但返回的响应格式是二进制的,需要解码
# 解码:decode('编码格式') 编码格式在Response Headers,Content_Type里面查看
print('baidu官网HTML代码如下:\n', response.read().decode('utf-8'))
# HTTPResponse这个类型
# 常见方法:read、readline、readlines、getcode、status、geturl、getheaders、getheader
# print(type(response)) # response是HTTPResponse的类型
# (1) 按照一个字节一个字节去读
content = response.read()
print(content)
# 读取具体的n个字节,在read()函数中传参即可
content2 = response.read(5)
print(content2)
# (2) 按行读取,但是只能读取一行
content3 = response.readline()
print(content3)
# (3) 按行读取,并且读取所有行
content4 = response.readlines()
print(content4)
# (4) 返回状态码的方法:200状态码没有问题,其他的状态码可能有问题
print('响应状态码为', response.getcode())
print('响应状态码为', response.status)
# (5) 返回访问的目标的url地址
print('响应访问的url地址为', response.geturl())
# (6) 获取的是响应头所有信息
print('响应头所有信息为', response.getheaders())
# (7)获取响应头指定信息
print('响应头指定信息为', response.getheader('Content-Type'))
urlli.parse的使用(一般用于处理带中文的url)
💡使用urllib模块向一个携带中文字样的url发送请求时 ,会报错:‘ascii’ codec can’t encode characters in position 10-11: ordinal not in range(128)💡
字典格式的处理方式
步骤
(1)导入request和parse模块
(2)添加请求头header(重构ua)反反爬第一步
(3)使用urllib.parse方法处理url中的中文字样(使用字典存储要处理的内容,经过parse处理返回正常的url地址)
(4)使用+拼接固定的url地址和经过处理后的url地址
(5)创建请求对象
(6)使用urlopen()模拟浏览器像服务器发送网络请求
(7)打印获取响应对象里面的内容,并进行decode解码
import urllib.parse # 导入parse解析模块
import urllib.request # 导入request模块
url = 'https://www.baidu.com/s?wd=酷我'
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
# 通过urllib.parse处理url中的中文字样--> 得到可以通过urllib发送请求的url地址
# 字典格式的处理方式
org = {'wd': '酷我'}
# 经过处理之后返回wd=%E9%85%B7%E6%88%9
result = urllib.parse.urlencode(org)
# 使用+拼接固定的url地址和经过处理的url地址
# https://www.baidu.com/s?wd=%E9%85%B7%E6%88%91
new_url = 'https://www.baidu.com/s?' + result
# 1、构造请求对象
res = urllib.request.Request(new_url, headers=header)
# 2、发送请求 获取响应
response = urllib.request.urlopen(res)
# 3、获取响应对象里面的内容(获取网页源码)
print(response.read().decode('utf-8'))
字符串格式的处理方式
步骤
(1)导入request和parse模块
(2)添加请求头header(重构ua)反反爬第一步
(3)使用urllib.parse.quote方法处理url中的中文字样(用一个变量存储酷我字样,使用parse.quote处理即可返回酷我经过处理的url地址)
(4)使用+拼接固定的url地址(需要加上wd=)和经过处理后的url地址(酷我字样处理后的url地址)
(5)创建请求对象
(6)使用urlopen()模拟浏览器像服务器发送网络请求
(7)打印获取响应对象里面的内容,并进行decode解码
import urllib.request
import urllib.parse
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
# 第二种 字符串格式的处理方式
string_org = '酷我'
# %E9%85%B7%E6%88%91
string_result = urllib.parse.quote(string_org)
# 使用+拼接固定的url地址(需要加上wd=)和经过处理后的url地址
new_string_url = 'https://www.baidu.com/s?wd=' + string_result
# 1、构造请求对象
res = urllib.request.Request(new_string_url, headers=header)
# 2、发送请求 获取响应
response = urllib.request.urlopen(res)
# 3、获取响应对象里面的内容,并进行decode解码
print(response.read().decode('utf-8'))
简单了解web前端
HTTP基本原理
HTTP(HpperText Transfer Protocol),即超文本传输协议,是互联网上应用广泛的一种网络协议。HTTP是利用TCP在Web服务器和客户端之间传输信息的协议,客户端使用Web浏览器发起HTTP请求给Web服务器,Web服务器发送被请求的信息给客户端。
HTTP协议常用的请求方法
| 方法 | 描述 |
|---|---|
| GET | 请求指定的页面信息,并返回响应内容 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中。POST请求可能会导致新的资源的建立、或已有资源的修改 |
| GEAD | 类似于GET请求,只不过返回的响应中没有具体的内容,用于获取报文头部信息 |
| PUT | 从客户端像服务器传送的数据取代指定的文档内容 |
| DELEAE | 请求服务器删除指定内容 |
| OPTIONS | 允许客户端查看服务器性能 |
HTML状态码及其含义
| 代码 | 含义 |
|---|---|
| 信息,请求收到,继续处理 | |
| 2** | 成功,行为被成功地接受、理解和采纳 |
| 3** | 重定向,为了完成请求必须进一步执行的动作 |
| 4** | 客户端错误,请求包含语法错误或者请求无法实现 |
| 5** | 服务器错误,服务器不能实现一种明显无效的请求 |
浏览器中的请求与响应
💡最好使用谷歌浏览器💡
使用谷歌浏览器访问baidu官网,查看请求和响应的具体步骤如下:
1在谷歌浏览器输入网址进入baidu官网
2按下F12键(或单击鼠标右键选择”检查“选项),审查页面元素
3单击谷歌浏览器调试工具中“Network”选项,按下F5 键(或手动刷新页面),单击调试工具中的“Name”栏目下的网址,查看请求与响应信息。

Genral
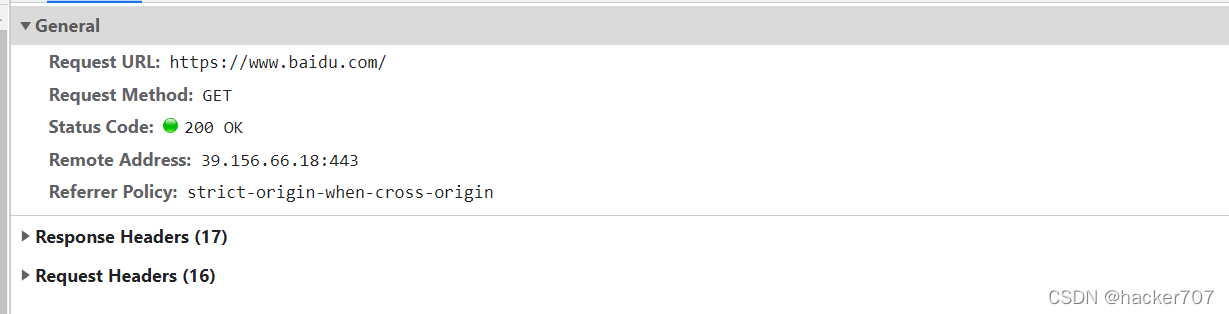
Geral概述关键信息如下:
Request URL:请求的URL网址,也就是服务器的URL网址
Request Method:请求方式为GET
Status Code:状态码为200,即成功返回响应。
Remote Address :服务器IP地址是39.156.66.14:443,端口号是443
✅http的端口号是80,https的端口号是443✅
Request Headers请求头
Response Headers响应头
✅爬取baidu官网HTML源代码✅
添加请求头信息(重构user_agent)
User-Agent(简称UA),记录了操作系统的信息和浏览器的信息
以www.baidu.com为例演示
当不重构ua时,直接访问网址,只会返回baidu的部分源码,因为baidu识别出来我们是爬虫
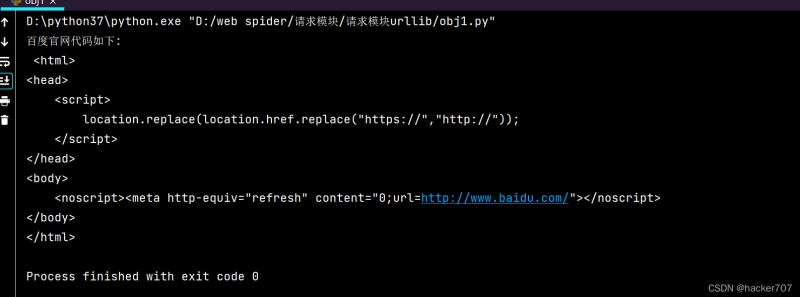
这时就需要重构ua,伪装自己是浏览器发起请求
查看浏览器ua的方法 按F12键打开Network,在request headers里面就可以看到浏览器的ua.

创建Request对象
创建具有请求头信息的Request对象,然后使用urlopen()方法向“baidu”地址发送一个GET请求,利用字典添加请求头信息最常用的用法就是修改User-Agent来伪装浏览器,例如
headers = {“user-agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36”
}表示伪装成谷歌浏览器进行网络请求,可以获取baidu的全部源代码
import urllib.request
# 请求对象的定制:为了解决反爬虫的第一种手段
url = 'https://www.baidu.com'
# 用户代理:UA
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
# urlopen()方法中不能传参字典,因而用户代理UA不能作为传参传入
# 此时需要定制一个请求对象:
# 如果request = urllib.request.Request(url,headers) 写会报错
request = urllib.request.Request(url, headers=header)
response = urllib.request.urlopen(request)
print('baidu官网HTML代码如下:\n', response.read().decode('utf-8'))
💘扩展知识💘
1.使用with open 和 open保存图片
import requests # 导入requests模块
# 找到目标图片的url地址
url = 'https://c-ssl.duitang.com/uploads/blog/202107/26/20210726111411_b4057.jpg'
img_name = 'code.png'
res = requests.get(url)
# 保存图片,音频之类的,会使用wb ————>以二进制方式写入
with open(img_name, 'wb') as file_obj:
# 保存图片,音频之类的,会使用content去响应对象里面取
file_obj.write(res.content)
import requests # 导入requests模块 url = 'https://c-ssl.duitang.com/uploads/blog/202008/12/20200812094028_qzhsq.jpg' img_name = 'code2.png' # 向目标网址发送网络请求并赋给一个变量 res = requests.get(url) # file_obj是一个文件对象 file_obj = open(img_name, 'wb') file_obj.write(res.content) # 用open写入需要关闭 file_obj.close()
💡with open和open两者的区别💡
with open会自动关闭,open则不会
2.使用urillib.request.urlretrieve() 函数保存图片
import urllib.request # 导入request模块 # 找到目标图片的url地址 url = 'https://c-ssl.duitang.com/uploads/item/201912/20/20191220140202_sbpjp.jpg' # 给图片命名 img_name = 'code3.png' # 使用urllib.request.urlretrieve urllib.request.urlretrieve(url, img_name)
💝扩展💖使用路径保存图片
from urllib import request # 导入request模块 url = 'https://c-ssl.duitang.com/uploads/blog/202102/14/20210214203011_1336a.jpeg' # 传入要保存的文件路径(可copy path查看) 加r防止转意 file_name = r'D:\web spider\request\code4.png' request.urlretrieve(url, file_name)
💡两种导入方式💡
import urllib.request(使用时需要urllib.request)
from urllib import request(使用时直接request即可)
总结
到此这篇关于python爬虫之请求模块urllib基本使用的文章就介绍到这了,更多相关python请求模块urllib使用内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!