
从零实现Nginx风格内存池完整代码
作者:UrSpecial
1.引言
本文将从为什么需要内存池讲起,重点探讨内存池的设计哲学,并详细拆解其实现方案,从而搭建起读者对内存池从理论到实践的完整认知模型。
2.为什么需要内存池
为什么需要内存池?这个问题可以换一种问法:为什么不直接malloc/free或new/delete?
我们一层一层的回答这个问题。
1.malloc/free有较高的性能开销。 内存的申请不光是给我们一块地址这么简单,malloc底层还要做很多事情,比如分割内存块,合并碎片等。在多线程场景下,malloc内部还会涉及到锁竞争,避免给不同线程返回相同的内存块。这些操作,都需要性能开销。
2.减少系统调用。 申请内存属于系统级操作,所以会涉及到用户态和内核态的切换,也就不可避免的进行CPU的上下文切换。而且,用户态有用户态的栈,内核态有内核态的栈,不能共用,所以也需要切换。这种用户态到内核态的切换,相对于在同一个态里直接调用函数来说,开销更高一些。内存池通过一次申请大块内存,后面再申请内存时直接从这一大块中切出来,减少了系统调用。因此,高性能系统总在想办法减少系统调用次数。
3.减少内存碎片。 普通的malloc/free会产生内存碎片。虽然内存的总容量够,但是就是分配不出来满足需求的连续内存。内存池通过将生命周期一致的对象放一起,比如将一个请求的所有对象放一起,请求结束时将整个池一起释放,不需要单独的free,这就减少了内存碎片。
4.减少锁竞争。 前面也有提到,多个线程同时调用malloc时,底层是会有锁竞争的,但是内存池通常是线程私有的,互不影响,几乎无锁。
3.内存对齐
因为在内存池的实现过程中,涉及到内存对齐,所以这里先介绍一下。
内存对齐本质上是编译器对变量地址存放位置的一个强制约束。
为什么需要内存对齐?
CPU在读取数据的时候,是按地址总线的宽度来读取的。如果数据按一定的对齐值进行了对齐,那么就可以减少CPU额外的读取次数,从而提高CPU访问数据的效率。
如何进行内存对齐?
主要有以下3条规则:
- 按各自的对齐值对齐。
- 整体按最大对齐值对齐。
- 结构体的大小是最大对齐值的整数倍。
进行内存对齐,就一定会有部分内存浪费。所以,内存对齐本质上是一种 空间换时间 的权衡之策。
4.内存池设计的核心思想
因为大对象如果也在内存池中分配的话,很快就会把内存池给沾满。所以,在设计内存池时,对小对象和大对象做了区分。
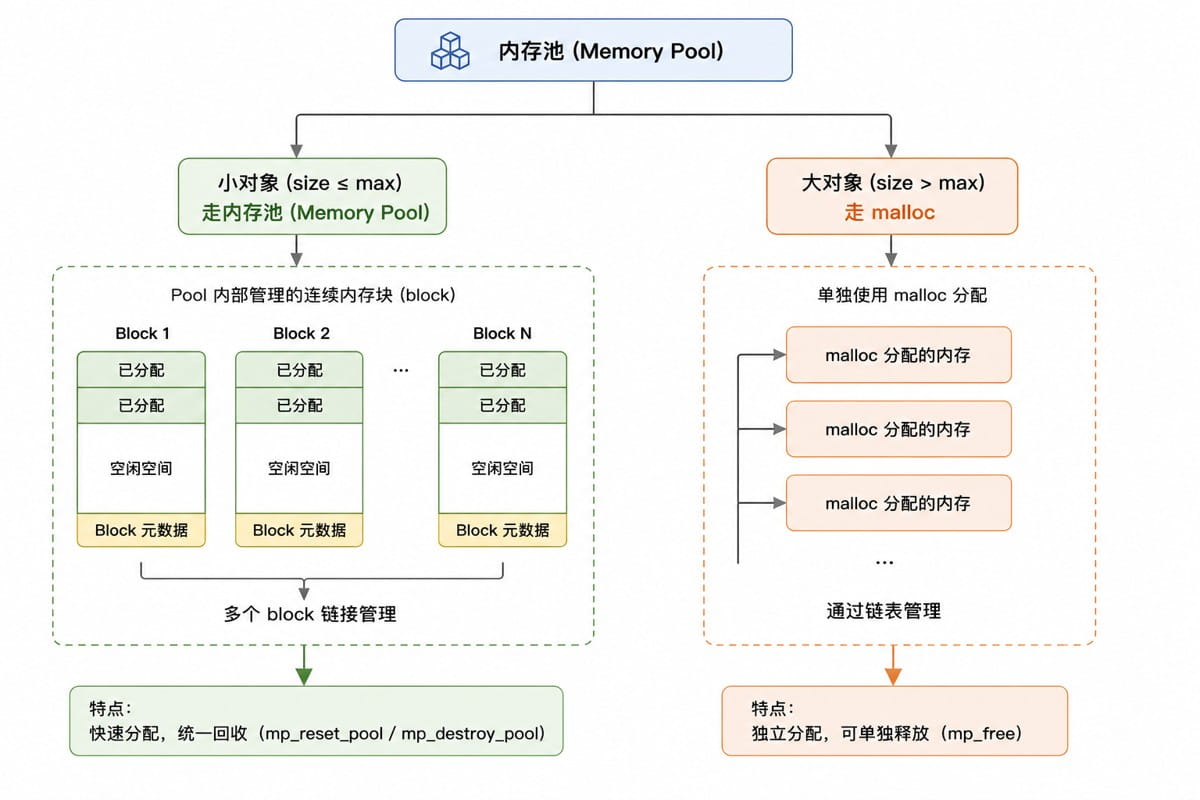
小对象:从内存池中分配内存。
大对象:直接malloc分配内存。
5.代码设计
小对象的节点设计
struct mp_node_s {
unsigned char *last;
unsigned char* end;
struct mp_node_s *next;
size_t failed;
};last: 下一个分配的起始地址。下一次有小对象申请内存时,从last位置开始向后切出来分配内存。
end: 当前节点内存的末尾。
next: 指向下一个节点的指针。
failed: 记录当前节点内存申请失败次数。这个字段主要是用来做优化的,如果该节点的内存申请失败次数达到一定值,我们直接就跳过该节点,不在该节点中申请内存。
大对象的节点设计
struct mp_large_s {
struct mp_large_s *next;
void *alloc;
};next: 指向下一个节点的指针。
alloc: 存放的是malloc函数的返回值,也就是指向的内存块起始地址。
线程池的总体设计
struct mp_pool_s {
size_t max;
struct mp_node_s *current;
struct mp_large_s *large;
struct mp_node_s head[];
};max: 小对象和大对象的分界点,申请的内存大于max的,视为大对象,走的是malloc;申请的内存小于max的,视为小对象,走的是内存池切块。
current: 指向小对象链表中某个节点的指针。current指向哪个节点,下次分配内存时,就首先从该节点尝试分配。
large: 指向下一个大对象节点的指针。
head: 柔性数组,整个小块链表的头节点。
这个结构体,作为整个内存池的入口和管理者。
内存池的创建
struct mp_pool_s *mp_create_pool(size_t size) {
struct mp_pool_s *p;
int ret = posix_memalign((void **)&p, MP_ALIGNMENT,
size + sizeof(struct mp_pool_s) + sizeof(struct mp_node_s));
if (ret != 0) {
printf("[%s:%d]mp_create_pool failed!\n", __func__, __LINE__);
return NULL;
}
p->max = (size < MP_MAX_ALLOC_FROM_POOL) ? size : MP_MAX_ALLOC_FROM_POOL;
p->current = p->head;
p->large = NULL;
// 当前可分配的起点
p->head->last = (unsigned char *)p +
sizeof(struct mp_pool_s) + sizeof(struct mp_node_s);
p->head->end = p->head->last + size;
p->head->failed = 0;
retint posix_memalign(void **memptr, size_t alignment, size_t size)
分配一块地址对齐的内存,相对于malloc来说,多了内存对齐的功能。
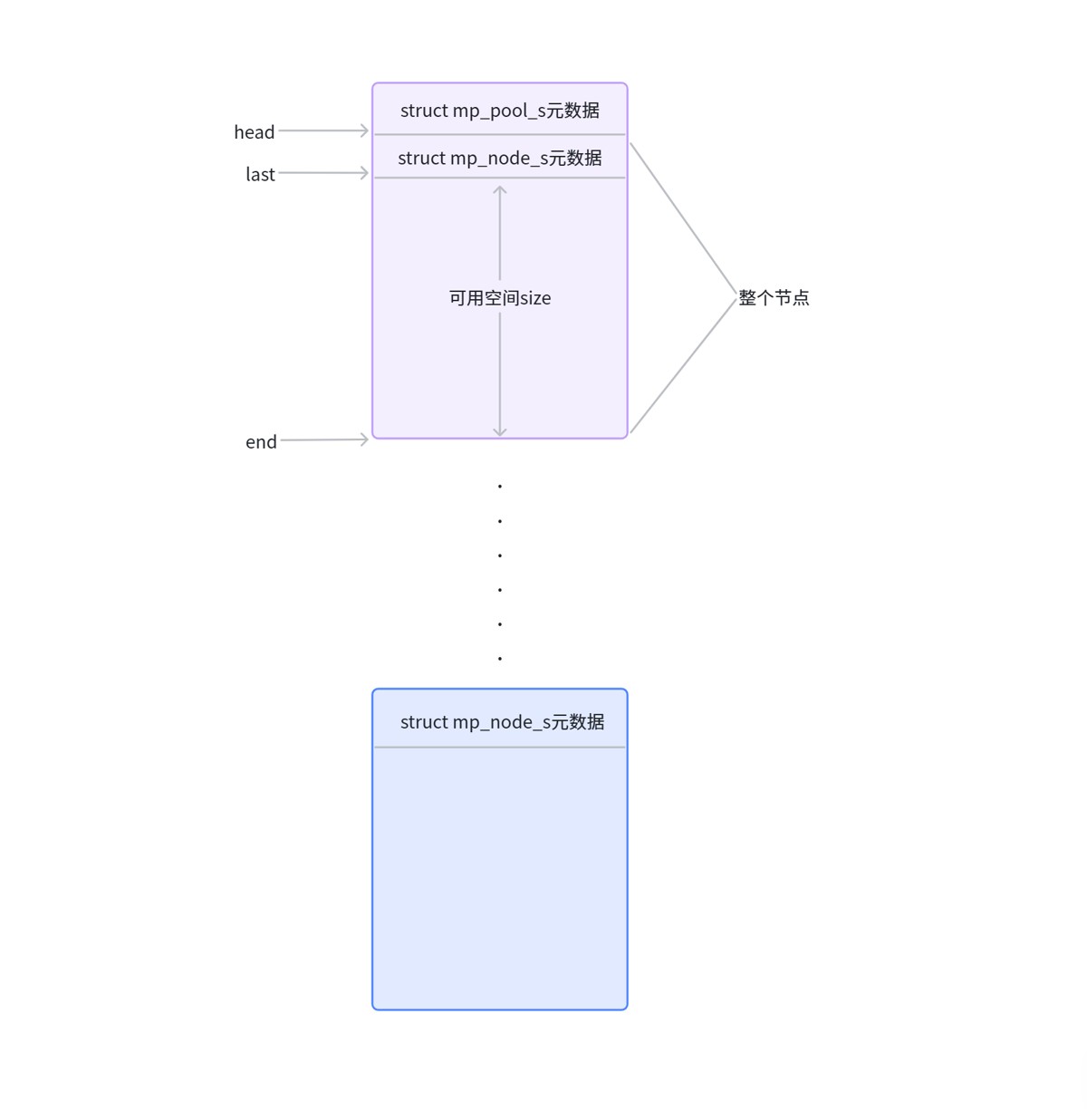
我们除了要分配用户申请的内存大小外,还要给元数据申请内存。而且,每一个mp_node_s节点的大小是一样的,last指针会随着节点中内存的分配情况而移动。
小对象节点的创建
static void *mp_alloc_block(struct mp_pool_s *pool, size_t size) {
unsigned char* m;
struct mp_node_s *h = pool->head;
//所有扩容block大小和初始block保持一致
size_t psize = (size_t)(h->end - (unsigned char *)h);
int ret = posix_memalign((void **)&m, MP_ALIGNMENT, psize);
if (ret != 0) {
printf("[%s:%d]mp_alloc_block failed!\n", __func__, __LINE__);
return NULL;
}
struct mp_node_s *p, *new_node, *current;
new_node = (struct mp_node_s *)m;
new_node->end = m + psize;
new_node->next = NULL;
new_node->failed = 0;
m += sizeof(struct mp_node_s);// 跳过node的元数据
m = mp_align_ptr(m, MP_ALIGNMENT);//因为元数据可能会破坏内存对齐,所以这里需要做一次内存对齐
new_node->last = m + size;
current = pool->current;
// 找链表的尾部,同时更新current字段和failed字段,用于表示失败的次数,以便用作优化
for (p = current; p->next; p = p->next) {
if (p->failed > 4) {
current = p->next;
p->failed++;
}
}
p->next = new_node;
pool->current = current ? current : new_node;
return m;
}创建新节点,意味着从current指向的节点往后的所有节点的剩余可用空间都小于当前用户申请的内存大小。
创建出来的新节点,和前面的节点大小是一样的。
大对象的节点创建
static void *mp_alloc_large(struct mp_pool_s *pool, size_t size) {
void *p = malloc(size);
if (p == NULL) {
printf("[%s:%d]mp_alloc_large failed!\n", __func__, __LINE__);
return NULL;
}
size_t n = 0;
struct mp_large_s *large;
for (large = pool->large; large; large = large->next) {
if (large->alloc == NULL) {
large->alloc = p;
return p;
}
if (n++ >= MP_MAX_LARGE_SCAN) break;
}
// large本身不是malloc出来的,而是在内存池中分配的
large = mp_alloc(pool, sizeof(struct mp_large_s));
if (large == NULL) {
free(p);
printf("[%s:%d]mp_alloc failed!\n", __func__, __LINE__);
return NULL;
}
// 头插
large->alloc = p;
large->next = pool->large;
pool->large = large;
return p;
}对于大对象,直接malloc分配内存。同时,还需要申请节点本身的空间,这里large节点的内存,不是直接malloc来的,而是走小对象内存分配的路,从内存池中切割出来的。对于直接malloc出来的大块内存,用完直接free,不用统一释放。
再强调一遍,mp_large_s结构体,它内部的指针指向malloc出来的大内存,但是这个结构体本身,不是我们直接malloc出来的,而是从内存池中申请得到的。因为mp_alloc函数内部,对于小于一定大小的空间,走的是内存池分配,不是malloc。
空间分配函数
void *mp_alloc(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *p;
if (size <= pool->max) {
p = pool->current;
do {
m = mp_align_ptr(p->last, MP_ALIGNMENT);
if ((size_t)(p->end - m) >= size) {
p->last = m + size;
return m;
}
p->failed++;
p = p->next;
}while (p);
return mp_alloc_block(pool, size);
}
return mp_alloc_large(pool, size);
}
void *mp_nalloc(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *p;
if (size <= pool->max) {
p = pool->current;
do {
m = p->last;
if ((size_t)(p->end - m) >= size) {
p->last = m + size;
return m;
}
p = p->next;
}while(p);
return mp_alloc_block(pool, size);
}
return mp_alloc_large(pool, size);
}外部申请内存的时候,调用的就是这两个函数。总体的逻辑就是:小对象走内存池分配,大对象直接malloc。
这两个函数的区别在哪?有没有内存对齐。
mp_alloc是有内存对齐的,而mp_nalloc没有。
CPU会按固定宽度类型来访问数据的,通常需要内存对齐。按字节流或文本访问数据的,通常可以不对齐。
我们常见的int、long等这些基本类型,通常就需要内存对齐。而字符串就没必要进行内存对齐。
内存池的销毁
void mp_destroy_pool(struct mp_pool_s *pool) {
struct mp_node_s *head = pool->head->next;
struct mp_node_s *next = NULL;
struct mp_large_s *cur = pool->large;
while (cur) {
if (cur->alloc) free(cur->alloc);
cur = cur->next;
}
while (head) {
next = head->next;
free(head);
head = next;
}
free(pool);
}如果有大对象的内存没有释放,那么这里会一并释放,最后在释放这个内存池。
6.内存池完整代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#define MP_ALIGNMENT 32
#define MP_PAGE_SIZE 4096
#define MP_MAX_LARGE_SCAN 4
#define MP_MAX_ALLOC_FROM_POOL (MP_PAGE_SIZE-1)
#define mp_align_ptr(p, alignment) \
(void *)((((size_t)p)+(alignment-1)) & ~(alignment-1))
struct mp_large_s {
struct mp_large_s *next;
void *alloc;
};
struct mp_node_s {
unsigned char *last;
unsigned char* end;
struct mp_node_s *next;
size_t failed;
};
struct mp_pool_s {
size_t max;//内存池允许的小块分配上限
struct mp_node_s *current;
struct mp_large_s *large;
struct mp_node_s head[];
};
void *mp_alloc(struct mp_pool_s *pool, size_t size);
struct mp_pool_s *mp_create_pool(size_t size) {
struct mp_pool_s *p;
int ret = posix_memalign((void **)&p, MP_ALIGNMENT,
size + sizeof(struct mp_pool_s) + sizeof(struct mp_node_s));
if (ret != 0) {
printf("[%s:%d]mp_create_pool failed!\n", __func__, __LINE__);
return NULL;
}
p->max = (size < MP_MAX_ALLOC_FROM_POOL) ? size : MP_MAX_ALLOC_FROM_POOL;
p->current = p->head;
p->large = NULL;
// 当前可分配的起点
p->head->last = (unsigned char *)p +
sizeof(struct mp_pool_s) + sizeof(struct mp_node_s);
p->head->end = p->head->last + size;
p->head->failed = 0;
return p;
}
void mp_destroy_pool(struct mp_pool_s *pool) {
struct mp_node_s *head = pool->head->next;
struct mp_node_s *next = NULL;
struct mp_large_s *cur = pool->large;
while (cur) {
if (cur->alloc) free(cur->alloc);
cur = cur->next;
}
while (head) {
next = head->next;
free(head);
head = next;
}
free(pool);
}
void mp_reset_pool(struct mp_pool_s *pool) {
struct mp_large_s *cur = pool->large;
struct mp_node_s *head = pool->head;
while (cur) {
free(cur->alloc);
cur = cur->next;
}
pool->large = NULL;
while (head) {
head->last = mp_align_ptr((unsigned char *)
head + sizeof(struct mp_node_s), MP_ALIGNMENT);
head->failed = 0;
head = head->next;
}
pool->current = pool->head;
}
static void *mp_alloc_block(struct mp_pool_s *pool, size_t size) {
unsigned char* m;
struct mp_node_s *h = pool->head;
//所有扩容block大小和初始block保持一致
size_t psize = (size_t)(h->end - (unsigned char *)h);
int ret = posix_memalign((void **)&m, MP_ALIGNMENT, psize);
if (ret != 0) {
printf("[%s:%d]mp_alloc_block failed!\n", __func__, __LINE__);
return NULL;
}
struct mp_node_s *p, *new_node, *current;
new_node = (struct mp_node_s *)m;
new_node->end = m + psize;
new_node->next = NULL;
new_node->failed = 0;
m += sizeof(struct mp_node_s);// 跳过node的元数据
m = mp_align_ptr(m, MP_ALIGNMENT);//因为元数据可能会破坏内存对齐,所以这里需要做一次内存对齐
new_node->last = m + size;
current = pool->current;
// 找链表的尾部,同时更新current字段和failed字段,用于表示失败的次数,以便用作优化
for (p = current; p->next; p = p->next) {
if (p->failed > 4) {
current = p->next;
p->failed++;
}
}
p->next = new_node;
pool->current = current ? current : new_node;
return m;
}
static void *mp_alloc_large(struct mp_pool_s *pool, size_t size) {
void *p = malloc(size);
if (p == NULL) {
printf("[%s:%d]mp_alloc_large failed!\n", __func__, __LINE__);
return NULL;
}
size_t n = 0;
struct mp_large_s *large;
for (large = pool->large; large; large = large->next) {
if (large->alloc == NULL) {
large->alloc = p;
return p;
}
if (n++ >= MP_MAX_LARGE_SCAN) break;
}
// large节点不是malloc出来的,而是在small pool分配的
large = mp_alloc(pool, sizeof(struct mp_large_s));
if (large == NULL) {
free(p);
printf("[%s:%d]mp_alloc failed!\n", __func__, __LINE__);
return NULL;
}
// 头插
large->alloc = p;
large->next = pool->large;
pool->large = large;
return p;
}
void *mp_memalign(struct mp_pool_s *pool, size_t size, size_t alignment) {
void *p;
int ret = posix_memalign(&p, alignment, size);
if (ret != 0) {
printf("[%s:%d]mp_memalign failed!\n", __func__, __LINE__);
return NULL;
}
struct mp_large_s *large = mp_alloc(pool, size);
if (large == NULL) {
free(p);
printf("[%s:%d]mp_memalign failed!\n", __func__, __LINE__);
return NULL;
}
large->alloc = p;
large->next = pool->large;
pool->large = large;
return p;
}
/**
* brief:带内存对齐的空间分配函数
*/
void *mp_alloc(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *p;
if (size <= pool->max) {
p = pool->current;
do {
m = mp_align_ptr(p->last, MP_ALIGNMENT);
if ((size_t)(p->end - m) >= size) {
p->last = m + size;
return m;
}
p = p->next;
}while (p);
return mp_alloc_block(pool, size);
}
return mp_alloc_large(pool, size);
}
/**
* brief:不带内存对齐的空间分配函数,因为不是所有场景下都需要内存对齐
*/
void *mp_nalloc(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *p;
if (size <= pool->max) {
p = pool->current;
do {
m = p->last;
if ((size_t)(p->end - m) >= size) {
p->last = m + size;
return m;
}
p = p->next;
}while(p);
return mp_alloc_block(pool, size);
}
return mp_alloc_large(pool, size);
}
void *mp_calloc(struct mp_pool_s *pool, size_t size) {
void *p = mp_alloc(pool, size);
if (p) memset(p, 0, size);
return p;
}
void mp_free(struct mp_pool_s *pool, void *p) {
struct mp_large_s *cur;
for (cur = pool->large; cur; cur = cur->next) {
if (p == cur->alloc) {
free(cur->alloc);
cur->alloc = NULL;
return;
}
}
}
int main() {
int size = 1 << 12;
struct mp_pool_s *pool = mp_create_pool(size);
for (int i = 0; i < 10; i++) {
void *mp = mp_alloc(pool, 512);
}
for (int i = 0; i < 5; i++) {
void *mp = mp_alloc(pool, 5120);
mp_free(pool, mp);
}
mp_reset_pool(pool);
for (int i = 0; i < 50; i++) {
void *mp = mp_alloc(pool, 512);
}
mp_destroy_pool(pool);
return 0;
}7.整体结构图
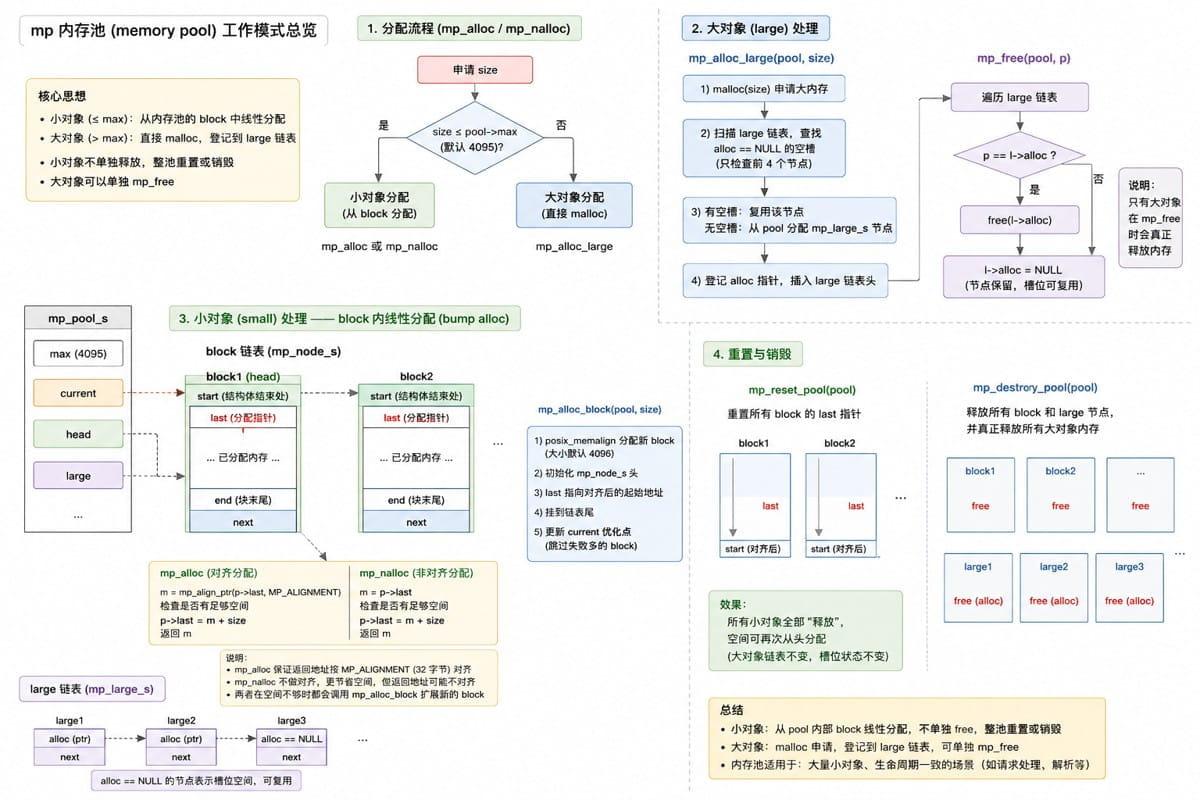
8.结语
到此这篇关于从零实现Nginx风格内存池的文章就介绍到这了,更多相关Nginx内存池内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!