
Python批量统计Excel工作簿的最大值和最小值
作者:杨利杰YJlio
1. 问题背景:表太多,手工统计最大值和最小值很容易出错
这一篇继续整理《超简单:用 Python 让 Excel 飞起来》第6章中的案例内容,主题是:批量统计工作簿的最大值和最小值。这个案例看起来不复杂,因为 Excel 里本来就有 MAX() 和 MIN() 函数。但真正放到办公场景里,问题就不是“会不会用函数”,而是“能不能批量、稳定、可追溯地统计”。
很多实际表格并不是一张表解决问题,而是一个工作簿里有多张工作表。比如按月份分成 1月、2月、3月,或者按区域分成华北、华东、华南,每张表的字段结构相似,但数据行数不同。现在如果要统计某一列的最大值和最小值,手工做法通常是:打开每张表,写公式,复制结果,再新建汇总表。
这种做法最大的问题不是慢,而是不可靠。表一多,最容易出现复制漏表、公式区域选错、结果没有追溯来源等问题。尤其是领导问一句“最大值是哪张表里的哪条记录”,如果前面只算了一个数字,后面还要重新翻表找数据。
本篇文章的目标很明确:用 Python 自动完成多个工作表的极值统计,最终得到 每张工作表的最大值、最小值,以及全工作簿范围内的全局最大值和全局最小值。
开篇先看整体效果。本图把本节主题压缩成一个核心动作:用 Python + Excel 自动化,一次性处理多个工作表中的最大值和最小值。

从画面里可以看出,本节重点不是单独统计一张表,而是面对多个 Sheet 时,把重复统计动作交给脚本完成。真正有价值的结果也不只是“最大值是多少”,而是形成一套可重复执行的批量统计流程。
如果你的工作里经常处理销售表、库存表、利润表、成本表、绩效表、资产台账,这类脚本就很有复用价值。
2. 目标效果:不是只算数字,而是输出可追溯结果
这类任务如果只是算出一个最大值、一个最小值,其实价值有限。因为真实办公场景里,数字只是结果,后面还要能回答三个问题:
第一,这个最大值来自哪张工作表?
第二,这个最大值在第几行?
第三,这条记录对应的产品、订单、部门或人员是谁?
所以我更建议把目标效果设计成三层:
| 输出层级 | 输出内容 | 实际价值 |
|---|---|---|
| 单表统计 | 每张工作表的最大值、最小值 | 快速知道每张表的极值情况 |
| 行级定位 | 极值所在行索引、关键字段 | 能回到原始记录,不只是看数字 |
| 汇总输出 | 生成“极值汇总”工作表 | 打开文件就能看到最终结论 |
也就是说,极值统计不是一个公式问题,而是一个“结果可追溯”的数据处理问题。
如果只用 Excel 公式,也能算出极值;但要批量遍历多个工作表、自动清洗数字、定位行号、生成汇总表,Python 会更合适。
3. 实现思路:读取、清洗、统计、定位、汇总
这一节的底层逻辑可以拆成一条流水线。先打开工作簿,再遍历所有工作表,读取目标数据列,清洗成数值类型,然后计算最大值和最小值。最后再把每张表的统计结果汇总到新工作表里。
这里最关键的判断是:不要默认 Excel 单元格里看起来像数字,就一定能被 Python 当成数字处理。真实表格里经常会出现逗号、货币符号、空格、中文单位、空值等情况。如果不先清洗,max() 和 min() 的结果可能不可靠,甚至直接报错。
这一张流程图非常适合放在实现思路部分。它把“极值统计”拆成了从读取到输出的完整链路,而不是只停留在 max() 和 min() 两个函数上。

从流程里可以看出,真正的自动化不是简单执行一行公式,而是把每一步都固定下来:读取工作簿、清洗数据、计算极值、定位行记录、生成汇总结果。这样脚本才能在不同工作簿里重复使用。
这也是写办公自动化脚本时最重要的习惯:不要只写“能跑”的代码,要写“能复用、能验证、能解释”的代码。
4. 完整代码:批量统计最大值和最小值
下面这版代码使用 pandas 负责数据统计,使用 xlwings 负责打开工作簿、写回结果和保存文件。它不是最短写法,但更接近真实办公环境里的可落地写法。
代码执行前,建议先安装依赖:
pip install pandas xlwings
正式运行前还要确认三件事:第一,Excel 文件没有被手动打开占用;第二,目标列名和代码里的 value_col 一致;第三,数据区域从 A1 开始,并且第一行是表头。
代码部分对应的是完整自动化落地场景:Python 脚本读取 Excel 数据,处理完成后自动输出结果文件。
从这个场景可以看出,Python + Excel 自动化的价值不是替代 Excel,而是把 Excel 中重复、机械、容易出错的动作交给脚本。人工只需要准备原始表格、确认字段规则、检查最终结果。
import pandas as pd
import xlwings as xw
def clean_to_number(s: pd.Series) -> pd.Series:
"""
将 Excel 中可能带有逗号、货币符号、空格的文本数字转换为真正的数值。
例如:
¥12,345.67 -> 12345.67
9,876.5 -> 9876.5
空值或异常字符 -> NaN
"""
s = s.astype(str).str.strip()
s = s.str.replace(",", "", regex=False)
s = s.str.replace(r"[¥¥$ ]", "", regex=True)
s = s.str.replace(r"[^0-9\.\-]", "", regex=True)
return pd.to_numeric(s, errors="coerce")
def batch_min_max(
input_xlsx: str,
value_col: str = "销售利润",
key_col: str | None = None,
summary_sheet: str = "极值汇总",
write_cell: str = "J1",
start_cell: str = "A1",
save_as: str | None = None,
) -> None:
"""
批量统计一个工作簿中所有工作表指定列的最大值和最小值。
参数说明:
input_xlsx 原始 Excel 文件路径
value_col 需要统计最大值和最小值的字段名
key_col 可选关键字段,例如产品名称、订单号、员工姓名
summary_sheet 汇总结果工作表名称
write_cell 每张原始工作表中写回统计结果的位置
start_cell 表格起始单元格
save_as 另存为路径;如果为 None,则覆盖保存原文件
"""
app = xw.App(visible=False, add_book=False)
app.display_alerts = False
app.screen_updating = False
try:
wb = app.books.open(input_xlsx)
rows = []
for sht in wb.sheets:
if sht.name == summary_sheet:
continue
rng = sht.range(start_cell).expand("table")
if rng.value is None:
print(f"[SKIP] {sht.name}: 空表")
continue
df = rng.options(pd.DataFrame).value
if df is None or df.empty:
print(f"[SKIP] {sht.name}: 无有效数据")
continue
if value_col not in df.columns:
print(f"[SKIP] {sht.name}: 缺少列:{value_col}")
continue
num = clean_to_number(df[value_col])
if num.isna().all():
print(f"[SKIP] {sht.name}: {value_col} 全部无法转换为数值")
continue
max_val = float(num.max(skipna=True))
min_val = float(num.min(skipna=True))
max_idx = int(num.idxmax(skipna=True))
min_idx = int(num.idxmin(skipna=True))
max_key = df.loc[max_idx, key_col] if (key_col and key_col in df.columns) else ""
min_key = df.loc[min_idx, key_col] if (key_col and key_col in df.columns) else ""
stat_df = pd.DataFrame({
"指标": [
"最大值",
"最小值",
"最大值所在行索引",
"最小值所在行索引",
"最大值关键字段",
"最小值关键字段"
],
"数值": [
max_val,
min_val,
max_idx,
min_idx,
max_key,
min_key
],
})
sht.range(write_cell).options(index=False).value = stat_df
sht.autofit()
rows.append({
"工作表": sht.name,
f"{value_col}最大值": max_val,
f"{value_col}最小值": min_val,
"最大值行索引": max_idx,
"最小值行索引": min_idx,
"最大值关键字段": max_key,
"最小值关键字段": min_key,
})
print(f"[OK] {sht.name}: max={max_val}, min={min_val}")
if not rows:
raise RuntimeError("没有得到任何极值结果,请检查字段名、表格区域或数据内容。")
summary_df = pd.DataFrame(rows)
global_max_row = summary_df.loc[summary_df[f"{value_col}最大值"].idxmax()]
global_min_row = summary_df.loc[summary_df[f"{value_col}最小值"].idxmin()]
try:
sum_sht = wb.sheets[summary_sheet]
sum_sht.clear()
except Exception:
sum_sht = wb.sheets.add(summary_sheet, before=wb.sheets[0])
sum_sht.range("A1").value = "全局最大值"
sum_sht.range("B1").value = float(global_max_row[f"{value_col}最大值"])
sum_sht.range("C1").value = "来自工作表"
sum_sht.range("D1").value = global_max_row["工作表"]
sum_sht.range("A2").value = "全局最小值"
sum_sht.range("B2").value = float(global_min_row[f"{value_col}最小值"])
sum_sht.range("C2").value = "来自工作表"
sum_sht.range("D2").value = global_min_row["工作表"]
summary_df_sorted = summary_df.sort_values(
by=f"{value_col}最大值",
ascending=False
)
sum_sht.range("A4").options(index=False).value = summary_df_sorted
try:
sum_sht.range("A1:D2").api.Font.Bold = True
sum_sht.autofit()
except Exception:
pass
if save_as:
wb.save(save_as)
print(f"[DONE] 已另存为:{save_as}")
else:
wb.save()
print(f"[DONE] 已覆盖保存:{input_xlsx}")
wb.close()
finally:
app.quit()
if __name__ == "__main__":
batch_min_max(
input_xlsx="产品销售统计表.xlsx",
value_col="销售利润",
key_col="产品名称",
summary_sheet="极值汇总",
write_cell="J1",
start_cell="A1",
save_as="产品销售统计表_极值统计.xlsx"
)
注意:如果你自己的表里没有 产品名称 这一列,就把 key_col="产品名称" 改成 key_col=None,否则关键字段会取不到。字段名必须和 Excel 表头完全一致,包括空格、括号、单位文字。
5. 关键点拆解:为什么要记录极值所在行和关键字段
很多人写极值统计脚本,只会输出一个最大值和最小值。这个结果看起来没错,但在实际工作中并不够。因为业务上真正关心的不是一个孤立数字,而是这个数字背后的记录。
比如最大利润是 35680,那还要继续问:它是哪张表里的?是哪一行?对应哪个产品?属于哪个销售区域?如果脚本没有记录这些信息,后续还是要人工回到原始表里查。
这就是为什么代码里要同时使用 max()、min()、idxmax() 和 idxmin()。
| 函数 | 作用 | 解决的问题 |
|---|---|---|
max() | 找最大值 | 最大是多少 |
min() | 找最小值 | 最小是多少 |
idxmax() | 找最大值所在索引 | 最大值在哪一行 |
idxmin() | 找最小值所在索引 | 最小值在哪一行 |
这里适合看极值追溯效果。画面中不仅标出了最大值,还把对应的工作表、行索引和关键字段关联起来。

从图中可以看出,极值定位的重点是“从结论回到明细”。这一步非常关键,因为它让统计结果不再是孤立数字,而是能直接追溯到原始数据。对真实办公场景来说,这比单纯算出最大值更有价值。
我的建议是:凡是做统计脚本,尽量同时输出“统计结论”和“数据来源”。这样后续复核、汇报、截图、做报告都会更顺。
6. 效果验证:最终应该看到什么结果
脚本运行结束后,不要只看控制台有没有报错。更稳的验证方式是打开输出的 Excel 文件,检查是否生成了新的 极值汇总 工作表。
正常情况下,汇总表顶部应该有全局最大值、全局最小值,以及对应来源工作表。下方应该有每张工作表的统计明细,包括最大值、最小值、最大值行索引、最小值行索引和关键字段。
最终汇总结果可以参考这种效果。它把每张表的极值和全局极值集中展示,适合直接作为统计结果交付。
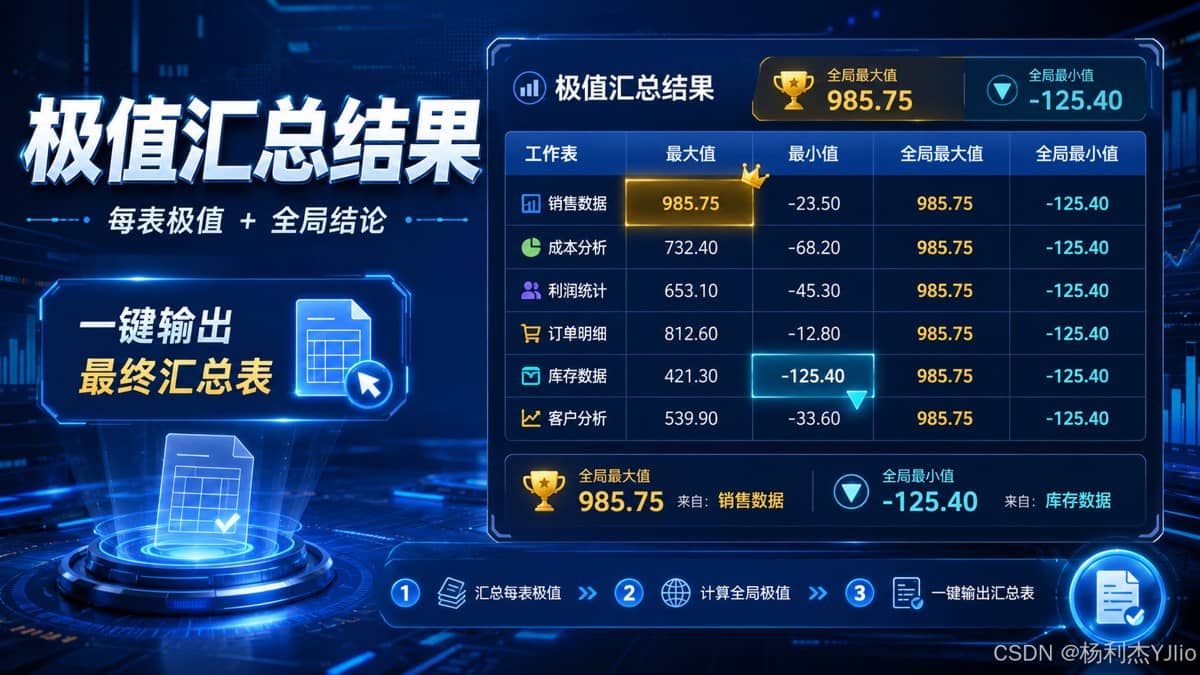
从这份结果里可以看出,汇总表的价值在于减少二次查找。打开结果页后,读者可以直接看到每张表的最大值、最小值,也能看到全局最大值和全局最小值来自哪里。
我建议至少做下面几个验证动作:
| 验证项 | 检查方法 | 正常结果 |
|---|---|---|
| 是否生成新文件 | 查看输出路径 | 出现 产品销售统计表_极值统计.xlsx |
| 是否生成汇总表 | 打开 Excel 查看 Sheet | 存在 极值汇总 工作表 |
| 是否统计到每张表 | 对比原工作表数量 | 汇总表中应有对应记录 |
| 是否有全局结论 | 查看 A1:D2 区域 | 有全局最大值和全局最小值 |
| 是否能追溯记录 | 查看行索引和关键字段 | 能定位到原始工作表中的明细 |
如果汇总表为空,不要急着怀疑 Python。优先检查目标列名是否写错、数据区域是否从 A1 开始、目标列是否全是文本异常值,或者工作表是否为空。
7. 常见问题与踩坑提醒
7.1 字段名不一致导致跳过工作表
最常见的问题是代码里写的是 销售利润,但 Excel 里实际表头是 利润、销售利润(元) 或者 销售利润。这类问题肉眼不一定容易发现,尤其是表头前后有空格时。
推荐做法是先打印每张表的字段名,确认字段是否一致。
print(df.columns.tolist())
7.2 数字看起来正常,但实际是文本
Excel 中的数字可能带有逗号、货币符号或者空格,例如 ¥12,345。如果不清洗,Python 可能会把它当成字符串处理。
这也是代码中单独写 clean_to_number() 函数的原因:先把目标列统一转换成数值,再计算极值。
7.3 行索引和 Excel 行号不是一回事
这里需要注意,idxmax() 返回的是 DataFrame 的索引,不一定等于 Excel 里的实际行号。如果表格第一行是标题,DataFrame 索引通常从数据行开始算。
如果你要输出精确的 Excel 行号,需要根据表头行位置进行换算。比如数据从第2行开始,那么 Excel 行号一般可以理解为 DataFrame索引 + 2。但如果原表中间有空行、合并单元格或复杂表头,就要重新确认。
7.4 不建议直接覆盖原文件
虽然脚本支持覆盖保存,但我更建议新手优先使用 save_as 另存为新文件。这样即使字段写错、数据区域识别错误,也不会破坏原始文件。
正式办公数据处理时,原始文件最好只读不改,输出结果另存。这是一条很朴素但很重要的习惯。
7.5 空表和缺列要允许跳过
真实工作簿里经常会有说明页、封面页、空白页或者结构不同的辅助表。如果脚本遇到这些表就直接报错,中断整个流程,使用体验会很差。
所以代码里对空表、缺列、无法转换数值等情况都做了跳过处理。这样能保证脚本尽量完成主要任务,同时在控制台输出跳过原因,方便后续检查。
8. 总结提升:极值统计的核心是“结论 + 来源 + 验证”
这一节表面是在学习最大值和最小值统计,但真正有价值的是建立一种办公自动化处理思路:先把重复动作抽象成流程,再用脚本固定下来,最后输出可以验证、可以追溯、可以复用的结果。
本篇最重要的收获可以总结成三句话。
第一,最大值和最小值不是难点,批量处理和结果追溯才是难点。
第二,统计结果不能只给数字,最好同时记录工作表名、行索引和关键字段。
第三,脚本运行成功不等于任务完成,必须打开结果文件做验证。
后续如果继续扩展,可以把这套脚本改造成更通用的模板。例如支持多个字段同时统计、支持 Top N 排名、支持按区域筛选后统计、支持批量处理多个工作簿。这样它就不只是一个案例代码,而是可以长期复用的 Excel 自动化工具。
以上就是Python批量统计Excel工作簿的最大值和最小值的详细内容,更多关于Python统计Excel最大值和最小值的资料请关注脚本之家其它相关文章!