
使用Python手写一个智能PDF文档助手
作者:我不是呆头
你是否想亲手打造一个属于自己的AI工具?是否想过用不到100行代码就能实现一个智能聊天机器人,本文将带你从零开始,手写一个实用的AI小工具——智能PDF文档助手,需要的朋友可以参考下
写在前面
你是否想亲手打造一个属于自己的AI工具?是否想过用不到100行代码就能实现一个智能聊天机器人
本文将带你从零开始,手写一个实用的AI小工具——智能PDF文档助手!
通过这个项目,你将学会:
- 如何调用OpenAI API
- 如何处理PDF文档
- 如何构建一个完整的命令行工具
- 如何优化代码结构和错误处理
项目简介:智能PDF文档助手
功能特性
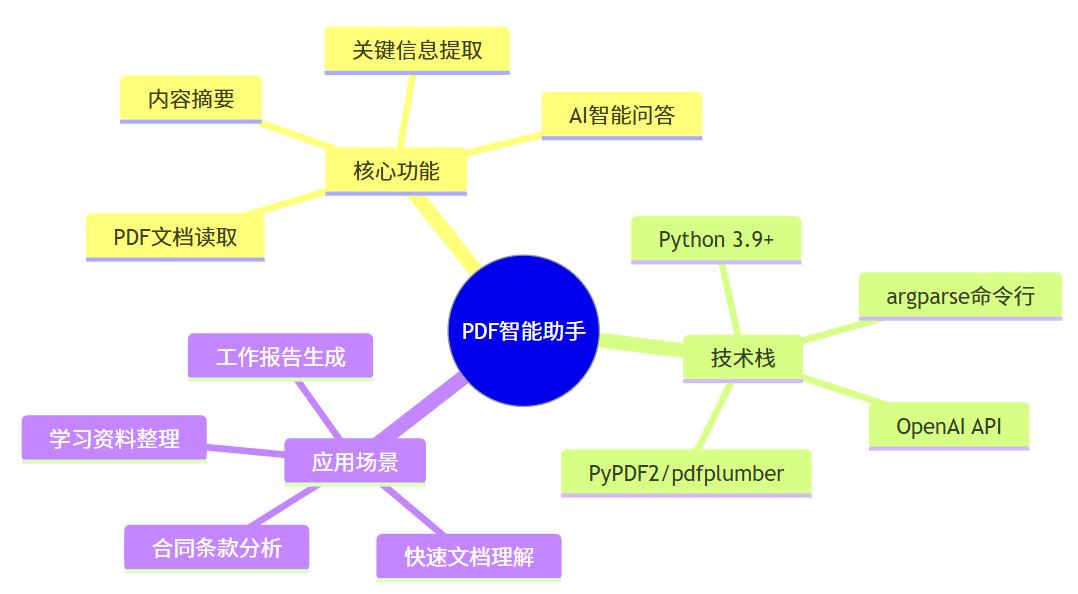
项目亮点
| 功能 | 说明 |
|---|---|
| 多格式支持 | 支持PDF、TXT文件读取 |
| AI驱动 | 使用GPT模型进行智能分析 |
| 快速响应 | 流式输出,实时查看结果 |
| 彩色输出 | 命令行美化,体验更佳 |
| 进度显示 | 文件读取进度可视化 |
环境准备
Python环境检查
# 检查Python版本
import sys
print(f"Python版本: {sys.version}")
# 推荐版本:Python 3.9 或更高
# 下载地址:https://www.python.org/downloads/
安装依赖库
创建 requirements.txt 文件:
openai>=1.0.0 pdfplumber>=0.10.0 python-dotenv>=1.0.0 colorama>=0.4.6 tqdm>=4.65.0
安装命令:
# 创建虚拟环境(推荐) python -m venv ai_assistant_env # 激活虚拟环境 # Windows: ai_assistant_env\Scripts\activate # Mac/Linux: source ai_assistant_env/bin/activate # 安装依赖 pip install -r requirements.txt
获取OpenAI API Key
![]()
# 创建 .env 文件 echo OPENAI_API_KEY=your_api_key_here > .env echo OPENAI_BASE_URL=https://api.openai.com/v1 >> .env
项目结构设计
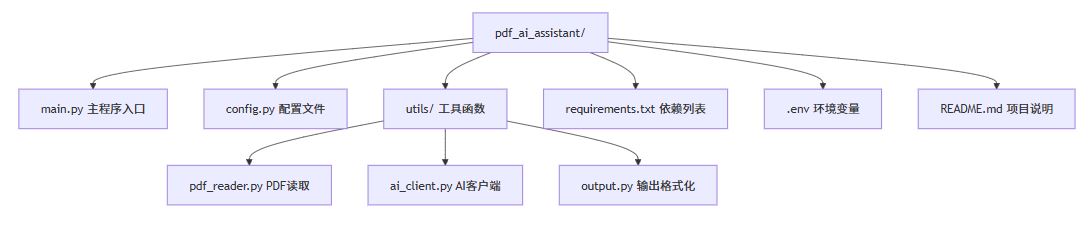
核心代码实现
配置文件 (config.py)
"""
配置文件 - 管理所有配置项
"""
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
class Config:
"""应用配置类"""
# OpenAI配置
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_BASE_URL = os.getenv("OPENAI_BASE_URL", "https://api.openai.com/v1")
OPENAI_MODEL = os.getenv("OPENAI_MODEL", "gpt-3.5-turbo")
# 应用配置
MAX_FILE_SIZE = 10 * 1024 * 1024 # 10MB
CHUNK_SIZE = 1000 # 每次处理的字符数
MAX_TOKENS = 2000 # AI最大响应长度
# 颜色配置
COLORS = {
"header": "\033[95m", # 紫色
"okblue": "\033[94m", # 蓝色
"okgreen": "\033[92m", # 绿色
"warning": "\033[93m", # 黄色
"fail": "\033[91m", # 红色
"endc": "\033[0m", # 结束
}
@classmethod
def color_print(cls, color_type, message):
"""彩色打印"""
color = cls.COLORS.get(color_type, "")
print(f"{color}{message}{cls.COLORS['endc']}")
# 验证配置
if not Config.OPENAI_API_KEY:
Config.color_print("fail", "❌ 请在.env文件中设置OPENAI_API_KEY")
exit(1)
PDF读取模块 (pdf_reader.py)
"""
PDF文档读取模块
"""
import pdfplumber
from tqdm import tqdm
from config import Config
class PDFReader:
"""PDF文档读取器"""
def __init__(self, file_path):
self.file_path = file_path
self.content = ""
self.page_count = 0
def validate_file(self):
"""验证文件"""
if not self.file_path.endswith('.pdf'):
raise ValueError("❌ 仅支持PDF文件格式")
import os
file_size = os.path.getsize(self.file_path)
if file_size > Config.MAX_FILE_SIZE:
raise ValueError(f"❌ 文件过大,最大支持{Config.MAX_FILE_SIZE//1024//1024}MB")
def read_pdf(self):
"""读取PDF内容"""
try:
self.validate_file()
Config.color_print("okblue", f"📖 正在读取文件: {self.file_path}")
with pdfplumber.open(self.file_path) as pdf:
self.page_count = len(pdf.pages)
Config.color_print("okgreen", f"📄 共 {self.page_count} 页")
# 使用进度条
for page in tqdm(pdf.pages, desc="读取进度", unit="页"):
text = page.extract_text()
if text:
self.content += text + "\n\n"
Config.color_print("okgreen", f"✅ 读取完成!共 {len(self.content)} 字符")
return self.content
except Exception as e:
Config.color_print("fail", f"❌ 读取失败: {str(e)}")
raise
def get_summary(self):
"""获取文档摘要(前500字)"""
return self.content[:500] + "..." if len(self.content) > 500 else self.content
AI客户端模块 (ai_client.py)
"""
OpenAI API客户端模块
"""
from openai import OpenAI
from config import Config
import time
class AIClient:
"""AI助手客户端"""
def __init__(self):
self.client = OpenAI(
api_key=Config.OPENAI_API_KEY,
base_url=Config.OPENAI_BASE_URL
)
def ask(self, question, context=""):
"""向AI提问"""
try:
# 构建消息
messages = [
{"role": "system", "content": "你是一个专业的文档分析助手。"},
{"role": "user", "content": f"文档内容:\n{context}\n\n问题:{question}"}
]
Config.color_print("okblue", "🤖 AI正在思考...")
# 调用API
start_time = time.time()
response = self.client.chat.completions.create(
model=Config.OPENAI_MODEL,
messages=messages,
max_tokens=Config.MAX_TOKENS,
stream=True # 启用流式输出
)
# 流式输出
answer = ""
Config.color_print("okgreen", "📝 AI回答:")
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
answer += content
print(content, end="", flush=True)
print() # 换行
elapsed = time.time() - start_time
Config.color_print("okblue", f"⏱️ 耗时: {elapsed:.2f}秒")
return answer
except Exception as e:
Config.color_print("fail", f"❌ API调用失败: {str(e)}")
raise
def summarize(self, content):
"""生成文档摘要"""
prompt = f"请为以下文档生成一个简洁的摘要(不超过200字):\n\n{content[:2000]}"
return self.ask(prompt, "")
def extract_keywords(self, content):
"""提取关键词"""
prompt = f"请从以下文档中提取5-10个关键词:\n\n{content[:2000]}"
return self.ask(prompt, "")
主程序入口 (main.py)
"""
PDF智能助手主程序
"""
import argparse
import sys
from pdf_reader import PDFReader
from ai_client import AIClient
from config import Config
def print_banner():
"""打印欢迎界面"""
banner = """
╔═══════════════════════════════════════╗
║ 📚 PDF智能文档助手 v1.0 📚 ║
║ Powered by OpenAI GPT ║
╚═══════════════════════════════════════╝
"""
Config.color_print("header", banner)
def interactive_mode(reader, ai_client):
"""交互模式"""
Config.color_print("okgreen", "\n🎯 进入交互模式(输入'quit'退出)")
context = reader.content[:3000] # 使用前3000字作为上下文
while True:
try:
question = input("\n💬 请输入问题: ").strip()
if question.lower() in ['quit', 'exit', 'q']:
Config.color_print("warning", "👋 再见!")
break
if not question:
continue
ai_client.ask(question, context)
except KeyboardInterrupt:
Config.color_print("warning", "\n👋 用户取消,再见!")
break
except Exception as e:
Config.color_print("fail", f"❌ 错误: {str(e)}")
def main():
"""主函数"""
parser = argparse.ArgumentParser(description="PDF智能文档助手")
parser.add_argument("file", help="PDF文件路径")
parser.add_argument("--summarize", action="store_true", help="生成文档摘要")
parser.add_argument("--keywords", action="store_true", help="提取关键词")
parser.add_argument("--ask", metavar="QUESTION", help="向AI提问")
args = parser.parse_args()
print_banner()
try:
# 读取PDF
reader = PDFReader(args.file)
content = reader.read_pdf()
# 初始化AI客户端
ai_client = AIClient()
# 执行相应功能
if args.summarize:
ai_client.summarize(content)
elif args.keywords:
ai_client.extract_keywords(content)
elif args.ask:
ai_client.ask(args.ask, content[:3000])
else:
# 进入交互模式
interactive_mode(reader, ai_client)
except Exception as e:
Config.color_print("fail", f"\n❌ 程序异常: {str(e)}")
sys.exit(1)
if __name__ == "__main__":
main()
项目功能流程图
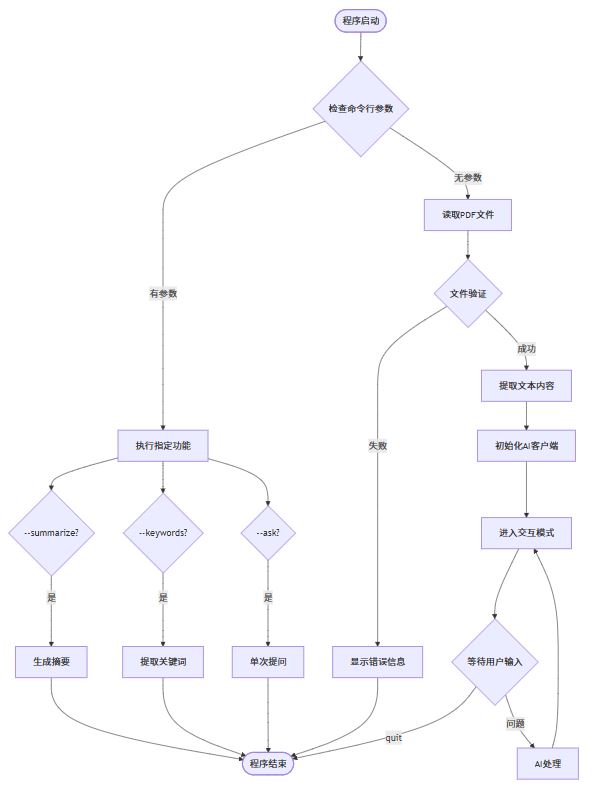
使用示例
生成文档摘要
python main.py document.pdf --summarize
提取关键词
python main.py document.pdf --keywords
单次提问
python main.py document.pdf --ask "这篇文章的主要观点是什么?"
交互模式
python main.py document.pdf
交互模式示例输出:
💬 请输入问题: 这篇文章讲了什么? 🤖 AI正在思考... 📝 AI回答: 这篇文章主要介绍了人工智能的发展历程和应用场景... ⏱️ 耗时: 2.35秒 💬 请输入问题: 作者提到了哪些关键技术? 🤖 AI正在思考... 📝 AI回答: 作者主要提到了以下几项关键技术: 1. 深度学习 2. 自然语言处理 3. 计算机视觉 ... ⏱️ 耗时: 1.98秒 💬 请输入问题: quit 👋 再见!
AI小工具开发技能分布
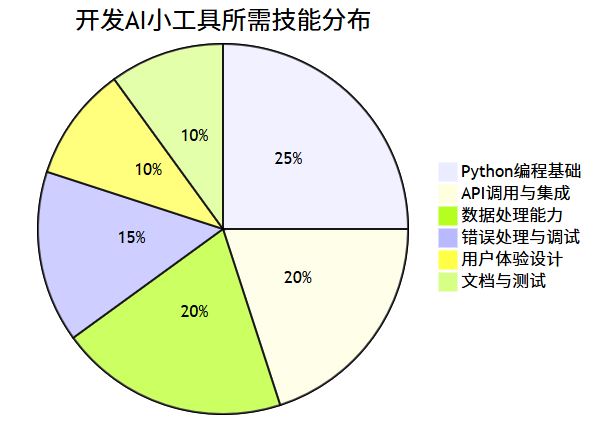
进阶功能扩展
添加批量处理功能
def batch_process(file_list, func):
"""批量处理多个文件"""
results = []
for file in tqdm(file_list, desc="批量处理"):
try:
reader = PDFReader(file)
content = reader.read_pdf()
result = func(content)
results.append({
"file": file,
"result": result,
"status": "success"
})
except Exception as e:
results.append({
"file": file,
"result": str(e),
"status": "failed"
})
return results
添加导出功能
def export_to_markdown(content, output_file):
"""导出为Markdown格式"""
with open(output_file, 'w', encoding='utf-8') as f:
f.write("# 文档摘要\n\n")
f.write(content)
Config.color_print("okgreen", f"✅ 已导出到: {output_file}")
添加记忆功能
class ConversationMemory:
"""对话记忆管理"""
def __init__(self, max_history=5):
self.history = []
self.max_history = max_history
def add(self, question, answer):
"""添加对话记录"""
self.history.append({
"question": question,
"answer": answer
})
# 保留最近N条记录
if len(self.history) > self.max_history:
self.history = self.history[-self.max_history:]
def get_context(self):
"""获取上下文"""
context = ""
for item in self.history:
context += f"Q: {item['question']}\nA: {item['answer']}\n\n"
return context
开发经验总结
常见问题及解决方案
| 问题 | 解决方案 |
|---|---|
| API调用超时 | 添加重试机制,设置合理的timeout |
| 内存占用过高 | 分块处理大文件,使用生成器 |
| 用户体验差 | 添加进度条、彩色输出、友好提示 |
| 代码可维护性差 | 模块化设计,添加类型注解和文档 |
最佳实践
# 1. 使用类型注解
def process_file(file_path: str) -> dict:
"""处理文件并返回结果字典"""
pass
# 2. 添加异常处理
try:
result = risky_operation()
except SpecificError as e:
logger.error(f"操作失败: {e}")
# 执行恢复操作
finally:
cleanup()
# 3. 使用日志记录
import logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
# 4. 编写单元测试
import unittest
class TestPDFReader(unittest.TestCase):
def test_validate_file(self):
reader = PDFReader("test.pdf")
# 测试代码...
结语
恭喜你!
如果你已经跟随这篇文章完成了项目,那么你已经:
✅ 学会了如何调用OpenAI API
✅ 掌握了PDF文件处理技巧
✅ 了解了命令行工具的开发流程
✅ 获得了一个实用的AI小工具
下一步建议:
- 尝试添加新功能(如多格式支持、语音交互)
- 优化用户界面(如使用GUI框架)
- 部署到云端(如使用FastAPI构建Web服务)
- 开发更多AI小工具(如图片识别、语音助手)
记住:最好的学习方式就是动手实践!
以上就是使用Python手写一个智能PDF文档助手的详细内容,更多关于Python智能PDF文档助手的资料请关注脚本之家其它相关文章!