
用Python爬取2022春节档电影信息
作者:FriendshipT
前提条件
熟悉HTML基础语句
熟悉Xpath基础语句
相关介绍
Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Requests是一个很实用的Python HTTP客户端库。Pandas是一个Python软件包,提供快速,灵活和可表达的数据结构,旨在使结构化(表格,多维,潜在异构)和时间序列数据的处理既简单又直观。Time是python标准库,无需额外下载,主要用于处理时间问题。Lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据;lxml和正则一样,也是用C语言实现的,是一款高性能的python HTML、XML解析器,也可以利用XPath语法,来定位特定的元素及节点信息。
HTML是超文本标记语言,主要用于显示数据,他的焦点是数据的外观XML是可扩展标记语言,主要用于传输和存储数据,他的焦点是数据的内容
实验目标:Python爬取2022春节档电影信息
实验环境
Python 3.x (面向对象的高级语言)
Resquest 2.14.2 (python第三方库)
Pandas 1.1.0(python第三方库)
Time (python标准库)
Lxml(python第三方库)
具体步骤
目标网站
https://movie.douban.com/cinema/later/shenzhen/
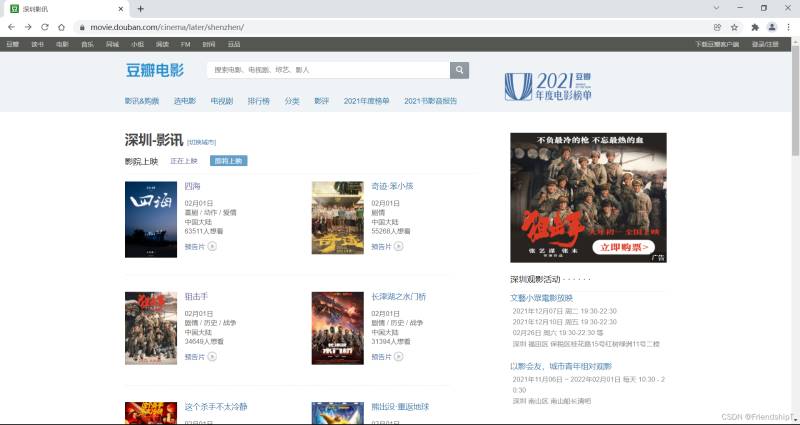
分析网站
按F12打开浏览器操作台
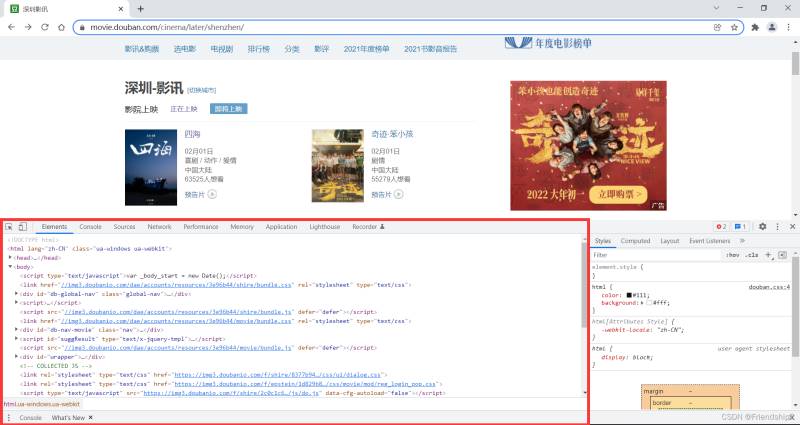
按Ctrl+Shift+C快捷键
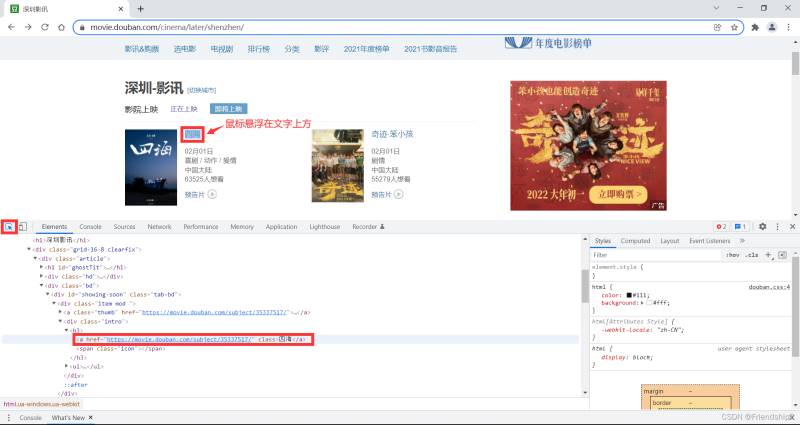
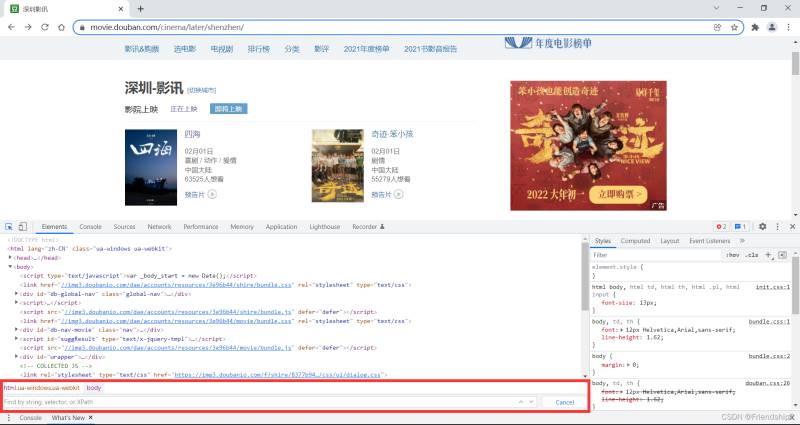
按Ctrl+F快捷键,控制台出现搜索框
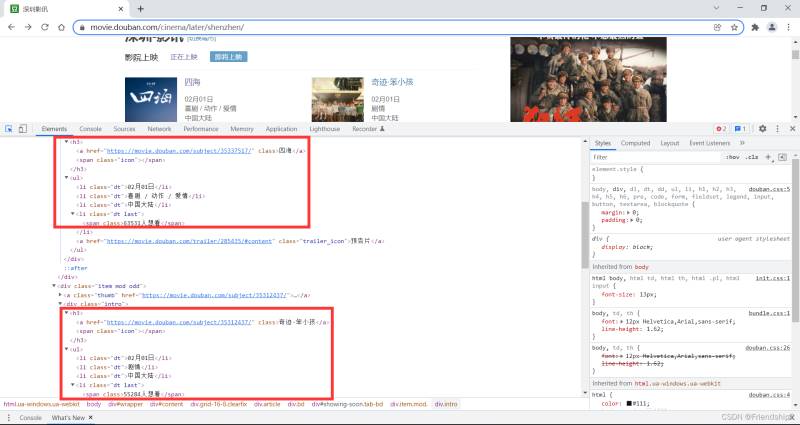
复制Xpath
Xpath为//*[@id=“showing-soon”]/div[1]/div/h3/a
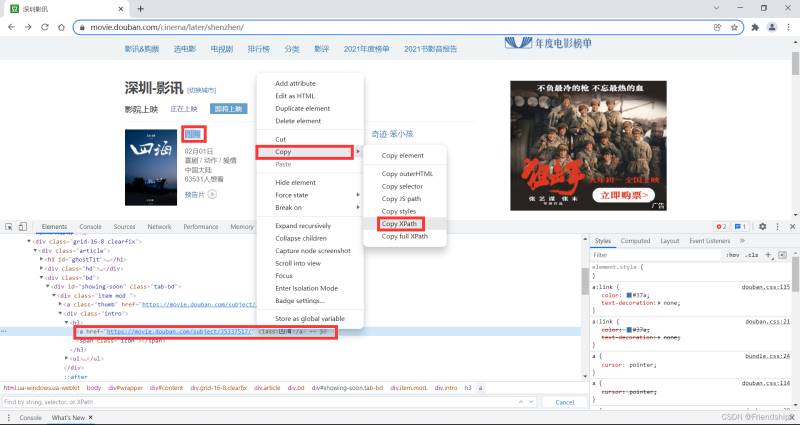
粘贴到搜索框,验证Xpath
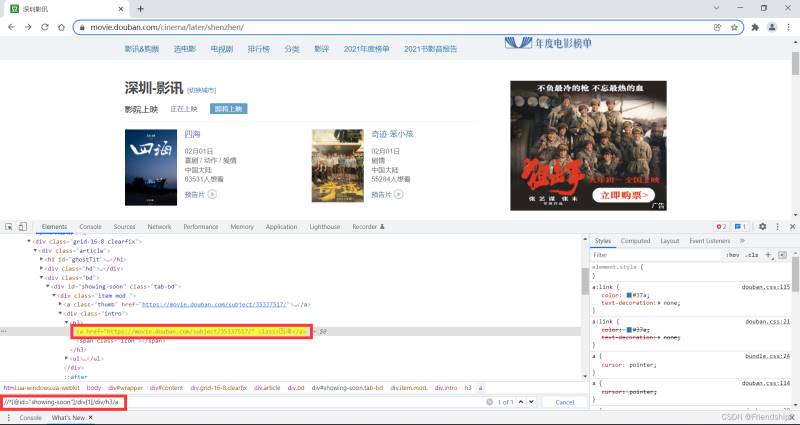
查看HTML,寻找共性
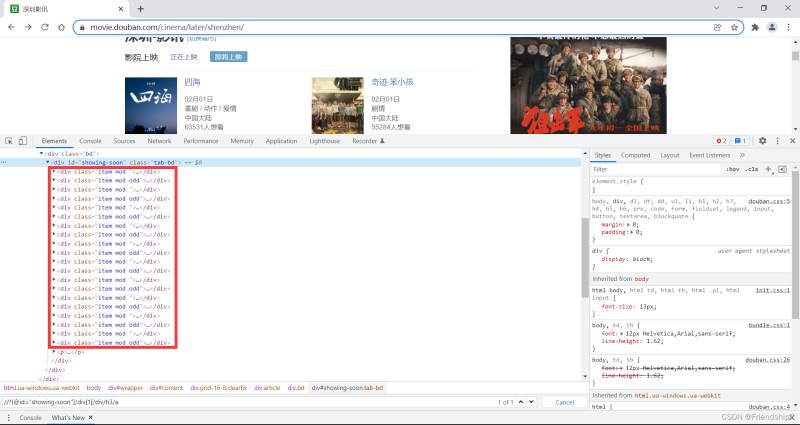
发现目标元素都在一个div框里,修改Xpath
Xpath修改为//*[@id=“showing-soon”]/div/div/h3/a
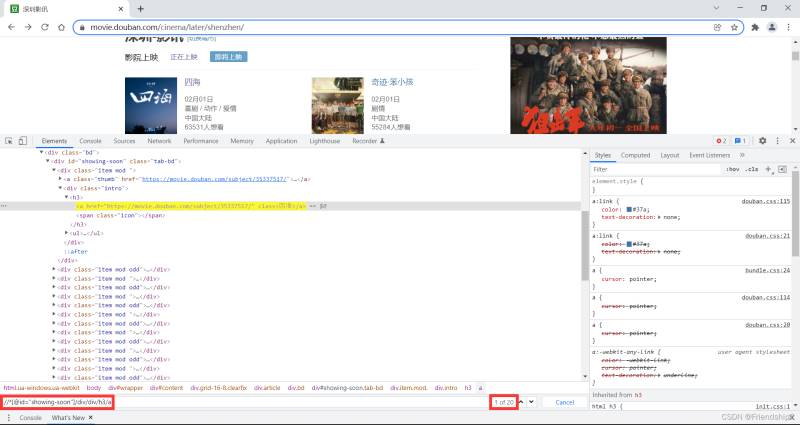
其余目标元素,以此类推
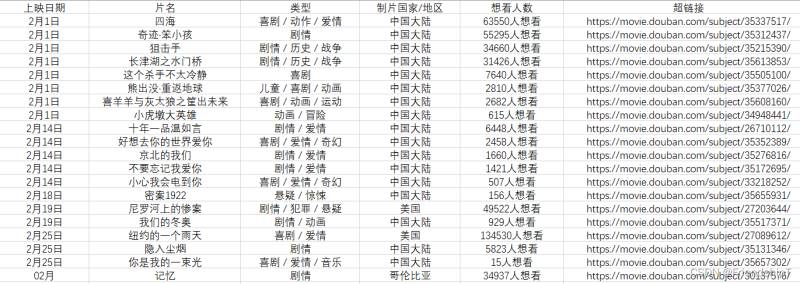
最后,用Pandas保存为CSV文件
# 利用pandas保存文件 df = pd.DataFrame() df['上映日期'] = Ondate df['片名'] = name df['类型'] = movie_class df['制片国家/地区'] = area df['想看人数'] = num df['超链接'] = href
代码实现
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 25 10:07:11 2022
@author: TFX
"""
import time
import requests # 请求库
import pandas as pd
from lxml import etree# 提取信息库
# 日期
today = time.strftime('%Y{y}%m{m}%d{d}',time.localtime()).format(y='年',m='月',d='日')
# 网址
url = 'https://movie.douban.com/cinema/later/shenzhen/'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'
}
# 发送请求
response = requests.get(url=url,headers=headers)
# 数据解析,xpath可以用浏览器检查元素获得
html = etree.HTML(response.text) #类型变换
# 电影详细超链接
href = html.xpath('//*[@id="showing-soon"]/div/div/h3/a/@href')
# 上映日期
Ondate = html.xpath('//*[@id="showing-soon"]/div/div/ul/li[1]/text()')
# 片名
name = html.xpath('//*[@id="showing-soon"]/div/div/h3/a/text()')
# 类型
movie_class = html.xpath('//*[@id="showing-soon"]/div/div/ul/li[2]/text()')
# 制片国家 / 地区
area = html.xpath('//*[@id="showing-soon"]/div/div/ul/li[3]/text()')
# 想看人数
num = html.xpath('//*[@id="showing-soon"]/div/div/ul/li[4]/span/text()')
# 利用pandas保存文件
df = pd.DataFrame()
df['上映日期'] = Ondate
df['片名'] = name
df['类型'] = movie_class
df['制片国家/地区'] = area
df['想看人数'] = num
df['超链接'] = href
df.to_csv('2022春节档电影_'+today+'.csv',mode='w',index=None,encoding='gbk')
print('保存完成!')
输出结果

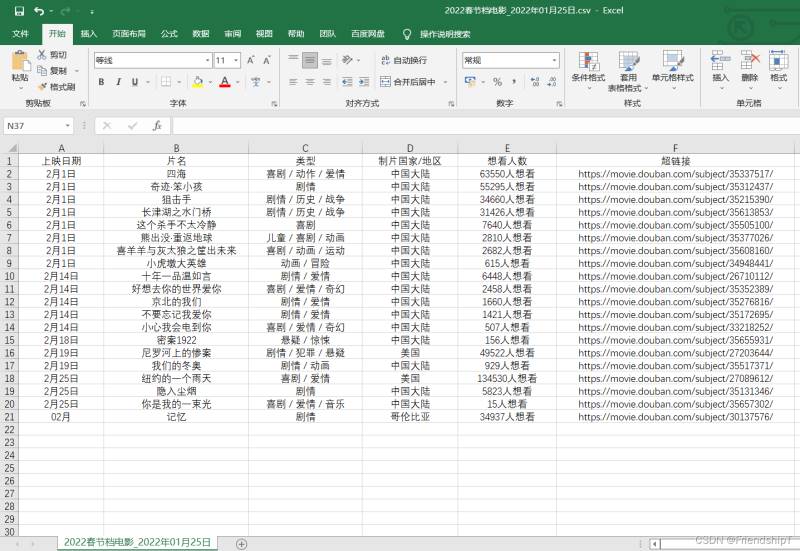
总结
到此这篇关于用Python爬取2022春节档电影信息的文章就介绍到这了,更多相关Python春节档电影信息内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!