
Pandas截取行列数据的方法实现过程
作者:驭风少年君
这篇文章主要介绍了Pandas截取行列数据的方法实现过程,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教
Pandas截取行列数据
- 读取方法有按行(单行,多行连续,多行不连续),按列(单列,多列连续,多列不连续);
- 部分不连续行不连续列;
- 按位置(坐标),按字符(索引);
- 按块(list);
函数有 df.iloc(), df.loc(), df.iat(), df.at(), df.ix()
#--------------------数据-------------------------
data = {'省份': ['北京', '上海', '广州', '深圳'],
'年份': ['2017', '2018', '2019', '2020'],
'总人数': ['2200', '1900', '2170', '1890'],
'高考人数': ['6.3', '5.9', '6.0', '5.2']}
#-------------------------Dataframe---------------------
df = pd.DataFrame(data, columns=['省份', '年份', '总人数', '高考人数', '高数'],
index=['one', 'two', 'three', 'four'])
#------------------------添加新的一列-------------------
df['高数'] = ['90', '95', '92', '98']
#-----------------------基本索引------------------------
print("行索引:{}".format(list(df.index)))
print("列索引:{}".format(list(df.columns)))
print('----------df.index[1:3]:------------')
print(df.index[1:3])
print('-----------df.columns[1]:----------')
print(df.columns[1])
print('-----------df.columns[1:3]:------------')
print(df.columns[1:3])
df

1.1 按照行取数据
print('*'*20)
print(df['省份']) #按列名取列
print('-'*16)
print(df.省份) #按列名取列
print('*'*20)
print(df[['省份', '总人数']]) #按列名取不连续列数据
print('-'*16)
print(df[df.columns[1:4]]) #按列索引取连续列数据
print('*'*20)
print(df.iloc[:, 1]) #按位置取列
print('-'*16)
print(df.iloc[:, [1, 3]]) #按位置取不连续列数据

1.2 按照行取数据
通过df.iloc[](数字)取行数据,取部分行部分列时,要先写行,再写列;有条件的取数据
print(df[1:3]) #按行取数据,这行代码结果没在下面输出print(df[df.高数>90]) #按行有条件的取数据,结果没输出print(df.iloc[1]) #按行取行数据 print(df.iloc[1, 3]) #按坐标取 print(df.iloc[[1], [3]]) #按坐标取 print(df.loc[df.index[1:3]]) #按行索引取行,但没必要 print(df.iloc[1:3]) #按行取连续数据 print(df.iloc[[1, 3]]) #按行取不连续数据 print(df.iloc[[1,2,3], [2,4]]) #取部分行部分列数据

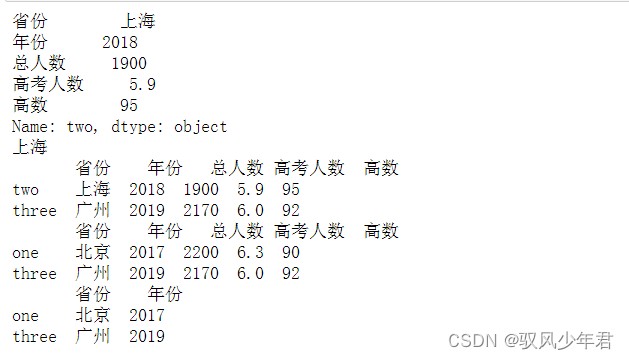
通过df.loc[]索引(字符)取行数据。
print(df.loc['two']) print(df.loc['two', '省份']) print(df.loc['two':'three']) print(df.loc[['one', 'three']]) print(df.loc[['one', 'three'], ['省份', '年份']])
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。