
Java深入了解数据结构之哈希表篇
作者:/少司命
1,概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键 码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O( ),搜索的效率取决于搜索过程中 元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函 数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小。

2,冲突-避免
首先,我们需要明确一点,由于我们哈希表底层数组的容量往往是小于实际要存储的关键字的数量的,这就导致一 个问题,冲突的发生是必然的,但我们能做的应该是尽量的降低冲突率。
3,冲突-避免-哈希函数设计
常见哈希函数
直接定制法--(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B 优点:简单、均匀 缺点:需要事先知道关 键字的分布情况 使用场景:适合查找比较小且连续的情况
除留余数法--(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数: Hash(key) = key% p(p<=m),将关键码转换成哈希地址
平方取中法--(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址; 再比如关键字为4321,对 它平方就是18671041,抽取中间的3位671(或710)作为哈希地址 平方取中法比较适合:不知道关键字的分 布,而位数又不是很大的情况
4,冲突-避免-负载因子调节

负载因子和冲突率的关系粗略演示
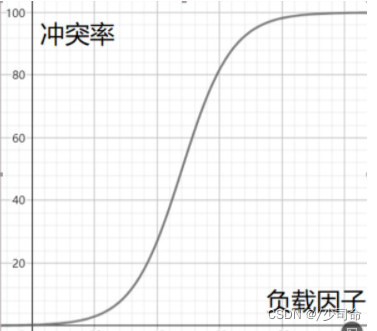
所以当冲突率达到一个无法忍受的程度时,我们需要通过降低负载因子来变相的降低冲突率。 、已知哈希表中已有的关键字个数是不可变的,那我们能调整的就只有哈希表中的数组的大小。
5,冲突-解决-闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以 把key存放到冲突位置中的“下一个” 空位置中去。
①线性探测
比如上面的场景,现在需要插入元素44,先通过哈希函数计算哈希地址,下标为4,因此44理论上应该插在该 位置,但是该位置已经放了值为4的元素,即发生哈希冲突。 线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
插入
通过哈希函数获取待插入元素在哈希表中的位置 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到 下一个空位置,插入新元素

采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他 元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标 记的伪删除法来删除一个元素。
②二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨 着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为: = ( + )% m, 或者: = ( - )% m。其中:i = 1,2,3…, 是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置, m是表的大小。 对于2.1中如果要插入44,产生冲突,使用解决后的情况为:
研究表明:当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不 会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情 况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
6,冲突-解决-开散列/哈希桶
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子 集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。


static class Node {
public int key;
public int val;
public Node next;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}
private Node[] array;
public int usedSize;
public HashBucket() {
this.array = new Node[10];
this.usedSize = 0;
}

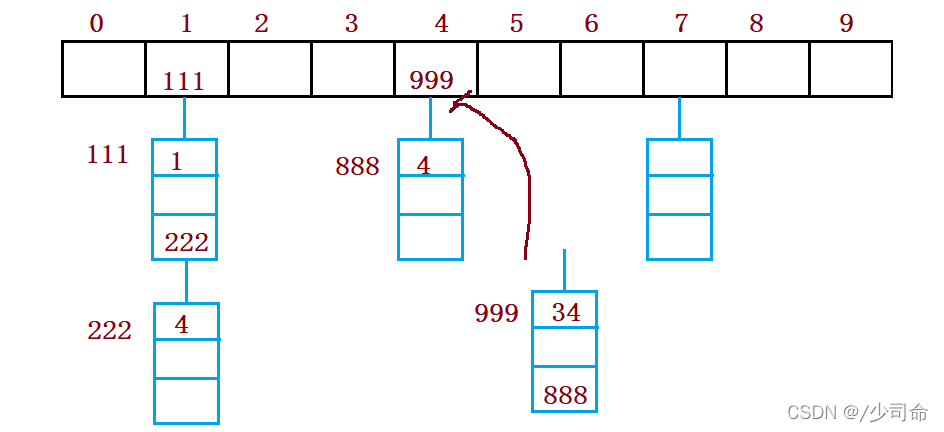
public void put(int key,int val){
int index = key % this.array.length;
Node cur = array[index];
while (cur != null){
if(cur.val == key){
cur.val = val;
return;
}
cur = cur.next;
}
//头插法
Node node = new Node(key,val);
node.next = array[index];
array[index] = node;
this.usedSize++;
if(loadFactor() >= 0.75){
resize();
}
}
public int get(int key) {
//以什么方式存储的 那就以什么方式取
int index = key % this.array.length;
Node cur = array[index];
while (cur != null) {
if(cur.key == key) {
return cur.val;
}
cur = cur.next;
}
return -1;//
}

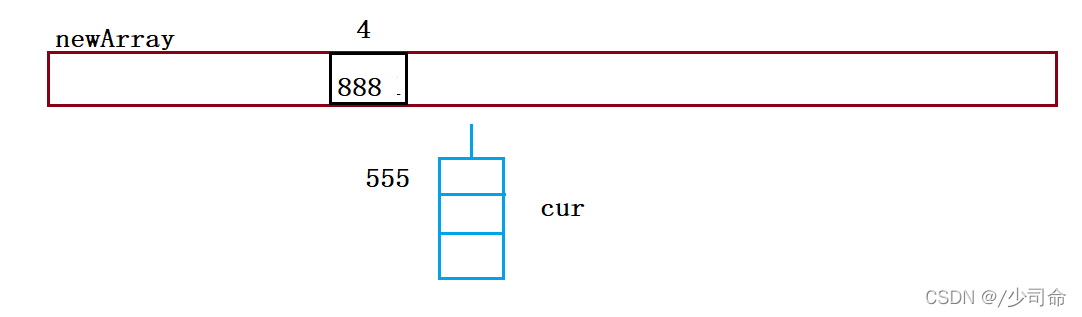

public void resize(){
Node[] newArray = new Node[2*this.array.length];
for (int i = 0; i < this.array.length; i++){
Node cur = array[i];
Node curNext = null;
while (cur != null){
curNext = cur.next;
int index = cur.key % newArray.length;
cur.next = newArray[i];
newArray[i] = cur;
cur = curNext.next;
cur = curNext;
}
}
this.array = newArray;
}
7,完整代码
class HashBucket {
static class Node {
public int key;
public int val;
public Node next;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}
private Node[] array;
public int usedSize;
public HashBucket() {
this.array = new Node[10];
this.usedSize = 0;
}
public void put(int key,int val) {
//1、确定下标
int index = key % this.array.length;
//2、遍历这个下标的链表
Node cur = array[index];
while (cur != null) {
//更新val
if(cur.key == key) {
cur.val = val;
return;
}
cur = cur.next;
}
//3、cur == null 当前数组下标的 链表 没要key
Node node = new Node(key,val);
node.next = array[index];
array[index] = node;
this.usedSize++;
//4、判断 当前 有没有超过负载因子
if(loadFactor() >= 0.75) {
//扩容
resize();
}
}
public int get(int key) {
//以什么方式存储的 那就以什么方式取
int index = key % this.array.length;
Node cur = array[index];
while (cur != null) {
if(cur.key == key) {
return cur.val;
}
cur = cur.next;
}
return -1;//
}
public double loadFactor() {
return this.usedSize*1.0 / this.array.length;
}
public void resize(){
Node[] newArray = new Node[2*this.array.length];
for (int i = 0; i < this.array.length; i++){
Node cur = array[i];
Node curNext = null;
while (cur != null){
curNext = cur.next;
int index = cur.key % newArray.length;
cur.next = newArray[i];
newArray[i] = cur;
cur = curNext.next;
cur = curNext;
}
}
this.array = newArray;
}
}
到此这篇关于Java深入了解数据结构之哈希表篇的文章就介绍到这了,更多相关Java 哈希表内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!