
Python自动化批量排序Excel所有工作表的完整指南
作者:杨利杰YJlio
1. 问题背景:为什么要批量排序整个工作簿?
在日常办公里,Excel 排序本身并不复杂。打开一个工作表,选中字段,点击“升序”,几秒钟就能完成。但问题是:如果一个工作簿里有几十个工作表,每个工作表都要按同一列排序,这件事就会从“简单操作”变成“重复劳动”。
这篇文章核心目标是:使用 Python 批量对一个工作簿中的所有工作表按指定字段进行升序排序,并将结果写回 Excel。
从技术上看,这不是单纯学一个 sort_values() 函数,而是把 Excel 手工动作翻译成一套可重复执行的自动化流程。
这张图展示了本文的核心主题:一个 Excel 工作簿中存在多个工作表,Python 负责统一遍历并按“销售利润”字段执行升序排序。

从这张图中我们可以看出,本文处理的对象不是单张表,而是一个工作簿中的所有工作表。这也是批量自动化和普通 Excel 操作最大的区别:前者关注流程复用,后者只是完成一次点击。
2. 适用场景与限制条件
这个案例适合用于结构比较统一的 Excel 文件,例如销售统计表、部门月报、区域数据表、设备台账、绩效明细表等。只要多个工作表的表头结构基本一致,并且存在同一个可排序字段,就可以考虑用这种方式批量处理。
2.1 适用场景
比较典型的场景包括:
- 一个工作簿内包含多个月份工作表,例如
1月、2月、3月 - 一个工作簿内包含多个部门工作表,例如
IT部、财务部、采购部 - 每个工作表都有同名字段,例如
销售利润 - 需要把所有工作表都按同一个字段升序或降序排列
- 希望处理后直接保存为新文件,避免手动逐表操作
2.2 限制条件
不是所有 Excel 都适合直接套用这段脚本。如果工作表格式混乱,存在大量合并单元格、空行、空列、跨区域表格,或者每个工作表字段名称不一致,脚本就容易读取不全或排序失败。
推荐做法是先用测试文件验证脚本,再处理真实业务数据。尤其是批量写回 Excel 的操作,必须先保留原始文件副本,不能上来就覆盖生产数据。
3. 核心原理:把手工排序翻译成程序流程
我们手工处理 Excel 时,大概会做这些动作:打开工作簿,切换到第一个工作表,选中字段,点击升序,保存,再切换到下一个工作表继续重复。
Python 自动化的本质,就是把这些动作拆成可编程步骤:
这里的关键判断是:Excel 负责承载文件和工作表,pandas 负责数据排序,xlwings 负责把 Python 和 Excel 连接起来。
这张图展示了批量处理的主流程:打开、遍历、读取、排序、写回、保存关闭。
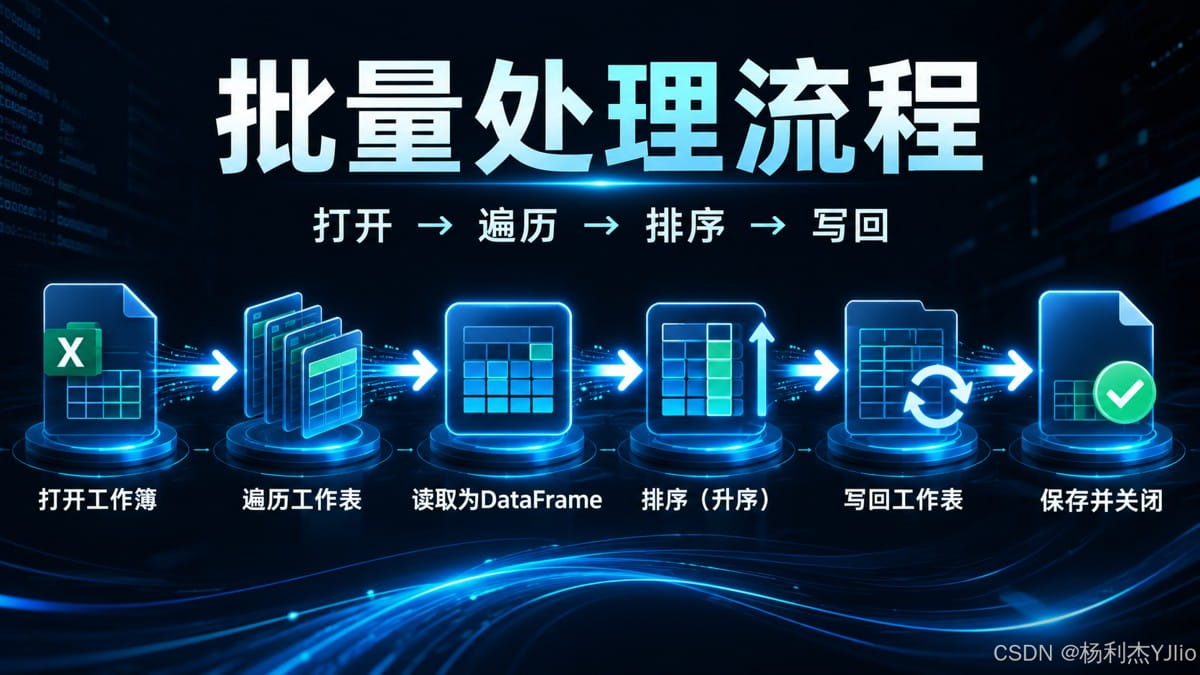
从这张图中我们可以看出,批量排序不是一句代码解决全部问题,而是多个环节连续配合。真正稳定的脚本,必须考虑打开文件、遍历对象、处理数据、写回结果、释放资源这几个动作是否完整闭环。
4. 核心代码实现:pandas 负责排序,xlwings 负责写回
这类自动化脚本最容易写成“能跑但不稳”的版本。为了更贴近日常办公场景,我更建议写成带校验、带跳过逻辑、带日志输出的版本。这样即使某个工作表为空、缺少排序字段,也不会让整个脚本直接崩掉。
这张图展示了代码实现层面的核心分工:pandas 处理 DataFrame 排序,xlwings 负责打开工作簿、定位工作表并写回结果。
从这张图中我们可以看出,sort_values() 是排序动作的核心,但它不是整个脚本的全部。Excel 自动化还要考虑工作簿打开、工作表遍历、结果写回和资源释放。
4.1 安装依赖
本案例主要依赖两个库:
pip install pandas xlwings
其中,pandas 负责表格数据处理,xlwings 负责调用本机 Excel 应用。
注意:xlwings 通常依赖本机安装 Microsoft Excel。如果是在没有 Office 的服务器环境中运行,需要重新评估方案。
4.2 推荐代码版本
import pandas as pd
import xlwings as xw
def to_number_series(s: pd.Series) -> pd.Series:
"""
将可能带有货币符号、逗号、空格的字段转换为数值。
无法转换的数据会变成 NaN。
"""
if s.dtype == "O":
s = s.astype(str).str.strip()
s = s.str.replace(",", "", regex=False)
s = s.str.replace(" ", "", regex=False)
s = s.str.replace(r"[¥¥$]", "", regex=True)
s = s.str.replace(r"[^0-9\.\-]", "", regex=True)
return pd.to_numeric(s, errors="coerce")
def sort_all_sheets_in_workbook(
input_xlsx: str,
sort_by: str = "销售利润",
output_xlsx: str | None = None,
ascending: bool = True,
start_cell: str = "A1",
) -> None:
"""
批量对一个工作簿中的所有工作表按指定列排序。
参数说明:
input_xlsx:输入 Excel 文件路径
sort_by:排序字段名称
output_xlsx:输出文件路径,None 表示覆盖原文件
ascending:True 表示升序,False 表示降序
start_cell:表格左上角起始单元格
"""
app = xw.App(visible=False, add_book=False)
app.display_alerts = False
app.screen_updating = False
try:
wb = app.books.open(input_xlsx)
ok_count = 0
skip_count = 0
for sht in wb.sheets:
rng = sht.range(start_cell).expand("table")
if rng.value is None:
print(f"[SKIP] {sht.name}: 空表")
skip_count += 1
continue
df = rng.options(pd.DataFrame).value
if df is None or df.empty:
print(f"[SKIP] {sht.name}: 无有效数据")
skip_count += 1
continue
if sort_by not in df.columns:
print(f"[SKIP] {sht.name}: 缺少字段 {sort_by}")
skip_count += 1
continue
df[sort_by] = to_number_series(df[sort_by])
df_sorted = df.sort_values(
by=sort_by,
ascending=ascending,
na_position="last"
)
sht.range(start_cell).value = df_sorted
ok_count += 1
print(f"[OK] {sht.name}: 已按 {sort_by} 排序")
if output_xlsx:
wb.save(output_xlsx)
print(f"[DONE] 已另存为:{output_xlsx}")
else:
wb.save()
print(f"[DONE] 已覆盖保存:{input_xlsx}")
wb.close()
finally:
app.quit()
if __name__ == "__main__":
sort_all_sheets_in_workbook(
input_xlsx="产品销售统计表.xlsx",
sort_by="销售利润",
output_xlsx="产品销售统计表_已排序.xlsx",
ascending=True,
start_cell="A1",
)
我更推荐使用“另存为新文件”的方式,例如输出为 产品销售统计表_已排序.xlsx。这样即使结果不符合预期,也不会破坏原始数据。
5. 关键避坑:先转数值,再排序
这个案例最容易被忽略的问题,不是语法,而是数据类型。很多 Excel 文件里看着像数字的内容,读进 pandas 后可能变成字符串。例如:
"9"
"100"
"¥12,345"
"$7,890.00"
如果直接按字符串排序,就可能出现 100 排在 9 前面的情况。因为字符串比较不是按数值大小,而是按字符顺序。
这张图展示了排序前必须做的数据清洗:把带货币符号、逗号、空格的字符串转换成真正的数值,再执行排序。

从这张图中我们可以看出,排序前的数据清洗比排序动作本身更关键。如果字段类型不对,脚本可能不会报错,但排序结果会悄悄出错,这比直接报错更危险。
5.1 为什么要使用pd.to_numeric()
pd.to_numeric() 可以把清洗后的字符串转换成数值。对于无法转换的内容,通过 errors="coerce" 让它变成 NaN,后续再通过 na_position="last" 放到末尾。
这样做的好处是:异常值不会阻断脚本执行,同时也不会混在正常排序结果中间。
5.2 为什么空值放到最后
排序字段如果存在空值、文本、异常符号,转换后会形成空值。放到最后更符合人工检查习惯,因为异常数据集中沉底,后续排查更方便。
不要为了让脚本“看起来成功”,就忽略这些异常数据。办公自动化最怕的是:脚本运行成功,但业务结果是错的。
6. 效果验证:看排序前后是否真的变化
脚本执行完成后,不能只看控制台有没有输出 [DONE]。真正的验证应该回到 Excel 文件本身,检查每个工作表中的目标字段是否已经按预期升序排列。
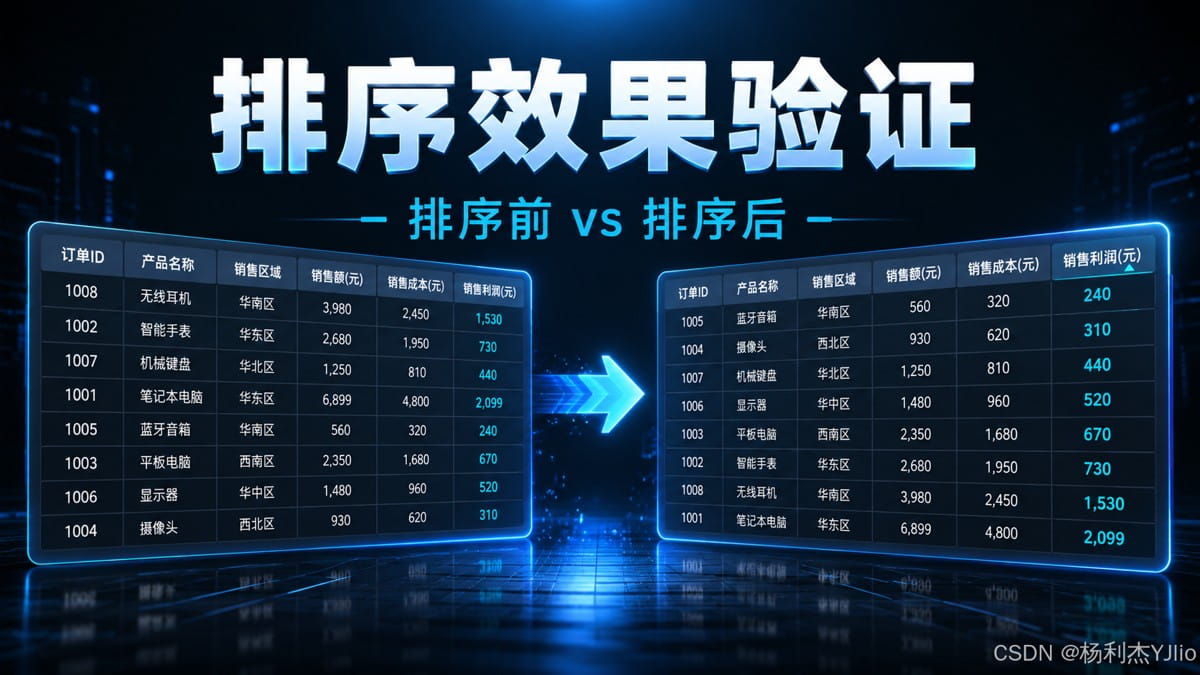
这张图展示了排序前后的对比:左侧是未排序状态,右侧是按“销售利润”升序排序后的状态。

从这张图中我们可以看出,验证重点不是“文件能打开”,而是排序字段是否从小到大排列,且同一行的其他字段是否仍然跟随该行数据一起移动。如果只排序了一列,而其他列没有同步移动,那就是严重数据错位。
6.1 建议的验证方法
我建议至少做三层验证:
- 打开输出文件,确认文件能正常打开
- 随机抽查 2~3 个工作表,确认
销售利润已升序排列 - 检查排序后每一行的订单 ID、产品名称、销售区域是否仍然对应正确
如果是重要数据,建议先抽样比对,再决定是否批量覆盖原文件。
7. 常见问题与踩坑记录
7.1 报错:找不到文件
如果提示文件不存在,优先检查路径。Windows 路径建议使用原始字符串:
input_xlsx = r"C:\Temp\产品销售统计表.xlsx"
前面的 r 是为了避免反斜杠被识别成转义字符,例如 \t、\n。
7.2 报错:文件被占用
如果 Excel 文件正被手动打开,脚本保存时可能失败。处理方法很简单:关闭对应 Excel 文件,或者把结果另存到新路径。
批量处理前必须确认目标文件没有被其他人打开,尤其是在共享盘或协同目录中。
7.3 某些工作表跳过了
如果控制台提示某个工作表缺少字段,说明该工作表中没有找到指定列名。例如脚本按 销售利润 排序,但某张表写成了 利润、销售利润(元) 或者表头有多余空格。
推荐先统一表头,再批量处理。自动化不是用来掩盖数据不规范的,而是放大规范数据的处理效率。
7.4 合并单元格导致读取错位
合并单元格是 Excel 自动化里的高频问题。它对人工阅读友好,但对程序读取并不友好。批量处理前,建议尽量使用标准二维表结构:第一行是字段名,下面每一行是一条完整记录。
8. 总结提升:Excel 的排序是动作,Python 的排序是流程
这一节最重要的收获,不是记住某一行代码,而是理解一种办公自动化思路:把重复性的 Excel 手工动作,拆成可以批量执行的程序流程。
在这个案例里,Excel 手工排序只是一个动作;Python 脚本则把它扩展成了完整流程:
- 打开工作簿
- 遍历所有工作表
- 读取表格数据
- 清洗排序字段
- 按指定字段升序排序
- 写回工作表
- 保存并关闭文件
pandas 的优势在于数据处理,xlwings 的优势在于连接 Excel,两者配合起来,才是这个案例真正的价值。
我的建议是:凡是涉及批量写回 Excel 的脚本,都优先采用“原文件不动,另存结果文件”的策略。等确认结果无误后,再考虑覆盖原始文件。
不要把“脚本能跑通”当成最终目标。真正可靠的自动化,必须能解释处理逻辑、能验证结果、能控制风险。
以上就是 Python自动化批量排序Excel所有工作表的完整指南的详细内容,更多关于 Python排序Excel工作表的资料请关注脚本之家其它相关文章!