
使用python svm实现直接可用的手写数字识别
作者:翟羽嚄
这篇文章主要介绍了使用python svm实现直接可用的手写数字识别,现在网上很多代码是良莠不齐,真是一言难尽,于是记录一下,能够运行成功并识别成功的一个源码
python svm实现手写数字识别——直接可用
最近在做个围棋识别的项目,需要识别下面的数字,如下图:
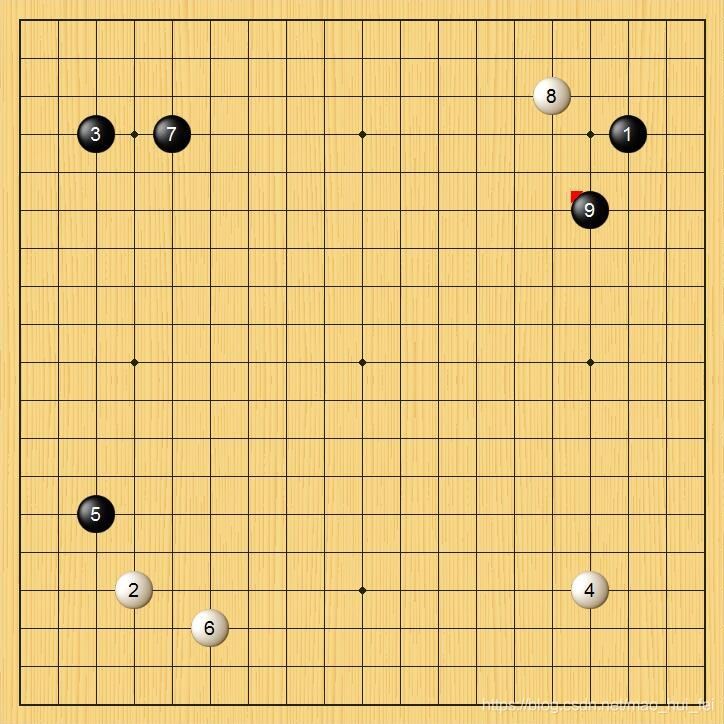
我发现现在网上很多代码是良莠不齐,…真是一言难尽,于是记录一下,能够运行成功并识别成功的一个源码。
1、训练
1.1、训练数据集下载——已转化成csv文件
1.2 、训练源码
train.py
import pandas as pd
from sklearn.decomposition import PCA
from sklearn import svm
from sklearn.externals import joblib
import time
if __name__ =="__main__":
train_num = 5000
test_num = 7000
data = pd.read_csv('train.csv')
train_data = data.values[0:train_num,1:]
train_label = data.values[0:train_num,0]
test_data = data.values[train_num:test_num,1:]
test_label = data.values[train_num:test_num,0]
t = time.time()
#PCA降维
pca = PCA(n_components=0.8, whiten=True)
print('start pca...')
train_x = pca.fit_transform(train_data)
test_x = pca.transform(test_data)
print(train_x.shape)
# svm训练
print('start svc...')
svc = svm.SVC(kernel = 'rbf', C = 10)
svc.fit(train_x,train_label)
pre = svc.predict(test_x)
#保存模型
joblib.dump(svc, 'model.m')
joblib.dump(pca, 'pca.m')
# 计算准确率
score = svc.score(test_x, test_label)
print(u'准确率:%f,花费时间:%.2fs' % (score, time.time() - t))
2、预测单张图片
2.1、待预测图像

2.2、预测源码
from sklearn.externals import joblib
import cv2
if __name__ =="__main__":
img = cv2.imread("img_temp.jpg", 0)
#test = img.reshape(1,1444)
Tp_x = 10
Tp_y = 10
Tp_width = 20
Tp_height = 20
img_temp = img[Tp_y:Tp_y + Tp_height, Tp_x:Tp_x + Tp_width] # 参数含义分别是:y、y+h、x、x+w
cv2.namedWindow("src", 0)
cv2.imshow("src", img_temp)
cv2.waitKey(1000)
[height, width] = img_temp.shape
print(width, height)
res_img = cv2.resize(img_temp, (28, 28))
test = res_img.reshape(1, 784)
#加载模型
svc = joblib.load("model.m")
pca = joblib.load("pca.m")
# svm
print('start pca...')
test_x = pca.transform(test)
print(test_x.shape)
pre = svc.predict(test_x)
print(pre[0])
2.3、预测结果
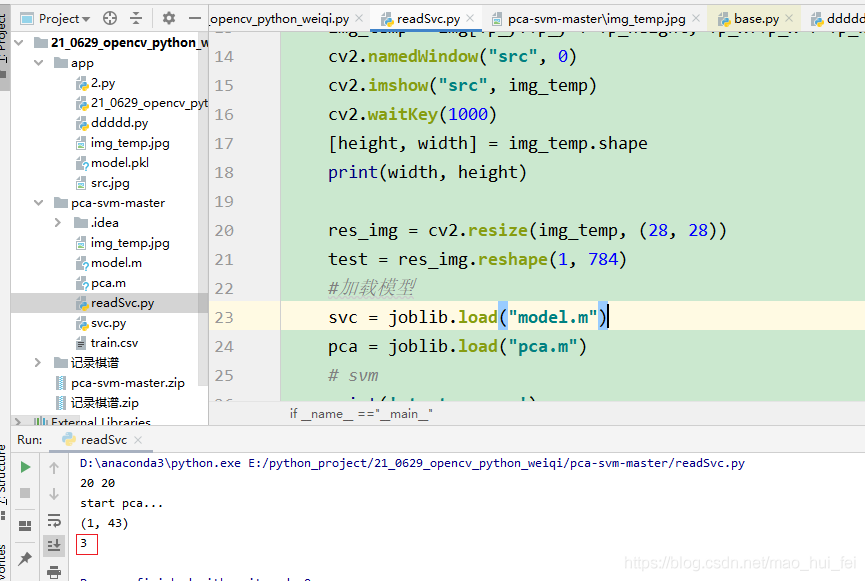
到此这篇关于使用python svm实现直接可用的手写数字识别的文章就介绍到这了,更多相关python svm 手写数字识别内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!