
用python爬虫爬取CSDN博主信息
作者:皖渝
一、项目介绍
爬取网址:CSDN首页的Python、Java、前端、架构以及数据库栏目。简单分析其各自的URL不难发现,都是https://www.csdn.net/nav/+栏目名样式,这样我们就可以爬取不同栏目了。
以Python目录页为例,如下图所示:

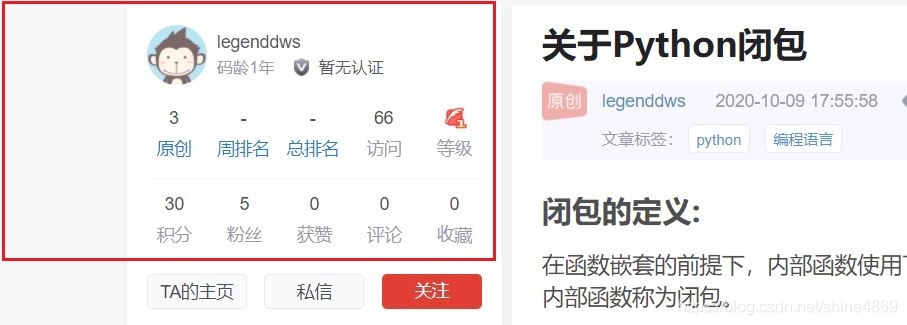
爬取内容:每篇文章的博主信息,如博主姓名、码龄、原创数、访问量、粉丝数、获赞数、评论数、收藏数
(考虑到周排名、总排名、积分都是根据上述信息综合得到的,对后续分析没实质性的作用,这里暂不爬取。)
不想看代码的朋友可直接跳到第三部分~
二、Selenium爬取
分析目录页可知文章是需要动态加载的,此时需要selenium模拟浏览器不断下拉才能获取新的文章。文章的链接如下所示:

1、第一种爬取思路(未果)
思路图如下:

执行的关键代码如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/nav/python')
#下拉若干次
for i in range(10):
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(1)
#定位所有链接
blog_url = driver.find_elements_by_css_selector('div.title > h2 > a') #注意:这里保存的是所有element对象
for i in range(len(blog_url)):
url = blog_url[i].get_attribute('href')
driver.get(url)
#------------相关信息爬取(省略)----------
driver.back() #返回目录页
理论上,这段代码看起来是可以实现要求的,但实际上会遇到以下两个问题!
(1)元素定位问题
报错的原因:selenium当打开新的页面后,原来定位过的元素都会失效,需要重新定位元素。上面的driver.back()相当于打开的新的页面(但是对于我们来说只是返回原来的页面)
解决方式:只要每次返回目录页后重新定位元素即可,如下所示:
for i in range(len(blog_url)):
blog_refind_url = driver.find_elements_by_css_selector('div.title > h2 > a') #重新定位
url = blog_refind_url[i].get_attribute('href')
driver.get(url)
#------------相关信息爬取(省略)----------
driver.back() #返回目录页
重新定位后,不难发现,这必须要求blog_url和blog_refind_url这两个列表的长度一致啊!那也就是:每次返回目录页后,需要保持在上一次浏览的位置! 由此引发了第二个问题:定位元素的不一致。
(2)定位元素不一致
我们在获取所有的文章链接之前,首先进行的下滑页面的操作。而每次driver.back()之后,页面都会回到最初的位置!这就很头疼,如果要保持一样的浏览位置,难道每次返回后都要下拉相同次数的页面么?那么此时我们需要解决的问题则是:如何保持上一级页面的浏览位置。emm,查了一些资料,发现这个需求是和javascript相关的。详细可参考这篇博客:js:返回到页面时滚动到上次浏览位置
大致解决思路:保存每次下滑的位置,然后最终调用最后一次下滑的位置。但归根到底,还是需要每次滑动页面,依旧很麻烦,这种思路到这也只能不了了之了。(会javascript的朋友可以尝试如何让页面直接恢复到上一级页面浏览的位置)
2、第二种爬取思路(成功)
不过,仔细思考一下,上面两个问题的来源关键在于selenium访问页面后,元素会重新定位。而我们第一步定位所有文章链接时保存的列表,里面的元素都是element对象(它是会随着页面变化而改变的!)。所以,我们只要保存每个文章的url到一个列表,挨个访问每个url,不就可以了?
思路图如下:

两种思路的对比与思考:前者装有所有文章的列表里都是element对象,而后者装有所有文章的列表里都是url。后者免去了再返回页面这一操作,相当于将一个爬取二级页面问题转化为一级页面问题!
全部代码如下:
from selenium import webdriver
import os
os.chdir('C:/Users/dell/Desktop')
import time
import pandas as pd
def scroll_down(driver,num):
for i in range(num):
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(1)
def save_data(df):
data=pd.DataFrame(df,columns=['blog_name','code_time','blog_num',
'view_num','fans_num','likes_num',
'comments_num','collections_num'])
data.to_csv('csdn_user.csv',index=False,encoding='gb18030')
def crawler_csdn(parts_list):
opt = webdriver.ChromeOptions()
opt.add_experimental_option('excludeSwitches',['enable-automation'])
opt.add_argument('--headless')
opt.add_argument('--disable-gpu')
opt.add_argument('blink-settings=imagesEnabled=false')
driver = webdriver.Chrome(options=opt)
df = []
for part in parts_list:
count=0
url_des='https://www.csdn.net/nav/'+part
driver.get(url_des)
scroll_down(driver,30)
time.sleep(2)
print('开始爬取{}部分'.format(part))
blog_list=[]
blog_url = driver.find_elements_by_css_selector('div.title > h2 > a')
for url in blog_url:
blog_list.append(url.get_attribute('href'))
print('共{}个博主'.format(len(blog_list)))
for i in range(len(blog_list)):
try:
driver.get(blog_list[i])
blog_name = driver.find_element_by_css_selector('div.profile-intro-name-boxTop > a >span.name').text
code_time = driver.find_element_by_css_selector('span.personal-home-page.personal-home-years').text
blog_num = driver.find_element_by_css_selector(
'div.data-info.d-flex.item-tiling>dl.text-center>a>dt>span.count').text
inf_list = driver.find_elements_by_css_selector('div.data-info.d-flex.item-tiling>dl.text-center>dt>span.count')
df.append([blog_name, code_time, blog_num,
inf_list[0].text, inf_list[2].text, inf_list[3].text,
inf_list[4].text, inf_list[5].text])
count += 1
print('第{}个博主信息爬取完成'.format(count))
except:
print('相关信息不全')
print('{}部分爬取完成'.format(part))
return df
if __name__ =='__main__':
start = time.time()
parts_list=['Python','Java','web','arch','db']
df = crawler_csdn(parts_list)
save_data(df)
end = time.time()
spend_time = int((end-start)/60)
print('共花费{}分钟'.format(spend_time))
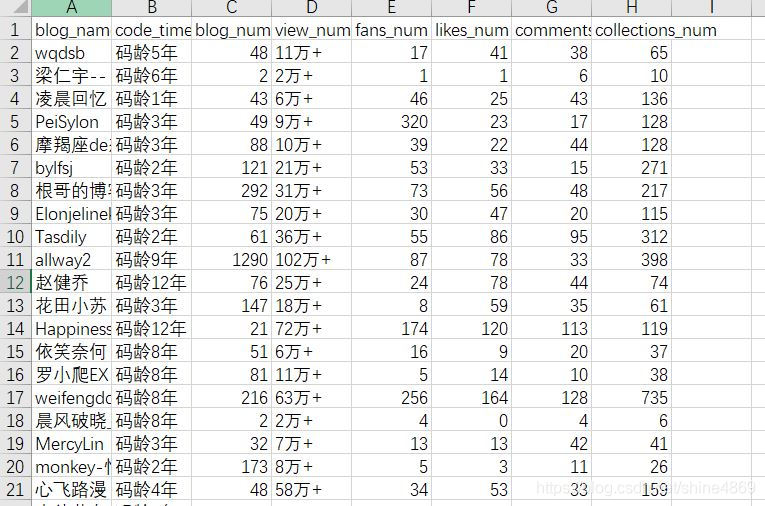
爬取结果如下:
三、Webscraper爬取
之前的博客分享过Webscraper是一种轻量级的爬取软件。不想看代码的朋友可以用它来复现上述爬取过程。(注:以下爬取过程只是针对首页的某一个栏目)
最终的爬取线路图如下
依旧以首页的Python栏为例:
1、创建下拉对象
这个container只是一个ID,它可以取任意名字的。其他的设置如下图所示:
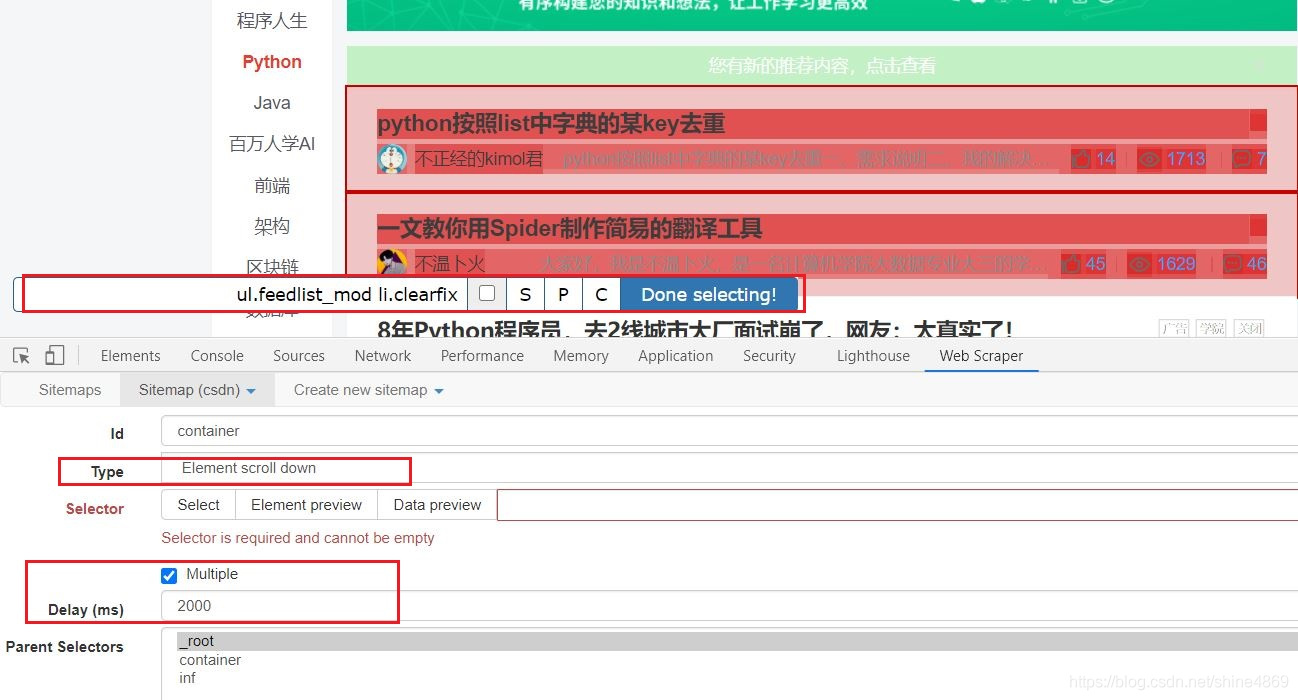
Type勾选Element_scroll_down(负责下拉页面)勾选上Multiple后,点击多个文章所在模块后,则会出现红色选定。此时点击Done selecting,完成selector的配置。Delay设置为2000毫秒(给予页面反应时间)
此外,需要在selector后面加上:nth-of-type(-n+300),控制爬取的条数,否则它会一直下拉页面!(这里的300则代表需要爬取的总条数)最终,selector的配置如下:

2、创建文章链接对象
保存container的selector后,点击进入下一层,创建如下selector

具体内容如下:
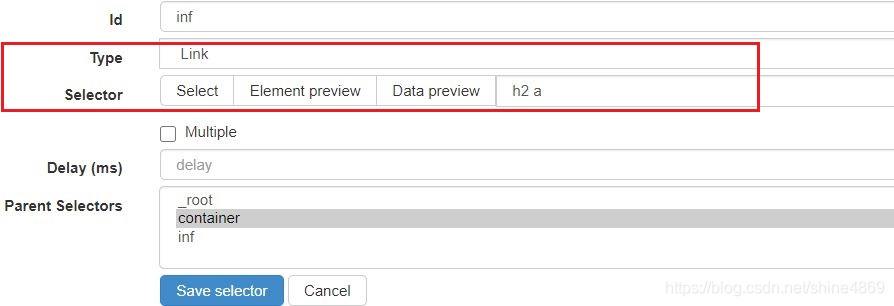
Type选择LinkSelector中不勾选Multiple,h2 a则是文章链接定位的位置
Link不方便定位的话,可以先选择text进行定位,然后得到位置后,再复制到link这即可。
3、创建博主信息对象
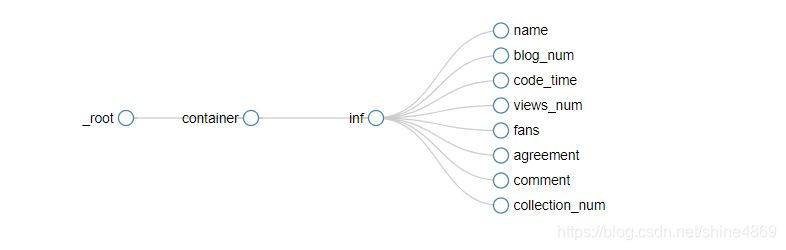
同理,保存完inf的selector后,再点击进入下一层,依次创建各类信息的selector,如下所示:
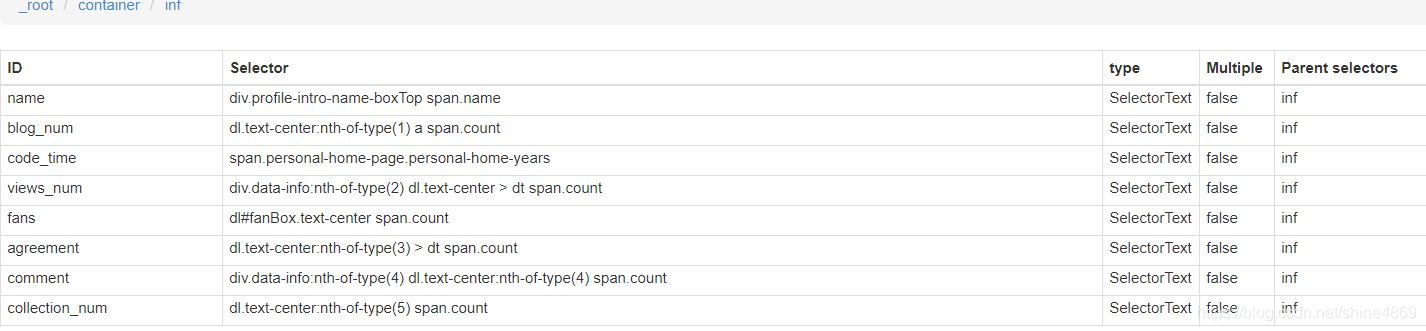
以name为例,其内容如下:
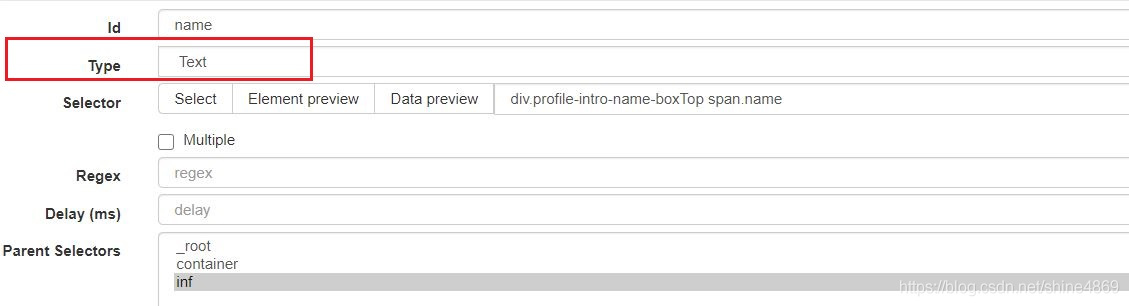
type选择text,相应的选择器内容只要鼠标点击博主姓名即可获得。
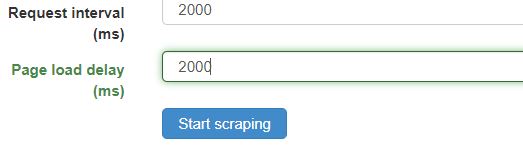
这样,我们就完成了所有的准备工作,接下来就可爬取啦~所有延迟时间均设置为2000ms
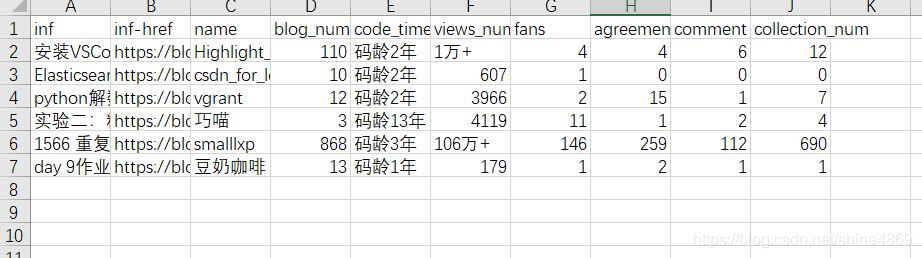
最终爬取结果如下(这里仅作演示,只爬取了七条):
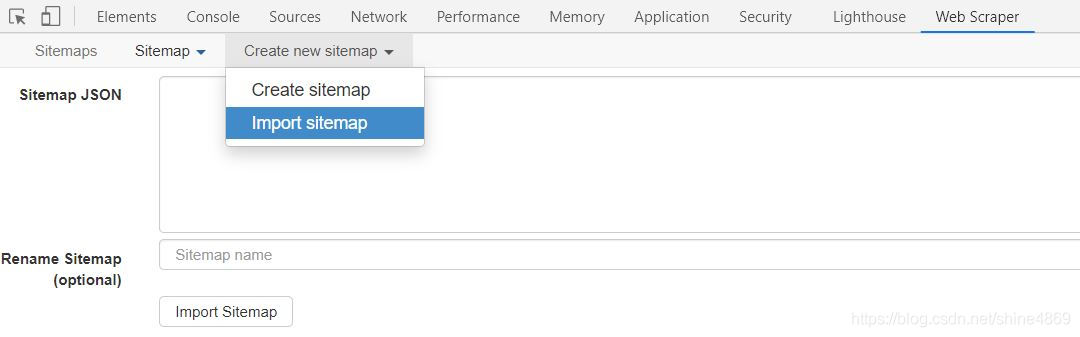
本次创建的sitemap如下,有兴趣的朋友可以自己实验下,只需要import sitemap即可
{"startUrl":"https://blog.csdn.net/nav/python","selectors":[{"parentSelectors":
["_root"],"type":"SelectorElementScroll","multiple":true,"id":"container","selector":"ul.feedlist_mod li.clearfix:nth-of-type(-n+300)","delay":"2000"},{"parentSelectors":
["container"],"type":"SelectorLink","multiple":false,"id":"inf","selector":"h2 a","delay":""},{"parentSelectors":
["inf"],"type":"SelectorText","multiple":false,"id":"name","selector":"div.profile-intro-name-boxTop span.name","regex":"","delay":""},{"parentSelectors":
["inf"],"type":"SelectorText","multiple":false,"id":"blog_num","selector":"dl.text-center:nth-of-type(1) a span.count","regex":"","delay":""},{"parentSelectors":
["inf"],"type":"SelectorText","multiple":false,"id":"code_time","selector":"span.personal-home-page.personal-home-years","regex":"","delay":""},{"parentSelectors":
["inf"],"type":"SelectorText","multiple":false,"id":"views_num","selector":"div.data-info:nth-of-type(2) dl.text-center > dt span.count","regex":"","delay":""},{"parentSelectors":
["inf"],"type":"SelectorText","multiple":false,"id":"fans","selector":"dl#fanBox.text-center span.count","regex":"","delay":""},{"parentSelectors":
["inf"],"type":"SelectorText","multiple":false,"id":"agreement","selector":"dl.text-center:nth-of-type(3) > dt span.count","regex":"","delay":""},{"parentSelectors":
["inf"],"type":"SelectorText","multiple":false,"id":"comment","selector":"div.data-info:nth-of-type(4) dl.text-center:nth-of-type(4) span.count","regex":"","delay":""},{"parentSelectors":["inf"],"type":"SelectorText","multiple":false,"id":"collection_num","selector":"dl.text-center:nth-of-type(5) span.count","regex":"","delay":""}],"_id":"csdn"}
总结:Webscraper虽然简单易操作,速度也和selenium差不多,但每次只能爬一个网址,需要连续爬取多个网址,还是得码代码~
以上就是使用python快速爬取CSDN博主信息的详细内容,更多关于python爬取CSDN博主信息的资料请关注脚本之家其它相关文章!