
pandas 实现分组后取第N行
作者:NoOne-csdn
目的:
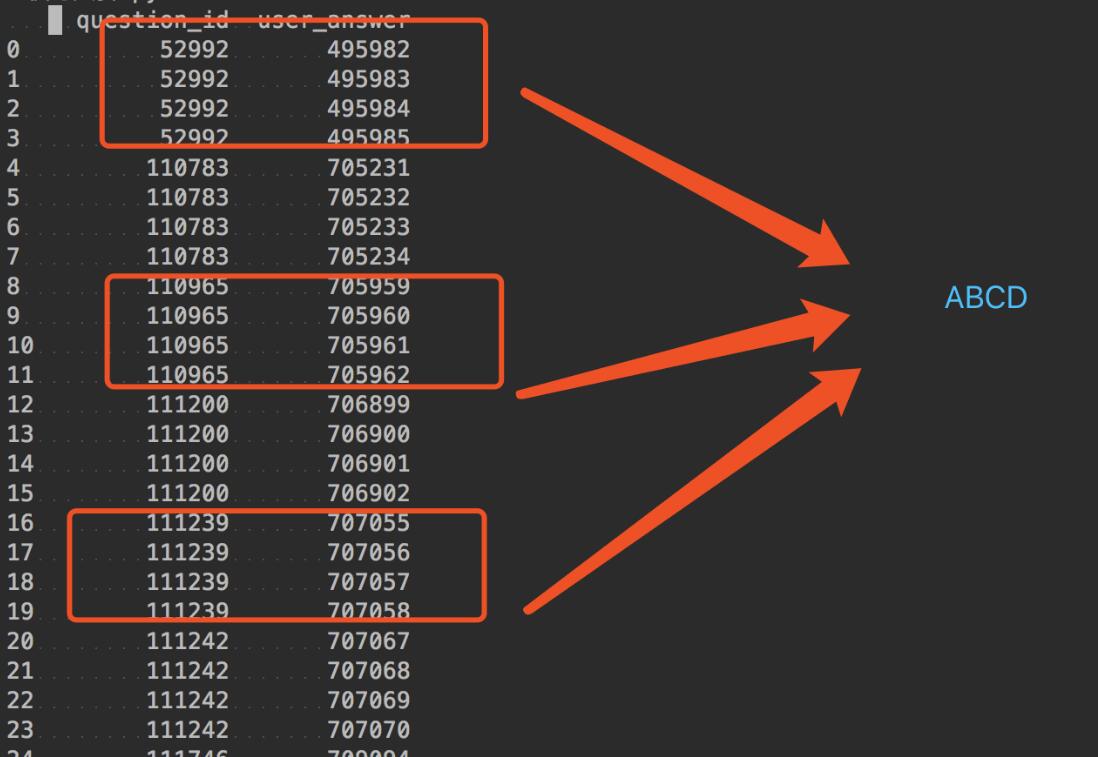
把question_id 对应的user_answer转成ABCD
solution
dfa=df.groupby('question_id').nth(0).reset_index()
dfa['flag']='A'
dfb=df.groupby('question_id').nth(1).reset_index()
dfb['flag']='B'
dfc=df.groupby('question_id').nth(2).reset_index()
dfc['flag']='C'
dfd=df.groupby('question_id').nth(3).reset_index()
dfd['flag']='D'
resdf=dfa.append([dfb,dfc,dfd])
resdf.sort_values(by='question_id')
result:
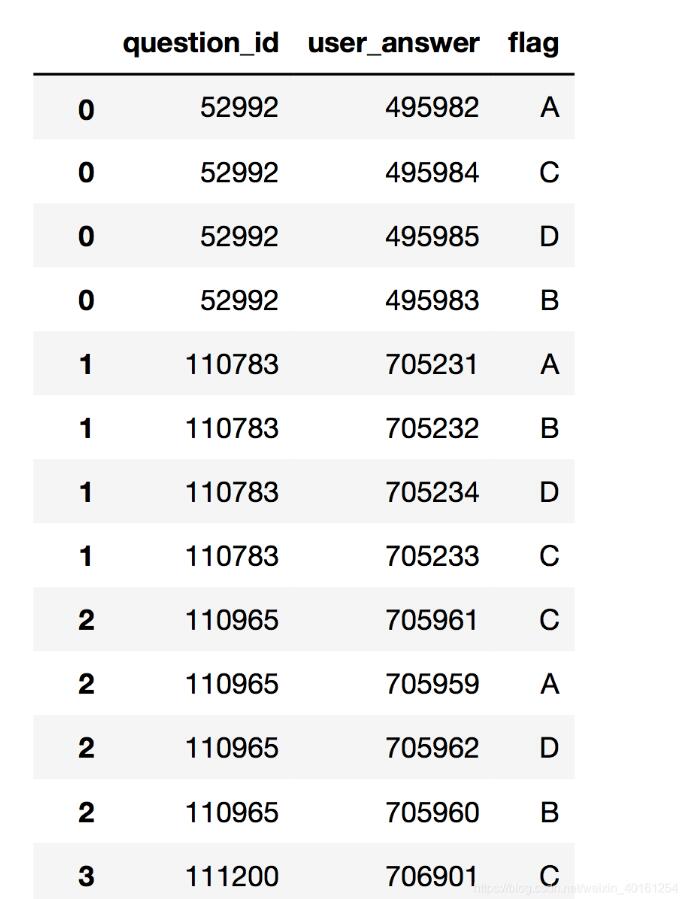
focus:
g.nth(0) #同 g.first() g.head(1) g.last() g.nth(2) g.nth(-1) g.nth(0,dropna='any') g.B.nth(0,dropna='all') g.groups g.get_group(134429) g.discribe() g.agg([np.mean,np.sum.np,std])
补充:pandas的分组取最大多行并求和函数nlargest()
在pandas库里面,我们常常关心的是最大的前几个,比如销售最好的几个产品,几个店,等。之前讲到的head(), 能够看到看到DF里面的前几行,如果需要看到最大或者最小的几行就需要先进行排序。max()和min()可以看到最大或者最小值,但是只能看到一个值。
所以我们可以使用nlargest()函数,nlargest()的优点就是能一次看到最大的几行,而且不需要排序。缺点就是只能看到最大的,看不到最小的。
我们来看看单价排在前十的数据:
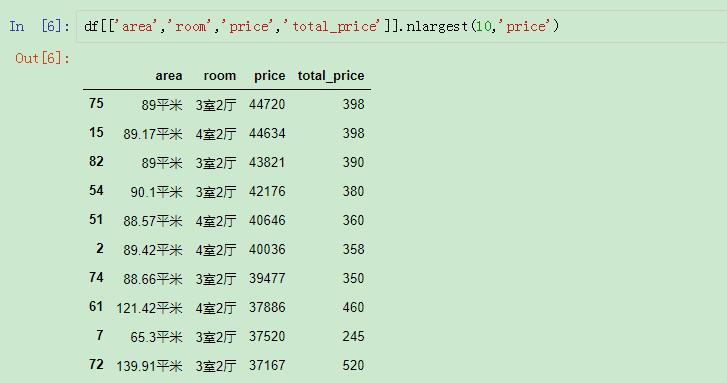
单价排在前十的数据
nlargest()的第一个参数就是截取的行数。第二个参数就是依据的列名。
这样就可以筛选出单价最高的前十行,而且是按照单价从最高到最低进行排列的,所以还是按照之前的索引。
还可以按照total_price来进行排名:
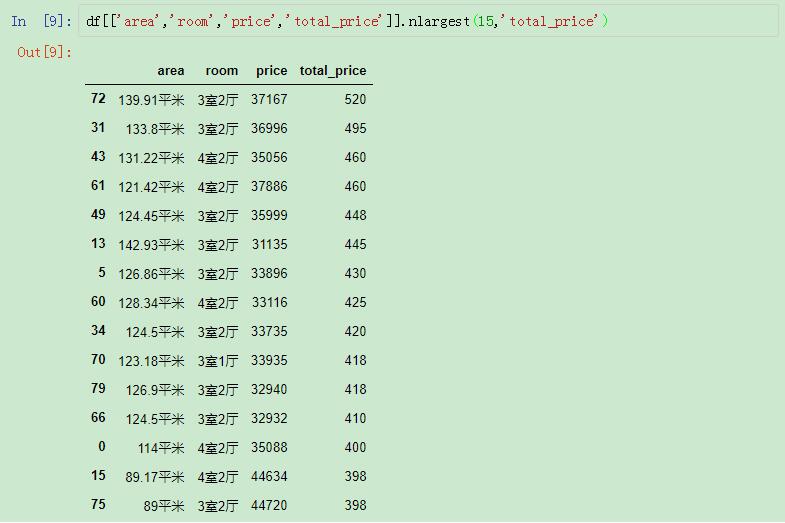
按照total_price排名
nlargest还有一个参数,keep='first'或者'last'。当出现重复值的时候,keep='first',会选取在原始DataFrame里排在前面的,keep='last'则去排后面的。
由于nlagerst()不能去最小的多个值,如果我们一定要使用这个函数进行选取也是可以的.
先设置一个辅助列:
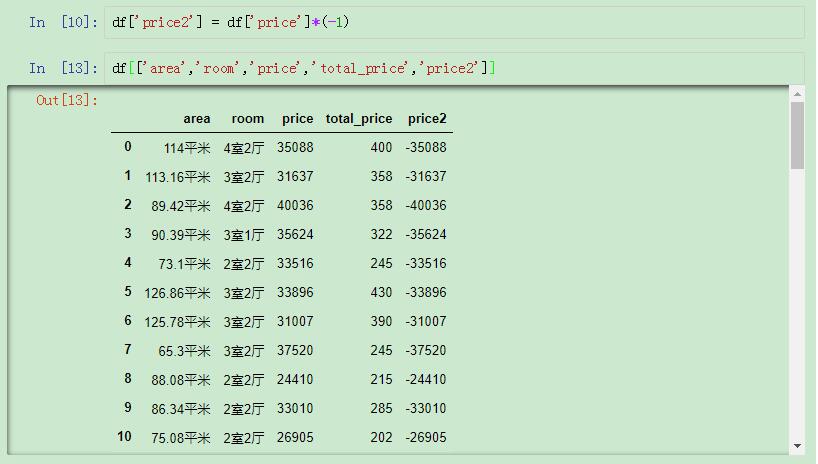
先设置一个辅助列
然后在进行选取:
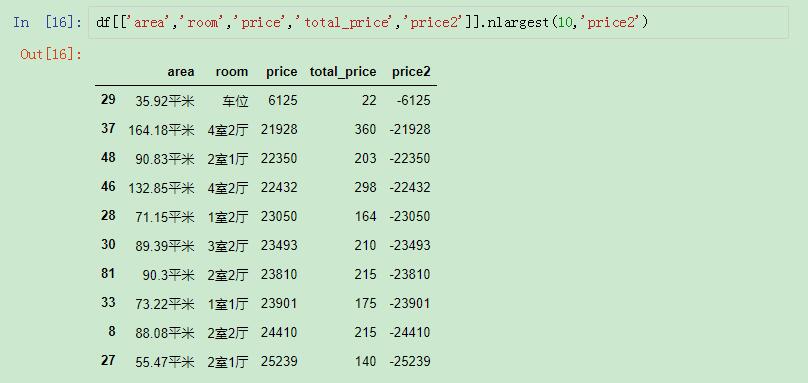
以辅助列进行选取
当然了,也可以通过head()加上排序进行选取的。
那以前这些操作都可以通过其它函数来进行替代的话,nlargest()有什么必要介绍吗?或者说学不学这个函数有什么关系吗?
这就是我们今天要重点介绍的,如果说要选择不同location_road下的前五名要怎么操作呢?
很多人可能第一反应会想到先分组然后进行max()操作,但是这样的操作只能选择最大的一列:
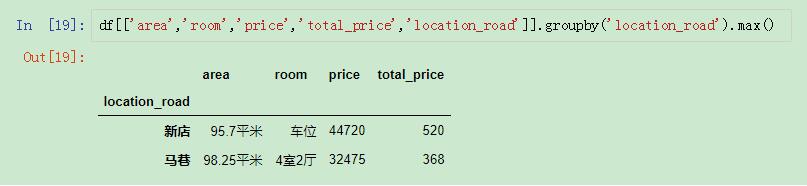
使用max()
但是使用max有一个问题,就是选取的是每一列的最大值,而不是选取最大值的那一行,也就是说只能在选取单列的最大值的时候才是准确的。
这个时候我们就要想到apply和lambda的自定义函数了:
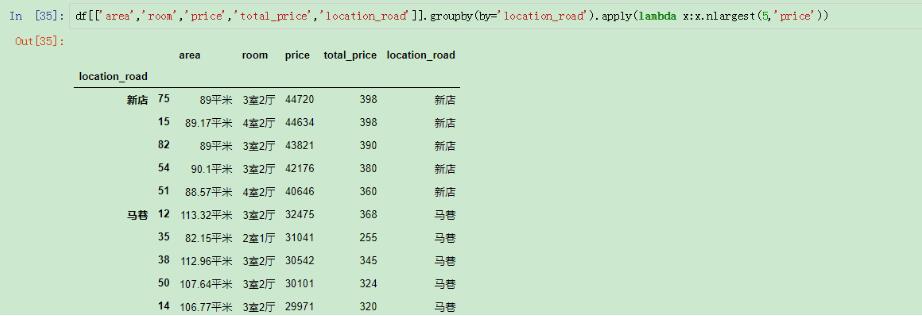
选取多个指标的TOP(N)
这样就选出了不同loaction_road的price排在前五的行了。
nlargest()函数在这种场景下使用是非常方便的,而且结果也已经默认排好顺序了。
还有一些场景下需要计算分组的前几名,然后在进行求和的,这个我们也可以使用nlargest进行操作:
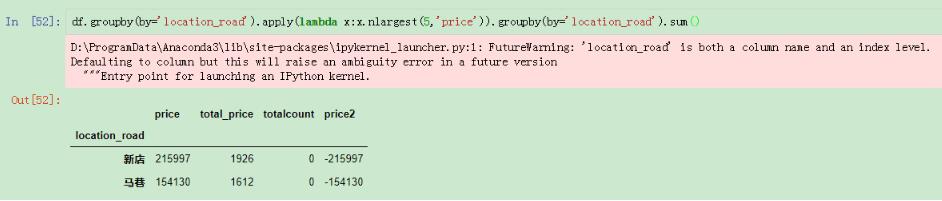
分组之后进行求和
使用这种方法会出现报错提示,这个因为在列和索引都存在loaction_road,有重复,系统有警告,在实际使用时可以先改列名再操作。我们也可以换一种方式直接按照索引进行求和,这样就没有警告了:

以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。