
Python 读取.dat 文件的实现
作者:简朴-ocean
这篇文章主要介绍了Python 读取.dat 文件的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
写在前面
使用matlab可以输出为 .dat 或者 .mat 形式的文件,之前介绍过读取 .mat 后缀文件,今天正好把 .dat 的读取也记录一下。
读取方法
这里可以使用pandas库将其作为一个dataframe的形式读取进python,数据内容格式如下,根据空格分隔开分别为:
经度、纬度、年、月、日、时、分、秒、变量数值
0 88.486 10.181 2023.0 3.0 20.0 0.0 15.0 0.0 3329.973 1 88.486 10.181 2023.0 3.0 20.0 0.0 30.0 0.0 3330.019 2 88.486 10.181 2023.0 3.0 20.0 0.0 45.0 0.0 3330.043 3 88.486 10.181 2023.0 3.0 20.0 1.0 0.0 0.0 3330.077
由于原始的dat文件中是没有相关数据的信息的,这里为了方便后续处理,手动将其添加上相关的经纬度信息
需要注意的是,在直接将 DataFrame 传递给 pd.DataFrame 构造函数并指定列名时,如果原始 DataFrame 的列数和新列名的数量不匹配,可能会导致数据不一致,从而生成 NaN 值。使用 to_numpy() 方法将 DataFrame 转换为 NumPy 数组可以确保数据的一致性,因为它会忽略原始列名并仅保留数据。
- 读取数据
import pandas as pd from datetime import datetime import numpy as np file_path = r'R:/ll/cj_YD_first_bpr_water_level.dat' df = pd.read_csv(file_path, header=None,sep=r'\s+') df
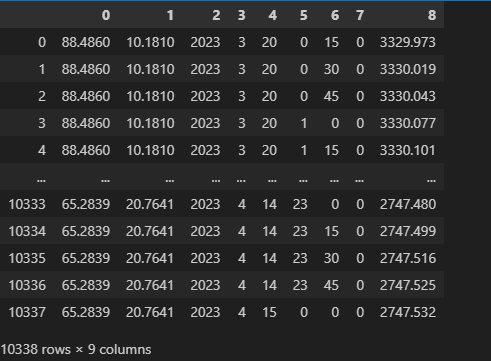
- 添加经纬度信息
df_from_array = pd.DataFrame(df.to_numpy(), columns=['lon', 'lat', 'year', 'month', 'day', 'hour', 'min', 'sec', 'water'])
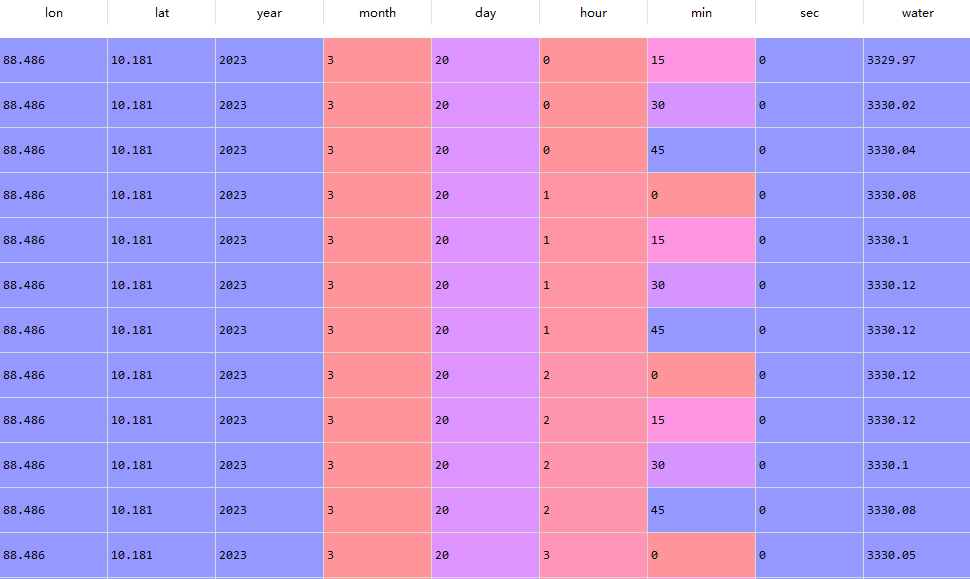
- 将时间提取出来作为新的一列,方便后续绘图
df_from_array['datetime'] = df_from_array.apply(lambda row: datetime(year=int(row['year']),
month=int(row['month']),
day=int(row['day']),
hour=int(row['hour']),
minute=int(row['min']),
second=int(row['sec'])),axis=1)
df_from_array
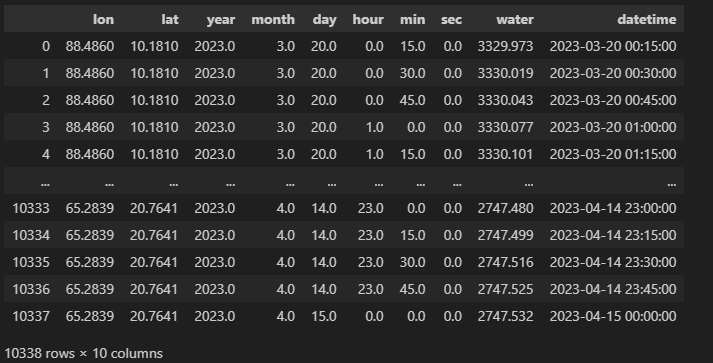
这里,做一个特殊的预处理,由于需要时刻的数据是相同的经纬度位置的,这里挑选出所有相同经纬度坐标点的数据
grouped = df_from_array.groupby(['lon', 'lat','datetime'])['water'].apply(list).reset_index() grouped
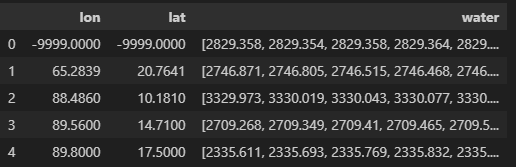
- 发现存在缺测的站点,剔除掉缺测的经纬度数据
grouped = grouped[(grouped['lon'] != -9999.0000) & (grouped['lat'] != -9999.0000)] grouped['water'] = grouped['water'].apply(lambda x: x[0]) grouped
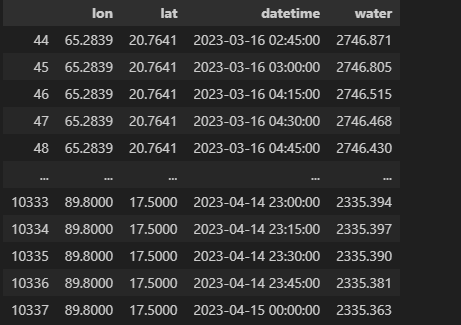
绘图
挑选相同站点,不同时间的数据绘制曲线,为了避免不同位置的站点的数据大小存在较大差异,设置不同的y轴来表征
fig, ax1 = plt.subplots(figsize=(15, 10), dpi=200)
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['Times New Roman']
plt.rcParams['font.size'] = 16
axes = [ax1]
colors = plt.cm.tab10.colors
lines = []
labels = []
for i, (_, coord) in enumerate(unique_coords.iterrows()):
lon = coord['lon']
lat = coord['lat']
filtered_data = grouped[(grouped['lon'] == lon) & (grouped['lat'] == lat)]
if i == 0:
ax = ax1
else:
ax = ax1.twinx()
axes.append(ax)
ax.spines['right'].set_position(('outward', 80 * (i - 1)))
color = colors[i % len(colors)]
line, = ax.plot(filtered_data['datetime'], filtered_data['water'], color=color,
linewidth=0.9, linestyle='-', label=f'Lon: {lon}, Lat: {lat}')
ax.set_ylabel(f' (Lon: {lon}, Lat: {lat})')
ax.yaxis.label.set_color(color)
ax.tick_params(axis='y', colors=color)
lines.append(line)
labels.append(f'Lon: {lon}, Lat: {lat}')
ax1.legend(lines, labels, loc='best',ncols=2, bbox_to_anchor=(0.9, 1))
plt.xticks(rotation=55)
plt.grid()
fig.suptitle('Data Over Time for Different station', y=0.95)
plt.tight_layout()
plt.show()
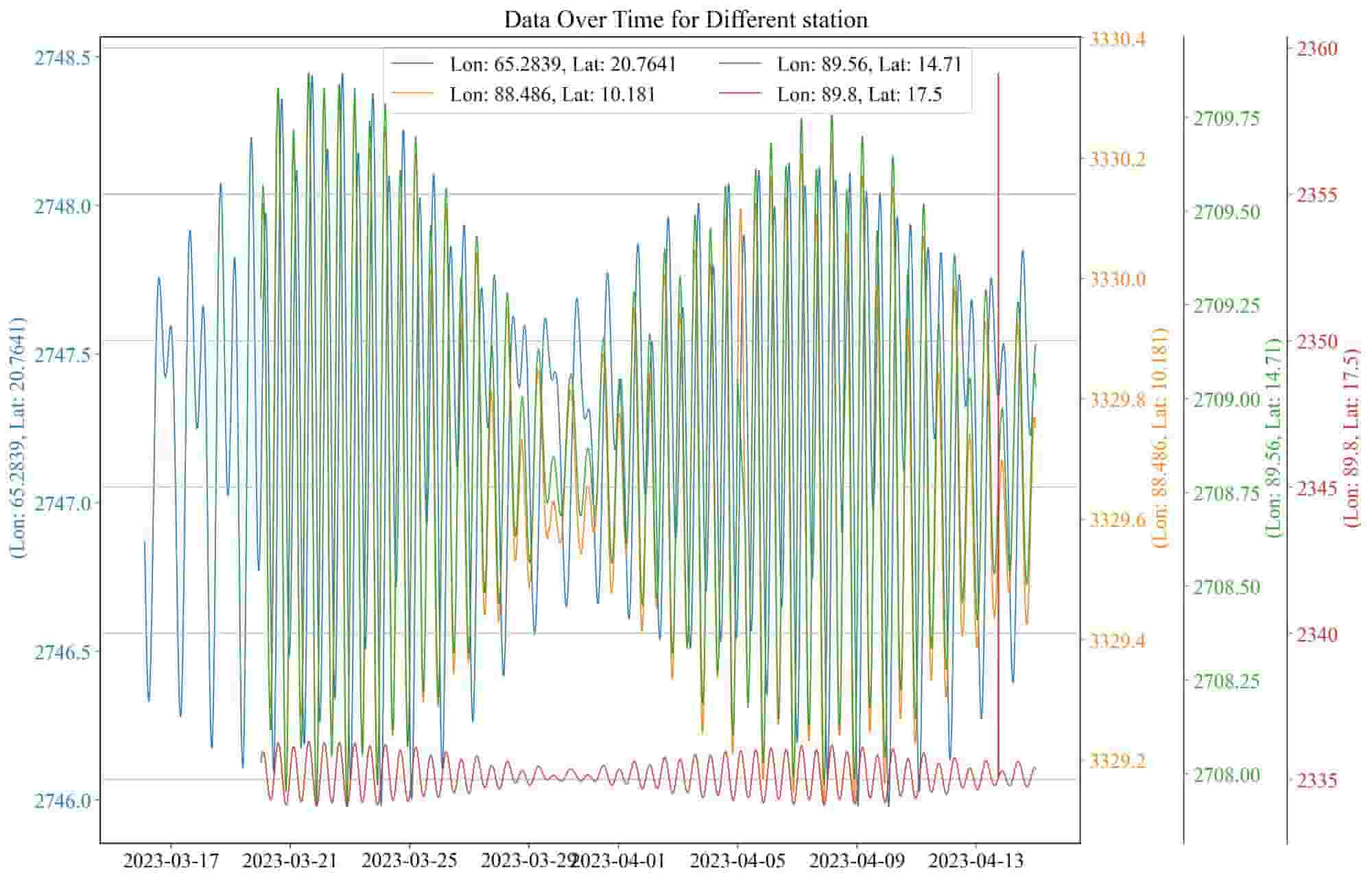
总结
复习了一下使用pandas读取.dat文件的相关函数,以及pandas的一些基础命令,绘图多y轴的方法。相关数据和代码放到GitHub上
到此这篇关于详解用python实现爬取CSDN热门评论URL并存入redis的文章就介绍到这了,更多相关python爬取URL内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!