
如何部署Alertmanager发送告警
作者:Aspire to freedom
这篇文章主要介绍了如何部署Alertmanager发送告警问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教
1、Alertmanager简介
Prometheus 对指标的收集、存储与告警能力分属于 Prometheus Server 和 AlertManager 两个独立的组件,前者仅负责定义告警规则生成告警通知, 具体的告警操作则由后者完成。
Alertmanager 负责处理由 Prometheus Server 发来的告警通知,Alertmanager对告警通知进行分组、去重后,根据路由规则将其路由到不同的receiver,如Email、钉钉或企业微信等。
除了基本的告警通知能力外,Altermanager还支持对告警进行去重、分组、抑制、静默和路由等功能:
- 分组(Grouping):将相似告警合并为单个告警通知的机制,在系统因大面积故障而触发告警潮时,分组机制能避免用户被大量的告警噪声淹没,进而导致关键信息的隐没
- 抑制(Inhibition):系统中某个组件或服务故障而触发告警通知后,那些依赖于该组件或服务的其它组件或服务可能也会因此而触发告警,抑制便是避免类似的级联告警的一种特性,从而让用户能将精力集中于真正的故障所在
- 静默(Silent):是指在一个特定的时间窗口内,即便接收到告警通知,Alertmanager也不会真正向用户发送告警信息的行为;通常,在系统例行维护期间,需要激活告警系统的静默特性
- 路由(route):用于配置Alertmanager如何处理传入的特定类型的告警通知,其基本逻辑是根据路由匹配规则的匹配结果来确定处理当前告警通知的路径和行为
2、部署使用Alertmanage
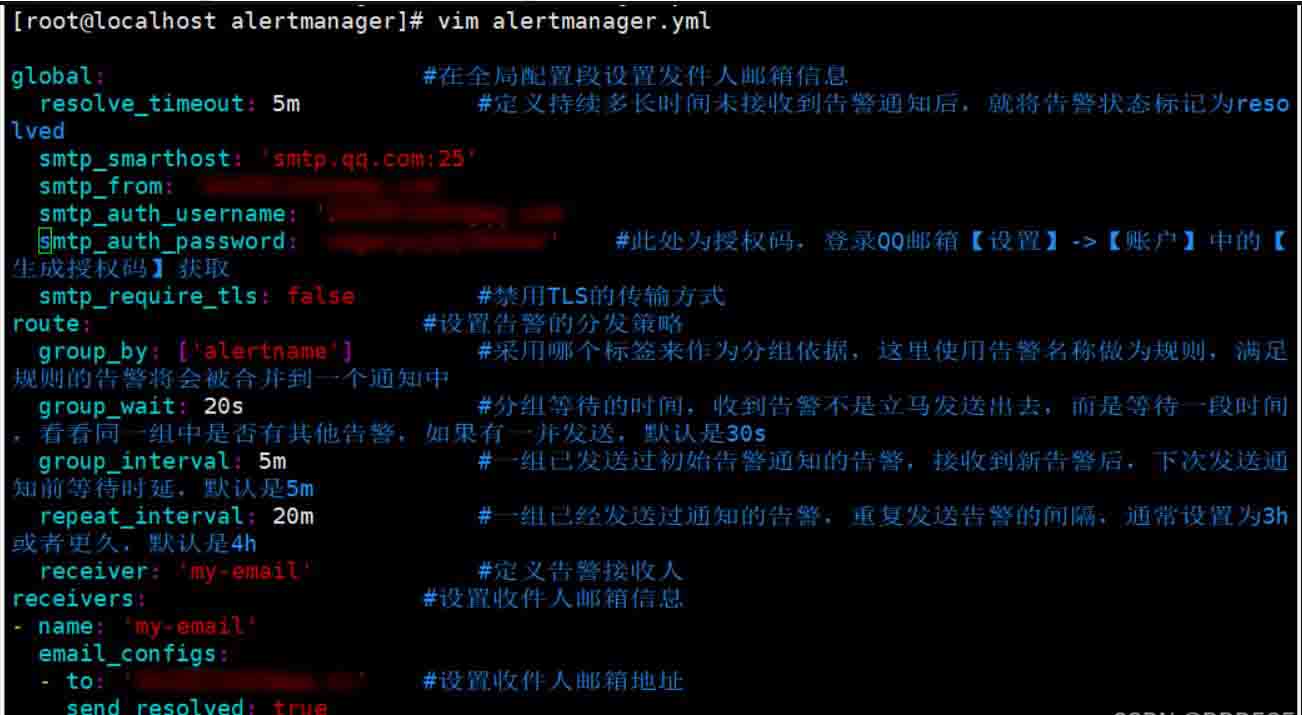
cd /opt 上传alertmanager-0.24.0.linux-amd64.tar.gz tar xf alertmanager-0.24.0.linux-amd64.tar.gz mv alertmanager-0.24.0.linux-amd64 /usr/local/alertmanager cd /usr/local/alertmanager cp alertmanager.yml alertmanager.yml.bak vim alertmanager.yml
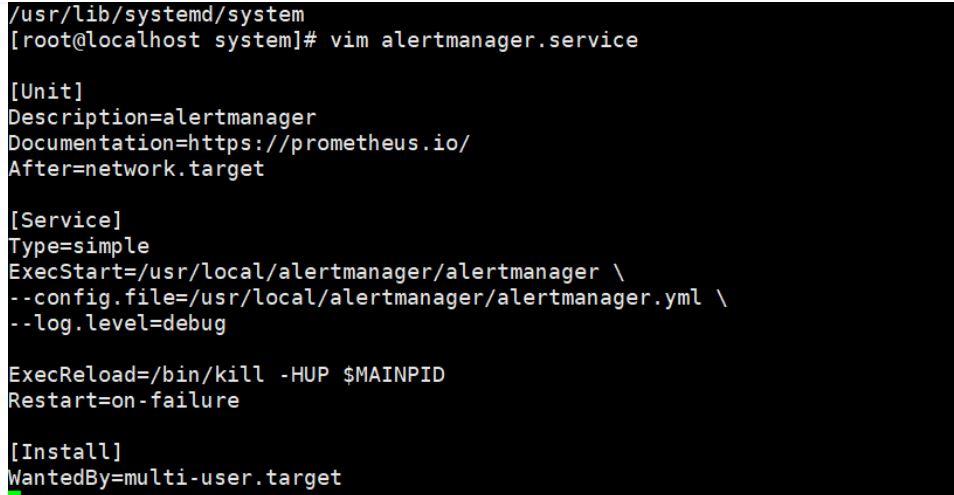
配置启动文件 cd /usr/lib/systemd/system [Unit] Description=alertmanager Documentation=https://prometheus.io/ After=network.target [Service] Type=simple ExecStart=/usr/local/alertmanager/alertmanager \ --config.file=/usr/local/alertmanager/alertmanager.yml \ --log.level=debug ExecReload=/bin/kill -HUP $MAINPID Restart=on-failure [Install] WantedBy=multi-user.target systemctl start alertmanager.service systemctl enable alertmanager.service netstat -lntp | grep alert

cd /usr/local/prometheus/
mkdir alert_rules
cd alert_rules/
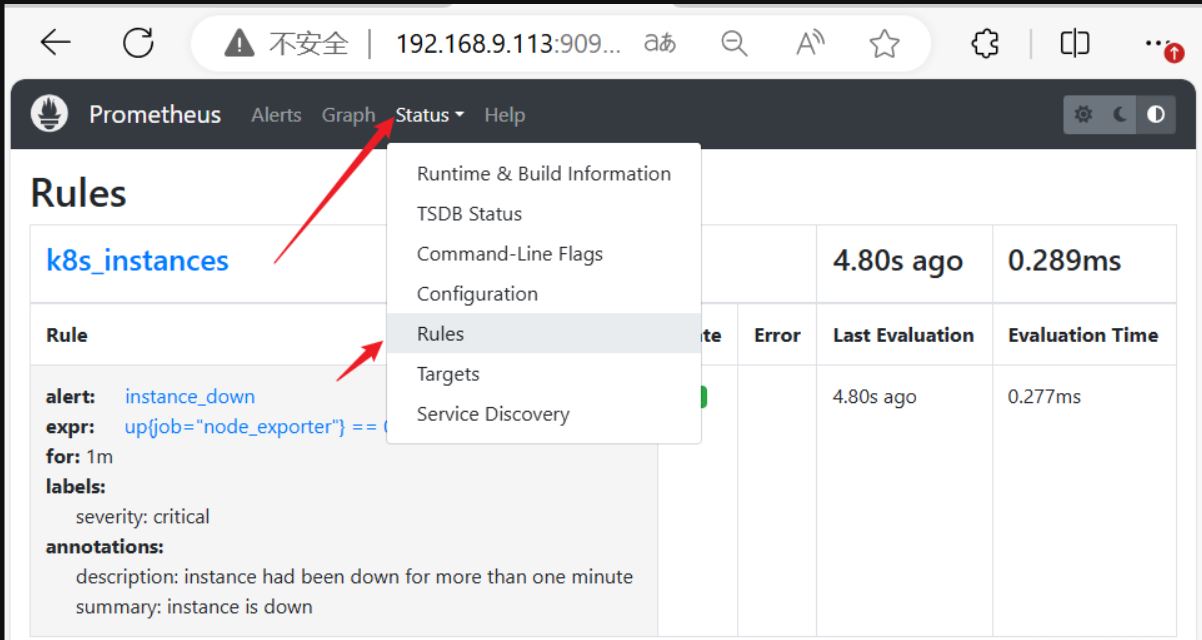
vim node_alert.yaml
groups:
- name: k8s_instances
rules:
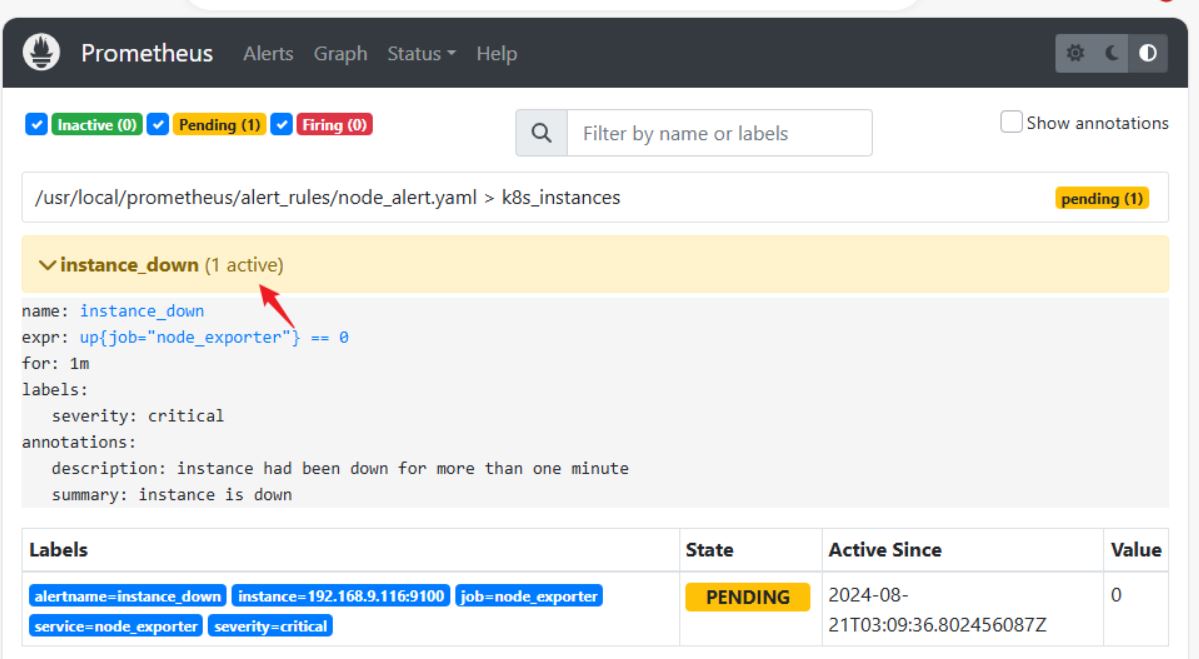
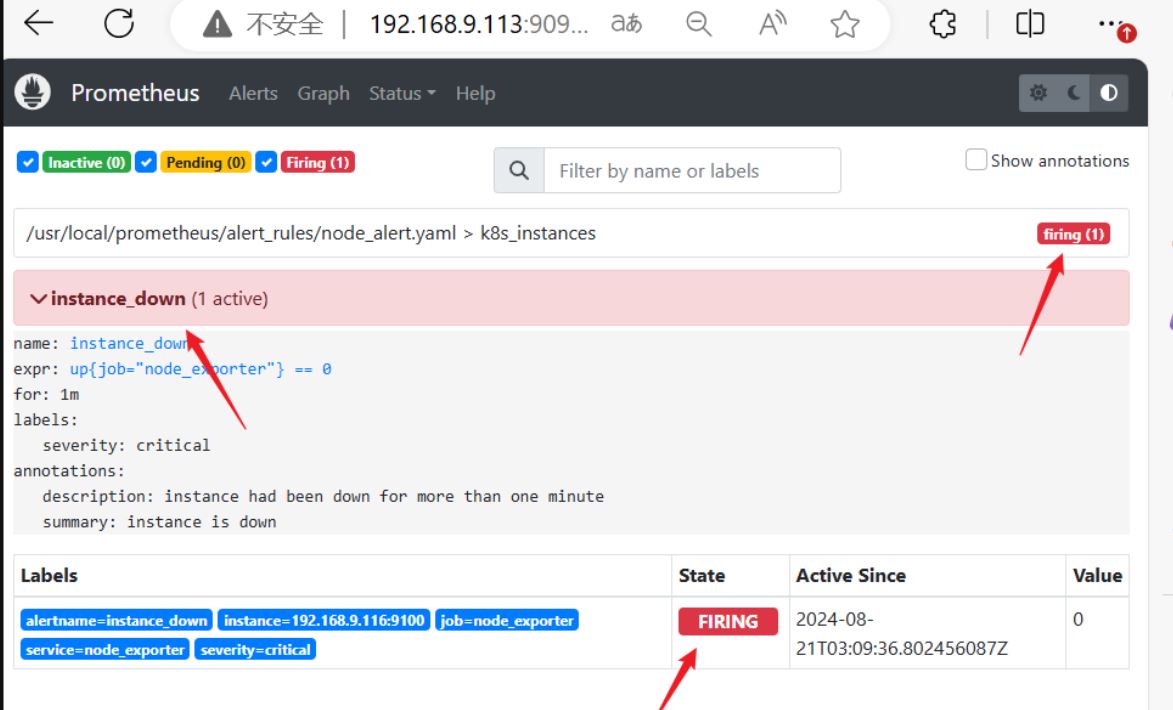
- alert: instance_down
expr: up{job="node_exporter"} == 0
for: 1m
labels:
severity: "critical"
annotations:
summary: "instance is down"
description: "instance had been down for more than one minute"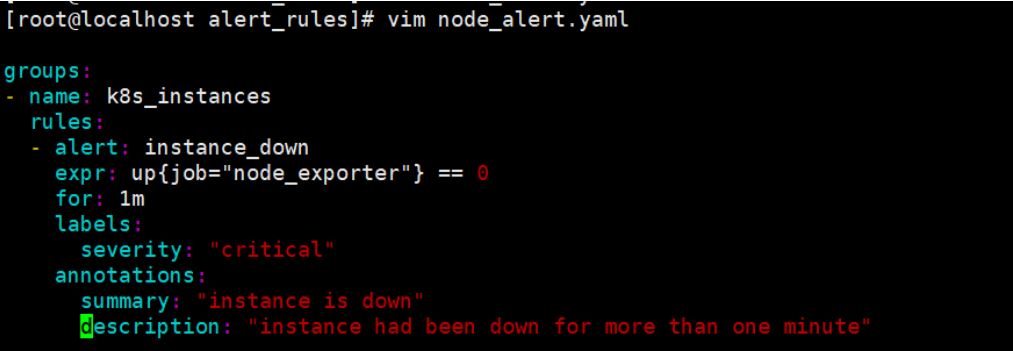
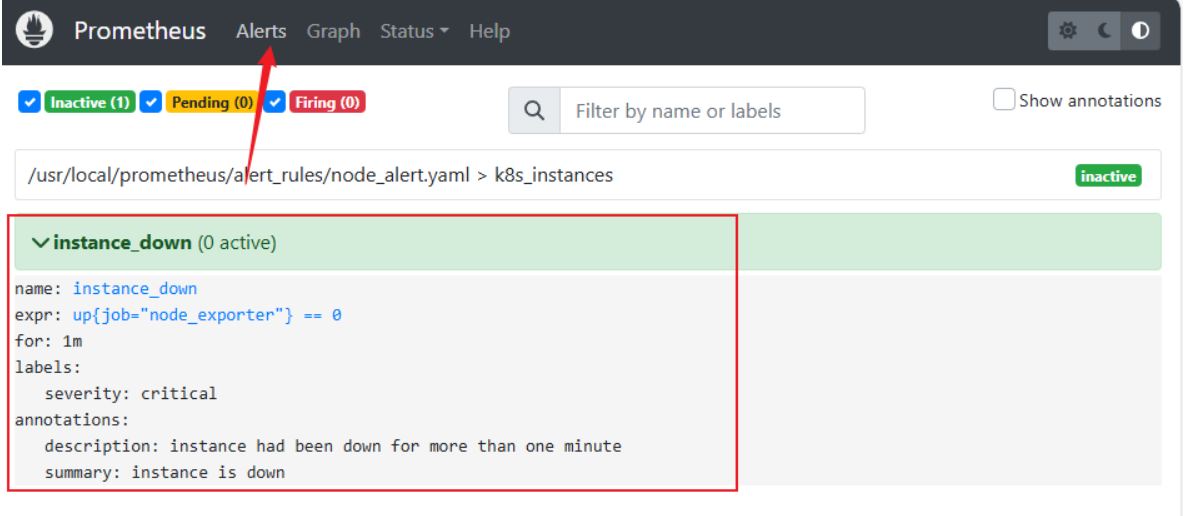
cd /usr/local/prometheus/ vim prometheus.yml 13行#- 192.168.9.113:9093 17行#- "alert_rules/*.yaml" systemctl restart prometheus.service
systemctl stop node_exporter.service #暂停服务验证
邮箱查看是否收到告警邮件
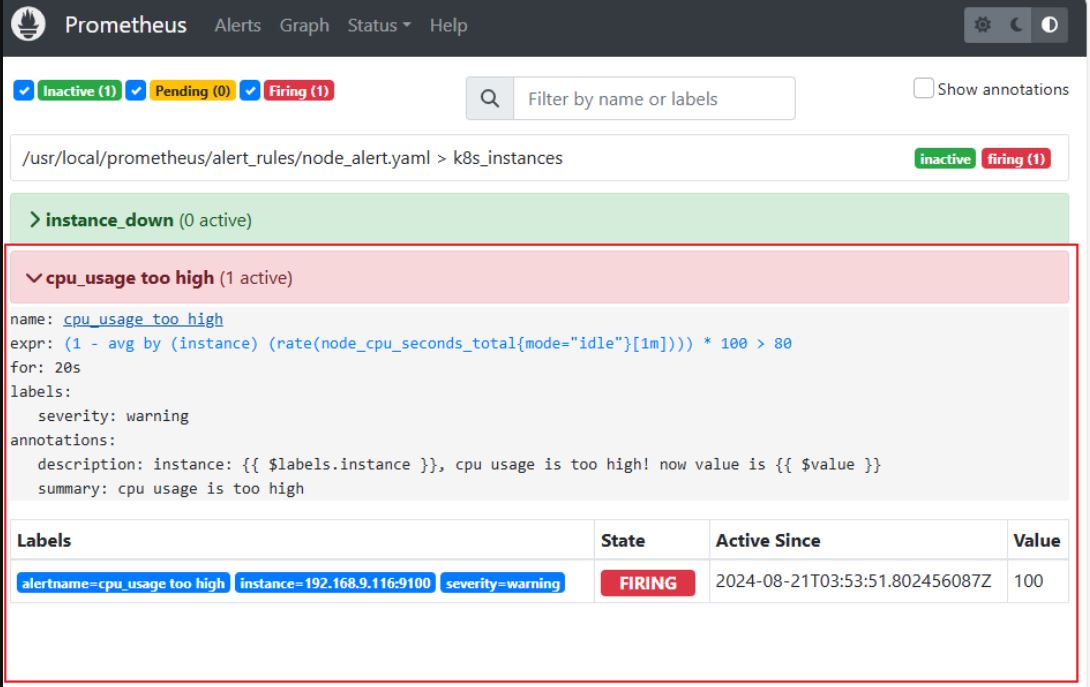
vim node_alert.yaml #设置cpu使用报警
- alert: "cpu_usage too high"
expr: (1 -avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)) * 100 > 80
for: 20s
labels:
severity: "warning"
annotations:
summary: "cpu usage is too high"
description: "instance: {{ $labels.instance }}, cpu usage is too high! now value is {{ $value }}"
cd ..
systemctl restart prometheus.service #重启服务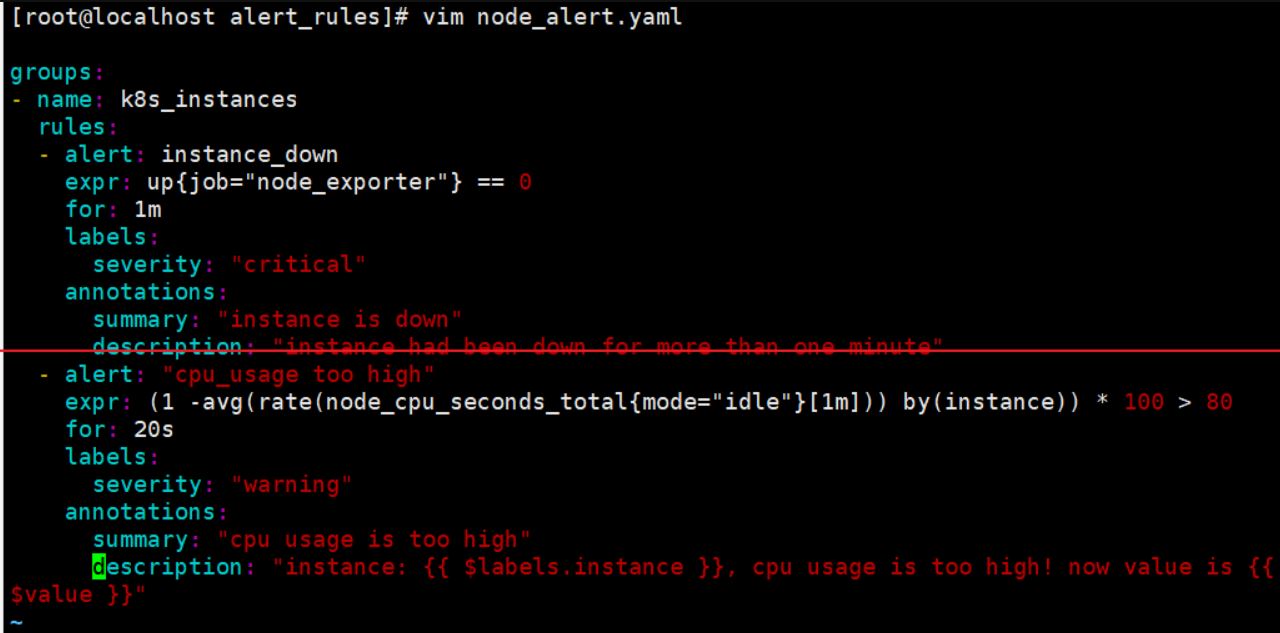
rpm -ivh stress-1.0.4-16.el7.x86_64.rpm stress -c 2 #对cpu进行压测
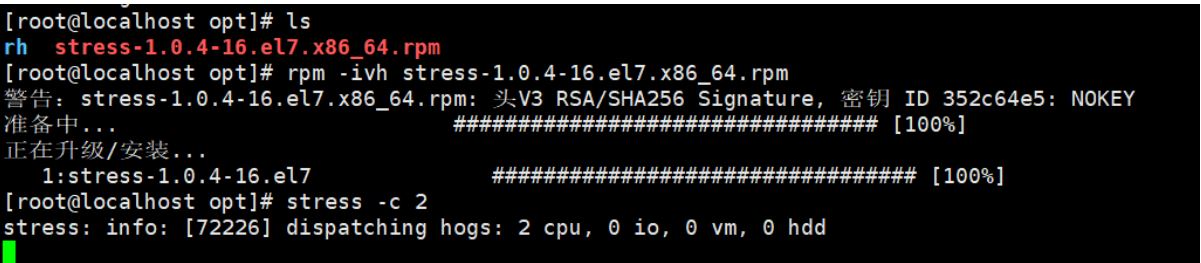
浏览器查看、邮件查看是否有报警提示
3、设置钉钉关联报报警
钉钉报警
创建群聊——群聊设置——机器人——添加机器人——自定义——添加——选择加签(复制密钥)——完成(保存webhook地址)
上传prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz tar xf prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz mv prometheus-webhook-dingtalk-2.1.0.linux-amd64 /usr/local/dingtalk cd !$ cp config.example.yml config.yml vim config.yml 取消2、8、9、13、14、15注释 注释23-39行 20行替换为保存的webhook地址 22行替换为保存的加签 ./prometheus-webhook-dingtalk
cd /usr/local/alertmanager/
vim alertmanager.yml
末尾添加
- name: 'dingtalk.webhook1'
webhook_configs:
- url: 'http://192.168.9.113:8060/dingtalk/webhook1/send'
send_resolved: true
13行修改 receiver: 'dingtalk.webhook1'
systemctl reload alertmanager.service 即可进行测试,查看钉钉报警邮件
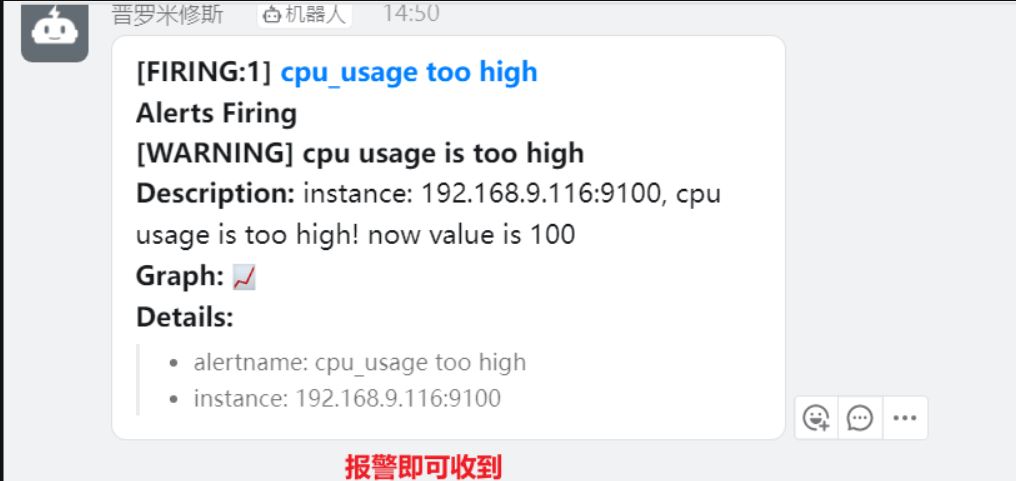
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。