
linux内核双向链表详解
作者:大肥周
介绍下linux内核的双向链表的使用,接口定义在include/linux/list.h
结构体
struct list_head {
struct list_head *next; // 指向下一个节点
struct list_head *prev; // 指向前一个节点
};使用的时候,会把这个结构体放在需要使用链表的结构体里,放在结构体里的任意位置都可以,读取数据的时候,是从链表里拿到node后,通过container_of拿到node所在结构体的地址,根据这个地址再来找结构体里的其他成员。
所以,同一个链表里,是根据node把存放的内容关联串起来,再根据node拿到内容的,而不关心这些node所在的内容的结构体是不是同一个结构体。
struct zslnode {
int seq;
struct list_head node;
};
struct zslnode1 {
int seq;
struct list_head node1;
int seq1;
};初始化
初始化有多种方式,常见的有LIST_HEAD_INIT和INIT_LIST_HEAD
作用是常见一个struct list_head变量,把里面的next和prev都指向自己。
增加
常用的增加分为两种接口,往前增加list_add,往后增加list_add_tail。这俩接口都是调用的__list_add实现的,往前增加是__list_add(new, head, head->next),往后是__list_add(new, head->prev, head)。
__list_add主要就是如下操作:
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);所以,增加节点其实就是在原来链表的的head->prev、head和head->next三个之间去增加。
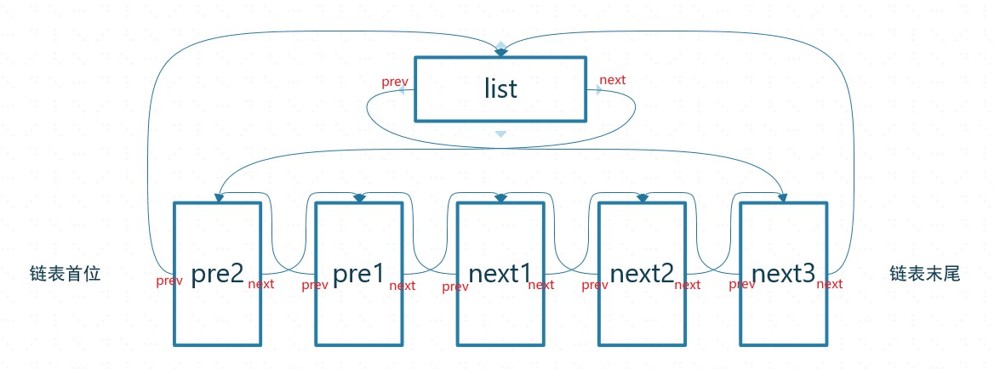
head本身不存在链表上(即在head上去存数据遍历的时候是取不到的),像是把双向链表的首尾连接起来的节点,head->next永远指向链表第一个节点,head->prev指向最后一个节点。
这样就容易理解__list_add里的赋值操作,去掉prev和next之间的联系,然后把new增加到prev和next中间。
往前增加参数里prev是head,即首尾相连的点,next是head->next即链表第一位,new增加到中间就变成了链表第一位。
往后增加prev是链表最后一位,next是首尾相连的点,new增加到中间就变成了链表最后一位。
删除
删除常用的是list_del,最终调用的是__list_del,主要操作如下:
next->prev = prev;
WRITE_ONCE(prev->next, next);即,后面一个节点的prev指向前面一个节点,前面一个节点的next指向后面。
遍历
遍历常用的是list_for_each_entry正向遍历,list_for_each_entry_reverse反向遍历,也还有不少别的变种,基本差不多。
list_for_each_entry定义如下
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
!list_entry_is_head(pos, head, member); \
pos = list_next_entry(pos, member))找到第一个节点,然后一路next查找。第一个节点,前面有提到就是head->next,再通过list_entry拿结构体地址,list_entry就是使用的container_of。
反向遍历就是反过来,查找最后一个节点,即head->prev,然后一路prev往前查找node。
直到遍历到list_entry_is_head停止,即发现自己就是head,&pos->member == (head),这里&pos->member就是存储的结构体里指向node的地址。
实例
struct zslnode {
int seq;
struct list_head node;
};
struct zslnode1 {
int seq1;
struct list_head node1;
int seq2;
};
static void testlist(void)
{
struct list_head list;
struct zslnode next1;
struct zslnode next2;
struct zslnode1 next3;
struct zslnode pre1;
struct zslnode pre2;
struct zslnode *tmpnode;
struct zslnode1 *tmpnode1;
INIT_LIST_HEAD(&list);
next1.seq = 101;
list_add_tail(&next1.node, &list);
next2.seq = 102;
list_add_tail(&next2.node, &list);
next3.seq1 = 1000;
next3.seq2 = 2000;
list_add_tail(&next3.node1, &list);
pre1.seq = 99;
list_add(&pre1.node, &list);
pre2.seq = 98;
list_add(&pre2.node, &list);
list_for_each_entry(tmpnode, &list, node)
{
printk(KERN_INFO "tlist: seq:%d\n",tmpnode->seq);
}
list_del(&next2.node);
list_for_each_entry(tmpnode1, &list, node1)
{
printk(KERN_INFO "tlist1: seq:%d %d\n",tmpnode1->seq1,tmpnode1->seq2);
}
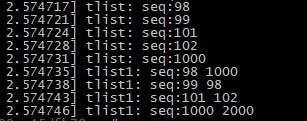
}运行结果如下
注意事项
- 从扫描的逻辑来看,head的节点是不能被扫描到的,虽然只有head存在的话,能拿到数据(那是因为head->next=head)。
- 从实例运行结果tlist1的打印可以看到不同的结构体可以放在一起处理,但是会出现内存越界的情况,读到不可控的内容。
- List的内容存放,都是用指针存放的,所以如果链表是全局变量的话,里面的节点也必须是全局或者静态变量,不能是栈里的内容,不然会有指针踩飞导致崩溃等问题。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。