
如何使用 Docker 部署 Spark 集群
作者:库库林_沙琪马
Apache Spark 是一个统一的分析引擎,用于大规模数据处理。使用 Docker 部署 Spark 集群是一种简便且高效的方式。本文将详细介绍如何通过 Docker Compose 部署一个 Spark 集群,包括一个 Master 节点和多个 Worker 节点。
环境要求
在开始部署之前,请确保以下环境已准备就绪:
- Docker Engine:安装并运行 Docker。
- Docker Compose:安装 Docker Compose,用于定义和运行多容器应用。
- 网络环境:确保主机可以连接到 Docker Hub 以下载镜像。
Docker Compose 配置文件
以下是用于部署 Spark 集群的 docker-compose.yml 文件:
version: '3'
services:
master:
image: bitnami/spark:3.5.4
container_name: master
user: root
environment:
- SPARK_MODE=master
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
- SPARK_MASTER_WEBUI_PORT=8080
- SPARK_MASTER_PORT=7077
ports:
- '8080:8080'
- '7077:7077'
volumes:
- ./python:/python
worker1:
image: bitnami/spark:3.5.4
container_name: worker1
user: root
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://master:7077
- SPARK_WORKER_MEMORY=1G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
depends_on:
- master
worker2:
image: bitnami/spark:3.5.4
container_name: worker2
user: root
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://master:7077
- SPARK_WORKER_MEMORY=1G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
depends_on:
- master
networks:
default:
driver: bridge配置详解
Master 节点配置
- 镜像:使用
bitnami/spark:3.5.4镜像。 - 容器名称:指定容器名称为
master。 - 用户:以
root用户运行容器。 - 环境变量:
SPARK_MODE=master:指定节点模式为 Master。SPARK_MASTER_WEBUI_PORT=8080:设置 Web UI 访问端口。SPARK_MASTER_PORT=7077:设置 Spark Master 通信端口。
- 端口映射:
8080:8080:映射 Web UI 端口。7077:7077:映射 Spark Master 端口。
- 卷挂载:将主机的
./python目录挂载到容器的/python目录。
Worker 节点配置
- 镜像:同样使用
bitnami/spark:3.5.4镜像。 - 容器名称:分别指定为
worker1和worker2。 - 用户:以
root用户运行容器。 - 环境变量:
SPARK_MODE=worker:指定节点模式为 Worker。SPARK_MASTER_URL=spark://master:7077:指定 Master 节点的 URL。SPARK_WORKER_MEMORY=1G:配置 Worker 节点的内存。SPARK_WORKER_CORES=1:配置 Worker 节点的 CPU 核数。
- 依赖:指定 Worker 节点依赖 Master 节点,确保 Master 节点先启动。
网络配置
- 使用桥接网络,将所有容器连接到同一个网络中,以便它们可以互相通信。
部署 Spark 集群
步骤 1:创建 Docker Compose 文件
将上述配置内容保存为 docker-compose.yml 文件。
步骤 2:构建并启动容器
在终端中,进入包含 docker-compose.yml 文件的目录,并运行以下命令:
docker compose up -d
up:构建并启动容器。-d:后台运行。
步骤 3:验证集群状态
启动容器后,可以通过以下方式验证集群状态:
查看容器状态:
docker compose ps
预期输出:

访问 Spark Web UI:
打开浏览器,访问 http://{你的虚拟机Ip}:8080,即可看到 Spark Master 的 Web UI,显示所有 Worker 节点的连接状态。
验证 Worker 节点连接:
在 Web UI 中,导航到 http://{你的虚拟机Ip}:8080,检查 "Workers" 标签页,应显示 worker1 和 worker2 已连接。
步骤 4:运行 Spark 作业
为了验证 Spark 集群的功能,可以运行一个简单的 Spark 作业。以下是一个示例:
方法一:在 Master 容器内部运行 Spark 作业
进入 Master 容器
docker compose exec master bash
运行 Spark PI 示例:
/opt/bitnami/spark/bin/spark-shell --master spark://master:7077 或者 $SPARK_HOME/bin/spark-shell --master spark://master:7077
在 Spark Shell 中运行以下代码:
val numSamples = 100000000
val count = sc.parallelize(1 to numSamples).count()
println(s"Pi is roughly ${count * 4.0 / numSamples}")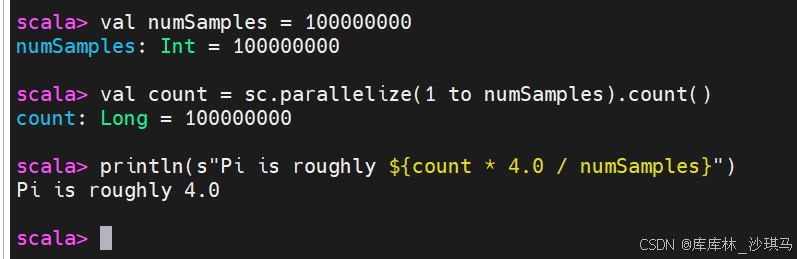
方法二:通过 Python 提交 Spark 作业
假设你有一个 Python 脚本 pi.py,内容如下:
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.appName("Pi Calculator").getOrCreate()
numSamples = 100000000
count = spark.sparkContext.parallelize(range(1, numSamples)).count()
print(f"Pi is roughly {4.0 * count / numSamples}")
spark.stop() 将 pi.py 放在 ./python 目录下,然后提交作业:
docker-compose exec master /opt/bitnami/spark/bin/spark-submit --master spark://master:7077 /python/pi.py
运行结果:
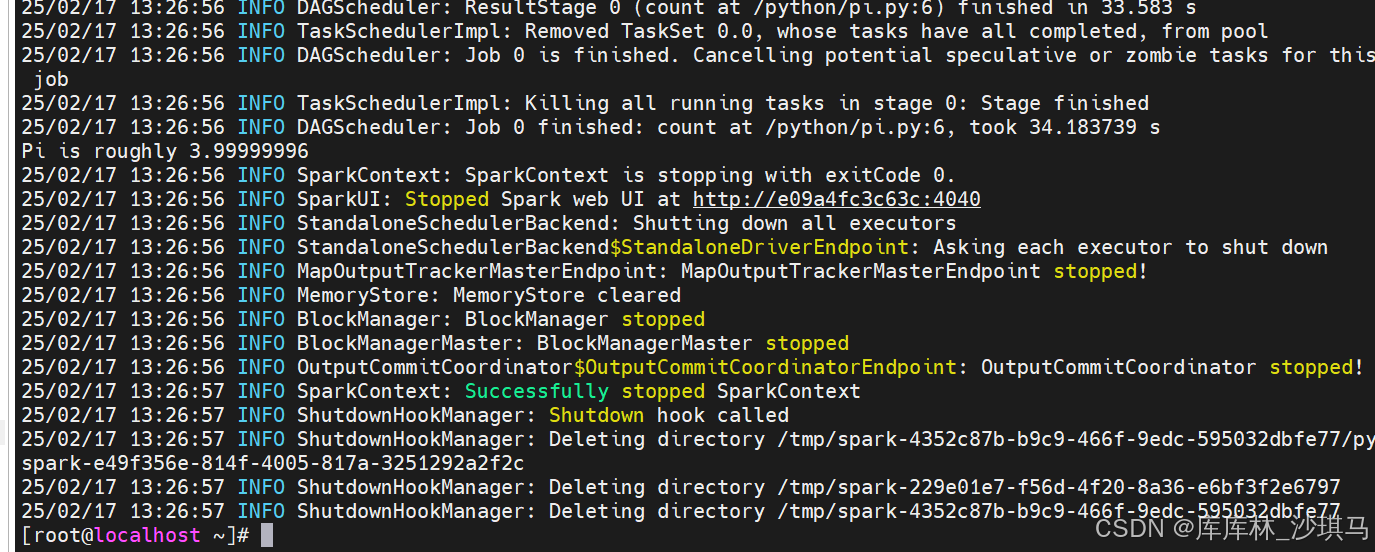
步骤 5:停止和清理(注意,这个不是让你测试的,看清楚)
完成测试后,可以停止并删除容器:
docker compose down
总结
通过以上步骤,你已经成功使用 Docker 部署了一个 Spark 集群,包括一个 Master 节点和两个 Worker 节点。这种部署方式具有以下优势:
- 快速部署:通过 Docker Compose 一键式部署,无需手动配置每个节点。
- 资源隔离:每个节点运行在独立的容器中,资源分配清晰。
- 易于扩展:可以轻松添加或删除 Worker 节点以适应不同的工作负载。
- 环境一致性:所有节点使用相同的 Spark 镜像,确保环境一致。
你可以根据需要调整 docker-compose.yml 文件中的配置,例如增加 Worker 节点的数量、调整内存和 CPU 核数等。希望这篇文章能帮助你快速上手 Spark 集群的 Docker 部署!
到此这篇关于如何使用 Docker 部署 Spark 集群的文章就介绍到这了,更多相关Docker 部署 Spark 集群内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!