
Kubernetes核心组件实战解析之API Server与Scheduler的生产级应用指南
作者:Leo-Yide
在Kubernetes集群中,kube-apiserver和kube-scheduler如同机场的塔台控制系统,一个负责全局通信调度,一个专注资源分配优化。本文将深入解析这两个核心组件在生产环境中的关键作用与实战配置。
一、kube-apiserver:集群的中枢神经系统
1. 核心功能全景
集群统一网关所有操作入口(kubectl/Dashboard/Operator)的唯一接入点,类似机场塔台的通信总台
安全防护体系

数据中枢桥梁通过etcd实现集群状态的持久化存储,处理速度直接影响集群性能
2. 生产级配置要点
高可用架构
# 典型三节点部署 kube-apiserver \ --etcd-servers=https://etcd1:2379,https://etcd2:2379,https://etcd3:2379 \ --secure-port=6443 \ --audit-log-path=/var/log/kubernetes/audit.log \ --enable-admission-plugins=PodSecurity,ResourceQuota
关键参数调优
| 参数 | 作用说明 | 生产建议值 |
|---|---|---|
| --max-requests-inflight | 并发请求限制 | 1500-3000 |
| --watch-cache-size | Watch缓存大小 | 按节点数量动态调整 |
| --event-ttl | 事件保留时间 | 168h(7天) |
审计日志实战
apiVersion: audit.k8s.io/v1
kind: Policy
rules:
- level: Metadata
resources:
- group: "" # 核心API组
resources: ["secrets"]3. 故障排查手册
API响应延迟高
检查etcd集群性能:
etcdctl endpoint status分析审计日志量级
调整--target-ram-mb参数限制内存使用
证书过期处理
# 查看证书有效期 openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -dates # 证书续期操作 kubeadm alpha certs renew apiserver
二、kube-scheduler:智能资源分配大师
1. 调度流程深度解析
三阶段决策模型
预选(Filter):淘汰不符合硬性条件的节点
- 资源是否充足(CPU/Memory)
- 是否满足NodeSelector
- 污点容忍匹配
优选(Score):为候选节点打分(0-10分)
- 资源平衡算法(如LeastRequestedPriority)
- 亲和性策略(PodAffinityPriority)
绑定(Bind):将Pod与最优节点绑定
// 调度器核心逻辑伪代码
func schedulePod(pod *v1.Pod) {
feasibleNodes := filterNodes(pod)
scoredNodes := prioritizeNodes(pod, feasibleNodes)
bindToBestNode(pod, scoredNodes[0])
}2. 生产调度策略配置
多维度调度策略示例
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
plugins:
preScore:
enabled:
- name: InterPodAffinity
score:
enabled:
- name: NodeResourcesBalancedAllocation
weight: 2
- name: NodeAffinity
weight: 1自定义调度器实战
- 实现调度器扩展器
- 部署多调度器实例
Pod指定调度器:
spec: schedulerName: my-custom-scheduler
3. 高级调度场景
GPU资源调度
kind: Pod
spec:
containers:
- name: gpu-container
resources:
limits:
nvidia.com/gpu: 2拓扑分布约束
topologySpreadConstraints: - maxSkew: 1 topologyKey: zone whenUnsatisfiable: DoNotSchedule
三、生产环境联调优化
1. 组件协同工作机制
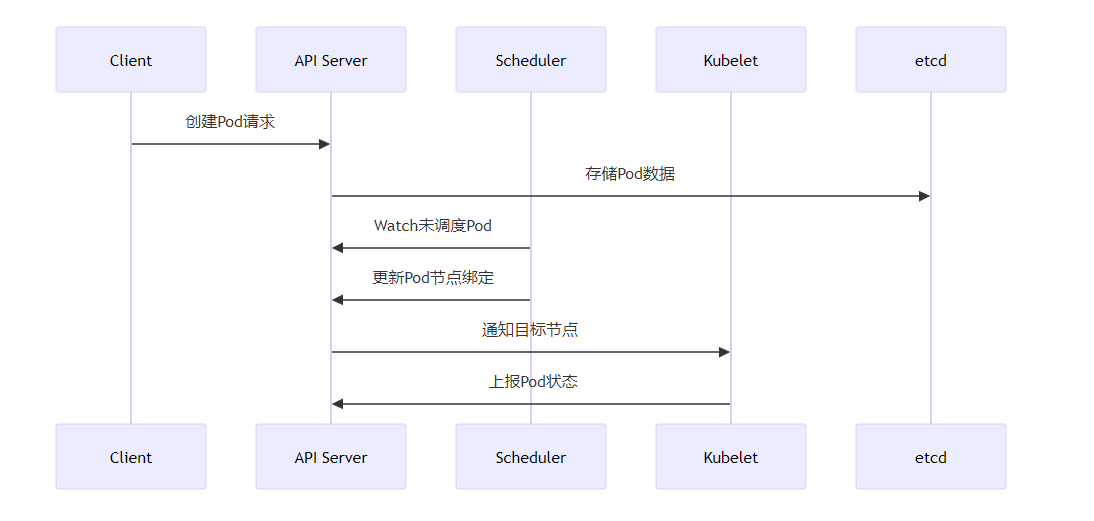
2. 性能优化方案
API Server优化
- 启用API优先级与公平性(APF)
- 配置高效的序列化器(protobuf)
Scheduler优化
- 设置百分比节点采样(--percentage-of-nodes-to-score)
- 启用调度框架并行处理
3. 监控指标体系
API Server关键指标
apiserver_request_total:请求吞吐量apiserver_request_duration_seconds:响应延迟etcd_request_duration_seconds:存储层延迟
Scheduler关键指标
scheduler_pending_pods:待调度Pod数scheduler_scheduling_attempts:调度尝试次数scheduler_framework_extension_point_duration_seconds:各阶段耗时
四、故障场景应急手册
1. API Server故障
现象:kubectl命令超时
处理流程:
- 检查负载均衡器健康状态
- 查看节点kubelet日志:
journalctl -u kubelet - 验证etcd集群可用性
2. 调度器异常
现象:Pod长期Pending
诊断命令:
kubectl describe pod <pod-name> | grep Events kubectl get events --field-selector involvedObject.name=<pod-name>
3. 配置错误回滚
# 查看历史配置 kubectl rollout history deployment/kube-apiserver # 回滚到上一版本 kubectl rollout undo deployment/kube-apiserver
五、演进方向与最佳实践
Serverless架构影响
- 虚拟节点调度(如AWS EKS on Fargate)
- 弹性调度策略优化
混合调度方案
- 批量任务调度(Volcano整合)
- 实时任务调度优化
AI驱动的调度
- 基于机器学习的资源预测
- 动态调度策略调整
生产经验分享:某AI计算平台通过自定义调度插件,将GPU任务调度耗时降低40%。关键措施:
实现节点GPU碎片整理算法
优化设备预热机制
引入亲和性权重动态计算
作为Kubernetes集群的"大脑"和"调度中心",API Server与Scheduler的稳定运行需要从架构设计、参数调优到日常监控的全方位保障。建议每季度进行一次调度压力测试,并建立组件级的故障切换演练机制。
到此这篇关于Kubernetes核心组件实战解析之API Server与Scheduler的生产级应用指南的文章就介绍到这了,更多相关API Server与Scheduler作用内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!