
python爬取晋江文学城小说评论(情绪分析)
作者:海胆奶油饭
1. 收集数据
1.1 爬取晋江文学城收藏排行榜前50页的小说信息
获取收藏榜前50页的小说列表,第一页网址为 ‘http://www.jjwxc.net/bookbase.php?fw0=0&fbsj=0&ycx0=0&xx2=2&mainview0=0&sd0=0&lx0=0&fg0=0&sortType=0&isfinish=0&collectiontypes=ors&searchkeywords=&page=1' , 第二页网址中page=2,以此类推,直到第50页中page=50。爬取每个小说的ID,小说名字,小说作者。将爬取到的信息存储到晋江排行榜【按收藏数】.txt文件中。
import requests from bs4 import BeautifulSoup import bs4 import re import csv import pandas as pd import numpy as np import matplotlib.pyplot as plt import jieba import seaborn as sns import xlrd from xlutils.copy import copy # 一些魔法命令,使得matplotlib画图时嵌入单元中而不是新开一个窗口 %matplotlib inline plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots plt.rcParams['image.interpolation'] = 'nearest' plt.rcParams['image.cmap'] = 'gray' %load_ext autoreload %autoreload 2 from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn import metrics from sklearn.model_selection import train_test_split
- 爬取小说基本信息 ,主要思路;
- 找到需要爬取的所有信息主体tbody;
- 分别找到每个信息对应的小标签td(a),数清楚在所有标签中的顺序;
- 存进txt文档时按顺序存储。
headers = {"User-Agent": "Mozilla/5.0"}
for n in range(1,50):
url = 'http://www.jjwxc.net/bookbase.php?fw0=0&fbsj=0&ycx0=0&xx2=2&mainview0=0&sd0=0&lx0=0&fg0=0&sortType=0&isfinish=0&collectiontypes=ors&searchkeywords=&page={}'.format(n)
html = requests.get(url,headers=headers)
html.encoding = html.apparent_encoding
soup = BeautifulSoup(html.text, 'html.parser')
for tr in soup.find_all('tbody'):
tds=tr('td')
a = tr('a')
count=0
id=[]
for u in tr.find_all('a'):
count=count+1
book_url=u.get('href') # 获取小说主页的url
p = re.compile(r'\d+')
book_id = p.findall(book_url)[0] # 获取小说ID
if(count%2==0):
id.append(book_id)
for n in range(0,100):
with open('./data/晋江排行榜【按收藏数】.txt','a+',encoding='utf-8') as f:
print("{0}\t{1}\t{2}".format(id[n],a[n*2+1].string,a[n*2].string),file=f) # 序号 书名 作者
1.2 查看爬虫结果
分别查看前8部小说的ID和名字
# 查看收藏榜前8部小说的ID
with open('./data/晋江排行榜【按收藏数】.txt','r',encoding='utf-8',errors='ignore') as f:
book_list = f.readlines()
id_list = [item.split('\t')[0] for item in book_list]
print(id_list[:8])
# 查看收藏榜前8部小说的名字
name_list = [item.split('\t')[1] for item in book_list]
print(name_list[:8])

1.3 ** 爬取每部小说的评论** 。
找到小说的评论区,第一部小说《天官赐福》的第一页评论网址为 ‘http://www.jjwxc.net/comment.php?novelid=3200611&huati=1' ,3200611是小说ID,1是评论页数,这部小说第二页网址为'http://www.jjwxc.net/comment.php?novelid=3200611&huati=2' 。下一部小说《撒野》的ID是2956313,它的第一页评论网址为'http://www.jjwxc.net/comment.php?novelid=2956313&huati=1' ,以此类推,爬取所有小说的评论和打分。为了避免有一些小说评论数不够多,自己设定每部小说只爬取5页的评论。
爬取思路与爬取小说信息大致相同,不同的是将爬取到的信息存储到xls文件中。
headers = {"User-Agent": "Mozilla/5.0"}
with open('./data/晋江排行榜【按收藏数】.txt','r',encoding='utf-8') as f:
book_list = f.readlines()
id_list = [item.split('\t')[0] for item in book_list]
for book_id in id_list:
for page in range(1,6):
url="http://www.jjwxc.net/comment.php?novelid={}&huati=1&page={}".format(book_id,page)
html = requests.get(url,headers=headers)
html.encoding = html.apparent_encoding
soup = BeautifulSoup(html.text, 'html.parser')
scores=[]
comments=[]
for item1 in soup.find_all('span',"coltext"):
score=item1('span')
scores.append(score[2].string)
for item2 in soup.find_all('div',"readbody"):
comment=item2('span')
comments.append(comment[0].string)
for i in range(0,len(comments)):
excel = xlrd.open_workbook('./data/jjwxc1.xls')
wb = copy(excel)
w_sheet = wb.get_sheet(0)
sheet = excel.sheets()[0]
nrow = sheet.nrows # 文件行数
w_sheet.write(nrow, 0, book_id)
w_sheet.write(nrow, 1, comments[i])
w_sheet.write(nrow, 2, scores[i])
wb.save('./data/jjwxc1.xls')
2. 数据加载和预处理
预处理包括:
- 格式转化;上一步将爬取信息存到了xls文件,将xls格式文件转化为csv格式文件方便下一步加载。
- 数据去重;爬取过程中某些页面爬取了多次,导致csv文件包含重复的行。
- 短评去重;对同一部小说,或者不同的小说,可能存在评论内容相同的行。
- 添加情绪标签
- 去除停用词和分词
- 短评可视化
2.1 格式转化
使用pandas模块可以快速将xls文件转换为.csv
# 格式转化
ex=pd.read_excel("./data/jjwxc.xls")
ex.to_csv("./data/jjwxc.csv",encoding="gb18030")
# 加载评论
review = pd.read_csv("./data/jjwxc.csv",names=['ID','comment','score'],encoding='gb18030')
2.2 数据去重
去除重复的行
# 去重 review = review.drop_duplicates()
2.3 短评去重
去除评论相同的行
# 删除评论内容重复的行
review= review.drop_duplicates('comment')
review.shape
2.4 添加情绪标签
根据打分的分数来添加情绪标签,观察晋江文学城的打分机制发现,打分区间在[-2,2]内,且打2分的人数占大多数,于是将分数为2的评论看作是好评,情绪标签为1,而低于2分的看作是差评,情绪标签为0。
# 添加情绪标签 review['emotion'] = (review.score ==2) * 1
# 打乱顺序 review = review.sample(frac=1).reset_index(drop=True) print(review.shape)
2.5 去除停用词和分词
短评内容进行分词并去掉停用词
def review_without_stop(review):
# 打开停用词文件
with open("./data/emotion_stopwords.txt","r",encoding="utf-8") as f:
stop_word = [x.strip() for x in f.readlines()]
all_stop_words = set(stop_word) # 删除停用词中重复的项
# 短评中的非中文字符替换为''
review = re.sub("[^\u4e00-\u9fa5]",'',review)
# 去除全角空白字符
review = review.replace("\u3000","")
# 分词
review = jieba.cut(review)
# 过滤一个字的词
review = filter(lambda x: len(x)>1,review)
# 去除停用词
review = filter(lambda x: x not in all_stop_words,review)
return ' '.join(review)
# 自定义分词字典
jieba.load_userdict("./data/emotion_userdict.txt")
review['cut_jieba'] = review.comment.apply(review_without_stop)
【注】停用词和分词文件需要自己定义
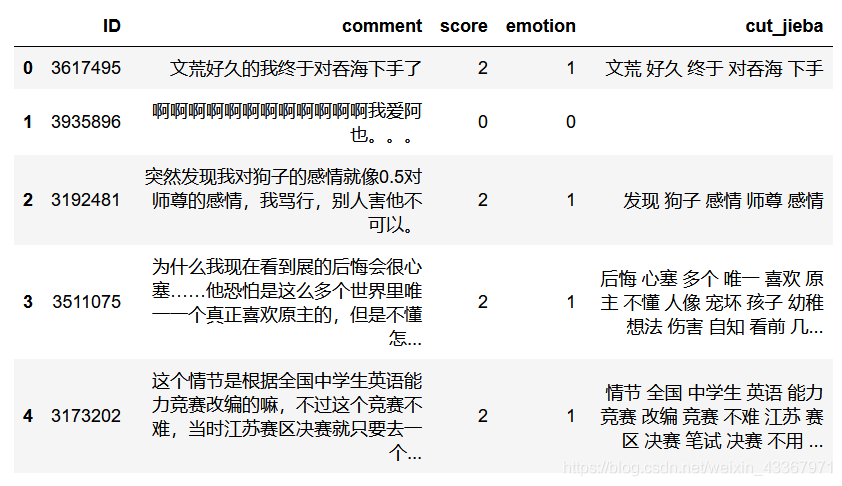
# 查看一些评论 review.head()
# 好评中一些评论包含“不想”,“不喜欢” review[(review['cut_jieba'] == '不想') & (review['emotion'] == 1)]
review[(review['cut_jieba'] == '不喜欢') & (review['emotion'] == 1)]
# 好评中出现的消极情绪词,去除这些评论
def change_negtive_like(cut_text):
word_list = cut_text.split()
if "不喜欢" in word_list:
for i in range(len(word_list)):
if word_list[i] == "不喜欢":
word_list[i] = ""
return " ".join(word_list)
elif "不想" in word_list:
for i in range(len(word_list)):
if word_list[i] == "不想":
word_list[i] = ""
return " ".join(word_list)
else:
return cut_text
review.loc[review['emotion'] == 1,'cut_jieba'] = review[review['emotion'] == 1].cut_jieba.apply(change_negtive_like)
# 一些评论内容为空,去除这些为空的评论 review = review[~(review['cut_jieba'] == '')] review.shape
2.6 短评可视化
对所有短评进行可视化
from wordcloud import WordCloud
from imageio import imread
mask = imread("./data/cloud.jpg")
font = './data/FZSTK.TTF'
wc = WordCloud(
font_path= font,
max_words=2000, # 设置最大现实的字数
max_font_size=250,# 设置字体最大值
background_color = "white",
random_state=30,
mask = mask)
wc.generate(''.join(review['cut_jieba'])) # 生成词云
plt.imshow(wc)
plt.axis('off')

对emotion为1的短评进行可视化
from wordcloud import WordCloud
from imageio import imread
mask = imread("./data/piggy.jpg")
font = './data/FZSTK.TTF'
wc1 = WordCloud(
font_path= font,
max_words=2000, # 设置最大现实的字数
max_font_size=300,# 设置字体最大值
background_color = "white",
random_state=30,
mask = mask)
wc1.generate(''.join(review['cut_jieba'][review['emotion']==1]))
plt.imshow(wc1)
plt.axis('off')

对score为-2的短评进行可视化
wc1.generate(''.join(review['cut_jieba'][review['score']==-2])) # 生成词云
plt.imshow(wc1)
plt.axis('off')

【注】词云和字体自己定义
3. 训练模型
3.1 建立训练数据集和测试数据集
由于已经为分析准备好了数据,所以现在需要将数据分成训练数据集和测试数据集。将数据分成两部分:75%的训练数据和25%的测试数据。
x, y = review['cut_jieba'], review['emotion'] x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.25)
print(x_train.shape) print(y_train.shape)
print(x_test.shape) print(y_test.shape)
3.2 特征提取
使用 sklearn 包中的 TfidfVectorizer 方法进行特征提取。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer(decode_error='ignore',
token_pattern=r"\b[^\d\W]\w+\b", # 剔除向量化结果中的数字
analyzer='word',
ngram_range=(2,4),
max_df = 0.8,
min_df = 3)
Xtrain = tfidf_vect.fit_transform(x_train)
Xtest = tfidf_vect.transform(x_test)
print(Xtrain.shape) print(Xtest.shape)
3.3 用朴素贝叶斯完成中文文本分类器
from sklearn.naive_bayes import MultinomialNB
review_classifier = MultinomialNB() review_classifier.fit(Xtrain,y_train)
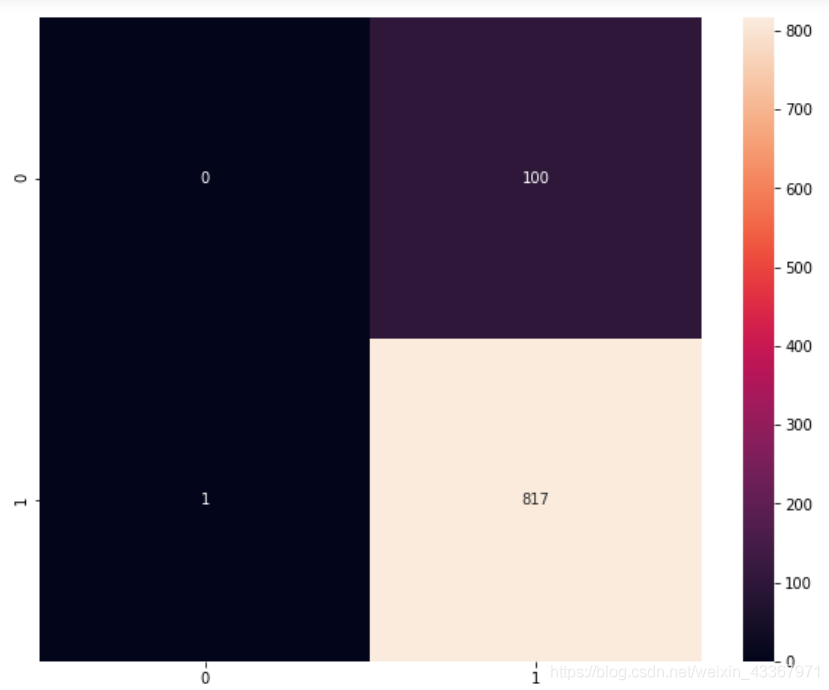
# 对测试集的样本进行预测 y_pred = review_classifier.predict(Xtest) metrics.confusion_matrix(y_test, y_pred) # 混淆矩阵
# 利用 sns 模块查看测试值和预测值构成的热图 colorMetrics = metrics.confusion_matrix(y_test, y_pred) sns.heatmap(colorMetrics,annot=True,fmt='d')
# 分类报告 # 给出每个类的准确率,召回率和F值,以及这三个参数和宏平均值 print(metrics.classification_report(y_test,y_pred))

print(metrics.accuracy_score(y_test,y_pred))
from sklearn.model_selection import cross_val_score score1 = cross_val_score(review_classifier,Xtrain,y_train,cv=10,scoring="accuracy").mean() print(score1)
3.4 用逻辑回归完成中文文本分类
from sklearn.linear_model import LogisticRegression LR_model = LogisticRegression(penalty='l2',max_iter=3000) LR_model.fit(Xtrain,y_train)
# 对测试集的样本进行预测 y_pred = LR_model.predict(Xtest) metrics.confusion_matrix(y_test, y_pred) # 混淆矩阵
print(LR_model.score(Xtest,y_test))
# 给出每个类的准确率,召回率和F值,以及这三个参数和宏平均值 print(metrics.classification_report(y_test,y_pred))
4. 结果分析
(1)词云分析:
- 词云1中最明显的词汇是“喜欢”;
- 词云2中的词汇与词云1区别不大,因为所有短评中好评占大多数;
- 由差评生成的词云3出现了“不好”、“一般”、“硬伤”等负面色彩的词语。
(2)影响情感分析准确性的原因:
- 获取到的短评数量比较少;
- 由于小说中对主角讨论比较多,一些小说角色名字会重复出现在短评内,一定程度影响对评论的感情分析;
- 没有删除过于短小的评论;
- 分词后中发现代表积极或消极情绪的词汇往往不会成为单独短评,而是和别的词一起出现,对于查找差评中的积极词汇和好评中的消极词汇造成一定困难。
- 短评中出现明显代表正面色彩和负面色彩的词汇较少。
到此这篇关于爬取晋江文学城小说评论(情绪分析)的文章就介绍到这了,希望对你有所帮助,更多相关python爬取内容请搜索脚本之家以前的文章或继续浏览下面的相关文章,希望大家以后多多支持脚本之家!