
入门初学者短期内快速掌握Python的经典全面教程(专家学习笔记)
作者:张彦峰ZYF
本博客将自己初步学习Python过程中的阶段性整理与沉淀。难免存在理解不够严谨或表述不够完善之处,欢迎各位读者在评论区留言指正、交流探讨,这对我和后续读者都会非常有价值。
同时说明一下:从当前基础学习和实践验证来看,当前准备的这些分享内容,确实是可以在一天半的时间内就可以快速学习完成并可以理解的,希望对我们彼此都有所收获!!!
一、快速了解 Python 和 环境准备
(一)Python 快速介绍
Python 是一种 简洁、强大、易读 的编程语言,广泛应用于 Web 开发、数据分析、人工智能、自动化运维 等领域。它由 Guido van Rossum 在 1991 年设计,因其清晰的语法和强大的生态系统,迅速成为全球最受欢迎的编程语言之一。
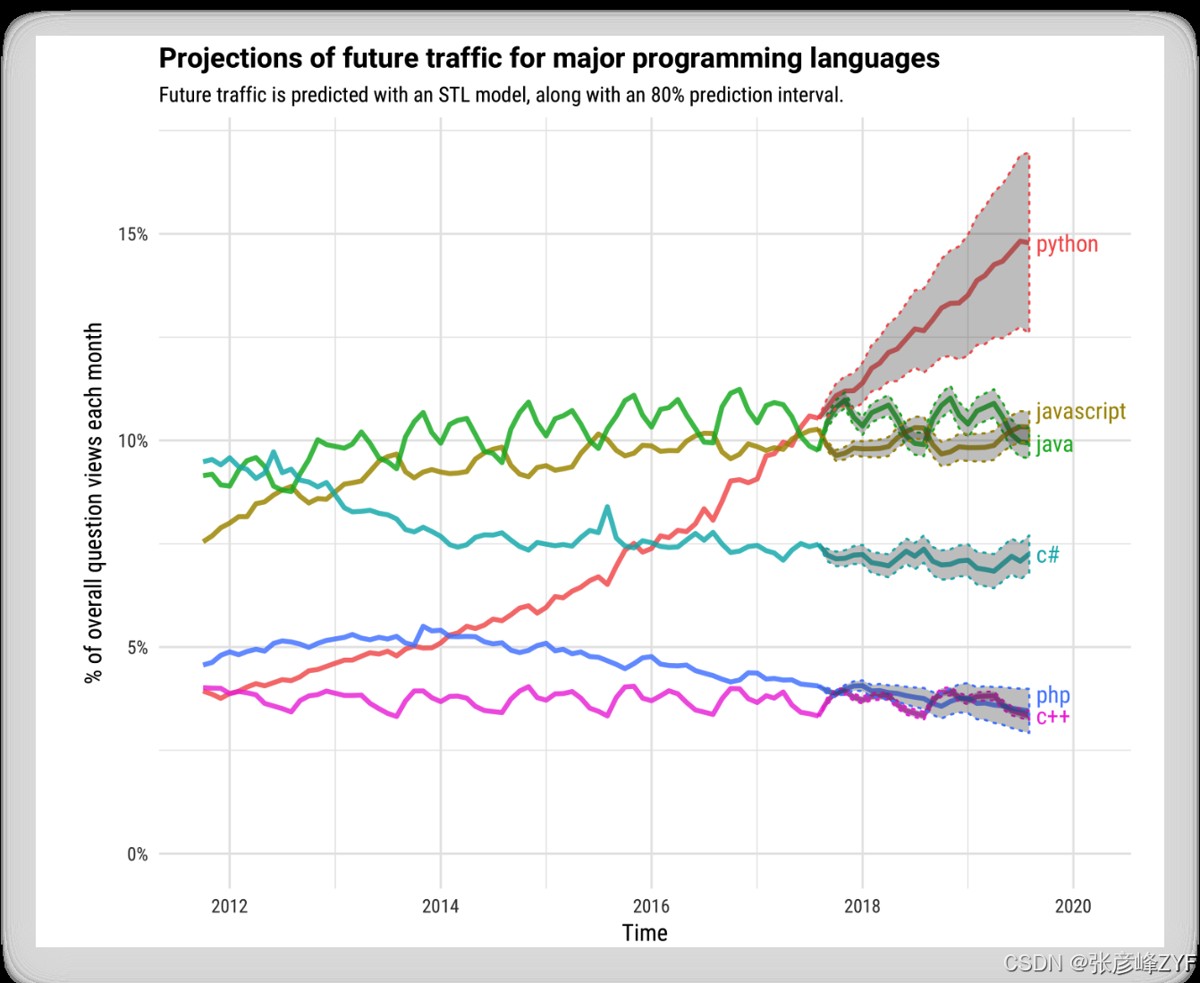
在 2017 年底,Stack Overflow 发布的数据显示,Python 已经超越 JavaScript 成为了该平台上提问流量最多的编程语言。
(二)Jupyter Notebook:从梦想到行业标配
Jupyter Notebook 的诞生源于创始人 Fernando Pérez一个大胆的想法:打造一个能整合 Julia(Ju)、Python(Py)和 R(ter) 这三种科学计算语言的通用计算平台。但目前Jupyter 早已超越最初的设想,成为一个支持几乎所有编程语言的多功能计算环境。
从 2017 年起,北美顶尖高校纷纷全面拥抱 Jupyter Notebook:
- 学术界:斯坦福的 CS231N《计算机视觉与神经网络》 课程2017 年便完全迁移到 Jupyter Notebook、UC Berkeley 的 《数据科学基础》 课程也在同年改用 Jupyter 作为唯一的作业平台。
- 工业界: Facebook尽管大型后端开发仍依赖传统 IDE,但几乎所有 内部分析、机器学习训练和数据探索 都基于 Jupyter Notebook 运行。同时 Google 的 AI Research 部门 Google Brain,也是清一色地全部使用 Jupyter Notebook(改进定制版,叫 Google Colab)。
(三)Mac 上安装 Python 和 Jupyter Notebook 的步骤
| 步骤 | 命令 | 说明 |
|---|---|---|
| 1. 安装 Homebrew | /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" | Mac 的包管理工具(如果未安装) |
| 2. 安装 Python 3 | brew install python | 安装最新的 Python 3 |
| 3. 验证 Python 版本 | python3 --version | 确保安装成功,显示 Python 3.x.x |
| 4. 安装 Jupyter Notebook | pip3 install jupyter | 通过 pip3 安装 Jupyter |
| 5. 检查 Jupyter 是否可用 | jupyter --version | 确保 Jupyter 已正确安装 |
| 6. 启动 Jupyter Notebook | jupyter notebook | 打开 Jupyter Notebook,浏览器自动打开 |
这样,我们就可以在 Mac 上使用 Jupyter Notebook 进行 Python 开发了!
备注:
- 如果你不习惯也可以直接idea,毕竟这么多年习惯了java开发,我就是两个都安装了,无所谓!
- 如果不想安装也可以在线使用:Jupyter 官方在线工具
二、Python 基础:变量、数据类型与输入输出
Python 以其 简洁、易读 的语法受到欢迎,而理解变量、数据类型和输入输出是学习 Python 的第一步。这部分内容构成了 Python 编程的基石。这部分代码我写的时候都是直接在idea中,网络版本有时很慢。Jupyter 官方在线工具
(一)变量:数据的存储与引用
变量(Variable)是用于存储数据的容器,在 Python 中变量不需声明类型,直接赋值即可创建。
1. 变量的定义与赋值
x = 10 # 整数变量 name = "Alice" # 字符串变量 pi = 3.14159 # 浮点数变量 is_python_fun = True # 布尔变量
Python 是动态类型语言,变量的类型是根据赋值内容自动推导的。
2. 变量命名规则
变量名必须 以字母或下划线(_)开头,不能以数字开头。
变量名只能包含 字母、数字和下划线,不能包含空格或特殊符号。
变量名区分大小写(
age和Age是不同的变量)。推荐使用 小写字母+下划线(
snake_case)风格,如user_name,符合 Python 代码规范(PEP 8)。
示例:正确与错误的变量命名
valid_name = "OK" # 正确 _valid_123 = 42 # 正确 2nd_value = "wrong" # ❌ 错误:不能以数字开头 user-name = "error" # ❌ 错误:不能包含 `-`
(二)数据类型(Data Types)
Python 具有丰富的数据类型,主要包括:
| 数据类型 | 示例 | 说明 |
|---|---|---|
| 整数(int) | x = 42 | 存储整数,如 10, -5, 1000 |
| 浮点数(float) | pi = 3.14 | 存储小数,如 3.1415, -0.5 |
| 字符串(str) | name = "ZYF" | 存储文本,如 "hello" |
| 布尔值(bool) | is_valid = True | 只有 True 或 False |
| 列表(list) | nums = [1, 2, 3] | 有序可变的集合 |
| 元组(tuple) | colors = ('red', 'blue') | 有序不可变的集合 |
| 字典(dict) | person = {"name": "Alice", "age": 25} | 键值对存储 |
| 集合(set) | unique_nums = {1, 2, 3} | 无序不重复元素集合 |
Python 提供 type() 函数来查看变量的数据类型:
x = 42 print(type(x)) # 输出:<class 'int'>
Python 允许不同类型之间的转换:
age = "25" age = int(age) # 将字符串转换为整数 pi = 3.14 pi_str = str(pi) # 将浮点数转换为字符串
(三)输入与输出(Input & Output)
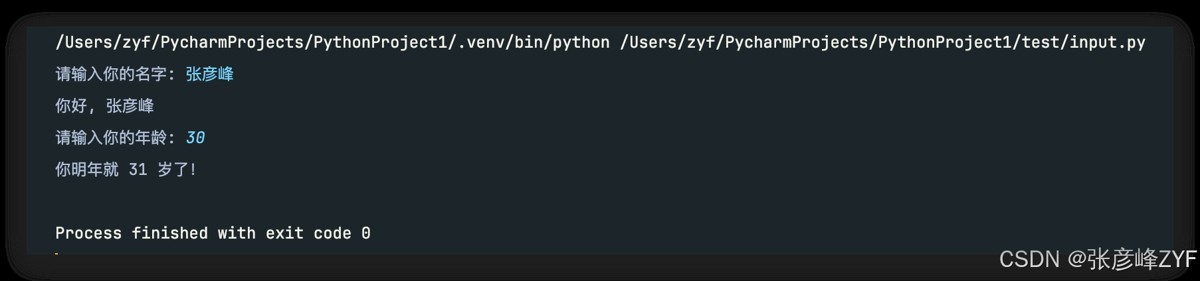
1. 标准输入(input)
input() 用于从用户获取输入,所有输入默认是 字符串类型:
name = input("请输入你的名字: ")
print("你好,", name)
如果需要数值类型,需要进行 类型转换:
age = int(input("请输入你的年龄: ")) # 输入默认是字符串,需要转换成整数
print("你明年就", age + 1, "岁了!")
基本验证:
2. 标准输出(print)
print() 用于向控制台输出内容:
name = "Alice"
age = 25
print("姓名:", name, "年龄:", age) # 多个参数用逗号分隔
格式化输出(推荐使用 f-string,Python 3.6+ 支持):
print(f"姓名: {name}, 年龄: {age}") # 推荐的写法✅ 小练习题
尝试自己编写代码练习以下问题:
定义一个变量
temperature,存储36.6,并使用print()输出"体温: 36.6 摄氏度"。编写一个程序,提示用户输入姓名和年龄,并打印
"你好,XX!你今年 YY 岁"(其中XX和YY由用户输入)。
Python 的变量、数据类型和输入输出构成了编程的基础,熟练掌握这些概念后,就可以进行更复杂的逻辑编写了!
三、控制流:让代码具备决策能力
在编程中,控制流 决定了代码的执行顺序,使程序能够做出决策(条件判断),或重复执行任务(循环)。通过 布尔值、逻辑运算、if 语句、for 和 while 循环,我们可以让 Python 代码变得更加智能和高效。这部分我会总结下这些关键概念,其是构建更具逻辑性程序的基础。
(一)布尔值与逻辑判断
在 Python 中,布尔值(Boolean) 是控制程序逻辑的基础。它用于 条件判断、循环控制和逻辑运算,让代码具备决策能力。
1. 布尔值(Boolean)
布尔值只有两个取值:
True # 代表 "真" False # 代表 "假"
布尔值本质上是整数的特殊形式,其中:
True == 1 # 结果为 True False == 0 # 结果为 True
布尔值的基本使用
is_python_fun = True is_raining = False print(is_python_fun) # 输出:True print(type(is_python_fun)) # 输出:<class 'bool'>
2. 比较运算符(Comparison Operators)
比较运算符用于比较两个值,返回 True 或 False。
| 运算符 | 含义 | 示例 | 结果 |
|---|---|---|---|
== | 等于 | 5 == 5 | True |
!= | 不等于 | 5 != 3 | True |
> | 大于 | 10 > 3 | True |
< | 小于 | 2 < 8 | True |
>= | 大于等于 | 5 >= 5 | True |
<= | 小于等于 | 3 <= 2 | False |
代码示例
a = 10 b = 5 print(a > b) # True print(a == b) # False print(a != b) # True
3. 布尔运算符(Boolean Operators)
Python 提供了 and、or 和 not 三种逻辑运算符,用于组合多个布尔表达式。
| 运算符 | 含义 | 示例 | 结果 |
|---|---|---|---|
and | 逻辑与(都为 True 时才为 True) | True and False | False |
or | 逻辑或(只要一个为 True 就是 True) | True or False | True |
not | 逻辑非(取反) | not True | False |
3.1and逻辑与
x = 5 y = 10 print(x > 0 and y > 5) # True,因为两个条件都成立 print(x > 0 and y < 5) # False,因第二个条件不成立
3.2or逻辑或
x = 5 y = 10 print(x > 0 or y < 5) # True,只要有一个条件为 True 即可 print(x < 0 or y < 5) # False,两个条件都为 False
3.3not逻辑非
is_python_fun = True print(not is_python_fun) # False,因为取反了
4. 混合布尔运算(优先级)
运算符的 优先级 从高到低依次为:not(最高)、and、or(最低)
知道黄晓明的“闹太套”英文梗,这里直接记成“闹安套”就好了
print(True or False and False) # 等价于 True or (False and False) → True or False → True print(not True or False) # 等价于 (not True) or False → False or False → False
5. 布尔值与其他数据类型的转换
在 Python 中,所有数据类型 都可以转换为布尔值:
以下情况视为
False:0(整数 0)0.0(浮点数 0)""(空字符串)[](空列表){}(空字典)None(特殊值,表示“空”)
其他情况均为
True。
5.1 使用bool()进行类型转换
print(bool(0)) # False
print(bool("")) # False
print(bool([])) # False
print(bool(42)) # True
print(bool("hello")) # True
5.2 在if语句中使用
name = "Alice"
if name: # 相当于 if bool(name) == True
print("名字有效")
else:
print("名字为空")
输出:
名字有效
✅ 小练习题
练习 1:布尔运算
判断以下表达式的结果:
True and False or Truenot (False or True)(10 > 5) and (3 != 3)
练习 2:用户输入比较
让用户输入两个数字,比较它们的大小,并输出 "第一个数字更大" 或 "第二个数字更大"。
# 提示:使用 input() 和 if 语句
布尔值和逻辑判断是 条件判断和循环 的基础,熟练掌握它们后,代码将更加智能化! 🚀
(二)🌟 条件判断(if语句)
在编程中,我们经常需要根据不同条件来执行不同的代码。这就要用到 条件判断语句(if statement)。Python 中使用 if、elif 和 else 关键字来实现条件分支。
1. 基本 if 语句
语法结构:
if 条件:
语句块
✅ 当“条件”为 True 时,语句块才会被执行。
示例:
age = 20
if age >= 18:
print("你已经成年了")
输出:
你已经成年了
2. if-else 结构(两分支选择)
用于处理“要么这样,要么那样”的情况。
语法结构:
if 条件:
语句块1
else:
语句块2
示例:
temperature = 15
if temperature > 20:
print("北京天气今天很暖和")
else:
print("北京天气今天有点冷")
输出:
北京天气今天有点冷
3. if-elif-else 结构(多分支选择)
用于处理多个条件判断的情况(相当于“多项选择”)。
语法结构:
if 条件1:
语句块1
elif 条件2:
语句块2
elif 条件3:
语句块3
else:
默认语句块
示例:
score = 85
if score >= 90:
print("优秀")
elif score >= 80:
print("良好")
elif score >= 60:
print("及格")
else:
print("不及格")
输出:
良好
💡
elif是 "else if" 的缩写。Python 中没有switch语句,if-elif-else是推荐的替代方案。
4. 嵌套 if 语句
嵌套 指的是在一个 if 块内部再写 if 判断。可以用来表示更复杂的逻辑结构。
示例:
age = 25
is_student = True
if age < 30:
if is_student:
print("你是年轻的学生")
else:
print("你是年轻的上班族")
输出:
你是年轻的学生
⚠️ 注意缩进层级,Python 是靠缩进来识别代码块的!
5. 条件表达式(三元运算符)
Python 支持一种简洁的写法:在一行中完成 if-else 判断。
语法:
变量 = 值1 if 条件 else 值2
示例:
age = 16 status = "成年" if age >= 18 else "未成年" print(status)
输出:
未成年
适合用于 根据条件选择一个值赋给变量 的情况。
小结一下吧
| 类型 | 场景示例 |
|---|---|
if | 只有一个条件 |
if-else | 两种可能,二选一 |
if-elif-else | 多种情况,依次判断 |
嵌套 if | 条件套条件,多层判断 |
| 三元表达式 | 简洁地赋值,适合一行判断 |
✅ 小练习题
练习 1:分数等级判断器
让用户输入一个 0~100 的整数,判断其属于哪个等级:
90 以上:优秀
80~89:良好
70~79:中等
60~69:及格
低于 60:不及格
其他情况提示“输入有误”
练习 2:三角形合法性判断
输入三条边的长度,判断是否能组成一个三角形(任意两边之和大于第三边),并进一步判断:
是等边三角形
是等腰三角形
是普通三角形
否则输出“不合法的三角形”
练习 3:模拟 ATM 登录与权限检查(嵌套)
假设用户名为
admin,密码为8888,登录成功后再检查是否为管理员(管理员输入"yes"才能继续操作)。
练习 4:三元运算小测试
输入一个数字,输出
"正数"、"负数"或"零",用三元运算符 实现。
(三)循环(Loops)
在编程中,我们常常需要重复执行某些操作,比如遍历列表、处理每一行数据、执行某个动作直到满足条件等等。Python 提供了两种主要的循环结构:while 循环和 for 循环,配合控制语句(如 break、continue)可以构建出丰富的循环逻辑。
1. while循环(基于条件重复执行)
✅ 基本语法
while 条件表达式:
循环体
每次循环前都会检查“条件表达式”的值;
条件为
True→ 执行循环体;条件为
False→ 结束循环。
🧪 示例:打印 1 到 5 的数字
i = 1
while i <= 5:
print(i)
i += 1
🔁break语句(提前终止循环)
break 用于立即跳出整个循环结构,不管循环条件是否还为 True。
i = 1
while True:
print(i)
if i == 3:
break
i += 1
输出:1, 2, 3,然后退出循环
🔁continue语句(跳过当前迭代)
continue 用于跳过本次循环中剩下的语句,直接进入下一次判断。
i = 0
while i < 5:
i += 1
if i == 3:
continue
print(i)
输出:1, 2, 4, 5(跳过了 3)
2.for循环(用于遍历序列)
✅ 基本语法
for 变量 in 可迭代对象:
循环体
可迭代对象包括:字符串、列表、字典、集合、元组等。
🔁 遍历字符串
for ch in "hello":
print(ch)
🔁 遍历列表
fruits = ['apple', 'banana', 'orange']
for fruit in fruits:
print(fruit)
🔁 遍历字典
info = {"name": "Tom", "age": 20}
for key in info:
print(key, "=>", info[key])
或使用 .items() 遍历键值对:
for key, value in info.items():
print(f"{key}: {value}")
🔁 遍历集合
s = {"apple", "banana", "cherry"}
for item in s:
print(item)
🔁range()函数与数值循环
for i in range(1, 6):
print(i)
range(n):0 到 n-1range(start, end):start 到 end-1range(start, end, step):按步长生成
🔁enumerate()结合索引遍历
想同时获取元素和下标时使用 enumerate():
colors = ['red', 'green', 'blue']
for index, color in enumerate(colors):
print(f"{index}: {color}")
3. 循环控制语句
✅break:提前终止整个循环
通常与 if 配合使用,用于在满足某个条件时立即退出循环。
for i in range(1, 10):
if i == 5:
break
print(i)
✅continue:跳过当前迭代
用于跳过某些不符合条件的值。
for i in range(1, 6):
if i % 2 == 0:
continue
print(i) # 输出 1 3 5(跳过偶数)
✅else语句在循环中的作用
else 可以与 for 或 while 循环一起使用:
当循环没有被
break中断时,else中的语句会执行。for i in range(1, 5): if i == 10: break else: print("未被 break,循环正常结束")这在处理搜索类问题时特别有用:
nums = [1, 3, 5, 7] target = 4 for num in nums: if num == target: print("找到目标") break else: print("未找到目标")
小结一下吧
| 循环类型 | 用途 | 特点 |
|---|---|---|
while | 条件控制循环 | 不确定次数时使用 |
for | 遍历序列 | 更简洁,适合固定结构 |
break | 跳出循环 | 终止整个循环体 |
continue | 跳过本次迭代 | 继续下一轮 |
else | 循环结构补充 | 仅在循环未被 break时执行 |
✅ 小练习题
🧪 练习题 1:打印 1~100 中所有能被 7 整除的数
🧪 练习题 2:使用while计算从 1 累加到 n 的和(n 由用户输入)
🧪 练习题 3:找出列表中第一个大于 50 的元素,并输出其值和索引
🧪 练习题 4:输出 1~30 中除了能被 3 整除的数(使用 continue)
🧪 练习题 5:统计一段字符串中元音字母的个数(不区分大小写)
🧪 练习题 6:使用for和else实现一个猜数字小游戏
四、函数与相关基础知识:让代码会“思考”的魔法工具
在编程的世界里,函数就像是程序的“积木”:它们能把一段可复用的操作封装起来,想用就调用,修改也方便,堪称优雅代码的起点。
无论是打印一行文字,计算一个数列的和,还是训练一个 AI 模型,本质上你做的都是“定义功能 + 调用功能” —— 这正是函数的使命。
(一)函数基础
1. 什么是函数?为什么要使用函数?
在编程中,函数是一个非常重要的概念,它可以被理解为“功能块”,用来封装一段代码,供其他地方调用。通过函数,开发者可以:
提高代码复用性:避免重复写相同的代码,简化开发和维护。
增强可读性:将复杂的任务拆解成小的、独立的单元,便于理解。
分隔逻辑:函数让代码的逻辑结构更加清晰和模块化,有助于团队协作开发。
例如,我们可以定义一个函数来计算两个数字的和,而不需要每次都重复写加法的操作。只要定义一次,后续就可以随时调用。
2. 使用def定义函数
在 Python 中,函数是通过 def 关键字来定义的。它的基本语法如下:
def function_name(parameters):
# 函数体
return result
def是 Python 中定义函数的关键字function_name是你给函数命名的名称,符合命名规则parameters是函数的输入(可以没有)return是返回结果的关键字(如果不返回任何值,则默认为None)
示例:一个简单的加法函数
def add(a, b):
return a + b
# 调用函数
result = add(3, 5)
print(result) # 输出: 8
这里我们定义了一个 add 函数,输入参数是 a 和 b,它们会被加在一起并返回结果。
3. 函数的调用和执行流程
定义函数后,调用函数就能执行该函数的代码。Python 会根据函数调用的顺序进入函数体,并执行其中的代码。
当函数被调用时,程序会暂停当前位置,跳转到函数体执行代码,直到遇到
return语句(或者函数执行完毕)才返回。如果没有
return语句,则返回None。
示例:简单的函数调用与返回值
def greet(name):
return f"Hello, {name}!"
message = greet("Alice")
print(message) # 输出: Hello, Alice!
这里的 greet 函数通过 return 语句返回了一个字符串,调用时传入了参数 "Alice",最终返回 "Hello, Alice!"。
4.print()与return的区别与使用场景
在 Python 中,print() 和 return 都用于输出数据,但它们有显著的不同:
print()用于将信息输出到控制台,主要用于调试、输出中间结果或与用户交互。return用于函数的输出,它将值返回给调用者,可以被其他代码再次使用。
示例:print()和return对比
# 使用 print()
def greet_print(name):
print(f"Hello, {name}!")
greet_print("Alice") # 输出: Hello, Alice!
# 使用 return
def greet_return(name):
return f"Hello, {name}!"
message = greet_return("Alice")
print(message) # 输出: Hello, Alice!
greet_print使用print()输出值,但无法把它传递给其他部分的代码。greet_return使用return返回结果,这个返回值可以在代码的其他地方使用或存储。
小结一下吧
函数是代码复用、模块化的核心工具。
使用
def定义函数,return返回值。print()用于输出调试信息,return用于返回计算结果。
(二)函数参数
函数参数是函数接收外部输入的方式。理解和掌握函数参数的使用,不仅能帮助你编写更灵活的代码,还能让你的程序更具扩展性和可维护性。
1. 位置参数
位置参数是最常见的函数参数类型,它是指参数传递时位置的顺序决定了每个参数的含义。
例如,在函数定义时,参数 a 和 b 的位置决定了它们的意义。当调用函数时,传递的参数值会根据位置匹配到相应的参数。
示例:位置参数
def add(a, b):
return a + b
result = add(3, 5) # 位置参数:3 被赋值给 a,5 被赋值给 b
print(result) # 输出: 8
这里的 add 函数有两个位置参数:a 和 b。我们调用 add(3, 5) 时,3 会赋值给 a,5 会赋值给 b,最终返回它们的和。
2. 关键字参数
关键字参数允许你在调用函数时显式地指定每个参数的名称。这样可以不关心参数的顺序,只需要知道参数名。
示例:关键字参数
def greet(name, age):
return f"Hello, {name}! You are {age} years old."
message = greet(age=25, name="Alice") # 参数顺序不重要
print(message) # 输出: Hello, Alice! You are 25 years old.
在调用 greet 函数时,age 和 name 的顺序不再重要,关键字参数通过指定 age=25 和 name="Alice" 来传递值。
3. 默认参数
默认参数是指在定义函数时,为某些参数提供默认值。如果调用时没有提供这些参数的值,Python 会使用默认值。
示例:默认参数
def greet(name, age=18): # age 有默认值
return f"Hello, {name}! You are {age} years old."
message1 = greet("Alice") # 调用时没有提供 age,使用默认值
message2 = greet("Bob", 30) # 调用时提供了 age,覆盖默认值
print(message1) # 输出: Hello, Alice! You are 18 years old.
print(message2) # 输出: Hello, Bob! You are 30 years old.
在 greet 函数中,age 有默认值 18。如果调用时没有传入 age,就会使用默认值;如果传入了 age,则会覆盖默认值。
4. 可变参数:*args与**kwargs
有时候我们不知道函数需要接收多少个参数,这时可以使用 可变参数。
*args用于接收位置参数,它将接收多余的位置参数并将其打包成一个元组。**kwargs用于接收关键字参数,它将接收多余的关键字参数并将其打包成一个字典。
示例:*args和**kwargs
def example(*args, **kwargs):
print("args:", args)
print("kwargs:", kwargs)
# 调用函数时传入不同数量的参数
example(1, 2, 3, name="Alice", age=25)
# 输出:
# args: (1, 2, 3)
# kwargs: {'name': 'Alice', 'age': 25}
*args将所有位置参数(1,2,3)打包成一个元组(1, 2, 3)。**kwargs将所有关键字参数(name="Alice",age=25)打包成一个字典{'name': 'Alice', 'age': 25}。
5. 参数顺序规范
当一个函数同时使用位置参数、默认参数和可变参数时,有一定的顺序规范,必须遵循以下顺序:
位置参数
默认参数
*args**kwargs
示例:参数顺序
def function(a, b=2, *args, c, **kwargs):
print(a, b, args, c, kwargs)
# 调用时,按照顺序传递参数
function(1, c=3, d=4, e=5)
# 输出: 1 2 () 3 {'d': 4, 'e': 5}
a是位置参数,必须最先提供。b是默认参数,如果不提供则使用默认值。*args用于接收多余的所有位置参数。c是一个关键字参数,调用时必须显式指定。**kwargs用于接收多余的所有关键字参数。
小结一下吧
位置参数:根据参数顺序传递值。
关键字参数:显式指定参数名和值。
默认参数:函数定义时为参数提供默认值。
可变参数:
*args用于接收多位置参数,**kwargs用于接收多关键字参数。参数顺序:位置参数 > 默认参数 >
*args>**kwargs。
(三)函数返回值
在 Python 中,函数不仅可以执行某些操作,还可以将结果“返回”给调用者。这就是 返回值(Return Value) 的概念。
通过 return 语句,函数可以把处理的结果交给外部使用。如果函数没有 return,那它默认返回的是 None。
1. 使用return返回结果
基本语法:
def function_name(...):
...
return result
示例:
def square(x):
return x * x
result = square(5)
print(result) # 输出: 25
函数 square 返回的是 x 的平方,调用后我们可以拿到这个结果并继续使用。
2. 返回多个值(元组)
Python 支持从一个函数中返回多个值,这些值实际上被打包成一个元组返回。
示例:
def get_name_and_age():
name = "Alice"
age = 30
return name, age
n, a = get_name_and_age()
print(n) # Alice
print(a) # 30
多值返回的本质是:
return name, age等价于return (name, age),然后通过拆包语法接收。
3. 函数无返回值时的表现
如果函数中没有 return 语句,或者只是 return 而没有值,那默认返回的是 None。
示例:
def say_hello():
print("Hello!")
result = say_hello()
print(result) # 输出: None
这个函数 say_hello() 虽然做了事情(打印),但没有 return,因此返回值是 None。
4. 提前终止函数执行
return 不仅能返回值,还能用来提前终止函数的执行。
示例:
def divide(a, b):
if b == 0:
return "除数不能为 0"
return a / b
print(divide(10, 0)) # 输出: 除数不能为 0
print(divide(10, 2)) # 输出: 5.0
当 b 是 0 时,函数遇到第一个 return 后立即终止执行,不会继续往下运行。
5. 将返回值作为表达式使用
函数返回值可以被用在其他表达式或函数中,像这样:
def add(a, b):
return a + b
print(add(2, 3) * 10) # 输出: 50
add(2, 3) 会返回 5,然后再与 10 相乘。
小结一下吧
| 内容 | 示例 | 返回值说明 |
|---|---|---|
| 返回单个值 | return x | 返回一个对象 |
| 返回多个值 | return x, y | 返回一个元组 |
| 无 return 或 return None | return / 无 return | 返回 None |
| 提前结束函数 | if ...: return ... | 直接退出函数 |
| 返回值可以参与表达式 | add(1, 2) * 3 | 函数结果用于计算 |
(四)函数返回值类型注解(Type Hint / Type Annotation)
1. Python 3 引入的类型注解(Type Hints)
先用一句话理解:
def add(a: int, b: int) -> int:
return a + b👉 -> int 的意思是:
这个函数“设计上”应该返回一个
int
不是强制,只是“声明”。这是 给“人”和“工具”看的,不是给 Python 解释器强制执行的。
注意Python 不会强制检查!下面的代码 是合法的:
def add(a: int, b: int) -> int:
return "not a number"Python 不会报错。❗类型注解的作用在于:
IDE(PyCharm)
静态检查工具(mypy、pyright)
阅读代码的人(包括未来的你)
2. 为什么现在的 Python 项目都强烈推荐用?
2.1 PyCharm 会变得非常聪明
def foo() -> dict[str, int]:
return {"a": 1}
你输入:
result = foo() result["a"].
PyCharm 会自动提示:👉 这是 int,有哪些方法
2.2 提前发现 bug(不用等运行)
def get_age() -> int:
return "18"
PyCharm / mypy 会直接警告你:
Expected
int, gotstr
3. 常见的返回值写法(你一定会遇到)
3.1 返回多个类型(Union)
from typing import Union
def parse(s: str) -> Union[int, None]:
if s.isdigit():
return int(s)
return None
Python 3.10+ 更推荐:
def parse(s: str) -> int | None:
...
3.2 返回列表 / 字典
def get_names() -> list[str]:
return ["Alice", "Bob"]
def get_scores() -> dict[str, int]:
return {"math": 90}
3.3 返回自定义对象
class User:
...
def get_user() -> User:
return User()
五、字符串操作模块
在 Python 中,字符串(str)是最常用、最重要的数据类型之一。无论你是在处理用户输入、读取文件、构建网页内容、分析文本数据,几乎都绕不开对字符串的处理。
现在我们总结掌握 Python 字符串的各种操作方法,从最基本的创建与访问,到复杂的格式化,我们需要学会如何清洗、切割、替换、判断和重组字符串,并为后续的数据处理与文本分析打下坚实基础。
(一)字符串基础
在 Python 中,字符串(str)是用来表示文本的数据类型。本部分介绍字符串的创建方式、基本特性、访问技巧以及常见的基本操作。
1. 字符串的定义与创建
字符串可以用 单引号 '、双引号 " 或 三引号 ''' / """ 括起来。
# 单引号 s1 = 'hello' # 双引号 s2 = "world" # 三引号(支持多行) s3 = '''This is a multi-line string.'''
✔️ Python 中单引号和双引号作用相同,主要用于避免转义冲突。
2. 字符串是不可变对象
字符串是 不可变的(immutable):创建后无法修改,只能重新赋值。
s = "hello" # s[0] = 'H' # ❌ 错误!字符串不能直接修改 s = "Hello" # ✅ 只能重新赋值
3. 字符串的索引与切片
字符串可以看作字符的序列,可以通过索引或切片访问其部分内容。
s = "Python" # 索引(从 0 开始) print(s[0]) # P print(s[-1]) # n(最后一个字符) # 切片 [start:end:step] print(s[0:2]) # Py(不包括 end) print(s[::2]) # Pto(每隔1个) print(s[::-1]) # nohytP(反转字符串)
✅ 切片非常强大,是字符串处理中不可或缺的工具。
4. 字符串的连接与重复
# 拼接字符串
a = "Hello"
b = "World"
c = a + " " + b
print(c) # Hello World
# 重复字符串
print("ha" * 3) # hahaha
5. 字符串的成员运算
s = "python"
print("p" in s) # True
print("z" not in s) # True
6. 字符串与类型转换
num = 123
text = str(num) # 数字转字符串
print("数字是:" + text)
# 也可以使用 f-string(推荐)
print(f"数字是:{num}")
小结一下吧
| 操作类型 | 常用方法 / 语法 |
|---|---|
| 创建字符串 | 'abc', "abc", '''abc''' |
| 索引 | s[0], s[-1] |
| 切片 | s[1:4], s[::-1] |
| 拼接与重复 | +, * |
| 判断是否存在 | in, not in |
| 类型转换 | str(x), f"{x}" |
(二)字符串常见操作方法
Python 的字符串类型(str)内建了大量实用的方法,帮助我们完成查找、替换、对齐、大小写转换、格式化等各类文本处理任务。本节将系统讲解所有主流、实用的方法,并配合用例说明。
1. 大小写转换
| 方法 | 作用 |
|---|---|
.lower() | 转为小写 |
.upper() | 转为大写 |
.capitalize() | 首字母大写,其余小写 |
.title() | 每个单词首字母大写 |
.swapcase() | 大小写互换 |
s = "hello World" print(s.lower()) # hello world print(s.upper()) # HELLO WORLD print(s.capitalize()) # Hello world print(s.title()) # Hello World print(s.swapcase()) # HELLO wORLD
2. 查找与判断
| 方法 | 功能 |
|---|---|
.find(sub) | 找到子串首次出现的位置(找不到返回 -1) |
.rfind(sub) | 从右侧开始查找 |
.index(sub) | 与 find 类似,但找不到抛出异常 |
.startswith(prefix) | 是否以某前缀开头 |
.endswith(suffix) | 是否以某后缀结尾 |
.in | 判断子串是否存在 |
s = "hello python"
print(s.find("py")) # 6
print(s.startswith("he")) # True
print(s.endswith("on")) # True
print("py" in s) # True
3. 删除空白符与字符清洗
| 方法 | 功能 |
|---|---|
.strip() | 删除两端空白符 |
.lstrip() | 删除左侧空白符 |
.rstrip() | 删除右侧空白符 |
.replace(old, new) | 替换子串 |
s = " hello world "
print(s.strip()) # "hello world"
s2 = "python,java,c"
print(s2.replace(",", " | ")) # python | java | c
4. 字符串对齐与填充
| 方法 | 说明 |
|---|---|
.center(width, char) | 居中填充 |
.ljust(width, char) | 左对齐填充 |
.rjust(width, char) | 右对齐填充 |
.zfill(width) | 用 0 填充左侧数字部分 |
print("hi".center(10, "-")) # ----hi----
print("hi".ljust(10, ".")) # hi........
print("hi".rjust(10, "*")) # ********hi
print("42".zfill(5)) # 00042
5. 拆分与连接
| 方法 | 功能 |
|---|---|
.split(sep) | 拆分为列表 |
.rsplit(sep) | 从右拆分 |
.splitlines() | 拆分多行字符串 |
'sep'.join(list) | 用分隔符连接列表为字符串 |
s = "apple,banana,grape"
print(s.split(",")) # ['apple', 'banana', 'grape']
lines = "line1\nline2\nline3"
print(lines.splitlines()) # ['line1', 'line2', 'line3']
words = ['one', 'two', 'three']
print("-".join(words)) # one-two-three
6. 内容判断类方法(返回布尔值)
| 方法 | 判断类型 |
|---|---|
.isalpha() | 是否全字母 |
.isdigit() | 是否全数字 |
.isalnum() | 是否全是字母或数字 |
.isspace() | 是否全是空白符 |
.isupper() | 是否全为大写 |
.islower() | 是否全为小写 |
.istitle() | 是否符合标题规范(首字母大写) |
print("abc".isalpha()) # True
print("123".isdigit()) # True
print("abc123".isalnum()) # True
print(" ".isspace()) # True
7. 高级字符串格式化(f-string)
name = "Alice"
age = 30
# 推荐方式:f-string(Python 3.6+)
print(f"{name} is {age} years old.") # Alice is 30 years old
# 老式:format()
print("{} is {} years old.".format(name, age))
# 占位对齐控制
print(f"|{name:^10}|{age:>3}|") # 居中+右对齐:| Alice | 30|
8. 转义字符与原始字符串
| 字符 | 含义 |
|---|---|
\n | 换行 |
\t | 制表符 |
\\ | 反斜杠 |
r"" | 原始字符串,不转义 |
print("hello\nworld") # 换行
print(r"c:\new\folder") # c:\new\folder
9. 其他实用技巧
长字符串拼接:
s = ( "This is a very long string " "split across multiple lines " "but still valid." )字符串比较支持
<,>,==等字典序对比:print("apple" < "banana") # True
小结:常用字符串方法分类对照表
| 类型 | 常用方法 |
|---|---|
| 查找判断 | find(), startswith(), in |
| 修改清洗 | strip(), replace() |
| 大小写处理 | lower(), capitalize() |
| 对齐填充 | center(), zfill() |
| 格式化 | f"", format() |
| 判断内容 | isdigit(), isalpha() |
| 分割拼接 | split(), join() |
| 其他 | len(), 转义、比较等 |
(三)字符串切片与索引
1. 字符串索引(正向索引 / 负向索引)
Python 字符串是序列类型,每个字符都有对应的索引位置。我们可以通过索引访问字符串中的单个字符。
📍 正向索引(从 0 开始)
s = "python" print(s[0]) # p print(s[1]) # y print(s[5]) # n
| 字符 | p | y | t | h | o | n |
|---|---|---|---|---|---|---|
| 索引 | 0 | 1 | 2 | 3 | 4 | 5 |
📍 负向索引(从 -1 开始,表示从右往左)
s = "python" print(s[-1]) # n print(s[-2]) # o print(s[-6]) # p
| 字符 | p | y | t | h | o | n |
|---|---|---|---|---|---|---|
| 索引 | -6 | -5 | -4 | -3 | -2 | -1 |
注意:
超出索引范围(如
s[10])会抛出IndexError。字符串是 不可变对象,不能通过索引修改某个字符。
2. 字符串切片([start:stop:step])
切片(slice)是从字符串中提取子串的一种方式,语法格式为:
s[start : stop : step]
start:起始索引(包含)stop:终止索引(不包含)step:步长(默认为 1)
基础切片
s = "Hello, Python!" print(s[0:5]) # Hello print(s[7:13]) # Python print(s[:5]) # Hello(从头开始) print(s[7:]) # Python!(直到结尾)
使用负数索引切片
s = "abcdefg" print(s[-4:-1]) # def print(s[-7:-4]) # abc
添加步长(step)
s = "0123456789" print(s[::2]) # 02468(每两个字符取一个) print(s[1::3]) # 147(从索引 1 开始,每隔 3 个取)
反向切片(步长为负数)
s = "abcdef" print(s[::-1]) # fedcba(字符串反转) print(s[-1:-7:-1]) # fedcba(等同上行)
切片边界记忆口诀
包头不包尾:起始位置包含,结束位置不包含。
步长方向一致:正数步长从左到右,负数步长从右到左。
索引可以为负:负索引从末尾向前数。
3. 字符串的遍历
遍历字符串可以逐个访问其字符,常用于统计、查找、生成新字符串等任务。
基础遍历
s = "hello"
for c in s:
print(c)
输出:
h e l l o
带索引遍历(推荐:使用 enumerate)
s = "hello"
for index, char in enumerate(s):
print(f"{index} -> {char}")
输出:
0 -> h 1 -> e 2 -> l 3 -> l 4 -> o
经典应用场景小结
| 场景 | 示例 |
|---|---|
| 提取子串 | s[3:7] |
| 字符串反转 | s[::-1] |
| 判断回文 | s == s[::-1] |
| 截取前缀/后缀 | s[:3] 或 s[-3:] |
| 每隔一个字符取 | s[::2] |
(四)字符串格式化
Python 提供了三种主要的字符串格式化方式:
%占位符格式化(经典写法)str.format()方法格式化(兼容写法)f-string 格式化(推荐方式,Python 3.6+)
1.%占位符格式化(C 风格)
这是最早期的格式化方式,语法类似于 C 语言:
name = "Alice"
age = 25
print("My name is %s and I am %d years old." % (name, age))
| 占位符 | 含义 |
|---|---|
%s | 字符串 |
%d | 整数 |
%f | 浮点数(默认小数点后 6 位) |
%.2f | 浮点数保留 2 位小数 |
缺点:可读性差、容易出错,不推荐用于新代码。
2.str.format()方法格式化
引入于 Python 2.7 / 3.0,支持位置参数、关键字参数,更灵活:
name = "Alice"
age = 25
print("My name is {} and I am {} years old.".format(name, age))
🎯 支持位置参数 / 关键字参数
print("Hello, {0}. You are {1}.".format("Bob", 30))
print("Hello, {name}. You are {age}.".format(name="Bob", age=30))
🎯 支持格式控制
pi = 3.1415926
print("Pi is {:.2f}".format(pi)) # Pi is 3.14
缺点:写法较冗长,推荐 f-string 替代。
3.f-string 格式化(Python 3.6+,推荐✅)
最现代、最简洁的格式化方式,代码更清晰,推荐作为首选写法。
name = "Alice"
age = 25
print(f"My name is {name} and I am {age} years old.")
🎯 支持表达式
a = 5
b = 3
print(f"{a} + {b} = {a + b}")
🎯 支持格式化控制
pi = 3.1415926
print(f"Pi rounded to 2 digits: {pi:.2f}")
🎯 与函数、数据结构结合
user = {"name": "Bob", "score": 88}
print(f"{user['name']} scored {user['score']}")
三种方式对比
| 特性 | % 格式化 | str.format() | f-string |
|---|---|---|---|
| 可读性 | ❌ | ✅ | ✅✅✅ |
| 功能强大 | 一般 | ✅✅ | ✅✅✅ |
| 写法简洁 | 一般 | ❌ | ✅✅✅ |
| 推荐程度 | ❌ 不推荐 | ✅ 过渡用法 | ✅✅✅ 首选 |
小结一下吧
新代码推荐 f-string,语法简洁、表达能力强。
str.format()适用于兼容旧版本 Python。%占位符方式适合了解,不建议用于正式项目中。
六、列表、字典与集合 —— Python 中的数据组织能力
(一)为什么需要“数据结构”
在前面的章节中,我们已经学习了 变量、基本数据类型、控制流和函数以及字符串。这些知识可以帮助我们描述一个值、处理一次逻辑、完成一个功能。
但在真实的程序中,我们面对的往往不是“一个值”,而是:
一组数据
多条记录
多个对象
一批状态或配置项
这正是 “数据结构”存在的意义。
1. 单个变量的局限性
先看一个最简单的例子。如果我们只需要保存一个人的名字,用一个变量就足够:
name = "张彦峰"
但如果现在要保存 10 个、100 个、甚至更多名字 呢?你显然不可能这样写:
name1 = "卢政伯" name2 = "吕鸿昌" name3 = "秦学磊"
这种写法存在明显问题:
变量数量不可控
无法方便地进行循环处理
代码几乎不可维护
这时,我们需要一种方式,把“一组相关的数据”组织在一起。
2. 从“一个值”到“一组值”
继续刚才的例子,如果我们希望把多个名字放在一起,Python 提供了 列表(list) 这样的数据结构:
names = ["张彦峰","卢政伯","吕鸿昌","秦学磊"]
这样做的好处是:
所有名字属于同一个整体
可以通过循环统一处理
可以按顺序访问、修改、删除
这一步,本质上是从:“一个变量保存一个值”升级为:“一个变量保存一组有结构的数据”
3. 一条记录 vs 多条记录
再看一个更贴近实际开发的例子。假设我们要表示一个用户的信息:
user_name = "张彦峰" user_age = 18 user_email = "zyf@alibaba.com"
这种写法的问题在于:
信息是分散的
很难整体传递或管理
字段之间缺乏明确的“归属关系”
这时,更合理的做法是使用 字典(dict):
user = {
"name": "张彦峰",
"age": 18,
"email": "zyf@alibaba.com"
}
字典的特点是:
通过 key(键) 来访问数据
每个字段都有清晰的含义
非常适合描述“一条记录”
如果现在有 多条用户记录,我们就可以把多个字典放进一个列表中:
users = [
{"name": "张彦峰", "age": 18},
{"name": "张琴", "age": 18}
]
你可以看到:数据结构是可以组合使用的,这正是后面处理嵌套数据(如 JSON)的基础。
4. 最常用的几种数据结构
在本章中,我们将系统学习 Python 中最常用的几种数据结构:
列表(list):用于存储有序、可变的一组数据
字典(dict):用于存储键值映射关系
集合(set):用于去重和集合运算
元组(tuple):用于表示不可变的数据组合
通过这一章,你将逐步建立起这样的能力:
根据问题特点,选择合适的数据结构,并高效地操作它们
这也是后续学习 嵌套结构、JSON 数据解析、配置处理 的必要基础。
(二)列表(List):有序数据的容器
列表是 Python 中最常用且强大的数据结构之一,广泛用于存储有序、可变的数据。作为一个容器类型,它不仅能存储多种数据类型,还能高效支持数据的添加、删除、修改和访问。掌握列表的使用是理解 Python 数据处理能力的重要基础。
1. 列表的基本概念
列表(list)是一个有序的容器,可以存储任意类型的数据,包括整数、字符串、布尔值,甚至是其他列表。列表的核心特点包括:
有序性:列表中的元素是按顺序排列的,每个元素都有一个对应的索引,索引从 0 开始。
可变性:列表是可变的,可以在原地修改列表的内容,例如添加、删除或更新元素。
支持多种数据类型:列表可以包含不同类型的元素,甚至可以存储其他容器类型(如列表、字典等)。
# 示例:包含整数的列表 numbers = [1, 2, 3, 4, 5] # 示例:包含不同数据类型的列表 info = ["Alice", 18, True, 3.14, ["nested", "list"]]
关键点:与字符串(str)类似,列表也支持通过索引访问和切片操作,但字符串是不可变的,而列表可以直接修改。
2. 列表的创建与访问
创建列表
列表的创建非常简便,可以通过方括号 [] 来定义。可以创建空列表、包含多个元素的列表,或是包含混合类型元素的列表。
# 空列表 empty_list = [] # 含有多个整数的列表 numbers = [1, 2, 3, 4, 5] # 含有不同类型的元素的列表 mixed = [1, "Alice", True, 3.14]
访问列表元素
通过索引访问列表中的元素,索引从 0 开始。列表还支持负索引,允许从列表的末尾开始访问元素。
numbers = [10, 20, 30, 40] # 正向索引 print(numbers[0]) # 10 print(numbers[3]) # 40 # 负向索引 print(numbers[-1]) # 40 print(numbers[-2]) # 30
此外,列表支持切片操作,可以通过指定起始和结束索引来获取子列表。
# 切片示例 print(numbers[1:3]) # [20, 30] print(numbers[:2]) # [10, 20] print(numbers[2:]) # [30, 40]
注意:切片操作返回的是新列表,原列表内容不受影响。
3. 列表的常用修改操作
列表是可变的,意味着可以在原地修改其内容。常见的修改操作包括添加元素、删除元素和修改元素。
添加元素
append():将元素添加到列表的末尾。insert():将元素插入到指定的索引位置。extend():批量追加
# 示例:添加元素 nums = [1, 2, 3] nums.append(4) # 在末尾添加元素 nums.insert(1, 1.5) # 在索引 1 处插入元素 nums.extend([3, 4]) # [1, 2, 3, 4] print(nums) # 输出: [1, 1.5, 2, 3, 4, 3, 4]
删除元素
remove():删除第一个匹配到的元素。pop():删除并返回指定索引位置的元素(默认删除最后一个元素)。del:根据索引删除元素。clear():清空列表
# 示例:删除元素 nums.remove(1.5) # 删除元素 1.5 popped_element = nums.pop() # 删除并返回最后一个元素 del nums[0] # 删除索引 0 处的元素 print(nums) # 输出: [2, 3, 4, 3]
修改元素
通过索引可以直接修改列表中的元素:
nums[0] = 10 # 将索引 0 处的元素修改为 10 print(nums) # 输出: [10, 3]
4. 列表的遍历与循环配合
遍历列表元素
遍历列表元素时,最常用的是 for 循环。可以直接遍历列表的每个元素,或者使用 range() 函数配合索引来遍历列表。
# 直接遍历元素
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit) # 输出每个水果
# 使用索引遍历
for i in range(len(fruits)):
print(i, fruits[i]) # 输出索引和值
# 使用 enumerate 获取索引和值
for idx, fruit in enumerate(fruits):
print(idx, fruit) # 输出索引和值
应用场景:
只关心值:直接遍历元素。
需要索引:使用
range()或enumerate()。
5. 列表的常用内置操作与函数
Python 提供了丰富的内置函数和方法来操作列表。以下是一些常用操作:
len():返回列表的长度。in:检查元素是否存在于列表中。count():统计元素在列表中出现的次数。index():查找元素首次出现的位置。sort():原地排序。sorted():返回一个新排序的列表。reverse():原地反转列表。
nums = [4, 2, 7, 1] print(len(nums)) # 输出: 4 print(2 in nums) # 输出: True print(nums.count(2)) # 输出: 1 print(nums.index(7)) # 输出: 2 nums.sort() # 原地排序 sorted_nums = sorted(nums) # 返回新列表 nums.reverse() # 原地反转
注意:sort() 和 reverse() 会改变原列表,而 sorted() 返回新列表。
6. 列表推导式(List Comprehension)
列表推导式是 Python 中非常强大且简洁的语法,它允许在一行代码内创建一个新的列表。相比于传统的 for 循环,列表推导式更加简洁且执行效率高。
# 基本语法:生成平方数列表 squares = [x**2 for x in range(5)] print(squares) # 输出: [0, 1, 4, 9, 16] # 带条件的推导式:生成偶数的平方数列表 even_squares = [x**2 for x in range(5) if x % 2 == 0] print(even_squares) # 输出: [0, 4, 16]
列表推导式的优势:
简洁性:可以用一行代码替代多行。
可读性:语法清晰、易懂。
性能:避免了手动使用
append()。
7. 浅拷贝(Shallow Copy)与深拷贝(Deep Copy)
在 Python 中,理解浅拷贝与深拷贝的前提,是理解一个核心事实:
Python 中的变量,本质上保存的是对象的引用(reference),而不是对象本身。
因此,“拷贝”并不等价于“生成一个完全独立的新对象”,是否真正独立,取决于拷贝的层级。
7.1 对象、引用与容器的关系模型
先从一个最小示例理解引用关系:
a = [1, 2, 3] b = a
此时:
a与b指向 同一个 list 对象对
a的任何修改,都会体现在b上
a[0] = 100 print(b) # [100, 2, 3]
这不是拷贝,而是 引用绑定(aliasing)。
7.2 浅拷贝(Shallow Copy)
浅拷贝的定义:创建一个新的容器对象,但容器中保存的元素仍然是对原对象中元素的引用。
换句话说:
外层容器是新的
内层对象是共享的
常见的浅拷贝方式
以下方式都会产生浅拷贝:
b = a.copy() b = a[:] b = list(a)
浅拷贝的行为示意
a = [[1, 2], [3, 4]] b = a.copy()
内存关系可以抽象为:
a ──▶ list ──▶ [ L1 , L2 ] b ──▶ list ──▶ [ L1 , L2 ]
a和b是两个不同的列表对象但它们内部的
L1、L2指向同一个子列表对象
浅拷贝的典型“坑”
a = [[1, 2], [3, 4]] b = a.copy() b[0][0] = 100 print(a) # [[100, 2], [3, 4]]
原因分析:
b[0]与a[0]指向同一子列表修改子列表,会影响所有引用它的容器
浅拷贝何时是安全的
列表中包含 不可变对象,后续操作只涉及 整体替换,不修改内部对象
a = [1, 2, 3, "abc"] b = a.copy() b[0] = 100 # 不影响 a print(a) # [1, 2, 3, 'abc'] print(b) # [100, 2, 3, 'abc']
7.3 深拷贝(Deep Copy)
深拷贝的定义:递归地复制对象本身以及其内部引用的所有子对象,生成完全独立的对象树。
特点:
外层容器独立
内层对象也完全独立
修改任何层级都不会相互影响
深拷贝的标准方式
import copy b = copy.deepcopy(a)
深拷贝的行为示意
a = [[1, 2], [3, 4]] b = copy.deepcopy(a)
内存模型:
a ──▶ list ──▶ [ L1 , L2 ] b ──▶ list ──▶ [ L1' , L2' ]
L1 ≠ L1'L2 ≠ L2'
深拷贝示例验证
a = [[1, 2], [3, 4]] b = copy.deepcopy(a) b[0][0] = 100 print(a) # [[1, 2], [3, 4]]
7.4 浅拷贝 vs 深拷贝的核心对比
| 维度 | 浅拷贝 | 深拷贝 |
|---|---|---|
| 外层容器 | 新对象 | 新对象 |
| 内层对象 | 共享引用 | 完全独立 |
| 性能 | 高 | 相对较低 |
| 内存占用 | 少 | 多 |
| 修改风险 | 高(嵌套结构) | 极低 |
8. list * n与浅拷贝的本质关系
a = [[0]] * 3
等价于:
sub = [0] a = [sub, sub, sub]
因此:
a[0][0] = 1 print(a) # [[1], [1], [1]]
这是浅拷贝的一种极端形式:
外层列表新建
内层对象全部指向同一个引用
正确构造独立子列表的方式
a = [[0] for _ in range(3)]
9. 列表的常见坑
浅拷贝问题
当使用 * 运算符复制包含可变元素的列表时,可能会发生意外的引用问题。例如:
a = [[1, 2]] * 3 a[0][0] = 100 print(a) # 输出: [[100, 2], [100, 2], [100, 2]]
原因:所有子列表都引用了同一个内存地址,修改一个元素会影响所有子列表。可以使用 copy.deepcopy() 来避免这种问题。
遍历时修改列表
直接在遍历列表时修改列表,可能会导致不预期的结果。例如:
nums = [1, 2, 3, 4]
for n in nums:
if n % 2 == 0:
nums.remove(n) # 删除偶数元素
print(nums) # 输出: [1, 3]
解决办法:遍历列表的副本,如 nums[:],或者使用列表推导式来过滤元素。
# 解决方法:遍历副本
for n in nums[:]:
if n % 2 == 0:
nums.remove(n)
小结一下吧
列表是 有序、可变 的数据容器,是 Python 数据结构的核心之一
支持索引访问、切片操作、原地修改和高效遍历
提供大量内置方法,配合列表推导式可以写出高效、优雅的代码
常见风险点主要集中在:
浅拷贝与引用共享
遍历过程中修改列表
误用
list * n构造嵌套结构
熟练掌握列表,将为后续学习字典、集合、嵌套数据结构以及 JSON / 数据分析场景打下坚实基础。
(三)字典(dict):键值映射的数据结构
字典(dict)是 Python 中最核心、使用频率极高的一种内置数据结构,用于存储 键值对(key-value)映射关系。它通过 key 直接定位 value,而不是像列表那样依赖下标位置,因此在表达“记录型数据”“配置数据”“映射关系”时具有不可替代的优势。
从底层实现角度看,Python 字典基于 哈希表(Hash Table) 实现,在绝大多数场景下,其查找、插入、删除操作的时间复杂度都接近 O(1)。
1. 字典的设计思想
为什么需要字典?
列表适合解决以下问题:
数据 有明确顺序
主要通过 位置(索引) 访问
但在很多真实业务中,我们更关心的是:
“这个人的 年龄 是多少?”
“这个配置项 timeout 对应的值是多少?”
此时,如果仍然依赖下标访问:
可读性差
容易出错
不利于扩展和维护
字典的核心思想是:
用有意义的 key,直接映射到对应的 value
对比示例
# 使用列表表示用户信息(语义不清晰)
user_list = ["Alice", 18, "alice@example.com"]
# 使用字典表示用户信息(结构清晰)
user_dict = {
"name": "Alice",
"age": 18,
"email": "alice@example.com"
}
字典的优势
字段含义清晰,代码自解释
不依赖顺序,结构稳定
便于新增、删除字段
非常贴近 JSON / 配置文件 / 数据库记录的结构
2. 字典的基本使用
创建字典
# 使用花括号(最常见)
user = {"name": "Alice", "age": 18}
# 使用 dict 构造函数
user2 = dict(name="Bob", age=20)
# 从键值对列表创建
pairs = [("name", "Charlie"), ("age", 22)]
user3 = dict(pairs)
访问 value
print(user["name"]) # Alice
print(user.get("age")) # 18
重要约束说明
key 必须唯一:后定义的 key 会覆盖之前的值
key 必须是不可变类型:
合法:
str、int、float、tuple非法:
list、dict、set
# 合法
d = {(1, 2): "ok"}
# 非法(会抛出 TypeError)
d = {[1, 2]: "error"}
3. 字典的增删改查(CRUD)
新增 / 修改(统一语法)
user["email"] = "alice@example.com" # 新增 user["age"] = 19 # 修改
字典不会区分“新增”和“修改”,是否存在 key 决定行为。
删除元素
# 删除指定 key
del user["email"]
# 删除并返回 value
age = user.pop("age")
# 指定默认值,避免 KeyError
age = user.pop("age", None)
查询
user["name"] # 不存在会抛 KeyError
user.get("email") # 不存在返回 None
user.get("email", "N/A") # 返回默认值
是否存在某个 key
"name" in user # True / False "email" not in user # True / False
4. 字典的遍历方式
遍历 key(默认行为)
for key in user:
print(key, user[key])
遍历 value
for value in user.values():
print(value)
遍历 key-value 对(最常用)
for key, value in user.items():
print(key, value)
遍历时的注意事项
遍历过程中 不建议修改字典结构(增删 key)
若需要修改,可先遍历
list(user.keys())
5. 字典的常用方法与典型模式
常用方法速览
user.keys() # 所有 key(视图对象) user.values() # 所有 value user.items() # (key, value) 对 user.clear() # 清空字典 user.copy() # 浅拷贝
setdefault:安全设置默认值
user.setdefault("age", 18)
等价于:
if "age" not in user:
user["age"] = 18
update:批量更新
user.update({"email": "alice@example.com", "age": 20})
典型模式一:计数器
words = ["apple", "banana", "apple", "cherry"]
counter = {}
for word in words:
counter[word] = counter.get(word, 0) + 1
print(counter)
典型模式二:分组
students = [
("Alice", "A"),
("Bob", "B"),
("Charlie", "A")
]
groups = {}
for name, grade in students:
groups.setdefault(grade, []).append(name)
print(groups) #{'A': ['Alice', 'Charlie'], 'B': ['Bob']}
6. 字典的拷贝与可变性
浅拷贝(Shallow Copy)
d1 = {"a": [1, 2]}
d2 = d1.copy()
d2["a"].append(3)
print(d1) # {'a': [1, 2, 3]}
浅拷贝只复制“引用”,不会复制内部的可变对象。
深拷贝(Deep Copy)
import copy
d1 = {"a": [1, 2]}
d2 = copy.deepcopy(d1)
d2["a"].append(3)
print(d1) # {'a': [1, 2]}
7. 字典与列表的组合(复杂结构建模)
列表中放字典
users = [
{"name": "Alice", "age": 18},
{"name": "Bob", "age": 20}
]
for user in users:
print(user["name"], user["age"])
字典中放列表
grades = {
"Alice": [90, 95, 88],
"Bob": [75, 80, 82]
}
for name, scores in grades.items():
avg = sum(scores) / len(scores)
print(name, avg)
多层嵌套字典
users = {
"Alice": {"age": 18, "email": "alice@example.com"},
"Bob": {"age": 20, "email": "bob@example.com"}
}
print(users["Alice"]["email"])
小结一下吧
字典是 键值映射容器,核心优势是按 key 快速访问
基于哈希表实现,查找效率高
支持完整的增删改查操作
提供丰富的方法与常见编程模式
可与列表自由组合,构建任意复杂数据结构
熟练掌握字典,是后续学习 JSON 处理、配置管理、Web 开发、数据分析 的关键基础。
(四)集合(set):去重与集合运算
集合(set)是 Python 中用于存储唯一元素并支持数学集合运算的一种内置数据结构。其核心价值在于:
天然去重
高效的成员判断(O(1) 平均时间复杂度)
直观表达集合关系(交集、并集、差集等)
在实际开发中,集合常用于数据清洗、权限控制、标签计算、关系判断等场景。
1. 什么是集合(set)
集合的概念来源于数学中的集合:一组不重复的元素构成的整体。
# 使用大括号创建集合
fruits = {"apple", "banana", "cherry"}
print(fruits)
# 输出顺序不固定,例如:{'banana', 'apple', 'cherry'}
# 使用 set() 构造函数
nums = set([1, 2, 3, 2, 1])
print(nums) # {1, 2, 3},自动去重
核心特性
无序(unordered):不支持索引和切片操作;元素顺序不稳定,每次打印结果可能不同
元素唯一(unique):相同元素只会保留一份,适合用于去重、排重逻辑
成员判断高效:
x in set的时间复杂度为 O(1),明显快于列表的 O(n)仅支持可哈希(hashable)类型:合法元素:
int、float、str、tuple;非法元素:list、dict、set
s = {(1, 2), "abc", 10} # 合法
# s = {[1, 2], 3} # TypeError: unhashable type: 'list'
2. 集合的创建方式
# 空集合(注意不能用 {})
empty_set = set()
# 从列表 / 元组 / 字符串创建
set([1, 2, 2, 3])
set(("a", "b", "a"))
set("hello") # {'h', 'e', 'l', 'o'}
⚠️
{}表示空字典,而不是空集合。
3. 集合的基本操作
添加元素
nums = {1, 2, 3}
nums.add(4)
print(nums) # {1, 2, 3, 4}
add():一次只能添加一个元素
删除元素
nums.remove(2) # 元素不存在会抛 KeyError nums.discard(5) # 元素不存在不会报错 popped = nums.pop() # 随机删除并返回一个元素 nums.clear() # 清空集合
对比说明:
| 方法 | 元素不存在时 | 使用建议 |
|---|---|---|
| remove | 抛异常 | 确保元素一定存在 |
| discard | 不报错 | 更安全,推荐 |
| pop | 随机删除 | 不依赖具体元素 |
成员判断
nums = {1, 2, 3}
print(2 in nums) # True
print(5 not in nums) # True
集合是做“是否存在”判断的首选结构。
4. 集合运算(重点)
集合支持与数学集合一致的运算语义。
a = {1, 2, 3}
b = {3, 4, 5}
并集(Union)
print(a | b)
print(a.union(b))
# {1, 2, 3, 4, 5}
交集(Intersection)
print(a & b)
print(a.intersection(b))
# {3}
差集(Difference)
print(a - b)
print(a.difference(b))
# {1, 2}
对称差集(Symmetric Difference)
print(a ^ b)
print(a.symmetric_difference(b))
# {1, 2, 4, 5}
5. 集合关系判断
a = {1, 2}
b = {1, 2, 3}
print(a.issubset(b)) # True 子集
print(b.issuperset(a)) # True 超集
print(a.isdisjoint({4})) # True 是否无交集
常用于:权限校验、条件覆盖判断。
6. 可变集合与不可变集合
set(可变)
支持 add / remove
不能作为字典的 key
frozenset(不可变)
fs = frozenset([1, 2, 3])
一旦创建不可修改
可作为字典 key 或集合元素
常用于配置、常量集合
7. 典型应用场景
去重
nums = [1, 2, 2, 3, 4, 4] unique_nums = list(set(nums))
权限 / 标签判断
user_roles = {"admin", "editor"}
required_roles = {"editor", "viewer"}
if user_roles & required_roles:
print("有权限")
查找共同元素
team_a = {"Alice", "Bob", "Charlie"}
team_b = {"Bob", "David"}
common = team_a & team_b
数据差异分析
old_users = {1, 2, 3}
new_users = {2, 3, 4}
lost = old_users - new_users # 流失用户
added = new_users - old_users # 新增用户
8. 与列表、字典的对比
| 结构 | 是否有序 | 是否可重复 | 核心用途 |
|---|---|---|---|
| list | 是 | 是 | 顺序数据 |
| dict | 是(3.7+) | key 不可重复 | 映射关系 |
| set | 否 | 否 | 去重 / 关系计算 |
小结一下吧
集合是 无序、不重复 的数据结构
成员判断和集合运算效率极高
核心能力:
去重
并 / 交 / 差 / 对称差
子集 / 超集判断
是处理“关系型数据”和“唯一性约束”的利器
掌握集合后,你可以用更简洁、更高效的方式解决大量实际问题,为后续复杂数据结构和算法学习打下坚实基础。
(五)元组(tuple):不可变序列
元组(tuple)是 Python 中的一种有序、不可变的序列类型。它在语法和使用方式上与列表(list)非常相似,但核心差异在于:一旦创建,元组的结构不能被修改。
在实际开发中,元组常用于:
表示固定含义的数据组合
作为函数的多返回值
作为字典的 key
在某些场景下,替代列表以提升安全性和性能
1. 元组的基本概念
元组的核心特性
有序(Ordered):元素按顺序存储,可以通过索引访问
不可变(Immutable):元组创建后,不能修改、添加、删除元素
可包含任意类型:支持混合类型,支持嵌套结构
point = (10, 20)
info = ("Alice", 18, True, ["Python", "Go"])
元素访问
print(point[0]) # 10 print(info[1]) # 18 print(info[-1]) # ['Python', 'Go']
元组 vs 列表(核心对比)
| 特性 | 列表 list | 元组 tuple |
|---|---|---|
| 是否可变 | 可变 | 不可变 |
| 是否有序 | 是 | 是 |
| 是否可作为 dict key | 否 | 是 |
| 使用场景 | 动态数据 | 固定数据 |
| 语法 | [ ] | ( ) |
2. 创建元组的多种方式
使用圆括号(最常见)
t = (1, 2, 3)
省略圆括号(语法层面支持)
t = 1, 2, 3
✅ 常用于函数返回多个值或简单赋值场景
❌ 不建议初学阶段频繁使用,容易降低可读性
单元素元组(非常重要)
single = (5,) # 正确 single2 = (5) # 错误,这是整数
📌 结论:是否为元组,关键不在于括号,而在于 逗号
使用tuple()构造函数
nums = [1, 2, 3]
chars = "abc"
print(tuple(nums)) # (1, 2, 3)
print(tuple(chars)) # ('a', 'b', 'c')
3. 元组的索引、切片与遍历
索引访问
t = (10, 20, 30, 40) print(t[0]) # 10 print(t[-1]) # 40
切片操作
print(t[1:3]) # (20, 30) print(t[:2]) # (10, 20)
注意:
切片返回的是 新元组
原元组不会发生任何变化
遍历元组
for item in t:
print(item)
4. 元组的不可变性(核心理解)
不允许的操作
t = (1, 2, 3) # t[0] = 10 # TypeError # t.append(4) # AttributeError # del t[1] # TypeError
元组中包含可变对象的情况(重点)
t = (1, [2, 3]) t[1].append(4) print(t) # (1, [2, 3, 4])
如何理解?
元组不可变:指的是
👉t[1]这个“引用”不能被替换列表可变:
👉 列表内部的内容仍然可以修改
📌 一句话总结:
元组保证的是“结构不变”,而不是“内容绝对不变”
5. 元组解包(非常重要的能力)
基本解包
point = (10, 20) x, y = point print(x, y) # 10 20
解包与函数返回值
def get_min_max(nums):
return min(nums), max(nums)
min_val, max_val = get_min_max([3, 7, 1, 9])
print(min_val, max_val) # 1 9
使用*进行扩展解包
a, *b = (1, 2, 3, 4) print(a) # 1 print(b) # [2, 3, 4]
6. 元组的常见应用场景
作为字典的 key
location = {}
location[(10, 20)] = "Home"
print(location)
原因:
字典 key 必须是 不可变类型
列表不能作为 key,元组可以
函数返回多个值(Pythonic 写法)
def user_info():
return "Alice", 18, True
name, age, active = user_info()
表示“业务含义固定”的数据
HOST = "localhost" PORT = 8080 CONFIG = (HOST, PORT)
📌 语义层面表达:
“这组数据不应该被修改”
7. 元组的常用方法与内置函数
元组方法非常少,这是其设计的一部分:
t = (1, 2, 2, 3) print(t.count(2)) # 2 print(t.index(3)) # 3
常配合使用的内置函数:
len(t) max(t) min(t) sum(t)
8. 元组与列表的深入对比
| 维度 | 列表 | 元组 |
|---|---|---|
| 内存占用 | 较高 | 较低 |
| 创建速度 | 较慢 | 较快 |
| 安全性 | 易被修改 | 更安全 |
| 可读性 | 偏数据容器 | 偏结构表达 |
小结一下吧
元组是 不可变的有序序列
与列表相似,但语义更偏向 “固定结构”
常见用途:
函数多返回值
字典 key
不可修改的配置数据
支持:
索引、切片、遍历
解包(非常重要)
(六)总结:如何选择合适的数据结构
✅ 至此,你已经系统掌握 Python 的四大基础数据结构::
列表(list):有序、可变的序列
字典(dict):键值映射
集合(set):无序、不重复
元组(tuple):不可变的序列
每种数据结构都有自己的特点和适用场景,选择合适的数据结构能够让程序更高效、更易维护、更易理解。
1. 数据结构选择对比表
| 数据结构 | 特性 | 使用场景 | 注意事项 |
|---|---|---|---|
| 列表 list | 有序,可变,可包含任意类型 | 保存顺序数据,循环处理,多次增删改 | 遍历修改时要小心;切片返回新列表 |
| 字典 dict | 键值映射,key 唯一,可变 | 记录型数据(用户信息、配置、状态映射),快速查找 | key 必须不可变;get 可提供默认值 |
| 集合 set | 无序,不重复,高效成员判断 | 去重、集合运算、权限判断、标签判断 | 无索引;遍历顺序不可控 |
| 元组 tuple | 有序,不可变,可包含任意类型 | 固定数据、函数多值返回、字典 key | 内部可变对象仍可修改;不可修改元素 |
2. 如何选择数据结构
选择数据结构可以按以下几个维度:
1️⃣ 是否需要顺序
是 → 列表或元组
否 → 集合或字典
2️⃣ 是否需要唯一性
是 → 集合
否 → 列表或元组
3️⃣ 是否需要通过名字访问
是 → 字典
否 → 列表或集合
4️⃣ 是否需要可变性
可变 → 列表、字典、集合
不可变 → 元组、不可变字典(扩展应用)
3. 常见组合场景
在实际开发中,这些数据结构经常组合使用:
| 场景 | 数据结构组合 | 示例 |
|---|---|---|
| 多条记录,每条记录有多个字段 | 列表 + 字典 | users = [{"name": "Alice", "age":18}, {"name": "Bob", "age":20}] |
| 字典中某字段有多个值 | 字典 + 列表 | grades = {"Alice":[90,95], "Bob":[80,82]} |
| 去重的列表 | 列表 + 集合 | unique_nums = list(set(nums)) |
| 函数返回多个值 | 元组 | min_val, max_val = get_min_max([3,7,1,9]) |
4. 选用原则总结
顺序性优先 → 列表/元组
键值访问优先 → 字典
唯一性 / 集合运算 → 集合
数据固定不变 → 元组
复杂嵌套 → 根据组合场景选择最合适的容器
🔑 核心思想:
数据结构是工具,目的是高效组织和操作数据。
不要只记语法,要根据问题特性选择最合适的数据结构。
七、结构化数据:Python 中的数据组织与处理
(一)为什么需要结构化数据建模
在前面的章节中,我们已经学习了 Python 提供的基础数据结构:列表(list)、字典(dict)、集合(set)和元组(tuple)。
这些数据结构在表达简单数据时非常高效,但当我们开始处理真实世界中的业务数据时,很快就会发现:仅靠基础数据结构,往往难以支撑复杂数据的长期演进与工程化使用。
结构化数据建模,正是为了解决这一问题而出现的。
1. 现实世界数据的天然复杂性
现实中的数据几乎从来不是“单值”的,而是具有以下典型特征:
多字段(Multi-attribute):一个用户不仅有名字,还包含年龄、邮箱、状态、注册时间等多个属性;一个订单不仅有金额,还包含商品列表、支付方式、物流信息等
层级关系(Hierarchical):用户包含地址信息;订单包含多个商品;商品又包含规格、价格、库存等子结构
实体之间存在关联:一对多:一个用户对应多个订单;多对一:多个订单属于同一个商家;多对多:用户与标签、商品与分类
状态与行为并存:数据不仅是“静态描述”,还会涉及状态变化(如订单状态流转),以及业务行为(如校验、计算、转换)
这些特征决定了:现实世界的数据,本质上是结构化、层级化、并且语义明确的。
2. 基础数据结构的能力边界
Python 的 list 和 dict 是非常强大的工具,但它们的设计初衷是通用容器,而不是“领域模型”。
以字典为例:
字典可以存任意键值对
但它并不关心:
这个字段是否必须存在
这个字段应该是什么类型
不同字段之间是否存在约束关系
随着业务复杂度的上升,单纯使用 dict 会逐渐暴露出问题:
结构不透明:字段依赖“约定”而非“定义”,阅读代码时无法一眼看出数据结构
缺乏约束:键名拼写错误只能在运行时报错,类型错误难以及早发现
可维护性下降:字段增加或调整会波及大量代码,缺乏统一的数据入口
业务语义缺失:
data["status"] == 1本身无法说明业务含义,需要额外注释或上下文才能理解
这意味着:基础数据结构更适合“存数据”,但并不适合“表达数据含义”。
3. 从“数据容器”到“数据模型”的转变
当系统规模逐渐扩大时,我们需要的不再只是一个“能装东西的容器”,而是一个明确表达业务含义的数据模型(Data Model)。
数据模型关注的不仅是“数据长什么样”,还包括:
字段的业务语义
字段之间的结构关系
数据的合法性规则
数据可支持的操作与行为
这种转变,本质上是:从“如何存数据”,升级为“如何描述现实世界中的对象”。
4. Python 在结构化数据建模上的天然优势
Python 之所以适合结构化数据建模,主要得益于以下能力:
灵活的基础数据结构(list / dict)
完整的面向对象体系(Class)
强大的类型注解支持
内建 JSON 处理能力
dataclass 等高级建模工具
这些能力,使得 Python 可以自然地完成从:原始数据 → 半结构化数据 → 领域模型 → 工程化数据体系的逐层演进。
小结一下吧
现实世界的数据天然是结构化的
基础数据结构适合存储,但不适合长期建模
结构化数据建模是代码工程化的必经之路
Python 提供了从简单到复杂的完整建模能力
在接下来的学习中,我们将从嵌套数据结构开始,逐步引入 JSON 处理,最终过渡到 基于 Class 的结构化数据建模,构建可维护、可扩展的 Python 数据体系。
(二)Python 中的嵌套结构化数据
在明确了为什么需要结构化数据建模之后,我们首先要面对的是:如何在 Python 中表达“多字段 + 多层级”的数据结构。
在不引入面向对象之前,Python 最直接、最常见的做法,就是使用嵌套的数据结构——即在 list 或 dict 中再包含 list 或 dict。
嵌套结构,是 Python 迈向结构化数据处理的第一步。
1. 嵌套结构化数据的基本思想
所谓嵌套结构,本质上是:用 dict 表达“对象”,用 list 表达“集合”,并通过层级组合还原现实关系。
这种思想非常直观,也几乎不需要额外语法成本,因此被广泛用于:
接口返回数据
配置文件
临时数据组织
JSON 原始载体
2. 字典嵌套字典:表达对象的层级属性
适用场景:一个对象内部存在子结构
user = {
"id": 1001,
"name": "Alice",
"profile": {
"age": 28,
"email": "alice@example.com",
"address": {
"city": "Beijing",
"zipcode": "100000"
}
}
}
结构理解
user:整体对象profile:用户的扩展属性address:更细粒度的子结构
这种结构清晰地反映了现实语义:地址不属于用户本身,而属于用户的资料信息。
访问方式
city = user["profile"]["address"]["city"]
此时你已经可以感受到第一个问题:
访问路径依赖结构稳定
任意一层缺失,都会导致运行期错误
3. 字典嵌套列表:表达一对多关系
适用场景:一个主体拥有多个子对象
order = {
"order_id": "ORD-001",
"user_id": 1001,
"items": [
{"sku": "SKU-1", "price": 100, "quantity": 2},
{"sku": "SKU-2", "price": 50, "quantity": 1}
]
}
结构理解
order是订单对象items是订单下的商品集合每个商品仍然是一个“对象”
典型处理逻辑
total_amount = 0
for item in order["items"]:
total_amount += item["price"] * item["quantity"]
此时一个非常关键的变化已经出现:业务计算逻辑,开始直接写在“嵌套结构遍历”之中。
这是后续引入 Class 建模的重要动机。
4. 列表嵌套字典:同构对象的集合
适用场景:多个结构相同的对象
users = [
{"id": 1, "name": "Alice", "active": True},
{"id": 2, "name": "Bob", "active": False},
{"id": 3, "name": "Charlie", "active": True}
]
遍历与筛选
active_users = []
for user in users:
if user["active"]:
active_users.append(user)
这种结构在接口返回数据中极为常见,但它也暴露了嵌套结构的本质问题之一:
字段完全依赖字符串约定
没有任何显式结构定义
错误只能在运行期发现
5. 多层混合嵌套:真实系统中的常态
在真实系统中,嵌套结构往往是多种形式的组合:
response = {
"code": 0,
"data": {
"user": {
"id": 1001,
"orders": [
{
"order_id": "ORD-001",
"items": [
{"sku": "SKU-1", "price": 100}
]
}
]
}
}
}
访问路径示例
sku = response["data"]["user"]["orders"][0]["items"][0]["sku"]
此类代码的特征非常明显:
访问链路极长
强依赖数据结构细节
可读性和可维护性迅速下降
6. 防御式访问:必要但有限的改进
为了避免异常,开发中常使用防御式写法:
user = response.get("data", {}).get("user", {})
orders = user.get("orders", [])
if orders:
first_order = orders[0]
这种方式可以:
降低运行期错误概率
提高代码健壮性
但需要清醒认识到:防御式访问解决的是“不崩溃”,而不是“结构合理”。
7. 嵌套结构的工程性问题总结
通过以上示例,可以清晰看到嵌套结构在工程中的局限:
结构定义分散:数据结构存在于代码路径中,而非集中定义
业务语义缺失:字段只是字符串,无法承载规则和含义
强耦合:结构变更会影响大量访问代码
逻辑与数据混杂:业务计算被迫写在遍历和索引中
当代码中大量出现如下形式时:
data["a"]["b"][0]["c"]["d"]
通常意味着:嵌套结构已经达到了可维护性的上限。
8. 嵌套结构在整体体系中的正确定位
嵌套 dict / list 并不是“错误做法”,而是阶段性工具:
| 使用场景 | 评价 |
|---|---|
| 原始 JSON 承载 | 合适 |
| 临时数据处理 | 合适 |
| 脚本 / Demo | 合适 |
| 核心业务模型 | 不合适 |
| 长期维护系统 | 不合适 |
它更适合作为:数据的“中间形态”,而非最终模型。
小结一下吧
嵌套结构是 Python 表达复杂数据的基础方式
它通过 dict + list 组合还原现实关系
随着层级加深,维护成本迅速上升
这正是引入 JSON 规范与 Class 建模的直接动因
接着我们将进入 半结构化数据:JSON 在 Python 中的处理,你会发现:JSON 的便利性,并没有从根本上解决嵌套结构的问题,而只是让它“标准化”了。
(三)半结构化数据:JSON 在 Python 中的处理
在上一节中,我们已经看到:通过 list 与 dict 的嵌套,Python 可以完整表达复杂数据结构,但可维护性迅速下降。
在真实工程中,这类嵌套结构往往并不是“手写”的,而是来自:
HTTP 接口返回
配置文件
消息队列
日志或存储系统
这些数据最常见的载体形式,就是 JSON(JavaScript Object Notation)。
1. 什么是半结构化数据
从数据组织角度看,数据大致可以分为三类:
非结构化数据:文本、图片、音频
结构化数据:表结构、强约束模型
半结构化数据:结构存在,但约束较弱
JSON 正是典型的半结构化数据格式,其特点是:
结构清晰(层级、键值)
可嵌套
无强类型约束
字段可选、可变
这使得 JSON 非常适合数据交换,但不适合直接作为业务模型。
2. JSON 的数据模型与 Python 的映射关系
JSON 本身支持的数据类型非常有限:
| JSON 类型 | Python 对应类型 |
|---|---|
| object | dict |
| array | list |
| string | str |
| number | int / float |
| boolean | bool |
| null | None |
也正因如此,JSON 在 Python 中的本质就是:嵌套的 dict 与 list
换句话说:JSON 并没有解决嵌套结构的问题,只是把它“标准化”了。
3. Python 中的 JSON 解析(反序列化)
Python 内置 json 模块,用于 JSON 与 Python 对象之间的转换。
import json
json_str = '''
{
"id": 1001,
"name": "Alice",
"active": true,
"roles": ["admin", "editor"]
}
'''
data = json.loads(json_str)
解析后:
data是一个 dict所有字段完全不受约束
访问方式与普通嵌套结构一致
name = data["name"] roles = data["roles"]
4. 从文件加载 JSON 数据
JSON 文件是配置与数据交换的常见形式(这里暂时先理解,后续这部分会在新博客单独讲解):
import json
with open("config.json", "r", encoding="utf-8") as f:
config = json.load(f)
此时你获得的是:
一个完全动态的嵌套结构
所有字段都只能“运行期验证”
5. JSON 的典型嵌套结构示例
考虑一个真实接口返回示例:
response = {
"code": 0,
"message": "success",
"data": {
"user": {
"id": 1001,
"name": "Alice",
"orders": [
{
"order_id": "ORD-001",
"items": [
{"sku": "SKU-1", "price": 100, "quantity": 2}
]
}
]
}
}
}
业务代码往往会这样写:
orders = response["data"]["user"]["orders"] first_item_price = orders[0]["items"][0]["price"]
到这里,你应该已经非常熟悉这种访问模式——它与嵌套结构没有任何本质区别。
6. JSON 带来的“结构假象”
JSON 的一个常见误区是:“有格式 ≠ 有模型”
虽然 JSON 看起来“结构清晰”,但它存在以下天然问题:
字段完全不受约束:缺字段不会报错,多字段也不会报错
类型不可靠:
price可能是数字,也可能是字符串,错误只能在运行期暴露业务语义缺失:
status = 1的含义无法自解释,需要依赖外部文档或注释结构变更极具破坏性:任意字段调整都会影响访问链
JSON 解决的是“数据如何传输”,而不是“数据如何使用”。
7. 防御式 JSON 解析的常见写法
为了避免运行期异常,代码中常见如下写法:
data = response.get("data", {})
user = data.get("user", {})
orders = user.get("orders", [])
if orders:
order_id = orders[0].get("order_id")
这种写法与上面讲的嵌套方式依旧没啥区别,更重要的是:仍然没有一个“明确的数据模型”。
8. JSON 在工程体系中的正确角色
在成熟系统中,JSON 的定位应当非常明确:
| 角色 | 是否合适 |
|---|---|
| 网络传输格式 | 非常合适 |
| 配置文件 | 合适 |
| 接口输入 / 输出 | 合适 |
| 业务内部模型 | 不合适 |
| 核心领域对象 | 不合适 |
JSON 更适合作为:系统边界上的数据格式,而非系统内部的结构表达。
系统引入结构化建模的阶段,Python 给出的答案是:
Class
dataclass
明确的数据模型定义
JSON ↔ Model 的转换边界
小结一下吧
JSON 是典型的半结构化数据格式
在 Python 中,JSON 本质仍是嵌套 dict / list
JSON 适合传输,不适合直接承载业务模型
防御式解析无法从根本上解决结构问题
这直接引出了:为什么必须使用 Class 进行结构化建模
(四)面向对象的结构化建模:Class 的引入
在前面的讲解中无论哪一步,数据始终以同一种形态存在:dict,只是内容变“干净”了而已。
接下来将通过一组连续示例说明:为什么必须引入 Class,以及 Class 在工程中应该如何使用。
1. 问题起点:业务逻辑正在“侵蚀”数据结构
先看一个非常真实的场景,接口返回订单数据:
order_data = {
"order_id": "ORD-001",
"price": "100",
"quantity": 2
}
业务中需要计算订单金额,代码往往这样写:
total_amount = int(order_data["price"]) * order_data["quantity"]
这段代码没有语法问题,但存在严重的工程隐患:
类型转换是“临时的”
规则是“隐含的”
任意地方都可以重复这段逻辑
此时系统出现了第一个危险信号:业务规则开始散落在 dict 操作中。
2. 第一次建模:用 Class 固定结构与类型
我们引入最基础的 Class,仅做一件事:把“字段定义”和“类型规则”集中到一个地方
class Order:
def __init__(self, order_id, price, quantity):
self.order_id = order_id
self.price = int(price)
self.quantity = int(quantity)
此时发生了三件非常重要的变化:
结构集中:
Order明确有哪些字段类型前置:类型转换只发生一次
使用成本下降:后续代码不再关心字段细节
业务代码变为:
order = Order("ORD-001", "100", 2)
3. 第二次建模:让业务行为回归模型
现在再看金额计算逻辑。如果继续写在外部:
total = order.price * order.quantity
虽然比 dict 好,但语义仍然分散。正确的工程做法是:只要逻辑“属于对象”,就应进入对象本身
class Order:
def __init__(self, order_id, price, quantity):
self.order_id = order_id
self.price = int(price)
self.quantity = int(quantity)
def total_amount(self):
return self.price * self.quantity
此时:
金额计算的业务含义被明确命名
外部代码无需关心实现细节
total = order.total_amount()
4. 工程规范一:Class 不是“数据壳”,而是“业务单元”
到这里,可以明确一个重要规范:
一个 Class 不应该只是 dict 的替代品,而应该是一个“可用对象”。
如果一个 Class:
只有属性
没有任何方法
那它的价值是非常有限的。
5. 第三次建模:让 Class 成为解析与清洗的边界
回到真实输入数据的问题。接口返回的往往是 不可信 JSON:
raw_data = {
"order_id": "ORD-001",
"price": None,
"quantity": "2"
}
工程上正确的做法是:让 Class 成为“不可信数据 → 可信对象”的边界
class Order:
def __init__(self, data: dict):
self.order_id = data.get("order_id")
self.price = self._to_int(data.get("price"), default=0)
self.quantity = self._to_int(data.get("quantity"), default=1)
def _to_int(self, value, default=0):
try:
return int(value)
except (TypeError, ValueError):
return default
此时:
所有防御逻辑被“封装”
外部世界不再处理脏数据
构造完成的对象即“可用对象”
6. 工程规范二:业务代码只接触“可信对象”
正确的调用方式应当是:
order = Order(raw_data) total = order.total_amount()
而不是:
# ❌ 不推荐 total = int(raw_data["price"]) * int(raw_data["quantity"])
规范总结:
解析、清洗、校验,必须发生在模型内部
业务代码不应再做任何字段判断
7. 第四次建模:用对象组合替代嵌套结构
考虑一个更真实的订单结构:
raw_order = {
"order_id": "ORD-001",
"items": [
{"sku": "SKU-1", "price": "100"},
{"sku": "SKU-2", "price": "50"}
]
}
如果继续使用嵌套 dict:
total = 0
for item in raw_order["items"]:
total += int(item["price"])
正确的建模方式是:用对象组合替代嵌套结构
class OrderItem:
def __init__(self, data):
self.sku = data.get("sku")
self.price = int(data.get("price", 0))
class Order:
def __init__(self, data):
self.order_id = data.get("order_id")
self.items = [OrderItem(item) for item in data.get("items", [])]
def total_amount(self):
return sum(item.price for item in self.items)
此时,结构发生了质变:
嵌套 dict → 对象关系
遍历逻辑 → 模型内部能力
8. 工程规范三:嵌套数据 ≠ 嵌套 dict,而是“对象层级”
这是结构化建模中非常重要的一条规范:
嵌套关系应通过“对象组合”表达,而不是嵌套 dict 访问路径。
一旦遵循这条规范:
访问路径显著变短
代码可读性成倍提升
结构演进成本大幅下降
小结一下吧
通过示例可以总结出 Class 建模的核心工程规范:
Class 是模型,不是数据壳
结构、语义、行为必须统一
解析与清洗是模型的职责
业务代码只操作可信对象
嵌套关系用对象组合表达
到这里,你已经完成了:
从“操作数据” → “使用模型” 的关键转变
(五)复杂对象组合与领域建模
在真实系统中,所谓“复杂数据”,并不仅仅是 层级多,而是同时具备:
多层嵌套结构
不同子结构承担不同职责
局部规则 + 全局规则并存
数据来自不可信边界(接口 / MQ / DB)
这一节,我们用一个 接近真实电商/交易系统的数据模型,完整展示 Python 中的复杂领域建模方式。
1. 原始输入:近真实系统级 JSON 结构
这是一个 近真实工程中常见复杂度 的订单数据(已适度抽象):
raw_order = {
"order_id": "ORD-9001",
"user": {
"id": "U-1001",
"profile": {
"name": "Alice",
"level": "VIP"
}
},
"items": [
{
"sku": "SKU-1",
"pricing": {
"unit_price": "100",
"currency": "CNY"
},
"quantity": 2,
"discounts": [
{"type": "PROMOTION", "amount": "10"},
{"type": "VIP", "amount": "5"}
]
}
],
"payment": {
"method": "CREDIT_CARD",
"transactions": [
{"tx_id": "TX-1", "amount": "185"},
{"tx_id": "TX-2", "amount": "10"}
]
}
}
特点:
最深层级:5 层
同时包含:列表嵌套 + 对象嵌套
金额、规则、行为全部混在 JSON 中
如果直接用 dict 操作,这类代码几乎不可维护。
2. 第一步:识别领域与聚合边界(不是拆字段)
复杂建模的第一步不是写类,而是划分领域对象。
从业务语义出发:
| JSON 片段 | 领域对象 |
|---|---|
| order | Order(聚合根) |
| user | User |
| profile | UserProfile |
| items | OrderItem |
| pricing | Pricing |
| discounts | Discount |
| payment | Payment |
| transactions | PaymentTransaction |
原则:
只要一个子结构有“独立业务含义”,就值得一个 Class。
3. 底层值对象(Value Object)建模
Discount(最小业务单元)
class Discount:
def __init__(self, data):
self.type = data.get("type")
self.amount = int(data.get("amount", 0))
Pricing(价格不是一个字段,而是一组规则)
class Pricing:
def __init__(self, data):
self.unit_price = int(data.get("unit_price", 0))
self.currency = data.get("currency")
def total(self, quantity):
return self.unit_price * quantity
4. OrderItem:多层对象的“局部聚合”
class OrderItem:
def __init__(self, data):
self.sku = data.get("sku")
self.quantity = int(data.get("quantity", 1))
self.pricing = Pricing(data.get("pricing", {}))
self.discounts = [
Discount(d) for d in data.get("discounts", [])
]
def discount_amount(self):
return sum(d.amount for d in self.discounts)
def subtotal(self):
return self.pricing.total(self.quantity) - self.discount_amount()
注意这里已经出现了领域行为协同:
折扣规则不在 Order
价格规则不在 Order
OrderItem 自洽完成金额计算
5. 用户领域:嵌套对象中的语义建模
class UserProfile:
def __init__(self, data):
self.name = data.get("name")
self.level = data.get("level")
def is_vip(self):
return self.level == "VIP"
class User:
def __init__(self, data):
self.user_id = data.get("id")
self.profile = UserProfile(data.get("profile", {}))
6. 支付领域:独立聚合,不混入订单逻辑
class PaymentTransaction:
def __init__(self, data):
self.tx_id = data.get("tx_id")
self.amount = int(data.get("amount", 0))
class Payment:
def __init__(self, data):
self.method = data.get("method")
self.transactions = [
PaymentTransaction(tx)
for tx in data.get("transactions", [])
]
def paid_amount(self):
return sum(tx.amount for tx in self.transactions)
7. Order:真正的“领域聚合根”
class Order:
def __init__(self, data):
self.order_id = data.get("order_id")
self.user = User(data.get("user", {}))
self.items = [OrderItem(i) for i in data.get("items", [])]
self.payment = Payment(data.get("payment", {}))
def order_amount(self):
return sum(item.subtotal() for item in self.items)
def is_fully_paid(self):
return self.payment.paid_amount() >= self.order_amount()
注意:
Order 不参与任何底层计算
Order 只做“聚合协调”
各领域职责清晰、不交叉
8. 工程级规范总结(复杂场景)
这一示例隐含了一套非常重要的工程规范:
规范一:不要让聚合根“变胖”
金额计算下沉到 OrderItem
折扣规则不写在 Order
规范二:多层嵌套 ≠ 多层 dict
每一层都是对象
每一层都有行为
规范三:领域隔离
Payment 不知道 OrderItem 的存在
Order 不知道 Discount 的细节
规范四:结构变化可控
JSON 结构变化只影响局部 Class
这一节完成的不是“示例升级”,而是复杂度跃迁:
从 2 层嵌套 → 5 层嵌套
从数据组合 → 领域协作
从“能跑” → “可演进、可维护”
你现在已经具备:用 Python Class 构建真实业务领域模型的能力
(六)JSON ↔ Class 的双向转换:边界层与 DTO 设计
在 (五) 中,我们已经构建了一套复杂、内聚、可演进的领域模型。但此时如果直接将这些 Class 用在接口层或存储层,会立即遇到新的问题:
接口层需要 JSON
MQ / RPC 需要可序列化结构
数据库存储结构与领域模型不一致
外部系统字段经常变动
这引出了一个非常重要的工程问题:领域模型不应直接暴露在系统边界。
1. 为什么不能让领域模型“裸奔”到边界
一个常见但危险的做法是:
json.dumps(order.__dict__)
这种方式存在严重问题:
结构不可控:私有字段、内部状态一并暴露
语义污染:内部对象结构被外部依赖
变更风险极高:内部模型调整会破坏接口
无法做版本治理:接口字段无法演进
工程结论:领域模型 ≠ 接口数据模型
2. 边界层的核心职责
在工程上,通常需要一个边界层(Boundary Layer),它负责:
JSON → DTO
DTO → Domain Model
Domain Model → DTO
DTO → JSON
其中,DTO(Data Transfer Object) 是核心中介。
3. DTO 的设计原则(非常重要)
DTO 与领域模型的关系,应遵循以下原则:
只包含数据,不包含业务行为
结构扁平,面向接口需求
允许字段冗余或命名不一致
变化频率远高于领域模型
边界转换集中化
一个成熟系统中,应当遵循:
所有 JSON ↔ Domain 的转换,都集中在边界层完成
而不是:Controller 中拼 dict; Service 中解析字段; Model 中关心接口格式
3.1 示例:为 Order 定义输入 DTO
接口输入 JSON:
{
"order_id": "ORD-9001",
"user_id": "U-1001",
"items": [
{
"sku": "SKU-1",
"unit_price": "100",
"quantity": 2
}
]
}
对应 DTO:
class OrderCreateDTO:
def __init__(self, data):
self.order_id = data.get("order_id")
self.user_id = data.get("user_id")
self.items = data.get("items", [])
DTO 的特点:
不做复杂解析
不包含嵌套对象建模
只服务接口需求
3.2 DTO → Domain Model(反序列化边界)
将 DTO 转换为领域模型,是边界层的核心工作之一。
class OrderFactory:
@staticmethod
def from_create_dto(dto: OrderCreateDTO):
raw = {
"order_id": dto.order_id,
"user": {"id": dto.user_id},
"items": [
{
"sku": item["sku"],
"pricing": {"unit_price": item["unit_price"]},
"quantity": item["quantity"],
"discounts": []
}
for item in dto.items
]
}
return Order(raw)
注意几点:
DTO 不知道领域模型
领域模型不依赖 DTO
转换逻辑集中在 Factory / Assembler 中
3.3 Domain Model → DTO(序列化边界)
对外输出时,同样不能直接暴露领域模型。
class OrderResponseDTO:
def __init__(self, order: Order):
self.order_id = order.order_id
self.total_amount = order.order_amount()
self.paid = order.is_fully_paid()
再由 DTO 转为 JSON:
response = json.dumps(order_response_dto.__dict__)
3.4. 复杂结构下的 DTO 拆分策略
当结构进一步复杂时,应避免:
class BigDTO:
...
而采用:
OrderDTO
ItemDTO
PaymentDTO
再由 Assembler 负责组合。
3.5 防腐层(Anti-Corruption Layer)视角
在对接外部系统时,DTO 还承担着一个更重要的角色:
防止外部模型“污染”内部领域模型
字段改名、结构变更、类型异常,都被限制在 DTO 层。
小结一下吧
通过本节,你应该建立起以下清晰认知:
领域模型只服务领域逻辑
DTO 是系统边界的语言
JSON 永远不应直接进入领域模型
Factory / Assembler 是关键角色
边界清晰,系统才能长期演进
(七)使用 dataclass 与类型系统增强结构化建模
在前面的分享中,我们已经用“原生 Class”完成了复杂领域建模。但你可能已经感受到几个现实问题:
__init__代码大量重复字段类型只能靠约定
对象结构难以一眼看清
重构时缺乏工具辅助
这正是 dataclass 与类型系统 登场的时机。
1. 为什么在复杂建模阶段引入 dataclass
dataclass 并不是“语法糖”,而是结构化建模的工程工具。
它解决的核心问题是:
| 问题 | 原生 Class | dataclass |
|---|---|---|
| 字段声明 | 分散在 __init__ | 集中声明 |
| 类型表达 | 隐式 | 显式 |
| 可读性 | 中等 | 高 |
| 维护成本 | 高 | 低 |
工程结论:当模型成为系统核心资产时,必须使用 dataclass 或等价机制。
2. 从原生 Class 到 dataclass:逐步演进
先看之前写的的一个典型类:
class Discount:
def __init__(self, data):
self.type = data.get("type")
self.amount = int(data.get("amount", 0))
使用 dataclass 重构后:
from dataclasses import dataclass
@dataclass
class Discount:
type: str
amount: int
但这只是第一步,真实工程不会直接这样写。
3. dataclass 中的构造边界:__post_init__
在领域模型中:
字段是“结构”
校验、转换是“规则”
dataclass 提供 __post_init__ 来承载规则。
from dataclasses import dataclass
@dataclass
class Discount:
type: str
amount: int
def __post_init__(self):
self.amount = int(self.amount)
规范:类型转换、校验逻辑应放在 __post_init__,而不是外部代码。
4. 复杂对象中的 dataclass 组合
重构 Pricing:
from dataclasses import dataclass
@dataclass
class Pricing:
unit_price: int
currency: str = "CNY"
def total(self, quantity: int) -> int:
return self.unit_price * quantity
OrderItem:
from dataclasses import dataclass, field
from typing import List
@dataclass
class OrderItem:
sku: str
pricing: Pricing
quantity: int = 1
discounts: List[Discount] = field(default_factory=list)
def subtotal(self) -> int:
discount = sum(d.amount for d in self.discounts)
return self.pricing.total(self.quantity) - discount
此时,模型结构已经一眼可读。
5. 类型系统带来的“隐性收益”
引入类型标注后,产生的收益包括:
IDE 自动补全
静态检查(mypy / pyright)
重构安全性
模型即文档
例如:
def calculate_total(items: List[OrderItem]) -> int:
...
类型本身就表达了设计意图。
6. dataclass 与不可变建模(高级用法)
在部分领域中(如支付、账务),对象应当是不可变的。
@dataclass(frozen=True)
class PaymentTransaction:
tx_id: str
amount: int
不可变对象的工程意义:
防止状态被随意修改
更容易推理
更适合并发场景
7. dataclass ≠ DTO:职责仍然要分清
一个常见误区是:“既然 dataclass 很方便,那 DTO 也用它吧?”
可以,但要遵守原则:
| 对象 | 是否可用 dataclass | 是否包含行为 |
|---|---|---|
| DTO | 可以 | 不应该 |
| Domain Model | 强烈推荐 | 必须 |
关键点不是工具,而是职责。
8. 工程规范:领域模型的现代 Python 写法
综合前面内容,可以形成一套明确规范:
领域模型使用 dataclass
字段必须有类型
规则写在方法或
__post_init__嵌套关系通过类型表达
不可变对象优先用于关键领域
小结一下吧
通过 dataclass 与类型系统:
模型从“能用”变为“可靠”
结构从“隐式”变为“显式”
重构从“危险”变为“可控”
(八)领域模型与数据库模型的边界:ORM 与持久化设计
前面整体学习了解了:
复杂领域建模
明确的边界与 DTO
dataclass + 类型系统增强
系统几乎不可避免地会进入一个危险阶段:为了“省事”,开始让领域模型向数据库结构妥协。
这一节的目标,是明确划清领域模型与持久化模型的边界。
1. 一个常见但致命的误区
很多系统会出现如下代码风格:
class Order(Base):
__tablename__ = "orders"
id = Column(String, primary_key=True)
total_amount = Column(Integer)
看似优雅,实际上隐藏着几个问题:
领域模型被 ORM 污染
数据库结构决定了领域结构
业务规则被挤出模型
工程结论:ORM Model ≠ Domain Model
2. 三种模型的职责划分(必须牢记)
在成熟系统中,通常存在三类模型:
| 模型类型 | 关注点 | 变化频率 |
|---|---|---|
| DTO | 接口 / 边界 | 高 |
| Domain Model | 业务规则 | 中 |
| Persistence Model(ORM) | 表结构 | 低 |
它们解决的是完全不同的问题。
3. 领域模型为什么不应该“继承 ORM”
原因并不抽象:
数据库字段不是业务语言
ORM 强制扁平化结构
懒加载/会话污染领域行为
测试复杂度急剧上升
领域模型应当:
与数据库无关
可以脱离 ORM 独立运行与测试
4. 正确的工程结构示意
一个合理的工程分层应当是:
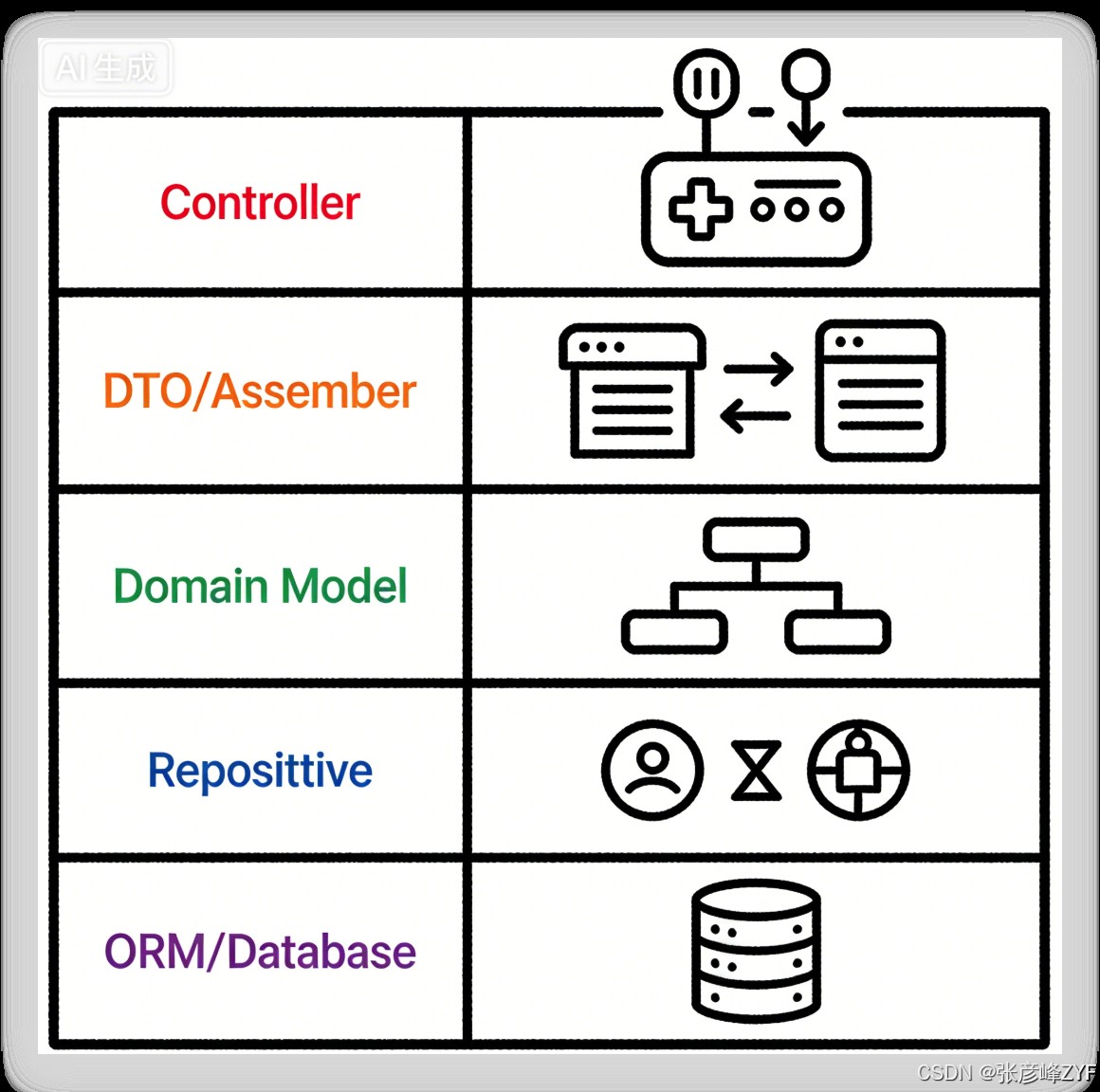
领域模型永远不直接操作数据库。
5. ORM Model:只做“表的映射”
以 SQLAlchemy 为例(仅作为概念说明):
class OrderORM(Base):
__tablename__ = "orders"
order_id = Column(String, primary_key=True)
total_amount = Column(Integer)
特点:
结构与表一一对应
没有业务行为
允许妥协命名
6. Repository:连接领域与持久化的桥梁
Repository 是最关键、但最容易被忽略的一层。
class OrderRepository:
def save(self, order: Order):
raise NotImplementedError
def get(self, order_id: str) -> Order:
raise NotImplementedError
领域层只依赖 接口,而不是实现。
7. ORM → Domain 的装配(反序列化)
class OrderRepositoryImpl(OrderRepository):
def get(self, order_id: str) -> Order:
orm = self.session.query(OrderORM).get(order_id)
raw = {
"order_id": orm.order_id,
"items": self._load_items(orm),
"payment": self._load_payment(orm)
}
return Order(raw)
注意:
ORM 结构被“翻译”
Domain Model 完全不知道 ORM 的存在
8. Domain → ORM 的持久化(序列化)
def save(self, order: Order):
orm = OrderORM(
order_id=order.order_id,
total_amount=order.order_amount()
)
self.session.add(orm)
即使结构重复,也要接受。重复是隔离的代价,也是稳定性的来源。
9. 工程规范:持久化永远是“外部关心的事”
领域模型中 绝对不应出现:
sessioncommitsave()ORM 注解
如果你在领域模型中看到这些,说明:领域已经被侵蚀。
小结一下吧
通过本节,你应当形成以下坚定认知:
领域模型不为数据库服务
ORM 只是技术实现
Repository 隔离变化
结构重复是合理且必要的
领域模型必须可以脱离数据库独立存在
(九)校验、异常与领域约束建模
现在我们已经解决了:
复杂结构如何建模
边界如何隔离
如何工程化增强模型
如何与数据库解耦
但到目前为止,仍有一个问题被刻意回避了:如果数据是“非法的”,怎么办?
现实系统中,非法数据是常态,而不是例外。
1. 一个常见但危险的现状
很多系统对“非法数据”的处理方式是:
if price <= 0:
return None
或者:
try:
...
except Exception:
pass
这些写法的问题不在于“能不能跑”,而在于:
错误被吞掉
规则被隐式化
系统进入“不可预期状态”
工程结论:校验不是工具层问题,而是领域模型的职责。
2. 什么是“领域约束”(Domain Constraint)
领域约束指的是:
业务上不允许被破坏的规则
与技术、存储、接口无关
一旦违反,系统就不应继续执行
例如:
订单金额不能为负
支付金额不能小于 0
已完成订单不能再次支付
这些规则 不属于 Controller,也不属于 Service,而是:领域模型自身的边界。
3. 领域异常:用“异常”表达规则破坏
在领域建模中,异常不是“程序错误”,而是:对业务规则被破坏的明确声明
首先,定义领域异常基类:
class DomainError(Exception):
pass
然后为关键规则定义具体异常:
class InvalidPriceError(DomainError):
pass
class PaymentAmountError(DomainError):
pass
class OrderStateError(DomainError):
pass
规范:不要在领域中直接抛 ValueError、TypeError。
4. 在模型内部执行校验(而不是外部 if)
以 OrderItem 为例:
from dataclasses import dataclass
@dataclass
class OrderItem:
sku: str
quantity: int
def __post_init__(self):
if self.quantity <= 0:
raise InvalidPriceError("quantity must be positive")
此时:
非法对象 根本无法被构造
错误在最早阶段暴露
5. 行为级校验:规则与动作绑定
不是所有校验都发生在构造阶段。
例如:支付行为。
class Order:
...
def pay(self, amount: int):
if amount <= 0:
raise PaymentAmountError("payment must be positive")
if self.is_fully_paid():
raise OrderStateError("order already paid")
self.payment.add_transaction(amount)
关键原则:规则应当与“动作”绑定,而不是与“字段”绑定。
6. 领域状态与约束的结合
复杂系统中,状态本身就是约束来源。
class OrderStatus:
CREATED = "CREATED"
PAID = "PAID"
CANCELED = "CANCELED"
class Order:
...
def cancel(self):
if self.status == OrderStatus.PAID:
raise OrderStateError("paid order cannot be canceled")
self.status = OrderStatus.CANCELED
此时:
状态转换路径被严格限制
非法流程无法发生
7. 校验逻辑的分层原则(非常重要)
一个成熟系统中,校验应分为三层:
| 层级 | 校验内容 | 示例 |
|---|---|---|
| 接口层 | 格式、必填 | JSON 字段是否存在 |
| 边界层 | 基本合法性 | 字符串能否转 int |
| 领域层 | 业务规则 | 金额、状态、约束 |
绝对禁止:在 Controller 中写业务规则判断。
8. 异常如何“向外传播”
领域异常的传播路径应当是:
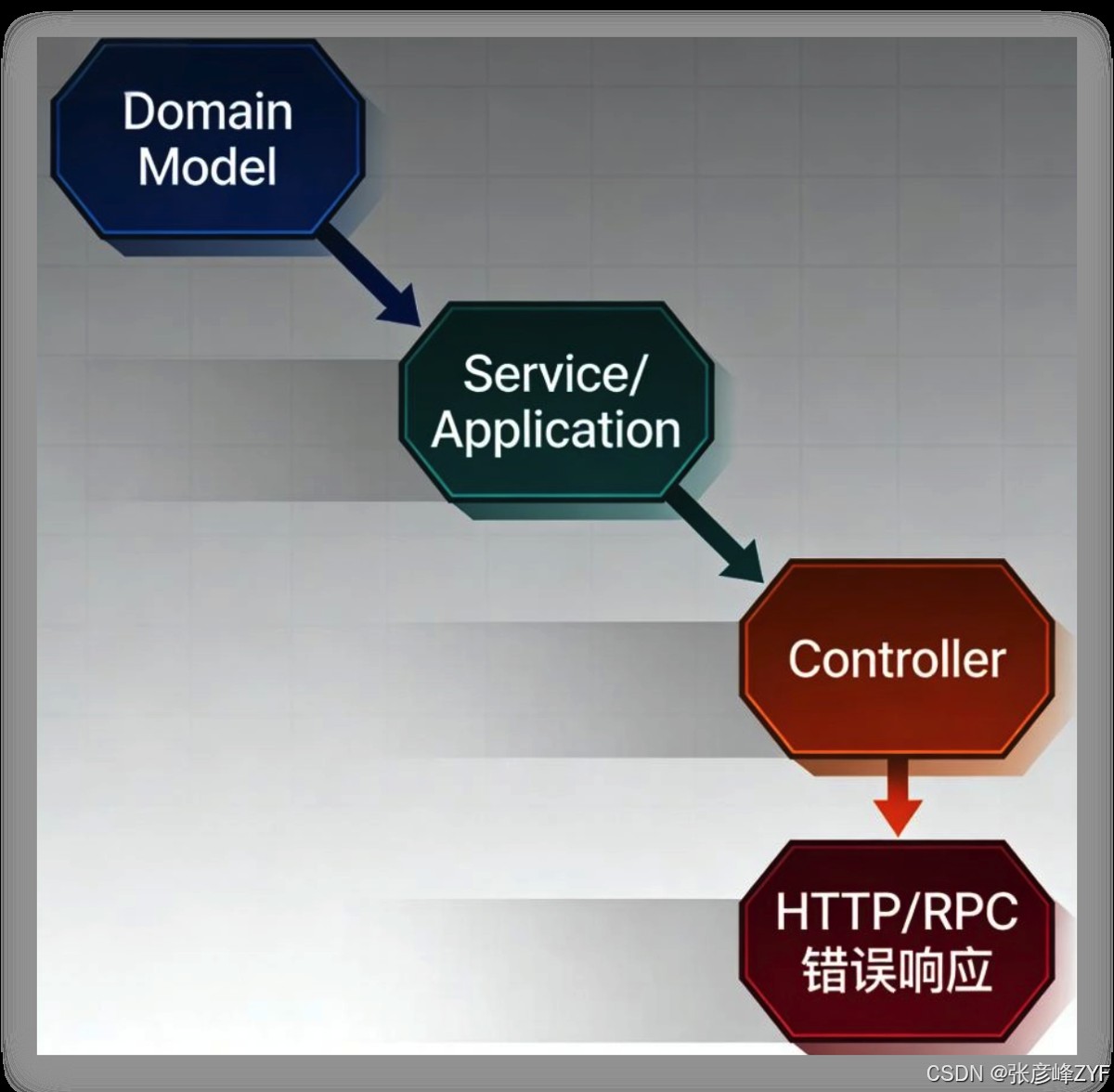
Controller 的职责不是“判断规则”,而是:
try:
order.pay(amount)
except DomainError as e:
return error_response(str(e))
9. 工程规范:失败是系统能力的一部分
一个系统是否健壮,不取决于:能否处理正常数据
而取决于:能否正确拒绝不合法行为
领域异常的价值在于:
规则显式
行为可追踪
错误不可忽略
八、总结
至此,本篇内容对 Python 基础知识进行了一个相对系统的梳理与总结。
从运行环境与工具选择,到变量、控制流、函数、字符串处理,再到列表、字典、集合等核心数据结构,本博客力求用工程视角 + 可运行示例的方式,期望在较短时间内建立起对 Python 编程的整体认知和基本实战能力。
需要说明的是,这份内容同样也是我在学习 Python 过程中的阶段性整理与沉淀。难免存在理解不够严谨或表述不够完善之处,欢迎各位读者在评论区留言指正、交流探讨,这对我和后续读者都会非常有价值。
如果你能通过本文:
理解 Python 的核心语法思想
看懂并独立编写基础程序
对后续深入学习(如数据处理、Web、自动化或 AI 方向)不再畏惧
那么这篇总结就达到了它应有的意义。
Python 是一门上手友好、上限极高的语言,但真正的成长来自持续实践,而不是一次性阅读。希望你在未来的学习过程中,多动手、多思考、多调试,把“会写”逐步变成“写得好、写得稳”。
以上就是入门初学者短期内快速掌握Python的经典全面教程(专家学习笔记)的详细内容,更多关于Python基础学习总结的资料请关注脚本之家其它相关文章!