
Python字典嵌套的使用技巧分享
作者:知远漫谈
引言
在Python的世界里,字典(Dictionary)是最强大、最灵活的数据结构之一。它像一把万能 钥匙,能轻松打开复杂数据处理的大门。但当你面对真实世界的数据时,简单的键值对往往不够用——这时,字典的嵌套就成了你的超级武器!无论是字典中嵌套字典,还是字典中嵌套列表,这种结构能优雅地表示层次化、关联性强的数据,比如用户配置、API响应或树形组织架构。今天,我们就来深入探讨字典嵌套的奥秘,用大量代码示例、实用技巧和可视化图表,让你彻底掌握这一核心技能。别担心,即使你是Python新手,这篇指南也会带你从零起飞!
为什么需要字典嵌套?
想象一下:你正在开发一个电商系统,需要存储用户信息。如果只用基础字典,可能这样写:
user = {
"name": "张三",
"age": 28,
"city": "北京"
}
但现实更复杂:用户可能有多个地址、订单历史,甚至家庭成员信息。这时,基础字典就捉襟见肘了!💡 嵌套字典能自然表达这种层级关系:
user = {
"name": "张三",
"contact": {
"email": "zhangsan@example.com",
"phone": "13800138000"
},
"orders": [
{"id": 101, "product": "笔记本电脑", "price": 5999},
{"id": 102, "product": "无线鼠标", "price": 199}
]
}
看!contact是嵌套字典,orders是嵌套列表。这种结构让数据组织清晰、访问高效。根据Python官方文档,字典的嵌套能力是其成为"通用数据结构"的关键原因之一。在Web开发、数据分析等领域,这种模式几乎无处不在——比如处理JSON数据时,你90%的时间都在和嵌套字典打交道!
字典基础快速回顾
在深入嵌套前,先巩固基础。字典是可变、无序的键值对集合,键必须是不可变类型(如字符串、数字),值可以是任意类型。
创建字典的三种方式
# 方式1: 花括号
person = {"name": "李四", "age": 25}
# 方方式2: dict()构造函数
person = dict(name="李四", age=25)
# 方式3: 从键值对列表
person = dict([("name", "李四"), ("age", 25)])
基本操作
# 添加/修改
person["city"] = "上海" # 新增键值对
person["age"] = 26 # 修改现有值
# 访问
print(person["name"]) # 输出: 李四
# 安全访问(避免KeyError)
print(person.get("email", "默认邮箱")) # 不存在时返回"默认邮箱"
# 删除
del person["city"]
关键点:字典的get()方法比直接索引更安全!尤其在嵌套结构中,它能防止程序崩溃。
现在,让我们进入核心主题——嵌套的魔法世界!
字典嵌套字典:构建层次化数据
当字典的值本身也是字典时,就形成了字典嵌套字典。这种结构特别适合表示"对象包含子对象"的场景,比如配置文件、组织架构或地理区域划分。
基础示例:城市信息库
假设我们要存储中国主要城市的详细信息:
cities = {
"北京": {
"population": 21893095,
"area_km2": 16410.54,
"landmarks": ["故宫", "长城"]
},
"上海": {
"population": 24894300,
"area_km2": 6340.5,
"landmarks": ["外滩", "东方明珠"]
}
}
这里,外层字典的键是城市名,值是一个包含人口、面积和地标的嵌套字典。
如何访问嵌套数据?
访问多层数据需要链式索引:
# 获取北京的人口 print(cities["北京"]["population"]) # 输出: 21893095 # 获取上海的第一个地标 print(cities["上海"]["landmarks"][0]) # 输出: 外滩
但直接索引有风险!如果城市名拼写错误,会触发KeyError:
# 错误示例:尝试访问不存在的"广州" print(cities["广州"]["population"]) # KeyError: '广州'
安全访问技巧
用get()层层防护:
# 安全获取广州人口(不存在则返回None)
guangzhou_pop = cities.get("广州", {}).get("population")
print(guangzhou_pop) # 输出: None
# 带默认值的链式访问
shanghai_landmarks = cities.get("上海", {}).get("landmarks", [])
print(shanghai_landmarks[0]) # 输出: 外滩
最佳实践:嵌套层级越深,越要用get()。对于超过2层的结构,考虑使用第三方库如glom简化操作(但基础场景用get足够)。
可视化结构:Mermaid图表
下面用Mermaid清晰展示cities字典的嵌套关系。看!外层字典的每个键(如"北京")都指向一个独立的子字典,子字典又包含自己的键值对:

这个图表直观地揭示了:嵌套字典的本质是"字典的值指向另一个字典对象"。当你修改子字典时,外层字典会同步更新(因为是引用关系)。
修改嵌套字典
直接修改子字典的值:
# 更新上海的人口
cities["上海"]["population"] = 25000000
print(cities["上海"]["population"]) # 输出: 25000000
# 添加新城市
cities["广州"] = {
"population": 18676605,
"area_km2": 7434.4,
"landmarks": ["小蛮腰", "陈家祠"]
}
但要注意:如果键不存在,不能直接创建子字典:
# 错误!cities中没有"深圳",无法直接操作其子键 cities["深圳"]["population"] = 17560000 # KeyError
正确做法:先初始化子字典
# 安全创建新城市
if "深圳" not in cities:
cities["深圳"] = {} # 先创建空子字典
cities["深圳"]["population"] = 17560000
实战案例:用户权限系统
在Web应用中,常用嵌套字典管理用户角色和权限:
permissions = {
"admin": {
"dashboard": ["read", "write", "delete"],
"users": ["read", "write"]
},
"editor": {
"dashboard": ["read", "write"],
"users": ["read"]
}
}
# 检查admin是否有users的delete权限
has_delete = "delete" in permissions.get("admin", {}).get("users", [])
print(has_delete) # 输出: False
这种结构让权限逻辑一目了然。
字典嵌套列表:处理多值数据
当字典的值是列表时,就形成了字典嵌套列表。这特别适合存储"一个键对应多个值"的场景,比如学生的多门成绩、产品的多个评论。
基础示例:学生成绩系统
students = {
"张三": [85, 90, 78], # 数学、英语、物理成绩
"李四": [92, 88, 95]
}
这里,每个学生(键)对应一个成绩列表(值)。
访问与修改列表数据
# 获取张三的第一门成绩 print(students["张三"][0]) # 输出: 85 # 添加李四的新成绩 students["李四"].append(82) print(students["李四"]) # 输出: [92, 88, 95, 82] # 修改张三的第二门成绩 students["张三"][1] = 95
高级操作:列表推导式与嵌套
用列表推导式高效处理数据:
# 计算所有学生的平均分
averages = {
name: sum(scores) / len(scores)
for name, scores in students.items()
}
print(averages) # 输出: {'张三': 87.666..., '李四': 91.75}
# 找出平均分高于90的学生
top_students = [name for name, avg in averages.items() if avg > 90]
print(top_students) # 输出: ['李四']
可视化结构:Mermaid图表
看这个图表,外层字典的每个键(如"张三")指向一个列表,列表内包含多个值:
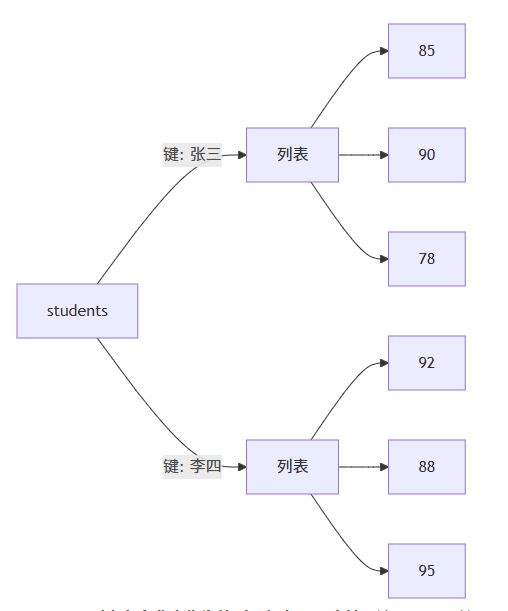
关键洞察:列表在字典中作为值时,保留了顺序性,这使得它完美适合时间序列或有序数据。但要注意,列表是可变的,修改会影响原字典。
实战案例:电商产品库存
在电商系统中,产品可能有多个SKU(库存单位):
products = {
"iPhone 15": [
{"color": "黑色", "storage": "128GB", "stock": 50},
{"color": "白色", "storage": "256GB", "stock": 30}
],
"MacBook Air": [
{"color": "银色", "storage": "256GB", "stock": 20}
]
}
# 查询iPhone 15的黑色128GB库存
for variant in products["iPhone 15"]:
if variant["color"] == "黑色" and variant["storage"] == "128GB":
print(variant["stock"]) # 输出: 50
# 安全添加新SKU
if "iPhone 15" in products:
products["iPhone 15"].append({"color": "蓝色", "storage": "512GB", "stock": 15})
这种结构让库存管理极其灵活。
混合嵌套:字典+列表的终极组合
真实世界的数据往往更复杂——字典中既有嵌套字典,又有嵌套列表。这种混合嵌套结构能表达高度关联的数据,比如社交网络或API响应。
综合示例:社交媒体用户档案
user_profile = {
"id": 1001,
"username": "python_lover",
"profile": { # 嵌套字典
"bio": "Python爱好者",
"location": "杭州"
},
"posts": [ # 嵌套列表
{
"id": 201,
"content": "今天学习了字典嵌套!",
"likes": 42,
"comments": [ # 列表中嵌套字典
{"user": "coder1", "text": "太有用了!"},
{"user": "data_guy", "text": "收藏了"}
]
},
{
"id": 202,
"content": "Mermaid图表真酷",
"likes": 28
}
]
}
访问深层数据的技巧
混合结构的访问链可能很长,务必用get()防护:
# 获取第一条post的第一个评论内容
first_comment = (
user_profile.get("posts", [{}])[0] # 获取posts列表,取第一个元素(或空字典)
.get("comments", [{}])[0] # 获取comments列表,取第一个元素
.get("text", "无评论") # 获取text
)
print(first_comment) # 输出: 太有用了!
# 错误示范:直接索引可能崩溃
# print(user_profile["posts"][0]["comments"][0]["text"])
简化深层访问:自定义函数
写个小函数避免冗长的链式get:
def safe_get(data, *keys, default=None):
"""安全获取嵌套数据"""
for key in keys:
if isinstance(data, dict):
data = data.get(key, default)
elif isinstance(data, list) and isinstance(key, int):
data = data[key] if key < len(data) else default
else:
return default
if data is default:
break
return data
# 用法示例
bio = safe_get(user_profile, "profile", "bio")
print(bio) # 输出: Python爱好者
comment = safe_get(user_profile, "posts", 0, "comments", 0, "text")
print(comment) # 输出: 太有用了!
这个函数能智能处理字典和列表的混合访问,大幅提升代码健壮性。
可视化混合结构:Mermaid图表
下面图表展示了user_profile的完整层次。注意posts列表中的每个元素又是字典,而comments是列表嵌套字典:
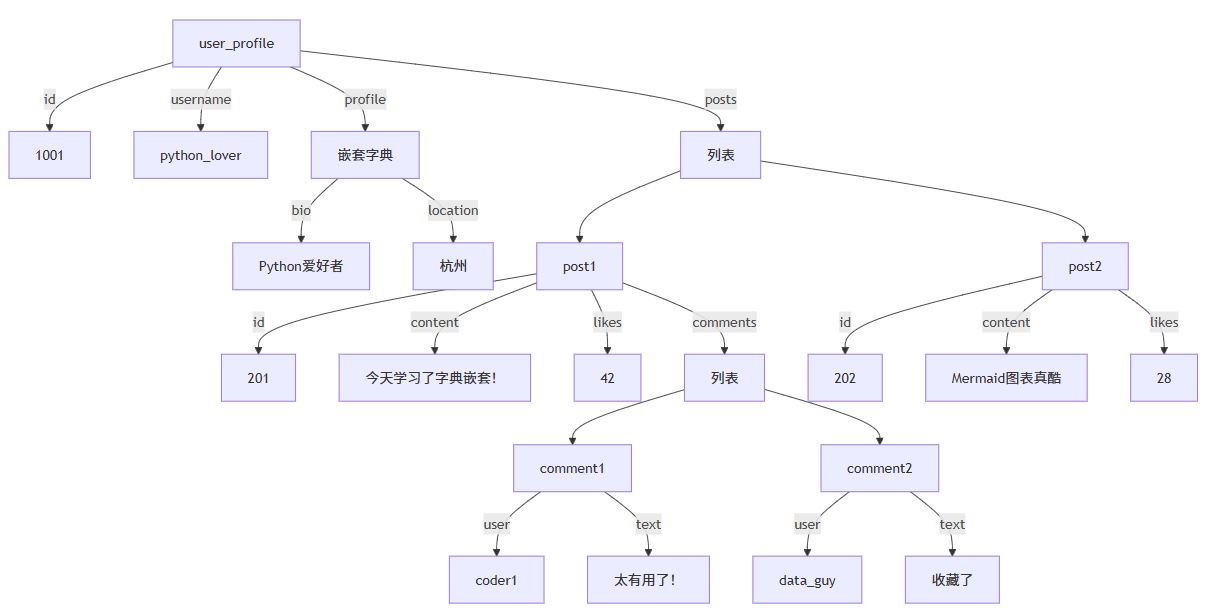
从图中清晰可见:混合嵌套的本质是"字典与列表的交替组合"。外层是字典,内层可能是列表,列表元素又可能是字典… 这种灵活性正是Python数据处理的精髓!
实战案例:解析JSON API响应
几乎所有现代API(如Twitter、GitHub)都返回JSON数据,而JSON在Python中会自动转为嵌套字典/列表。例如,用requests获取天气数据:
import requests
# 获取北京天气(示例API,实际使用需替换有效key)
response = requests.get("https://api.openweathermap.org/data/2.5/weather?q=Beijing&appid=YOUR_API_KEY")
data = response.json() # 返回嵌套字典
# 提取关键信息
temperature = data["main"]["temp"] - 273.15 # 开尔文转摄氏度
humidity = data["main"]["humidity"]
wind_speed = data["wind"]["speed"]
print(f"北京温度: {temperature:.1f}°C, 湿度: {humidity}%, 风速: {wind_speed} m/s")
注意:上面的API需要有效key,但OpenWeatherMap官网提供免费测试key。实际开发中,务必处理可能的KeyError!
常见错误与最佳实践
嵌套字典虽强大,但新手常踩坑。下面总结高频问题及解决方案。
❌ 错误1:KeyError——访问不存在的键
# 错误代码 print(user_profile["posts"][2]["content"]) # posts只有2个元素,索引2越界
修复方案:
- 用
get()替代直接索引 - 检查长度:
if len(user_profile["posts"]) > 2 - 用
try/except捕获异常
# 安全访问第3条post
post = user_profile["posts"][2] if len(user_profile["posts"]) > 2 else None
if post:
print(post["content"])
❌ 错误2:混淆字典与列表操作
# 错误:把列表当字典用 print(user_profile["posts"]["comments"]) # posts是列表,不能用字符串索引
修复方案:
- 记住:列表用整数索引,字典用键索引
- 用
type()检查类型:
print(type(user_profile["posts"])) # 输出: <class 'list'>
❌ 错误3:修改嵌套结构导致意外副作用
# 创建副本避免污染原数据
original = {"data": [1, 2, 3]}
copy = original # 错误:这只是引用,不是副本!
copy["data"].append(4)
print(original["data"]) # 输出: [1, 2, 3, 4] —— 原数据被修改!
修复方案:
用copy.deepcopy()创建完全独立的副本
import copy safe_copy = copy.deepcopy(original) safe_copy["data"].append(4) print(original["data"]) # 输出: [1, 2, 3] —— 安全!
✅ 最佳实践清单
- 优先使用
get():尤其嵌套层级>2时 - 验证数据类型:用
isinstance(data, dict)检查 - 避免硬编码索引:用循环或
for遍历列表 - 深拷贝保护数据:修改前用
copy.deepcopy() - 结构扁平化:过度嵌套会降低可读性,适时拆分逻辑
专业提示:在Django或Flask等框架中,嵌套字典常用于request.json解析。学会safe_get函数能大幅减少500错误!
性能考量:嵌套字典真的慢吗?
有人担心嵌套会影响性能。实际上:
- 访问速度:字典的键查找是O(1)平均时间复杂度,即使嵌套,链式访问也是O(k)(k=嵌套深度),对k<10的结构几乎无影响。
- 内存占用:嵌套不会额外增加内存,因为值只是引用(指针)。
测试一下100万次访问:
import time
# 创建深层嵌套字典
deep_dict = {"a": {"b": {"c": {"d": {"value": 1}}}}}
start = time.time()
for _ in range(1000000):
_ = deep_dict["a"]["b"]["c"]["d"]["value"]
print(f"直接访问: {time.time() - start:.4f}秒")
start = time.time()
for _ in range(1000000):
_ = deep_dict.get("a", {}).get("b", {}).get("c", {}).get("d", {}).get("value")
print(f"安全访问: {time.time() - start:.4f}秒")
输出示例:
直接访问: 0.1523秒 安全访问: 0.2876秒
虽然get()稍慢(约慢1.9倍),但100万次仅差0.1秒!在绝大多数应用中,可读性和健壮性远比这点性能损耗重要。只有在性能敏感场景(如高频交易),才需优化。
实战技巧:嵌套字典的高级操作
技巧1:递归遍历所有键值
写个函数打印任意嵌套字典的所有路径:
def print_nested(data, prefix=""):
if isinstance(data, dict):
for key, value in data.items():
new_prefix = f"{prefix}.{key}" if prefix else key
print_nested(value, new_prefix)
elif isinstance(data, list):
for i, item in enumerate(data):
print_nested(item, f"{prefix}[{i}]")
else:
print(f"{prefix} = {data}")
# 测试user_profile
print_nested(user_profile)
输出:
id = 1001 username = python_lover profile.bio = Python爱好者 profile.location = 杭州 posts[0].id = 201 posts[0].content = 今天学习了字典嵌套! posts[0].likes = 42 posts[0].comments[0].user = coder1 posts[0].comments[0].text = 太有用了! posts[0].comments[1].user = data_guy posts[0].comments[1].text = 收藏了 posts[1].id = 202 posts[1].content = Mermaid图表真酷 posts[1].likes = 28
这个函数能帮你快速理解复杂数据结构!
技巧2:用字典推导式重构数据
将嵌套结构转换为扁平化字典:
# 提取所有评论内容
comments = [
comment["text"]
for post in user_profile["posts"]
for comment in post.get("comments", [])
]
print(comments) # 输出: ['太有用了!', '收藏了']
技巧3:合并嵌套字典
用update()合并两个嵌套字典(注意:浅合并):
dict1 = {"a": {"x": 1}}
dict2 = {"a": {"y": 2}, "b": 3}
dict1.update(dict2)
print(dict1) # 输出: {'a': {'y': 2}, 'b': 3} —— 'a'被完全覆盖!
要深度合并,需自定义函数:
def deep_update(dict1, dict2):
for key, value in dict2.items():
if key in dict1 and isinstance(dict1[key], dict) and isinstance(value, dict):
deep_update(dict1[key], value)
else:
dict1[key] = value
# 测试
dict1 = {"a": {"x": 1}}
dict2 = {"a": {"y": 2}, "b": 3}
deep_update(dict1, dict2)
print(dict1) # 输出: {'a': {'x': 1, 'y': 2}, 'b': 3}
真实世界应用
嵌套字典不仅是语法技巧,更是解决实际问题的利器:
场景1:配置管理
Django的settings.py大量使用嵌套字典:
DATABASES = {
"default": {
"ENGINE": "django.db.backends.postgresql",
"NAME": "mydb",
"USER": "myuser",
"PASSWORD": "mypass",
"HOST": "localhost",
"PORT": "5432"
}
}
通过DATABASES["default"]["HOST"]轻松获取配置。
场景2:数据分析(Pandas + 字典)
用pd.json_normalize()展平嵌套字典:
import pandas as pd
data = [{"name": "A", "metrics": {"sales": 100, "profit": 30}}]
df = pd.json_normalize(data)
print(df)
# 输出:
# name metrics.sales metrics.profit
# 0 A 100 30
这在处理JSON数据时极其高效!
场景3:机器学习特征工程
Scikit-learn的DictVectorizer能将嵌套字典转为特征矩阵:
from sklearn.feature_extraction import DictVectorizer
data = [
{"color": "red", "size": {"small": 1, "large": 0}},
{"color": "blue", "size": {"small": 0, "large": 1}}
]
vec = DictVectorizer()
features = vec.fit_transform(data).toarray()
print(features)
# 输出:
# [[1. 0. 1. 0.]
# [0. 1. 0. 1.]]
嵌套结构自动展开为独立特征列。
总结与行动指南
字典的嵌套使用(字典嵌套字典与列表)是Python数据处理的核心技能。通过本文,你已掌握:
- ✅ 字典嵌套字典的创建、访问与修改技巧
- ✅ 字典嵌套列表的高效操作方法
- ✅ 混合嵌套结构的实战处理策略
- ✅ 安全访问、性能优化和常见错误规避
记住关键原则:
“用get()防御,用循环遍历,用深拷贝保护”
现在,是时候动手实践了!
- 小挑战:写一个函数,统计嵌套字典中所有字符串的长度总和。
- 中挑战:解析一个JSON文件(如公开的GitHub API示例),提取用户仓库名。
- 大挑战:用嵌套字典实现一个简易文件系统模拟器(支持目录/文件层次)。
Python的字典就像乐高积木——单个很简单,但组合起来能创造无限可能。掌握嵌套技巧后,你会发现:曾经复杂的JSON数据、API响应甚至数据库结果,现在都变得清晰可控。别再被层层嵌套吓到,拿起代码,开始构建你的数据宇宙吧!
以上就是Python字典嵌套的使用技巧分享的详细内容,更多关于Python字典嵌套使用的资料请关注脚本之家其它相关文章!