
T-SQL查询为何慎用IN和NOT IN详解
作者:薛定谔的DBA
前言
今天突然想到之前在书上看到的一个例子,竟然想不起来了.
于是翻书找出来,测试一下.
-- drop table father,son create table father(fid int,name varchar(10),oid int) create table son(sid int,name varchar(10),fid int) insert into father(fid,name,oid) values(1,'father',5),(2,'father',9),(3,'father',null),(4,'father',0) insert into son(sid,name,fid) values(1,'son',2),(2,'son',2),(3,'son',3),(4,'son',null),(5,'son',null) select * from father select * from son
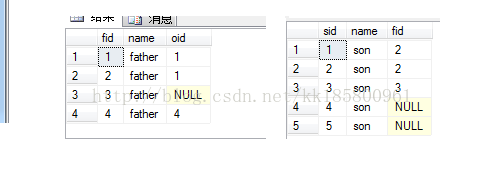
in和exists差异开始测试吧,现在测试使用in、not in 可能带来的“错误”。之所以错误,是因为我们总是以自然语言去理解SQL,却忽略了数学中的逻辑语法。不废话了,测试看看吧!
【测试一:in子查询】
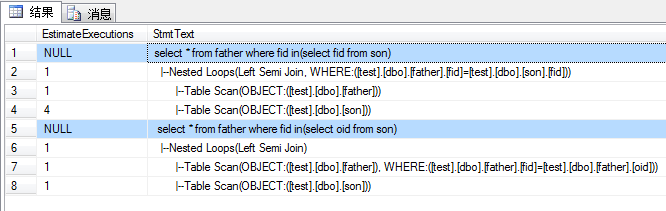
--返回在son中存在的所有father的数据 --正确的写法: select * from father where fid in(select fid from son) --错误的写法: select * from father where fid in(select oid from son)
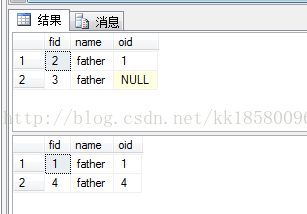
说明:
两个查询都执行没有出错,但是第二个tsql的子查询写错了。子查询(select oid from son)实际单独执行会出错,因为表son不存在字段oid,但是在这里系统不会提示错误。而且father表有4行数据,所有子查询扫描了4次son表,但是第二个查询中,实际也只扫描了1次son表,也就是son表没有用到。
即使这样写也 不会出错: select*fromfatherwherefidin(selectoid)
这个查询的意思是,表father中每行的fid与oid比较,相同则返回值。
实际查询是这样的: select * from father where fid = oid
测试一中,fid in(select fid from son)子查询中包含null值,所以 fid in(null)返回的是一个未知值。但是在刷选器中,false和unknown的处理方式类似。因此第一个子查询返回了正确的结果集。
【测试二:not in子查询】
--返回在son中不存在的所有father的数据 --错误的写法: select * from father where fid not in(select fid from son) --错误的写法: select * from father where fid not in(select oid from son) --正确的写法: select * from father where fid not in(select fid from son where fid is not null)
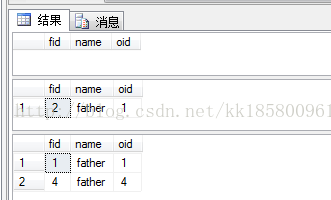
说明:
查看select fid from son,子查询中有空值null,子查询中的值为(2,3,null),谓词fid in(2,3,null)永远不会返回false,只反会true或unknown,所以谓词fidnot in(2,3,null)只返回not true 或not unknown,结果都不会是true。所以当子查询存在null时,not in和not exists 在逻辑上是不等价的。
总结:
In 或 not in在SQL语句中经常用到,尤其当子查询中有空值的时候,要谨慎考虑。因为即使写了“正确”的脚本,但是返回结果却不正确,也不出错。在不是很理解的情况下,最好使用 exists和 not exists来替换。而且exists查询更快一些,因为只要在子查询找到第一个符合的值就不继续往下找了,所以能用exists就用吧。
select *fromfatherawhereexists(select 1fromsonbwherea.fid=b.fid) select * from father awherenotexists(select 1fromsonbwherea.fid=b.fid)
到此这篇关于T-SQL查询为何慎用 IN和NOT IN详解的文章就介绍到这了,更多相关T-SQL查询慎用 IN和NOT IN内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!