
详解shell 变量的高级用法示例
作者:Crazymagic
变量删除和替换

案例:从头开始匹配,将符合最短的数据删除 (#)
variable_1="I love you, Do you love me"
echo $variable_1
variable_2=${variable_1#*ov}
echo $variable_2

案例:从头开始匹配,将复合最短的数据删除(##)
varible_3=${variable_1##*ov}
echo $varible_3

案例:替换字符串,只替换第一次匹配成功的(/)
echo $PATH
var6=${PATH/bin/BIN}
echo $var6

案例:替换字符串,符合条件的全部替换 (//)
var7=${PATH//bin/BIN}
echo $var7

变量测试

简单举例(用的比较少)
var=${str-expr}
如果变量 str 没有定义,那么var=expr
如果变量 str的字符串中有值,那么 变量 var 的值就等于 str变量的值

字符串处理
计算字符串的长度

案例1
var="hello world"
len=${#var}
echo $len

案例2
var1="zhang biao" len=`expr length "$var1"` echo $len

获取字串在字符串中的索引位置 (把字串拆分成一个个的字串,最先匹配到的第一个就会返回)

案例
var="quickstart is a app" ind=`expr index "$var" start` echo $ind
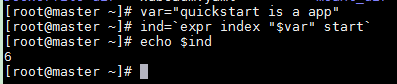
案例 查找一个不存在的字串,返回 1
ind=`expr index "$var" uniq` echo $ind

计算字串的长度 (只能从头开始匹配,用的不多)

例子:找不到返回 0,不是从头开始匹配
var="quickstart is a app" sub_len=`expr match "$var1" app` echo $sub_len

从头开始匹配
sub_len=`expr match "$var" quick*` echo $sub_len

sub_len=`expr match "$var" quick.*` echo $sub_len

抽取字串

案例:方法一
提取var1中索引从10开始一直到结尾的字符串,索引下标从0开始
var1="kafka hadoop yarn mapreduce"
sub_str1=${var1:10}
echo $sub_str1

案例:方法二
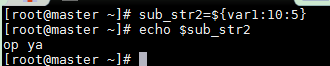
从第10个位置开始提取5个字符串
sub_str2=${var1:10:5}
echo $sub_str2
案例:方法三
取最后的5位
sub_str3=${var1: -5}
echo $sub_str3

案例:方法四
取从最后开始取最后5位,注意 var1: -5 之间有空格
sub_str3=${var1:(-5)}
echo $sub_str3

案例:方法五
提取最后5位的前两位
sub_str3=${var1: -5:2}
echo $sub_str3

注意: 使用expr,索引计数是从1开始计算 使用${string:position},索引计数是从0开始
字符串处理完整脚本
需求描述:
变量 string="Bigdata process framework is Hadoop,Hadoop is an open source project"
执行脚本后,打印输出string字符串变量,并给出用户以下选项:
(1)、打印string长度
(2)、删除字符串中所有的Hadoop
(3)、替换第一个Hadoop为Mapreduce
(4)、替换全部Hadoop为Mapreduce用户输入数字1|2|3|4,可以执行对应项中的功能;输入q|Q则退出交互模式
思路分析:
1、将不同的功能模块划分,并编写函数、
- function print_tips
- function len_of_string
- function del_hadoop
- function rep_hadoop_mapreduce_first
- function rep_hadoop_mapreduce_all
2、实现第一步所定义的功能函数
#!/bin/bash
#
string="Bigdata process framework is Hadoop,Hadoop is an open source project"
function print_tips
{
echo "********************************************"
echo "(1)打印string长度"
echo "(2)删除字符串中所有的Hadoop"
echo "(3)替换第一个Hadoop为Mapreduce"
echo "(4)替换全部Hadoop为Mapreduce"
echo "********************************************"
}
function len_of_string
{
echo "${#string}"
}
function del_hadoop
{
# 把hadoop替换为空
echo "${string//Hadoop/}"
}
function rep_hadoop_mapreduce_first
{
echo "${string/Hadoop/Mapreduce}"
}
function rep_hadoop_mapreduce_all
{
echo "${string//Hadoop/Mapreduce}"
}
3、程序主流程的设计
example.sh
#!/bin/bash
#
string="Bigdata process framework is Hadoop,Hadoop is an open source project"
function print_tips
{
echo "********************************************"
echo "(1) 打印string长度"
echo "(2) 删除字符串中所有的Hadoop"
echo "(3) 替换第一个Hadoop为Mapreduce"
echo "(4) 替换全部Hadoop为Mapreduce"
echo "********************************************"
}
function len_of_string
{
echo "${#string}"
}
function del_hadoop
{
# 把hadoop替换为空
echo "${string//Hadoop/}"
}
function rep_hadoop_mapreduce_first
{
echo "${string/Hadoop/Mapreduce}"
}
function rep_hadoop_mapreduce_all
{
echo "${string//Hadoop/Mapreduce}"
}
while true
do
echo " 【string=$string】"
echo
print_tips
read -p "Pls input your choice(1|2|3|4|q|Q):" choice
case $choice in
1)
len_of_string
;;
2)
del_hadoop
;;
3)
rep_hadoop_mapreduce_first
;;
4)
rep_hadoop_mapreduce_all
;;
q|Q)
exit
;;
*)
echo "Error,input only in {1|2|3|4|q|Q}"
;;
esac
done

命令替换
语法格式

例子1: 获取系统的所有用户并输
cat /etc/passwd | cut -d ":" -f 1
使用 cut 对 : 进行切割,获取第一个及时用户的名字
for循环能以空格、换行、tab键作为分隔符
sys_user.sh
#!/bin/bash # index=1 for user in `cat /etc/passwd | cut -d ":" -f 1` do echo "this is $index user: $user" index=$(($index + 1)) done

例子2: 根据系统时间计算今年或明年
echo "this is $(date +%Y) year" echo "this is $(( $(date +%Y) + 1)) year"

总结: ``和$()两者是等价的,但推荐初学者使用$(),易于掌握;缺点是极少数UNIX可能不支持,但``两者都支持 $(())主要用来进行整数运算,包括加减乘除,引用变量前面可以加$,也可以不加$
echo "$((20+30))"

示例3
echo $((100+30)) echo $(( (100 + 30) / 13 )) echo $(( $num1 + $num2 * 2))
shell 语法不是很严格,是否加$都会计算
num1=50 num2=70 echo "$((num1 + num2))"
例子4:
今天是今年的第多少天
echo $(date +%j)

根据系统时间获取今年还剩下多少星期,已经过了多少星期
echo "this year have passed $(date +%j) days" echo "this year have passed $(($(date +%j) / 7)) weeks"

今年还剩余多少天
echo "there is $((365 - $(date +%j))) days before new year" echo "there is $(((365 - $(date +%j)) / 7 )) weeks before new year"

示例5:判断nginx进程是否存在,如果没有需求拉起这个进程
example_3.sh
#!/bin/bash # # grep -v 过滤掉 grep 进程 nginx_process_num=$(ps -ef|grep nginx|grep -v grep|wc -l) if [ $nginx_process_num -eq 0 ];then systemctl start nginx fi
有类型变量


shell编程系列4--有类型变量:字符串、只读类型、整数、数组
declare -r 将变量设置为只读类型
var2="hello python" declare -r var2 var2="hello java"

declare -i 将变量设为整数
默认把变量当做字符处理
num1=10 num2=$num1+20 echo $num2

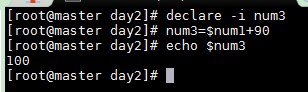
声明为整数
declare -i num3 num3=$num1+90 echo $num3
declare -a 将变量定义为数组
定义数组
declare -a array
array=("jones" "make" "kobe" "jordan")
列出数组所有元素
echo ${array[@]}

列出其中指定的一个
echo ${array[1]}

计算数组长度
echo ${#array[@]}

输出数组中元素长度
echo ${#array[0]}

-f 显示此脚本前定义过的所有函数和内容 ,-F 进显示脚本前定义过的函数名
declare -f declare -F
数组常用的方法(仅供参考,实际生产用的少)
array=("jones" "mike" "kobe" "jordan")
输出数组内容:
echo ${array[@]} 输出全部内容
echo ${array[1]} 输出下标索引为1的内容
获取数组长度:
echo ${#array} 数组内元素个数
echo ${#array[2]} 数组内下标索引为2的元素长度
给数组某个下标赋值:
array[0]="lily" 给数组下标索引为1的元素赋值为lily
array[20]="hanmeimei" 在数组尾部添加一个新元素
删除元素:
unset array[2] 清空元素
unset array 清空整个数组
分片访问:
${array[@]:1:4} 显示数组下标索引从1开始到3的3个元素
内容替换:
${array[@]/an/AN} 将数组中所有元素包含an的子串替换为AN
数组遍历:
for v in ${array[@]}
do
echo $v
done
declare -x 将变量声明为环境变量
test1.sh
#!/bin/bash # echo $num5
运行 shtest1.sh

当使用declare -x 变量后,就可以直接在脚本中引用了
num5=30 declare -x num5

到此这篇关于详解shell 变量的高级用法示例的文章就介绍到这了,更多相关shell 变量用法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!