
python 爬取腾讯视频评论的实现步骤
作者: 春日宴
一、网址分析
查阅了网上的大部分资料,大概都是通过抓包获取。但是抓包有点麻烦,尝试了F12,也可以获取到评论。以电视剧《在一起》为例子。评论最底端有个查看更多评论猜测过去应该是 Ajax 的异步加载。
网上的大部分都是构建评论的网址,通过 requests 获取,正则表达式进行数据处理。本文也利用该方法进行数据处理,其实利用 scrapy 会更简单。
根据前辈给出的经验,顺利找到了评论所在的链接。
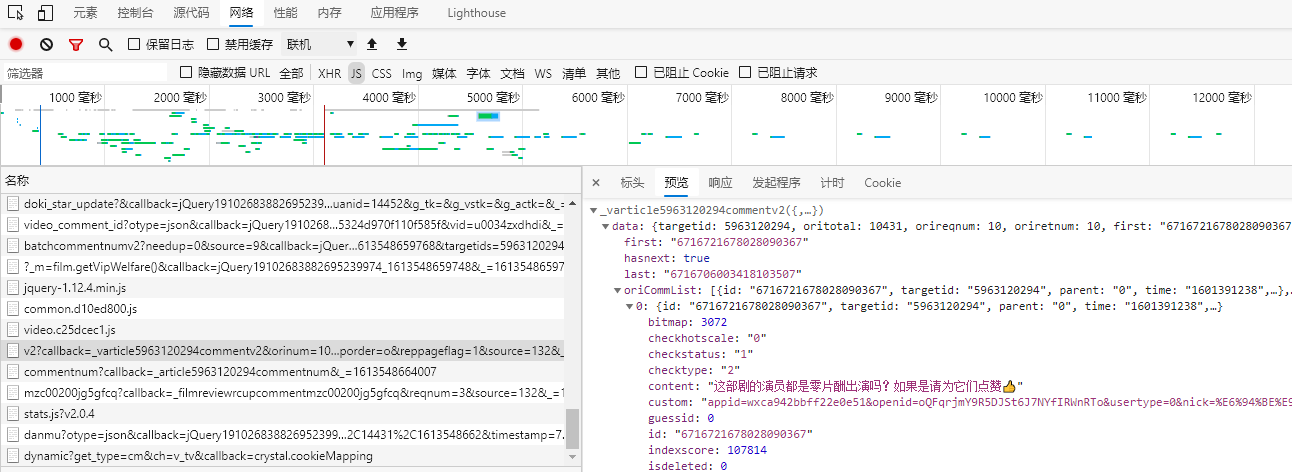
在新标签中打开,该网址的链接。

评论都在"content":"xxxxx"里面,所有可以通过正则表达式获取。
那么现在要开始构建网址,找到其规律。
在查找评论链接的过程中无意发现,点击影评旁边的评论总数,可以获取到更为干净的评论界面。结果是一样的。
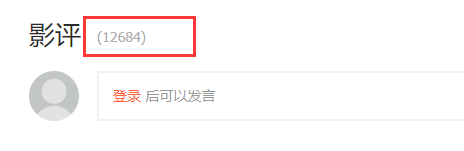
既然是要爬取所有的评论,所以知道评论数是必不可少的。

再通过F12获取到评论链接,找到网址的规律,构建网址,加载三四个评论就行了。这里加载了四个网址。把所有网址复制到文本文件中,进行对比分析。

观察发现只有 cursor 和 source 进行了改变,其他是不变的,二 source 是在第一个的基础上进行加一操作,所以只需要获取到 cursor 即可。我们打开一个评论链接的网址,我们可以知道,cursor 其实是上一页 最后一个用户的ID码。所以我们只需要在爬取上一页的时候一起爬虫了。然后就可以构建网址。

二、代码编写
这个代码还是简单的。套用之前上课做的模板就可以直接进行爬虫了。
通过正则表达式获取评论,返回一个列表;
正则表达式获得的 cursor 码是列表,所以要转化为字符串使用;
source 很简单了,直接在上一个的基础上加一即可。
def getComment(html): # 爬取单页评论 findeComment = re.compile(r'"content":"(.*?)"', re.S) comment = re.findall(findeComment, html) # print(comment) return comment def getCursor(html): # 获取下一页的cursor码 findeCursor = re.compile(r'"last":"(.*?)"', re.S) cursor = re.findall(findeCursor, html)[0] # print(cursor) return cursor def getSource(source): # 获取下一页的source码 source = int(source) + 1 return str(source)
有点难度的可能就送弄代理吧,但是代理可以模仿网上其他人的写法,所以还是不是很难。
#添加用户代理
def ua(uapools):
thisua = random.choice(uapools)
# print(thisua)
headers = ("User-Agent", thisua)
opener = urllib.request.build_opener()
opener.addheaders = [headers]
# 设置为全局变量
urllib.request.install_opener(opener)
三、遇到的问题
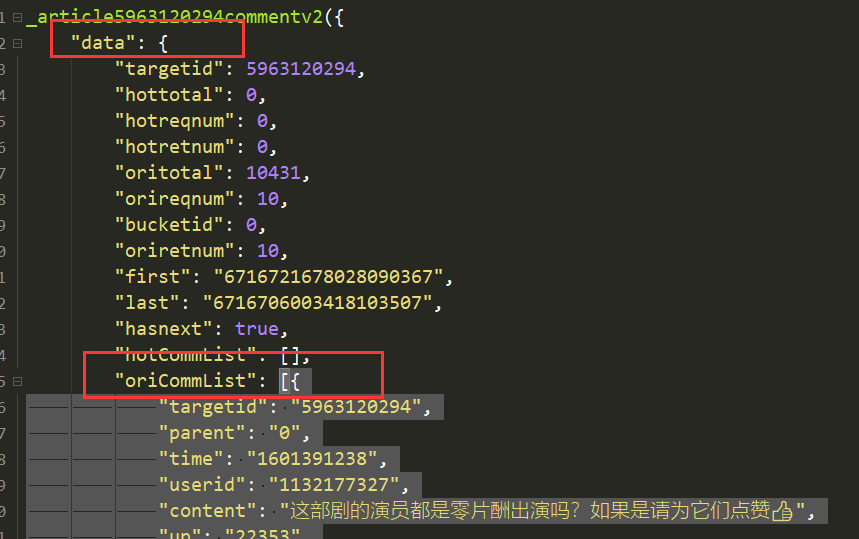
1. 获取评论的时候也将子评论爬虫进去了。
仔细查看了源码,发现评论主要在 data 下面的 oriCommList 列表里,其他范围的评论为子评论。个人认为子评论也算有效评论,目前不打算处理。
2. 获取全部评论数,直接通过 requests 获取不到
尝试了 xpath 和 requests 发现不能获取全部评论数,所以目前只能通过 selenium 获取,但是 selenium 效率太低了,就获取一个评论总数,还不如打开源码直接修改评论总数,所以暂时没有修改
3. 评论总数数据太大
因为之前爬虫过很多网站,同一个 user-agent 很容易被 ban ,所以目前构建了用户代理,然后进行随机。其实还想加一个 ip 代理的,但是使用了 ip 代理的网址,上面写的正常的 ip ,在使用的时候,拒绝连接。也尝试过构建代理池。但是代理池一般都是使用docker 和 Redis 进行获取。暂时没有选用,之选用了用户代理,然后在获取 headers 的时候加个 time.sleep(1)。目前还是正常的。
4. 报错'utf-8' codec can't decode byte 0xff in position 1: invalid start byte
遇到这个问题,实在无语,我怀疑后面的评论是新出的 emjoy,然后utf-8不能识别,程序挂掉了。但是选取其他格式,在解释的过程估计还会挂掉,就暂时爬到1万条吧。

四、完整代码
以上就是python 爬取腾讯视频评论的实现步骤的详细内容,更多关于python 爬取腾讯视频评论的资料请关注脚本之家其它相关文章!