
专家解析Python文件读写的理论与实践(从基础概念到工程应用)
作者:张彦峰ZYF
文件读写是所有编程语言中最基础、却也最容易被低估的能力。在 Python 中,open()、read()、write() 等接口看似直观,但其背后涉及操作系统文件模型、字符编码、缓冲机制以及资源管理等一整套抽象与约束。对这些机制理解不清,往往会导致内存浪费、性能问题,甚至隐蔽的生产故障。
我们将从文件系统与文件对象的基本模型出发,系统讲解 Python 中文件的打开、读取、写入与关闭过程,逐步深入到上下文管理、文件指针、二进制处理以及编码异常等关键议题。内容覆盖语言层面的用法,强调工程实践中的风险与最佳实践,让我们一起建立对 Python 文件读*“为何如此设计、应当如何正确使用”的完整认知。但整体内容难免存在理解不够严谨或表述不够完善之处,欢迎各位读者在评论区留言指正、交流探讨,这对我和后续读者都会非常有价值,感谢!

一、文件系统与文件对象基础
在讨论具体的读写 API 之前,必须先厘清两个层面的概念:操作系统中的文件,以及 Python 中的文件对象。前者决定“文件是什么”,后者决定“程序如何使用文件”。
(一)文件的概念:文本文件 vs 二进制文件
从操作系统角度看,文件本质上是一段按字节顺序存储的数据。所谓“文本文件”和“二进制文件”,并不是文件本身的物理差异,而是解释方式的差异。
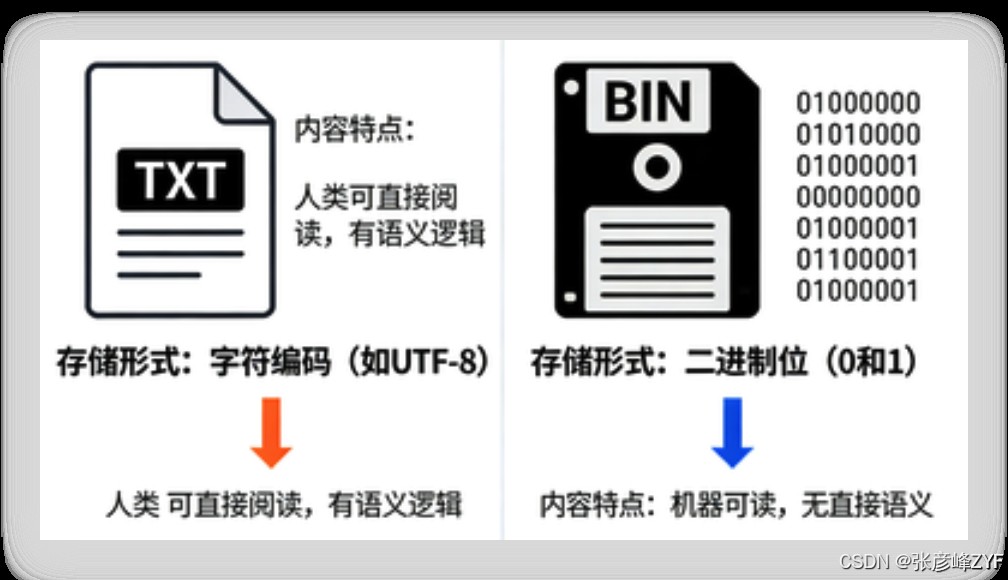
1. 文本文件(Text File)
内容可以通过某种字符编码(如 UTF-8)映射为字符序列
常见形式:
.txt、.py、.csv、.json读写时需要关注编码与换行符处理
2. 二进制文件(Binary File)
内容不应被解释为字符
常见形式:图片、音频、视频、压缩包
读写单位是
bytes,不存在编码概念
在 Python 中,这一差异直接体现在打开模式上:是否使用文本模式或二进制模式,决定了数据在“字节”与“字符”之间是否发生自动转换。
(二)操作系统视角下的文件路径
文件路径是操作系统用于定位文件的标识符,Python 只是将路径原样传递给操作系统。
绝对路径
从文件系统根目录开始
唯一、明确,不依赖当前运行环境
相对路径
相对于“当前工作目录”(Current Working Directory)
更灵活,但对运行位置敏感
需要注意的工程事实:
Python 并不保证脚本所在目录就是当前工作目录
相对路径错误是文件操作中最常见的问题之一
在实践中,应明确区分:
代码所在路径
程序运行时的工作路径
配置或数据文件的存放路径
(三)Python 文件对象(file object)的抽象模型
在 Python 中,程序并不直接操作操作系统文件,而是通过 文件对象(file object) 这一抽象层。
文件对象的核心特征包括:
封装了底层文件描述符
维护当前文件指针位置(offset)
管理缓冲区、编码转换等行为
提供统一的读写接口(
read、write等)
可以将文件对象理解为:操作系统文件的“安全代理”,负责在 Python 运行时管理访问细节与资源生命周期。
一旦文件对象被创建:
它就占用系统资源
它的生命周期需要被显式或隐式管理
错误使用可能导致资源泄露或数据未写入磁盘
这也是后续必须引入关闭机制与上下文管理的根本原因。
(四)快速理解
文件在底层始终是字节序列,文本与二进制只是解释方式
路径问题源自操作系统,与 Python 运行环境强相关
Python 文件对象是对底层文件的受控抽象,是后续所有读写行为的核心载体
理解这一基础模型,是正确使用 open()、with 以及各类读写 API 的前提。
二、打开与关闭文件
文件操作从 open() 开始,也往往在 open() 处出问题。理解其行为边界,比记住参数列表更重要。
(一)open()的本质行为
open() 做的事情只有一件:向操作系统申请文件资源,并返回一个文件对象。
f = open("data.txt", "r", encoding="utf-8")
如果申请失败(路径错误、权限不足等),不会返回对象,而是直接抛异常。
(二)文件路径的确定性
open("data.txt") # 相对路径
open("/tmp/data.txt") # 绝对路径
关键事实:
相对路径依赖当前工作目录,而不是脚本所在目录
Python 不会自动创建中间目录
错误示例:
open("logs/app/log.txt", "w")
# FileNotFoundError: 中间目录不存在
正确做法(目录需提前存在或手动创建):
import os
os.makedirs("logs/app", exist_ok=True)
open("logs/app/log.txt", "w")
(三)打开模式的真实语义(必须明确)
1. 只读:r
open("data.txt", "r")
文件必须存在
不允许写入
最安全的读取模式
2. 覆盖写入:w
open("data.txt", "w")
文件不存在:创建
文件存在:立即清空内容
常见误用源头
# 旧数据会被无条件清空
open("important.txt", "w")
3. 追加写入:a
open("data.txt", "a")文件不存在:创建
文件存在:从文件末尾写入
不影响原有内容
4. 独占创建:x
open("data.txt", "x")文件已存在:直接失败
适合防止误覆盖
5. 文本 vs 二进制:t / b
open("data.txt", "rt") # 文本(默认)
open("image.png", "rb") # 二进制
核心差异:
文本模式 →
str二进制模式 →
bytes二进制模式不允许
encoding
6. 读写混合:+
open("data.txt", "r+")
open("data.txt", "w+")
注意:
文件指针位置不会自动重置
容易产生“读不到内容”的错觉
(四)编码参数不是可选项
open("data.txt", "r", encoding="utf-8")工程级结论:
永远显式指定编码
不要依赖平台默认值
编码错误不会在
open()时出现,而是在读写时出现
错误示例:
open("data.txt").read()
# UnicodeDecodeError(在某些系统上)
(五)文件对象与资源占用
f = open("data.txt")此时系统已分配:
文件描述符
内核缓冲区
相关系统资源
这些资源:
不会随变量销毁立即释放
依赖显式关闭或上下文管理
(六)close()的作用与风险
f.close()
关闭操作包含:
刷新写缓冲区
释放系统资源
标记文件对象为不可用
验证示例:
f = open("data.txt")
f.close()
f.read() # ValueError: I/O operation on closed file
(七)忘记关闭文件的后果(示例)
def write_log():
f = open("log.txt", "a")
f.write("log\n")
# 未关闭
长期运行后可能出现:
文件句柄耗尽
数据未完全写入磁盘
文件无法再次打开
(八)最小结论(直接可用)
open()是资源申请,不是普通函数调用w模式具有破坏性,必须慎用编码必须显式指定
凡是
open(),就必须有对应的关闭策略
正因手动关闭存在天然缺陷,上下文管理(with)才成为文件操作的标准写法。下一节将以代码为主,说明为什么 with 是不可替代的。
三、上下文管理与with语句
Python 提供 with 语句,解决手动 open / close 的潜在风险。核心目标是:保证资源使用结束时被正确释放,无论是否发生异常。
(一)手动关闭的风险示例
# 错误示范:异常中断导致文件未关闭
f = open("data.txt", "w", encoding="utf-8")
f.write("Hello World\n")
1 / 0 # 运行异常,f.close() 永远不会执行
后果:
文件写入可能未落盘
文件句柄未释放
长期运行可能导致资源泄露
(二)with语句的基本用法
with open("data.txt", "w", encoding="utf-8") as f:
f.write("Hello World\n")
1 / 0 # 异常仍会被抛出,但文件会被自动关闭
文件对象
f在with代码块内有效代码块结束时,无论是否异常,
f.close()自动执行
等价逻辑:
f = open("data.txt", "w", encoding="utf-8")
try:
f.write("Hello World\n")
1 / 0
finally:
f.close()
(三)多文件同时管理
手动管理多个文件时容易出错:
f1 = open("a.txt", "r")
f2 = open("b.txt", "w")
data = f1.read()
f2.write(data)
f1.close()
f2.close()
异常中任意一步都可能导致资源泄露。with 写法:
with open("a.txt", "r", encoding="utf-8") as src, \
open("b.txt", "w", encoding="utf-8") as dst:
dst.write(src.read())
特点:
多文件在同一作用域安全管理
自动关闭顺序由解释器保证
异常路径无需额外处理
(四)文件对象生命周期验证
with open("data.txt", "r", encoding="utf-8") as f:
print(f.closed) # False
print(f.closed) # True
说明:
with块内文件可用块结束后自动关闭
生命周期边界清晰可控
(五)写缓冲区自动刷新
with open("log.txt", "w", encoding="utf-8") as f:
f.write("line 1\n")
f.write("line 2\n")
# 退出 with 后,数据已安全写入磁盘,无需手动 flush()
(六)工程级最佳实践
# 推荐
with open("config.json", "r", encoding="utf-8") as f:
config = f.read()
# 不推荐
f = open("config.json", "r")
config = f.read()
f.close() # 容易因异常或维护疏忽导致关闭遗漏
总结:
凡是可以用
with的场景,都应使用with上下文管理不仅简化代码,更保证文件操作安全、数据完整
四、文本文件读取方式
Python 提供多种文本文件读取方式,不同方法适用于不同场景:从小文件一次性读取,到大文件逐行流式处理。理解每种方法的内存与性能特点,是高效、安全读写的关键。
(一)read():一次性读取整个文件
with open("data.txt", "r", encoding="utf-8") as f:
content = f.read()
print(content)
特点:
返回整个文件的字符串
内存占用与文件大小成正比
适用小文件,大文件可能导致内存溢出
可以限制读取字节数:
with open("data.txt", "r", encoding="utf-8") as f:
first_10_chars = f.read(10)
print(first_10_chars)
(二)readline():逐行读取
with open("data.txt", "r", encoding="utf-8") as f:
line1 = f.readline()
line2 = f.readline()
print(line1.strip(), line2.strip())
特点:
每次返回文件的一行
内存占用小,可处理大文件
返回字符串包含换行符
\n,需strip()去除
适用场景:
按逻辑逐行处理
避免一次性加载整个文件
(三)readlines():读取所有行到列表
with open("data.txt", "r", encoding="utf-8") as f:
lines = f.readlines()
print(lines) # ['line1\n', 'line2\n', ...]
特点:
返回列表,每个元素是一行
相当于
read()+splitlines(keepends=True)内存占用与文件大小成正比
不适合超大文件
(四)文件迭代器:推荐大文件逐行处理
with open("data.txt", "r", encoding="utf-8") as f:
for line in f:
process(line.strip()) # 自定义处理函数
特点:
最优内存性能,只在内存中保留一行
可结合生成器进行流水线处理
工程实践中大文件、日志处理首选
(五)文件指针示意
with open("data.txt", "r", encoding="utf-8") as f:
print(f.tell()) # 当前文件指针位置
f.readline()
print(f.tell()) # 指针向后移动
文件读取会移动文件指针
可以结合
seek()实现随机读取或跳过
(六)工程实践建议
小文件:
read()或readlines(),方便快速处理大文件:迭代器模式或
readline(),避免内存溢出逐行处理:尽量用迭代器
for line in f,兼顾效率与代码可读性处理多种编码时,显式指定
encoding,防止异常
五、文本文件写入方式
Python 中文本文件写入主要依赖 write() 和 writelines(),结合不同模式 (w, a, x) 可实现覆盖、追加或独占写入。理解缓冲机制、换行符和跨平台差异是写入安全和性能的关键。
(一)write():单次写入字符串
with open("output.txt", "w", encoding="utf-8") as f:
f.write("Hello World\n")
f.write("Python 文件写入示例\n")
特点:
接收单个字符串作为输入
不自动添加换行符
覆盖写入模式下,会清空原文件内容
追加模式示例:
with open("output.txt", "a", encoding="utf-8") as f:
f.write("追加内容\n")
(二)writelines():写入字符串序列
lines = ["第一行\n", "第二行\n", "第三行\n"]
with open("output.txt", "w", encoding="utf-8") as f:
f.writelines(lines)
特点:
接收可迭代对象(如列表)
不自动添加换行符,需在字符串末尾手动添加
\n对于批量写入非常高效
追加模式同样适用:
with open("output.txt", "a", encoding="utf-8") as f:
f.writelines(["追加行1\n", "追加行2\n"])
(三)写入模式差异
| 模式 | 行为 |
|---|---|
w | 文件存在则覆盖,不存在则创建 |
a | 文件存在则追加,不存在则创建 |
x | 文件存在则报错,不存在则创建 |
示例:
# 独占创建,防止覆盖
with open("new_file.txt", "x", encoding="utf-8") as f:
f.write("独占写入\n")
(四)写缓冲区与flush()
Python 默认使用缓冲区写入:
with open("output.txt", "w", encoding="utf-8") as f:
f.write("部分内容")
f.flush() # 强制刷新缓冲区到磁盘
flush()仅刷新缓冲区close()自动刷新并释放资源工程实践:异常敏感场景可调用
flush(),否则依赖上下文管理自动刷新
(五)换行符与跨平台差异
with open("output.txt", "w", encoding="utf-8", newline="\n") as f:
f.write("Unix 风格换行\n")
默认
newline=None时,Python 会自动转换\n为系统默认换行符显式设置
newline="\n"或newline="\r\n"可保证跨平台一致性
(六)工程实践建议
批量写入字符串序列时,优先
writelines()需要换行符自动管理时,可结合
print(..., file=f)使用避免在循环内频繁打开关闭文件,尽量在上下文管理块内完成全部写入
对重要文件写入,考虑
flush()或with以确保数据落盘
六、文件指针与随机访问
在 Python 中文本或二进制文件中,文件指针(offset)决定下一次读写操作的位置。理解 tell() 和 seek() 的使用,是实现随机访问、跳过数据或重复读取的基础。
(一)文件指针的概念
文件对象内部维护一个 指针位置
读写操作总是从指针当前位置开始
操作完成后,指针自动向前移动
with open("data.txt", "r", encoding="utf-8") as f:
print(f.tell()) # 输出初始指针位置,通常为 0
line = f.readline()
print(f.tell()) # 指针移动到下一行的起始位置
(二)tell():获取当前指针位置
with open("data.txt", "r", encoding="utf-8") as f:
print(f.tell()) # 0
f.read(5)
print(f.tell()) # 5(已读取5个字符)
用途:
在文件中标记当前位置
在需要回退或重复读取时使用
(三)seek():移动文件指针
with open("data.txt", "r", encoding="utf-8") as f:
f.read(10)
f.seek(0) # 回到文件开头
content = f.read() # 从头开始读取
参数:
f.seek(offset, whence)
offset:相对位置whence:0(默认):文件开头1:当前位置2:文件末尾
示例:从文件末尾倒数 10 个字节开始读取(仅二进制安全,文本模式需注意编码):
with open("data.txt", "rb") as f:
f.seek(-10, 2)
print(f.read())
(四)文本模式 vs 二进制模式差异
文本模式:
seek()和tell()的行为受编码影响不保证字节精确偏移,通常按字符或缓冲单位跳转
二进制模式:
偏移精确,以字节为单位
推荐用于随机访问或文件尾部操作
with open("data.bin", "rb") as f:
f.seek(100, 0) # 跳过前100字节
chunk = f.read(50)
(五)工程实践示例:跳过表头读取 CSV
with open("data.csv", "r", encoding="utf-8") as f:
f.readline() # 跳过表头
for line in f:
process(line.strip())
结合 seek() 可以实现:
with open("data.csv", "r", encoding="utf-8") as f:
header_pos = f.tell() # 记录表头结束位置
f.readline()
for line in f:
process(line.strip())
f.seek(header_pos) # 回到表头后重读
(六)常见误区与限制
文本模式下
seek()不能保证按字节精确定位对超大文件,频繁
seek()会影响性能读写混合模式(
r+,w+)下需注意文件指针位置,可能需要seek()调整
(七)工程实践总结
小文件:通常不需要手动控制指针
大文件或二进制文件:指针控制是随机访问、分块处理的基础
文本文件:尽量按行读取,减少手动
seek(),防止编码问题二进制文件:随机访问安全高效,可结合
seek()和tell()实现任意位置读写
七、二进制文件读写
二进制文件不同于文本文件,其内容以 字节序列 (bytes) 存储,不进行字符编码转换。典型场景包括图片、音频、视频、压缩文件等。理解二进制模式及其读写方法是工程处理大文件和非文本数据的基础。
(一)二进制模式打开文件
常用模式:
rb:只读二进制wb:写入二进制(覆盖)ab:追加二进制r+b/w+b:读写二进制
# 读取二进制文件
with open("image.png", "rb") as f:
data = f.read()
print(type(data)) # <class 'bytes'>
# 写入二进制文件
data = b'\x89PNG\r\n\x1a\n' # PNG 文件头示例
with open("new_image.png", "wb") as f:
f.write(data)
(二)写入与读取字节对象
# 写入字节序列
with open("output.bin", "wb") as f:
f.write(b'\x00\x01\x02\x03')
# 读取字节序列
with open("output.bin", "rb") as f:
chunk = f.read(4)
print(chunk) # b'\x00\x01\x02\x03'
特点:
返回
bytes对象写入必须是
bytes或bytearray不进行编码/解码转换
(三)分块读取大文件
# 分块读取大文件,避免一次性占用内存
chunk_size = 1024 # 1 KB
with open("video.mp4", "rb") as f:
while chunk := f.read(chunk_size):
process(chunk) # 自定义处理函数
使用海象运算符 (
:=) 简洁控制循环内存占用恒定,可处理任意大小文件
(四)文件指针随机访问
with open("audio.mp3", "rb") as f:
f.seek(100) # 跳过前100字节
header = f.read(50) # 读取50字节
二进制模式下
seek()精确按字节偏移适合处理文件头、索引或分段读取
(五)二进制追加写入
with open("log.bin", "ab") as f:
f.write(b'\x01\x02\x03')
特点:
文件不存在时自动创建
文件存在时在末尾追加
适用于日志文件、二进制数据累积
(六)工程实践建议
非文本数据必须使用二进制模式,否则可能破坏数据
小文件:一次性读取写入即可
大文件:分块读取/写入,避免内存占用过高
随机访问:二进制模式下安全,文本模式可能因编码不一致出错
追加模式适用于日志或累积数据,覆盖模式适用于生成文件或重写数据
八、编码与字符集问题
在 Python 中文本文件读写过程中,编码 (encoding) 是核心问题。错误的编码可能导致 UnicodeDecodeError 或 UnicodeEncodeError,影响程序的稳定性和跨平台兼容性。理解编码原理并明确指定编码,是工程实践的必备规范。
(一)编码的基本概念
文件在磁盘上是字节序列 (
bytes)文本模式读写时,Python 会根据
encoding将字节序列 ↔ 字符串 (str) 转换常用编码:
utf-8:通用,多语言推荐gbk:中文 Windows 常用ascii:仅英文字符
(二)指定编码读写文件
# 指定 UTF-8 编码读取
with open("data.txt", "r", encoding="utf-8") as f:
content = f.read()
print(content)
# 指定 UTF-8 编码写入
with open("output.txt", "w", encoding="utf-8") as f:
f.write("中文字符示例\n")
工程实践:始终明确 encoding,不要依赖系统默认值。
(三)常见编码错误示例
1. 读取编码不匹配
# 文件实际编码为 UTF-8
with open("data.txt", "r", encoding="gbk") as f:
f.read()
# UnicodeDecodeError: 'gbk' codec can't decode byte 0xe4 ...
原因:
Python 按
gbk解码,遇到 UTF-8 字节序列报错
2. 写入编码不匹配
text = "中文字符"
with open("output.txt", "w", encoding="ascii") as f:
f.write(text)
# UnicodeEncodeError: 'ascii' codec can't encode characters ...
原因:
ascii无法表示非英文字符写入前必须确保编码支持目标字符集
(四)解决编码问题的策略
明确文件实际编码,并在
open()中指定统一工程编码标准,推荐 UTF-8
异常捕获与处理(必要时)
try:
with open("data.txt", "r", encoding="utf-8") as f:
content = f.read()
except UnicodeDecodeError:
print("读取文件编码错误,请检查文件编码或修改 encoding 参数")
(五)高级实践:带errors参数处理异常
with open("data.txt", "r", encoding="utf-8", errors="ignore") as f:
content = f.read() # 遇到无法解码的字符直接跳过
with open("output.txt", "w", encoding="utf-8", errors="replace") as f:
f.write("中文字符示例")
# 无法编码字符会被替换为 '?'
errors="ignore":忽略无法处理的字符errors="replace":替换无法处理字符工程实践中慎用,仅用于容错或日志输出
(六)工程实践建议
统一使用 UTF-8 编码,避免跨平台乱码
避免默认编码(
encoding=None),确保可控性二进制模式处理非文本数据,避免编码干扰
对外部文件进行预检查,确保与指定编码一致
九、常见文件操作异常处理
在 Python 文件操作中,异常是不可避免的,如文件不存在、权限不足或编码错误。正确捕获和处理异常,保证程序稳健,是工程实践的关键。
(一)文件不存在
try:
with open("missing.txt", "r", encoding="utf-8") as f:
content = f.read()
except FileNotFoundError as e:
print(f"文件未找到: {e}")
说明:
FileNotFoundError表示路径不存在可结合逻辑创建文件或提示用户
import os
file_path = "missing.txt"
if not os.path.exists(file_path):
with open(file_path, "w", encoding="utf-8") as f:
f.write("") # 创建空文件
(二)权限不足
try:
with open("/root/secret.txt", "w", encoding="utf-8") as f:
f.write("test")
except PermissionError as e:
print(f"权限不足: {e}")
说明:
PermissionError表示当前用户无权限访问文件工程实践:提前检查权限或调整运行环境
(三)编码异常
try:
with open("data.txt", "r", encoding="ascii") as f:
f.read()
except UnicodeDecodeError as e:
print(f"编码解码错误: {e}")
说明:
读取或写入时编码不匹配会抛出
UnicodeDecodeError或UnicodeEncodeError可结合
errors="ignore"或errors="replace"容错处理
with open("data.txt", "r", encoding="ascii", errors="ignore") as f:
content = f.read()
(四)异常捕获与上下文管理结合
try:
with open("data.txt", "r", encoding="utf-8") as f:
process(f.read())
except FileNotFoundError:
print("文件不存在")
except PermissionError:
print("无权限访问文件")
except UnicodeDecodeError:
print("编码错误")
with保证文件对象在异常发生时自动关闭异常捕获保证程序不会因单个文件操作崩溃
(五)捕获所有文件相关异常
try:
with open("data.txt", "r", encoding="utf-8") as f:
content = f.read()
except (FileNotFoundError, PermissionError, UnicodeDecodeError) as e:
print(f"文件操作失败: {e}")
工程实践:
避免捕获过于宽泛的
Exception精确捕获预期异常,提高可维护性
(六)工程实践总结
始终使用
with管理文件,保证资源安全释放预判常见异常:文件不存在、权限不足、编码错误
针对性捕获,提供清晰的错误提示或容错策略
不要依赖默认行为,如文件自动创建或默认编码,保证可控性
十、工程实践与最佳实践总结
文件读写不仅是语言特性问题,更是工程安全、性能和可维护性的核心环节。综合前面各部分,总结 Python 文件操作的实践原则,并通过代码示例展示高效安全的策略。
(一)文件读写的性能与安全原则
1. 使用上下文管理
with open("data.txt", "r", encoding="utf-8") as f:
content = f.read()
# 自动关闭文件,无需手动 close()
2. 避免一次性读取超大文件
with open("large_file.txt", "r", encoding="utf-8") as f:
for line in f:
process(line.strip()) # 流式处理
3. 明确编码,避免平台差异
with open("data.txt", "r", encoding="utf-8") as f:
content = f.read()
4. 捕获常见异常
try:
with open("data.txt", "r", encoding="utf-8") as f:
process(f.read())
except FileNotFoundError:
print("文件不存在")
except PermissionError:
print("无权限访问文件")
(二)大文件处理策略(流式读取)
chunk_size = 1024 * 1024 # 1 MB
with open("huge_file.bin", "rb") as f:
while chunk := f.read(chunk_size):
process(chunk)
分块读取,保持内存占用恒定
适用于视频、音频、压缩文件等大文件
结合二进制模式,保证数据完整性
(三)文件指针与随机访问
with open("data.txt", "r", encoding="utf-8") as f:
f.seek(100) # 跳过前100字节
chunk = f.read(50) # 读取50字符
二进制模式随机访问安全
文本模式随机访问需注意编码影响
可结合
tell()保存当前位置,实现文件分段处理
(四)写入优化与安全
lines = ["line1\n", "line2\n", "line3\n"]
with open("output.txt", "w", encoding="utf-8") as f:
f.writelines(lines) # 批量写入,提高性能
批量写入比循环多次调用
write()性能更好对关键文件写入,可在上下文管理块内完成所有操作,减少数据丢失风险
(五)工程级编码处理
try:
with open("data.txt", "r", encoding="utf-8", errors="replace") as f:
content = f.read()
except UnicodeDecodeError:
print("编码错误,已替换无法解码字符")
默认使用 UTF-8
遇到外部文件,可结合
errors参数处理异常二进制模式适合非文本文件或需要精确控制字节
(六)常见反模式总结
| 反模式 | 风险 | 正确做法 |
|---|---|---|
手动 open() + close() | 异常中资源泄露 | 使用 with 管理 |
一次性 read() 处理超大文件 | 内存溢出 | 使用迭代器或分块读取 |
| 不指定编码 | 跨平台乱码或异常 | 显式指定 encoding |
| 循环中频繁打开文件 | I/O 性能低下 | 批量处理或保持文件打开 |
捕获宽泛 Exception | 难以定位问题 | 捕获精确异常类型 |
(七)总结实践建议
文件操作总是使用
with小文件可一次性读取,大文件必须流式读取
二进制模式处理非文本数据
明确指定编码和异常处理策略
利用
seek()和tell()做随机访问或断点处理批量写入比循环写入高效且安全
避免依赖默认值或系统行为,保证跨平台一致性
十一、实际项目应用示例——日志分析工具
为了将前面学习的文件读写、编码、异常处理、随机访问等内容落地,我们以一个日志分析工具为例,完整展示如何在真实项目中运用这些技术。项目目标:
读取大型日志文件
按关键字筛选并统计日志条目
将结果写入输出文件
保证异常安全、内存高效、跨平台可靠
(一)项目结构
log_analyzer/ ├── input_logs/ │ └── app.log ├── output/ │ └── filtered_logs.txt └── analyze.py
(二)核心功能实现
1. 流式读取大文件
# analyze.py
LOG_PATH = "input_logs/app.log"
KEYWORD = "ERROR"
def filter_logs(input_path, keyword):
"""按关键字过滤日志行"""
with open(input_path, "r", encoding="utf-8", errors="ignore") as f:
for line in f:
if keyword in line:
yield line.strip()
使用 文件迭代器,避免一次性读取大文件
errors="ignore"防止编码异常导致程序中断
2. 统计日志数量
def count_logs(lines):
count = 0
for _ in lines:
count += 1
return count
可以直接对生成器
filter_logs()迭代不占用额外内存存储全部数据
3. 写入输出文件
OUTPUT_PATH = "output/filtered_logs.txt"
def save_logs(lines, output_path):
with open(output_path, "w", encoding="utf-8") as f:
for line in lines:
f.write(line + "\n")
使用批量写入循环写入
with保证写入完成后自动关闭文件
4. 完整流程整合
def main():
try:
filtered = filter_logs(LOG_PATH, KEYWORD)
total = count_logs(filtered)
print(f"共找到 {total} 条包含关键字 '{KEYWORD}' 的日志")
# 再次生成迭代器写入文件
filtered = filter_logs(LOG_PATH, KEYWORD)
save_logs(filtered, OUTPUT_PATH)
print(f"结果已写入 {OUTPUT_PATH}")
except FileNotFoundError:
print(f"文件未找到: {LOG_PATH}")
except PermissionError:
print(f"无权限访问文件")
except UnicodeDecodeError:
print(f"编码错误,请检查文件编码")
异常处理覆盖常见错误
流式读取避免内存爆炸
上下文管理保证资源释放
(三)扩展功能示例:随机访问文件尾部(查看最新日志)
def tail_logs(file_path, lines=10):
"""读取日志文件最后 N 行"""
with open(file_path, "rb") as f: # 二进制模式更安全
f.seek(0, 2) # 移动到文件末尾
size = f.tell()
offset = max(size - 1024, 0) # 从末尾 1 KB 开始读取
f.seek(offset, 0)
data = f.read().decode("utf-8", errors="ignore")
return data.splitlines()[-lines:]
利用 二进制模式 + seek() + tell() 实现快速尾部访问
避免读取整个大文件
(四)工程实践总结
文件打开模式:文本模式读取日志,二进制模式随机访问尾部
流式读取:保证大文件处理安全
编码处理:显式指定 UTF-8,errors="ignore" 防止异常
异常处理:FileNotFoundError、PermissionError、UnicodeDecodeError 全覆盖
写入输出文件:
with open()+ 循环写入随机访问:利用
seek()与tell()高效读取文件末尾
(五)使用示例
python analyze.py
输出示例:
共找到 125 条包含关键字 'ERROR' 的日志 结果已写入 output/filtered_logs.txt
十二、总结
本文系统、全面地讲解了 Python 文件读写的理论与实践,从基础概念到工程应用,内容涵盖了文件对象的抽象、打开与关闭、上下文管理、文本与二进制文件读写、文件指针与随机访问、编码问题、异常处理,以及在实际项目中的落地应用。通过大量可执行代码示例,我们展示了每种读写方式的使用场景、性能特点和潜在风险,让我们不仅理解语法,还能掌握工程实践方法。
在文本文件处理中,我们学习了 read()、readline()、readlines() 及迭代器模式的差异,并结合大文件流式读取策略保证内存安全;在写入中,掌握了 write() 与 writelines() 的使用,以及覆盖写入、追加写入和缓冲机制的处理方法。二进制文件部分重点展示了字节对象操作、分块读取以及随机访问的安全方法。编码与字符集章节强调了显式指定 encoding 与异常处理的重要性,而异常处理章节提供了工程化方案,覆盖文件不存在、权限不足和编码错误等常见问题。
最后,通过日志分析工具的实际项目示例,我们把前面学到的知识整合到一个完整可执行的工程实践中,体现了文件操作在真实场景中的高效、安全与可维护性。希望你能在实际开发中灵活运用这些技巧,提升代码质量与开发效率。愿你的每一次文件操作都顺利可靠,项目进展顺心如意。
到此这篇关于专家解析Python文件读写的理论与实践(从基础概念到工程应用)的文章就介绍到这了,更多相关Python文件读写核心机制与最佳实践内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!