
Python实现批量将CSV按行或按列拆分
作者:小庄-Python办公
本文完整拆解一个可用于生产的 CSV 拆分工具,从架构、核心算法、GUI 与多线程到异常与性能边界,全部基于 Python 标准库 csv 与 PyQt5 实现。
效果图
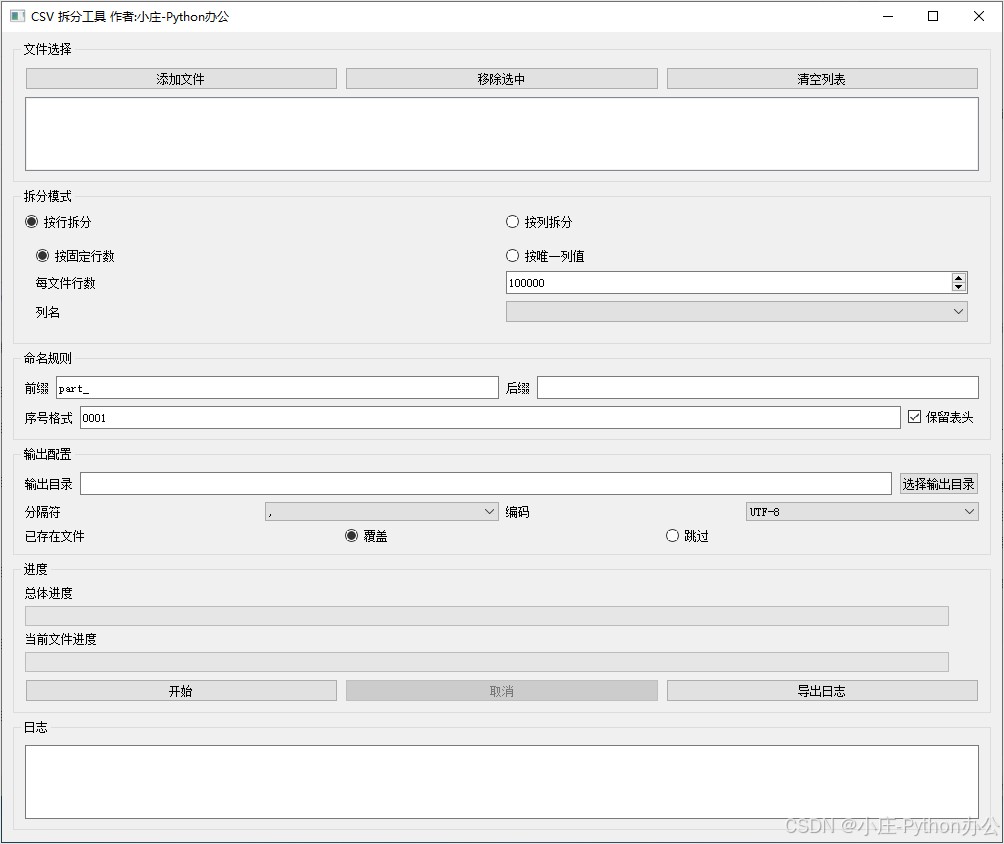
需求与目标
核心目标是实现一个桌面 GUI:
- 多文件选择与拖拽列表
- 按行拆分与按列拆分两种模式,参数联动
- 可配置输出目录、编码、分隔符、命名规则与覆盖策略
- 支持 1GB / 500 万行规模,内存占用低,GUI 不阻塞
- 实时进度、日志与异常提示,支持取消与清理
总体设计
项目结构极简,仅一个入口脚本:
- GUI 与业务逻辑全部在 [main.py]
- 核心拆分函数
split_csv_file完成流式拆分与异常捕获 Worker在 QThread 中执行,保证 GUI 响应- 日志、进度通过 Qt 信号回传 UI
设计重点是把“耗时 IO 与 CPU”放在后台线程,把“交互与展示”留给主线程。
CSV 拆分核心逻辑
核心函数是 [split_csv_file],仅使用 csv.reader/csv.writer,满足低内存与高兼容性。
1. 统一设置与结果模型
通过 SplitSettings 和 FileResult 描述输入配置与输出状态:
- 选择拆分模式、编码、分隔符
- 命名规则(前缀/后缀/序号格式)
- 是否保留表头、覆盖策略
- 统一错误信息与 traceback
2. 按行拆分
按行拆分包含两种子模式:
- 按固定行数切分
- 按唯一列值分组输出
按固定行数
关键点:
- 每达到
rows_per_file就关闭当前输出文件,启动下一个 - 表头按需写入
- 通过
row_index控制进度刷新,避免频繁更新 UI
示例片段(仅为理解):
if count == 0:
seq_text = format_sequence(seq, settings.seq_format)
filename = f"{settings.prefix}{seq_text}{settings.suffix}.csv"
out_file = os.path.join(settings.output_dir, filename)
按唯一列值
核心策略是使用 WriterCache 复用输出文件句柄,避免每行开关文件:
WriterCache维护有限数量打开文件- 超出上限后按 LRU 关闭句柄
- 已创建文件用 append 追加,避免重复写表头
3. 按列拆分与二次按行
按列拆分本质上也是“按唯一值分组输出”,并可选二次按行拆分:
- 先按列值生成文件名
- 若开启二次拆分,按行数再切分出
value_序号.csv
4. 文件名安全与序号格式
为防止非法字符,统一使用 sanitize_filename 处理列值:
- 替换系统禁止字符
- 空值统一成
EMPTY - 过长截断
序号格式支持两种:
- 纯数字模板,如
0001 - format 模式,如
{0:04d}
GUI 设计与交互流
GUI 核心在拆分成多个可复用面板。
1. 文件选择与拖拽
FileListWidget 继承 QListWidget,实现拖拽导入:
- 过滤 csv 后缀
- 自动去重
2. 模式切换
按行/按列通过 QStackedWidget 互斥显示:
self.mode_row与self.mode_col绑定_switch_mode切换索引
3. 参数联动与列名读取
当文件列表变化或编码/分隔符变化时,自动刷新列名:
- 读取首行作为表头
- 更新“按行唯一列”和“按列拆分列”下拉框
4. 输出配置与命名规则
统一面板提供:
- 输出目录选择
- 分隔符(逗号/分号/制表符/竖线)
- 编码(UTF-8/UTF-8-sig/GBK)
- 覆盖或跳过策略
- 命名规则(前缀/后缀/序号格式)
多线程与任务生命周期
耗时任务在 QThread 中执行:
run()循环处理文件- 向 UI 发射总体进度与单文件进度
- 每个文件独立成功/失败计数,互不阻塞
调用流程:
_start()创建线程与 Worker- 绑定信号:log、progress、finished
worker_thread.start()开始后台执行
进度与日志设计
进度条
进度分两层:
- 当前文件进度:读取
file.tell()与文件大小比例 - 总体进度:按文件大小加权
日志
日志输出包含时间戳与异常堆栈:
timestamp()统一格式- 失败时记录 traceback
- 支持导出为文本文件
异常处理与容错策略
异常处理贯穿拆分流程:
- 编码错误
UnicodeDecodeError - 列名缺失
ValueError - 磁盘空间不足
OSError+ errno.ENOSPC
设计要点:
- 单文件失败不影响其他文件
- 失败信息写入日志并弹窗提示
- 失败数在任务结束汇总
性能与内存控制
针对 1GB 大文件设计要点:
csv.reader流式读取,行级处理- 输出文件使用
WriterCache限制句柄数量 - 不缓存整文件或整列内容
内存占用主要来自:
- 现有行字符串对象
- 已打开的输出句柄
- GUI 层的日志与列表
对于“按唯一列值”的模式,如果唯一值极多:
- 可适当降低
max_open_files - 采用“跳过已存在文件”减少 IO
源代码
'''
作者:小庄-Python办公
公众号:小庄-Python学习
'''
import sys
import os
import csv
import traceback
import errno
from dataclasses import dataclass, field
from datetime import datetime
from typing import Callable, Dict, List, Optional, Tuple
from PyQt5.QtCore import Qt, QObject, pyqtSignal, QThread
from PyQt5.QtGui import QFont
from PyQt5.QtWidgets import (
QApplication,
QMainWindow,
QWidget,
QFileDialog,
QListWidget,
QListWidgetItem,
QVBoxLayout,
QHBoxLayout,
QLabel,
QPushButton,
QRadioButton,
QButtonGroup,
QStackedWidget,
QGroupBox,
QLineEdit,
QSpinBox,
QComboBox,
QCheckBox,
QTextEdit,
QMessageBox,
QProgressBar,
)
def timestamp() -> str:
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def sanitize_filename(value: str) -> str:
if value is None:
value = ""
value = str(value).strip()
if not value:
value = "EMPTY"
for ch in ['\\', '/', ':', '*', '?', '"', '<', '>', '|']:
value = value.replace(ch, "_")
value = value.replace("\n", "_").replace("\r", "_").replace("\t", "_")
value = value.strip(" .")
if not value:
value = "EMPTY"
if len(value) > 120:
value = value[:120]
return value
def format_sequence(seq: int, pattern: str) -> str:
if "{" in pattern and "}" in pattern:
return pattern.format(seq)
width = max(1, len(pattern))
return str(seq).zfill(width)
def ensure_dir(path: str) -> None:
if not os.path.isdir(path):
os.makedirs(path, exist_ok=True)
@dataclass
class SplitSettings:
mode: str
row_mode: str
rows_per_file: int
unique_column: str
col_column: str
col_secondary_split: bool
col_secondary_rows: int
prefix: str
suffix: str
seq_format: str
keep_header: bool
delimiter: str
encoding: str
output_dir: str
on_exists: str
max_open_files: int = 64
@dataclass
class FileResult:
file_path: str
success: bool
created_files: List[str] = field(default_factory=list)
skipped_files: List[str] = field(default_factory=list)
error_message: str = ""
exception: Optional[Exception] = None
traceback_text: str = ""
def read_header(file_path: str, encoding: str, delimiter: str) -> List[str]:
with open(file_path, "r", newline="", encoding=encoding) as f:
reader = csv.reader(f, delimiter=delimiter)
return next(reader, [])
class WriterCache:
def __init__(self, max_open: int, created_set: set):
self.max_open = max_open
self._order: List[str] = []
self._writers: Dict[str, Tuple[object, csv.writer]] = {}
self._created_set = created_set
def get_writer(self, key: str, file_path: str, encoding: str, delimiter: str, header: Optional[List[str]], on_exists: str, created_files: List[str], skipped_files: List[str]) -> Optional[csv.writer]:
if key in self._writers:
if key in self._order:
self._order.remove(key)
self._order.append(key)
return self._writers[key][1]
file_exists = os.path.exists(file_path)
if file_exists and file_path not in self._created_set and on_exists == "skip":
skipped_files.append(file_path)
return None
ensure_dir(os.path.dirname(file_path))
if file_exists and file_path in self._created_set:
mode = "a"
header_to_write = None
else:
mode = "w"
header_to_write = header
self._created_set.add(file_path)
created_files.append(file_path)
f = open(file_path, mode, newline="", encoding=encoding)
writer = csv.writer(f, delimiter=delimiter)
if header_to_write:
writer.writerow(header_to_write)
self._writers[key] = (f, writer)
self._order.append(key)
while len(self._order) > self.max_open:
evict_key = self._order.pop(0)
handle, _ = self._writers.pop(evict_key)
try:
handle.close()
except Exception:
pass
return writer
def close_all(self) -> None:
for handle, _ in self._writers.values():
try:
handle.close()
except Exception:
pass
self._writers.clear()
self._order.clear()
def split_csv_file(
file_path: str,
settings: SplitSettings,
log_cb: Callable[[str], None],
progress_cb: Callable[[float], None],
cancel_cb: Callable[[], bool],
) -> FileResult:
result = FileResult(file_path=file_path, success=True)
file_size = os.path.getsize(file_path) if os.path.exists(file_path) else 0
file_size = max(1, file_size)
def update_progress(file_obj) -> None:
try:
ratio = min(1.0, file_obj.tell() / file_size)
progress_cb(ratio)
except Exception:
pass
try:
with open(file_path, "r", newline="", encoding=settings.encoding) as f:
reader = csv.reader(f, delimiter=settings.delimiter)
header = next(reader, None)
if header is None:
return result
header_row = header if settings.keep_header else None
created_set: set = set()
if settings.mode == "row":
if settings.row_mode == "fixed":
seq = 1
count = 0
row_index = 0
writer = None
handle = None
for row in reader:
if cancel_cb():
result.success = False
result.error_message = "用户取消"
break
if count == 0:
seq_text = format_sequence(seq, settings.seq_format)
filename = f"{settings.prefix}{seq_text}{settings.suffix}.csv"
out_file = os.path.join(settings.output_dir, filename)
if os.path.exists(out_file) and settings.on_exists == "skip":
result.skipped_files.append(out_file)
writer = None
handle = None
else:
ensure_dir(settings.output_dir)
handle = open(out_file, "w", newline="", encoding=settings.encoding)
writer = csv.writer(handle, delimiter=settings.delimiter)
if header_row:
writer.writerow(header_row)
result.created_files.append(out_file)
seq += 1
if writer:
writer.writerow(row)
count += 1
row_index += 1
if count >= settings.rows_per_file:
count = 0
if handle:
try:
handle.close()
except Exception:
pass
writer = None
handle = None
if row_index % 2000 == 0:
update_progress(f)
if handle:
try:
handle.close()
except Exception:
pass
update_progress(f)
else:
if settings.unique_column not in header:
raise ValueError(f"列名不存在: {settings.unique_column}")
col_index = header.index(settings.unique_column)
cache = WriterCache(settings.max_open_files, created_set)
skipped_values: set = set()
for row in reader:
if cancel_cb():
result.success = False
result.error_message = "用户取消"
break
key = sanitize_filename(row[col_index] if col_index < len(row) else "")
if key in skipped_values:
continue
filename = f"{settings.prefix}{key}{settings.suffix}.csv"
out_file = os.path.join(settings.output_dir, filename)
writer = cache.get_writer(key, out_file, settings.encoding, settings.delimiter, header_row, settings.on_exists, result.created_files, result.skipped_files)
if writer is None:
skipped_values.add(key)
continue
writer.writerow(row)
if len(result.created_files) % 100 == 0:
update_progress(f)
cache.close_all()
update_progress(f)
else:
if settings.col_column not in header:
raise ValueError(f"列名不存在: {settings.col_column}")
col_index = header.index(settings.col_column)
cache = WriterCache(settings.max_open_files, created_set)
value_state: Dict[str, Dict[str, int]] = {}
skipped_values: set = set()
for row in reader:
if cancel_cb():
result.success = False
result.error_message = "用户取消"
break
value = sanitize_filename(row[col_index] if col_index < len(row) else "")
if value in skipped_values:
continue
if settings.col_secondary_split:
state = value_state.setdefault(value, {"seq": 1, "count": 0})
if state["count"] == 0:
seq_text = format_sequence(state["seq"], settings.seq_format)
filename = f"{settings.prefix}{value}_{seq_text}{settings.suffix}.csv"
out_file = os.path.join(settings.output_dir, filename)
writer = cache.get_writer(f"{value}:{state['seq']}", out_file, settings.encoding, settings.delimiter, header_row, settings.on_exists, result.created_files, result.skipped_files)
if writer is None:
skipped_values.add(value)
continue
state["seq"] += 1
else:
writer = cache.get_writer(f"{value}:{state['seq']-1}", os.path.join(settings.output_dir, f"{settings.prefix}{value}_{format_sequence(state['seq']-1, settings.seq_format)}{settings.suffix}.csv"), settings.encoding, settings.delimiter, None, settings.on_exists, result.created_files, result.skipped_files)
if writer:
writer.writerow(row)
state["count"] += 1
if state["count"] >= settings.col_secondary_rows:
state["count"] = 0
else:
filename = f"{settings.prefix}{value}{settings.suffix}.csv"
out_file = os.path.join(settings.output_dir, filename)
writer = cache.get_writer(value, out_file, settings.encoding, settings.delimiter, header_row, settings.on_exists, result.created_files, result.skipped_files)
if writer is None:
skipped_values.add(value)
continue
writer.writerow(row)
if len(result.created_files) % 100 == 0:
update_progress(f)
cache.close_all()
update_progress(f)
except UnicodeDecodeError as e:
result.success = False
result.error_message = f"编码错误: {e}"
result.exception = e
result.traceback_text = traceback.format_exc()
except Exception as e:
result.success = False
result.error_message = str(e)
result.exception = e
result.traceback_text = traceback.format_exc()
if result.exception and isinstance(result.exception, OSError) and getattr(result.exception, "errno", None) == errno.ENOSPC:
log_cb(f"{timestamp()} 磁盘空间不足: {result.exception}")
return result
class Worker(QObject):
overall_progress = pyqtSignal(int)
file_progress = pyqtSignal(int)
log = pyqtSignal(str)
finished = pyqtSignal(dict)
show_error = pyqtSignal(str, str)
def __init__(self, files: List[str], settings: SplitSettings):
super().__init__()
self.files = files
self.settings = settings
self._cancel = False
self._created_files: List[str] = []
def cancel(self) -> None:
self._cancel = True
def _is_cancelled(self) -> bool:
return self._cancel
def run(self) -> None:
total_size = sum(max(1, os.path.getsize(p)) for p in self.files)
processed_size = 0
success_count = 0
fail_count = 0
for file_path in self.files:
if self._cancel:
break
file_size = max(1, os.path.getsize(file_path))
self.log.emit(f"{timestamp()} 开始处理: {file_path}")
def log_cb(msg: str) -> None:
self.log.emit(msg)
def progress_cb(ratio: float) -> None:
self.file_progress.emit(int(ratio * 100))
overall_ratio = min(1.0, (processed_size + ratio * file_size) / total_size)
self.overall_progress.emit(int(overall_ratio * 100))
result = split_csv_file(file_path, self.settings, log_cb, progress_cb, self._is_cancelled)
self._created_files.extend(result.created_files)
if result.success:
success_count += 1
self.log.emit(f"{timestamp()} 完成: {file_path} 输出 {len(result.created_files)} 个文件")
else:
fail_count += 1
detail = result.error_message
if result.traceback_text:
detail = f"{result.error_message}\n{result.traceback_text}"
self.log.emit(f"{timestamp()} 失败: {file_path}\n{detail}")
if isinstance(result.exception, OSError) and getattr(result.exception, "errno", None) == errno.ENOSPC:
self.show_error.emit("磁盘空间不足", detail)
processed_size += file_size
self.file_progress.emit(100)
self.overall_progress.emit(int(min(1.0, processed_size / total_size) * 100))
summary = {
"success": success_count,
"failed": fail_count,
"cancelled": self._cancel,
}
if self._cancel:
for path in self._created_files:
try:
if os.path.exists(path):
os.remove(path)
except Exception:
pass
self.finished.emit(summary)
class FileListWidget(QListWidget):
def __init__(self):
super().__init__()
self.setSelectionMode(QListWidget.ExtendedSelection)
self.setAcceptDrops(True)
def dragEnterEvent(self, event):
if event.mimeData().hasUrls():
event.acceptProposedAction()
else:
super().dragEnterEvent(event)
def dropEvent(self, event):
if event.mimeData().hasUrls():
for url in event.mimeData().urls():
path = url.toLocalFile()
if path and path.lower().endswith(".csv"):
self.add_file(path)
event.acceptProposedAction()
else:
super().dropEvent(event)
def add_file(self, path: str) -> None:
for i in range(self.count()):
if self.item(i).text() == path:
return
self.addItem(QListWidgetItem(path))
def files(self) -> List[str]:
return [self.item(i).text() for i in range(self.count())]
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("CSV 拆分工具 作者:小庄-Python办公")
self.resize(1000, 720)
self.file_list = FileListWidget()
self.add_btn = QPushButton("添加文件")
self.remove_btn = QPushButton("移除选中")
self.clear_btn = QPushButton("清空列表")
self.mode_row = QRadioButton("按行拆分")
self.mode_col = QRadioButton("按列拆分")
self.mode_row.setChecked(True)
self.mode_group = QButtonGroup()
self.mode_group.addButton(self.mode_row)
self.mode_group.addButton(self.mode_col)
self.stack = QStackedWidget()
self.row_panel = self._build_row_panel()
self.col_panel = self._build_col_panel()
self.stack.addWidget(self.row_panel)
self.stack.addWidget(self.col_panel)
self.prefix_input = QLineEdit("part_")
self.suffix_input = QLineEdit("")
self.seq_input = QLineEdit("0001")
self.keep_header = QCheckBox("保留表头")
self.keep_header.setChecked(True)
self.output_dir_input = QLineEdit("")
self.output_browse_btn = QPushButton("选择输出目录")
self.delimiter_combo = QComboBox()
self.delimiter_combo.addItems([",", ";", "\\t", "|"])
self.encoding_combo = QComboBox()
self.encoding_combo.addItems(["UTF-8", "UTF-8-sig", "GBK"])
self.exists_overwrite = QRadioButton("覆盖")
self.exists_skip = QRadioButton("跳过")
self.exists_overwrite.setChecked(True)
self.start_btn = QPushButton("开始")
self.cancel_btn = QPushButton("取消")
self.cancel_btn.setEnabled(False)
self.export_log_btn = QPushButton("导出日志")
self.total_progress = QProgressBar()
self.file_progress = QProgressBar()
self.log_text = QTextEdit()
self.log_text.setReadOnly(True)
self.log_text.setFont(QFont("Consolas", 10))
layout = QVBoxLayout()
layout.addWidget(self._build_files_group())
layout.addWidget(self._build_mode_group())
layout.addWidget(self._build_naming_group())
layout.addWidget(self._build_output_group())
layout.addWidget(self._build_progress_group())
layout.addWidget(self._build_log_group())
container = QWidget()
container.setLayout(layout)
self.setCentralWidget(container)
self.add_btn.clicked.connect(self._add_files)
self.remove_btn.clicked.connect(self._remove_selected)
self.clear_btn.clicked.connect(self.file_list.clear)
self.mode_row.toggled.connect(self._switch_mode)
self.mode_col.toggled.connect(self._switch_mode)
self.output_browse_btn.clicked.connect(self._choose_output_dir)
self.start_btn.clicked.connect(self._start)
self.cancel_btn.clicked.connect(self._cancel)
self.export_log_btn.clicked.connect(self._export_log)
self.delimiter_combo.currentIndexChanged.connect(self._refresh_headers)
self.encoding_combo.currentIndexChanged.connect(self._refresh_headers)
self.file_list.itemSelectionChanged.connect(self._refresh_headers)
self.worker_thread: Optional[QThread] = None
self.worker: Optional[Worker] = None
def _build_files_group(self) -> QGroupBox:
group = QGroupBox("文件选择")
layout = QVBoxLayout()
btn_layout = QHBoxLayout()
btn_layout.addWidget(self.add_btn)
btn_layout.addWidget(self.remove_btn)
btn_layout.addWidget(self.clear_btn)
layout.addLayout(btn_layout)
layout.addWidget(self.file_list)
group.setLayout(layout)
return group
def _build_mode_group(self) -> QGroupBox:
group = QGroupBox("拆分模式")
layout = QVBoxLayout()
mode_layout = QHBoxLayout()
mode_layout.addWidget(self.mode_row)
mode_layout.addWidget(self.mode_col)
layout.addLayout(mode_layout)
layout.addWidget(self.stack)
group.setLayout(layout)
return group
def _build_row_panel(self) -> QWidget:
panel = QWidget()
layout = QVBoxLayout()
self.row_fixed = QRadioButton("按固定行数")
self.row_unique = QRadioButton("按唯一列值")
self.row_fixed.setChecked(True)
self.row_group = QButtonGroup()
self.row_group.addButton(self.row_fixed)
self.row_group.addButton(self.row_unique)
row_mode_layout = QHBoxLayout()
row_mode_layout.addWidget(self.row_fixed)
row_mode_layout.addWidget(self.row_unique)
layout.addLayout(row_mode_layout)
fixed_layout = QHBoxLayout()
fixed_layout.addWidget(QLabel("每文件行数"))
self.rows_per_file = QSpinBox()
self.rows_per_file.setRange(1, 10_000_000)
self.rows_per_file.setValue(100000)
fixed_layout.addWidget(self.rows_per_file)
layout.addLayout(fixed_layout)
unique_layout = QHBoxLayout()
unique_layout.addWidget(QLabel("列名"))
self.row_unique_column = QComboBox()
unique_layout.addWidget(self.row_unique_column)
layout.addLayout(unique_layout)
panel.setLayout(layout)
return panel
def _build_col_panel(self) -> QWidget:
panel = QWidget()
layout = QVBoxLayout()
col_layout = QHBoxLayout()
col_layout.addWidget(QLabel("列名"))
self.col_column = QComboBox()
col_layout.addWidget(self.col_column)
layout.addLayout(col_layout)
split_layout = QHBoxLayout()
self.col_secondary = QCheckBox("每子文件再按行数拆分")
split_layout.addWidget(self.col_secondary)
split_layout.addWidget(QLabel("行数"))
self.col_secondary_rows = QSpinBox()
self.col_secondary_rows.setRange(1, 10_000_000)
self.col_secondary_rows.setValue(100000)
split_layout.addWidget(self.col_secondary_rows)
layout.addLayout(split_layout)
panel.setLayout(layout)
return panel
def _build_naming_group(self) -> QGroupBox:
group = QGroupBox("命名规则")
layout = QVBoxLayout()
row1 = QHBoxLayout()
row1.addWidget(QLabel("前缀"))
row1.addWidget(self.prefix_input)
row1.addWidget(QLabel("后缀"))
row1.addWidget(self.suffix_input)
layout.addLayout(row1)
row2 = QHBoxLayout()
row2.addWidget(QLabel("序号格式"))
row2.addWidget(self.seq_input)
row2.addWidget(self.keep_header)
layout.addLayout(row2)
group.setLayout(layout)
return group
def _build_output_group(self) -> QGroupBox:
group = QGroupBox("输出配置")
layout = QVBoxLayout()
row1 = QHBoxLayout()
row1.addWidget(QLabel("输出目录"))
row1.addWidget(self.output_dir_input)
row1.addWidget(self.output_browse_btn)
layout.addLayout(row1)
row2 = QHBoxLayout()
row2.addWidget(QLabel("分隔符"))
row2.addWidget(self.delimiter_combo)
row2.addWidget(QLabel("编码"))
row2.addWidget(self.encoding_combo)
layout.addLayout(row2)
row3 = QHBoxLayout()
row3.addWidget(QLabel("已存在文件"))
row3.addWidget(self.exists_overwrite)
row3.addWidget(self.exists_skip)
layout.addLayout(row3)
group.setLayout(layout)
return group
def _build_progress_group(self) -> QGroupBox:
group = QGroupBox("进度")
layout = QVBoxLayout()
layout.addWidget(QLabel("总体进度"))
layout.addWidget(self.total_progress)
layout.addWidget(QLabel("当前文件进度"))
layout.addWidget(self.file_progress)
row = QHBoxLayout()
row.addWidget(self.start_btn)
row.addWidget(self.cancel_btn)
row.addWidget(self.export_log_btn)
layout.addLayout(row)
group.setLayout(layout)
return group
def _build_log_group(self) -> QGroupBox:
group = QGroupBox("日志")
layout = QVBoxLayout()
layout.addWidget(self.log_text)
group.setLayout(layout)
return group
def _switch_mode(self) -> None:
self.stack.setCurrentIndex(0 if self.mode_row.isChecked() else 1)
def _add_files(self) -> None:
files, _ = QFileDialog.getOpenFileNames(self, "选择 CSV 文件", "", "CSV Files (*.csv)")
for path in files:
self.file_list.add_file(path)
self._refresh_headers()
def _remove_selected(self) -> None:
for item in self.file_list.selectedItems():
row = self.file_list.row(item)
self.file_list.takeItem(row)
self._refresh_headers()
def _choose_output_dir(self) -> None:
path = QFileDialog.getExistingDirectory(self, "选择输出目录")
if path:
self.output_dir_input.setText(path)
def _delimiter_value(self) -> str:
text = self.delimiter_combo.currentText()
return "\t" if text == "\\t" else text
def _refresh_headers(self) -> None:
files = self.file_list.files()
if not files:
self.row_unique_column.clear()
self.col_column.clear()
return
path = files[0]
try:
header = read_header(path, self.encoding_combo.currentText(), self._delimiter_value())
self.row_unique_column.clear()
self.col_column.clear()
self.row_unique_column.addItems(header)
self.col_column.addItems(header)
except Exception as e:
self.log_text.append(f"{timestamp()} 读取表头失败: {e}")
self.row_unique_column.clear()
self.col_column.clear()
def _build_settings(self) -> Optional[SplitSettings]:
files = self.file_list.files()
if not files:
QMessageBox.warning(self, "提示", "请先选择 CSV 文件")
return None
output_dir = self.output_dir_input.text().strip()
if not output_dir:
QMessageBox.warning(self, "提示", "请指定输出目录")
return None
delimiter = self._delimiter_value()
encoding = self.encoding_combo.currentText()
on_exists = "overwrite" if self.exists_overwrite.isChecked() else "skip"
mode = "row" if self.mode_row.isChecked() else "col"
row_mode = "fixed" if self.row_fixed.isChecked() else "unique"
settings = SplitSettings(
mode=mode,
row_mode=row_mode,
rows_per_file=self.rows_per_file.value(),
unique_column=self.row_unique_column.currentText(),
col_column=self.col_column.currentText(),
col_secondary_split=self.col_secondary.isChecked(),
col_secondary_rows=self.col_secondary_rows.value(),
prefix=self.prefix_input.text(),
suffix=self.suffix_input.text(),
seq_format=self.seq_input.text() or "0001",
keep_header=self.keep_header.isChecked(),
delimiter=delimiter,
encoding=encoding,
output_dir=output_dir,
on_exists=on_exists,
)
return settings
def _start(self) -> None:
settings = self._build_settings()
if not settings:
return
files = self.file_list.files()
ensure_dir(settings.output_dir)
self.total_progress.setValue(0)
self.file_progress.setValue(0)
self.start_btn.setEnabled(False)
self.cancel_btn.setEnabled(True)
self.log_text.append(f"{timestamp()} 任务开始,文件数: {len(files)}")
self.worker_thread = QThread()
self.worker = Worker(files, settings)
self.worker.moveToThread(self.worker_thread)
self.worker_thread.started.connect(self.worker.run)
self.worker.log.connect(self.log_text.append)
self.worker.file_progress.connect(self.file_progress.setValue)
self.worker.overall_progress.connect(self.total_progress.setValue)
self.worker.finished.connect(self._finish)
self.worker.show_error.connect(self._show_error)
self.worker_thread.start()
def _finish(self, summary: dict) -> None:
if self.worker_thread:
self.worker_thread.quit()
self.worker_thread.wait()
self.start_btn.setEnabled(True)
self.cancel_btn.setEnabled(False)
if summary.get("cancelled"):
QMessageBox.information(self, "已取消", "任务已取消,临时文件已清理")
else:
QMessageBox.information(
self,
"完成",
f"成功: {summary.get('success', 0)},失败: {summary.get('failed', 0)}",
)
def _cancel(self) -> None:
if self.worker:
self.worker.cancel()
self.log_text.append(f"{timestamp()} 用户取消任务")
self.cancel_btn.setEnabled(False)
def _show_error(self, title: str, detail: str) -> None:
QMessageBox.critical(self, title, detail)
def _export_log(self) -> None:
path, _ = QFileDialog.getSaveFileName(self, "导出日志", "log.txt", "Text Files (*.txt)")
if not path:
return
try:
with open(path, "w", encoding="utf-8") as f:
f.write(self.log_text.toPlainText())
QMessageBox.information(self, "成功", "日志已导出")
except Exception as e:
QMessageBox.critical(self, "失败", str(e))
def main() -> None:
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())
if __name__ == "__main__":
main()可扩展方向
如果继续增强,可考虑:
- 增加“预览前 N 行”功能
- 支持保存与加载配置
- 增加“输出文件压缩”为 zip
- 提供“拆分后统计报表”
结语
这个工具的核心理念是“稳定、低内存、高可用”。通过标准库 csv 与 PyQt5 的组合,达成了性能与交互的平衡,并保持项目结构简单、易维护。对于日常办公与大规模数据拆分,已具备可直接使用的工程级质量。
以上就是Python实现批量将CSV按行或按列拆分的详细内容,更多关于Python拆分CSV的资料请关注脚本之家其它相关文章!