
Java数据结构之实现哈希表的分离链接法
作者:TanGBx
哈希表的分离链接法
原理
Hash Table可以看作是一种特殊的数组。他的原理基本上跟数组相同,给他一个数据,经过自己设置的哈希函数变换得到一个位置,并在这个位置当中放置该数据。哦对了,他还有个名字叫散列
| 0 | 1 |
| 数据1 | 数据2 |
就像这个数组,0号位置放着数据1,1号位置放数据2
而我们的哈希表则是通过一个函数f(x) 把数据1变成0,把数据2变成1,然后在得到位置插入数据1和数据2。
非常重要的是哈希表的长度为素数最好!!
而且当插入数据大于一半的时候我们要进行扩充!!!
冲突问题产生
现在这个表就是2个数据,所以不会产生什么冲突,但是若一个数据他通过f(x)计算得到的位置也是0呢?是不是就跟数据1产生了冲突,因为数据1已经占据了这个位置,你无法进行插入操作。对不对。
所以我们该如何解决这个问题呢,诶,我们肯定是想两个都可以插入是不是,就像一个炸串一样把他串起来。如图
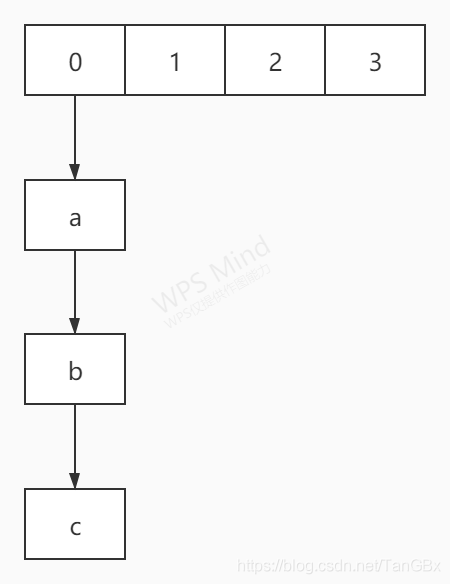
a b c就像一个炸串,而如何实现这个炸串就有多种方式。这里我们用线性表来实现
线性表实现
我们可以用java自带的List ArrayList等表,这边也给出单链表的实现方式。
public class MyArray<AnyType> {
我们首先得创建一个内部类用来存放数据,以及保存下个节点
class ArrayNode<AnyType>{
public AnyType data;
public ArrayNode<AnyType> next;
public ArrayNode(AnyType data){this(data,null);}
private ArrayNode(AnyType data,ArrayNode<AnyType> next){
this.data=data;
this.next=next;
}
}//save type node;
设置我们这个线性表所需要的对象,例如size和一个头节点,以及我们要进行初始化,判断这个表是否为空等。
private int theSize;//array list size
private ArrayNode<AnyType> head; //head node every data behind it
//init MyArray
public MyArray(){doClear();}
public void clear(){doClear();}
private void doClear(){
theSize=0;
head=new ArrayNode<>(null);
}
//get size and is empty
public int size(){return theSize;}
public boolean isEmpty(){return theSize==0;}
接下来我们需要实现他的基本操作,是否包含,插入,获得以及删除。
//contain
public boolean contains(AnyType x){
ArrayNode<AnyType> newNode=head;//get a new node=head
while (newNode.next!=null) {
newNode=newNode.next;
if (newNode.data == x)
return true;
}
return false;
}
//get the data in idx from array
public AnyType get(int idx){return get(idx,head).data;}
private ArrayNode<AnyType> get(int idx,ArrayNode<AnyType> node){
if(idx<0||idx>size())
throw new IndexOutOfBoundsException();//out of length
ArrayNode<AnyType> newNode=node;
//find start head.next
for (int i = 0; i < idx; i++)
newNode=newNode.next;
return newNode;
}
//set data into array
public void set(AnyType x){set(x,head);}
private void set(AnyType x,ArrayNode<AnyType> node){
ArrayNode<AnyType> newNode=node;
while (newNode.next!=null)
newNode=newNode.next;
theSize++;
newNode.next=new ArrayNode<>(x);
}
//remove
public void remove(AnyType x){remove(x,head);}
private void remove(AnyType x,ArrayNode<AnyType> node){
if(!contains(x))
return;
while (node.next!=null){
node=node.next;
if (node.next.data==x)
break;
}
ArrayNode<AnyType> oldNode=node.next;
node.next=null;
node.next=oldNode.next;
}
}
哈希表实现
public class MyHashTable<AnyType>{
//define the things that we need to use
private static final int DEFAULT_SIZE = 10;
private MyArray<AnyType>[] arrays;
private int currentSize;
因为我实现的是学号的存储
也就是带0开头的数据 所以我用字符串
这里这个myHash就是我实现的简单哈希函数,即获得的数据字符串化,得到最后两个字符
private int myHash(AnyType x){
String s=x.toString();
return Integer.parseInt(s.substring(s.length()-2,s.length()));
}
初始化哈希表,设置的默认大小为10,然后进行素数判断,如果它不是素数,那么就找到他的下一个素数作为表的大小。
//init we should ensure that the table size is prime
public MyHashTable(){
ensureTable(nextPrime(DEFAULT_SIZE));
makeEmpty();
}
private void ensureTable(int x){
arrays=new MyArray[x];
for (int i = 0; i < arrays.length; i++)
arrays[i]=new MyArray<>();
}
//make the array empty
public void makeEmpty(){
currentSize=0;
for(MyArray<AnyType> myArray:arrays)
myArray.clear();
}
//size and empty
public int size(){return currentSize;}
public boolean isEmpty(){return currentSize==0;}
基本方法的实现,插入,获得,删除,包含
//contain x
public boolean contains(AnyType x){
int position=myHash(x);
return arrays[position].contains(x);
}
//insert x
public void insert(AnyType x){
int position=myHash(x);
if(arrays[position].contains(x))
return;
else if(arrays[position].size()==0)
if(++currentSize>arrays.length)
makeBigger();
arrays[position].set(x);
}
//get idx data
public MyArray<AnyType> get(int idx){ return arrays[idx];}
在这里,如果插入的时候啦,实际的currentSize大于二分之一表的大小了
则进行扩充表
一般扩充表的话,我们是直接两倍两倍扩充的。
//makeBigger
public void makeBigger() {
MyArray[] oldArray = arrays;
arrays = new MyArray[2 * arrays.length];
for (int i = 0; i < oldArray.length; i++)
arrays[i] = oldArray[i];
}
下一个素数查找,如果他是偶数,则给他加1这样可以大大减少开销。
然后进行下一个素数判断,奇数当中找素数。
//nextPrime
private int nextPrime(int i){
if(i%2==0)
i++;
for (; !isPrime(i); i+=2);//ensure i is jishu
return i;
}
是否为素数判断,如果为2则范围true
如果是1或者为偶数则返回false
都不满足则从三开始,他的平方小于输入的数,用奇数进行操作,因为用偶数的话,前面那个2就直接判断了,所以我们用奇数,大大减少开销。
我们也可以设置他的判断条件是小于输入的二分之一,但是我们用平方进行判断大大减少了开销,而且对于奇数来说是十分有效果的。
//is Prime
private boolean isPrime(int i){
if(i==2||i==3)
return true;
if(i==1||i%2==0)
return false;
for (int j = 3; j*j<=i ; j+=2)
if (i%j==0)
return false;
return true;
}
}
测试
public class test {
public static void main(String[] args) {
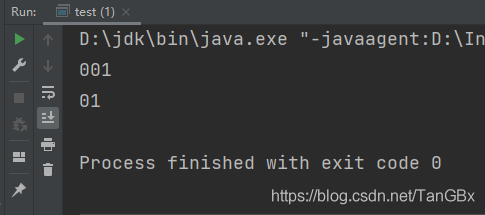
MyHashTable<String> a=new MyHashTable<>();
a.insert("001");
a.insert("01");
for(int i=1;i<a.get(1).size()+1;i++){
System.out.println(a.get(1).get(i));
}
}
}
结果
到此这篇关于Java数据结构之实现哈希表的分离链接法的文章就介绍到这了,更多相关Java哈希表的分离链接法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!