
pandas组内排序,并在每个分组内按序打上序号的操作
作者:Automation_走天涯
这篇文章主要介绍了pandas组内排序,并在每个分组内按序打上序号的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
问题:
pandas组内排序,并在每个分组内按序打上序号
描述:
pandas dataframe 对dep_id组内的salary排序。希望给下面原本只有前三列的dataframe,添加上第四列。
等价于sql里的排序函数 row_number() over() 功能
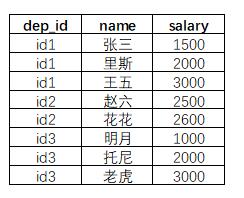
假设我已经建好了仅有前三列的dataframe,数据集命名为 MyData,
解决方案如下:
MyData['sort_id'] = MyData['salary'].groupby(MyData['dep_id']).rank()
结果如下:
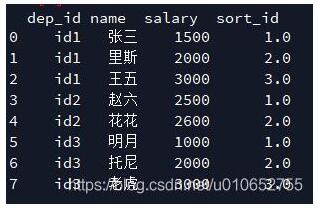
补充:Pandas.DataFrame实现分组、排序并且为分组插入排名
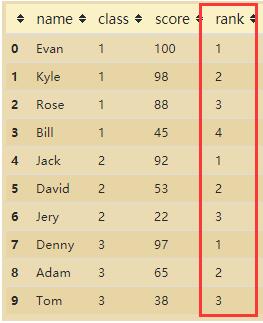
1. 示例数据(各班级学生得分)
import pandas as pd
data_dict = {"name":
["Rose", "Jack", "Tom", "Kyle", "Jery", "Adam", "Bill", "David", "Denny", "Evan"],
"class": [1, 2, 3, 1, 2, 3, 1, 2, 3, 1],
"score": [88, 92, 38, 98, 22, 65, 45, 53, 97, 100]}
df = pd.DataFrame(data=data_dict)
df
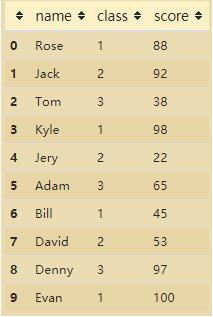
2. 按班级分组
df = df.groupby('class', sort=False)\
.apply(lambda x:x.sort_values("score", ascending=False))\
.reset_index(drop=True)
df
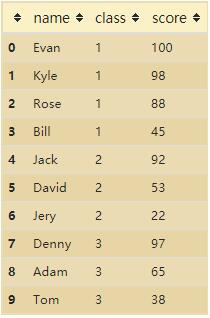
3. 给各分组班级增加排名列
df["rank"] = None
# 标识班级
flag = df.loc[0].values[1]
rank = 0
for i in range(len(df)):
temp = df.loc[i].values[1]
if (temp == flag).all():
# 同一班级
rank += 1
else:
# 不同班级,重新计算排名
flag = temp
rank = 1
df.loc[i, "rank"] = rank
df
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。