
Python使用dis模块解析字节码
作者:闲人编程
引言
Python作为一门解释型语言,其代码执行过程对于大多数开发者来说似乎是一个"黑盒"。我们编写.py文件,Python解释器执行它,但中间发生了什么?答案就藏在Python字节码中。字节码是Python源代码编译后的中间表示,是Python虚拟机(PVM)实际执行的指令集。通过dis模块,我们可以揭开这层神秘面纱,深入理解Python代码的执行机制。本文将带领您全面探索Python字节码的世界,从基础概念到高级技巧,帮助您真正理解Python代码的执行本质。
一、Python字节码基础
1.1 什么是字节码
字节码是Python源代码编译后的中间表示形式,它是平台无关的、基于栈的指令集。当我们执行Python代码时,解释器首先将源代码编译为字节码,然后Python虚拟机执行这些字节码指令。
# 字节码基础概念演示
import dis
import types
from opcode import opname, opmap
class BytecodeFundamentals:
"""字节码基础概念演示类"""
def explain_bytecode_concept(self):
"""解释字节码的基本概念"""
concepts = {
"字节码定义": "Python源代码编译后的中间表示形式",
"文件扩展名": ".pyc (编译后的Python文件)",
"执行环境": "Python虚拟机(PVM)",
"指令特点": "基于栈的操作、平台无关、比源代码更接近机器码",
"查看工具": "dis模块(反汇编器)"
}
print("Python字节码核心概念:")
for concept, description in concepts.items():
print(f" • {concept}: {description}")
return concepts
def demonstrate_compilation_process(self):
"""演示编译过程"""
print("\n=== Python代码编译过程 ===")
# 源代码
source_code = """
def calculate(x, y):
result = x + y * 2
return result
"""
print("1. 源代码:")
print(source_code)
# 编译为字节码
code_obj = compile(source_code, '<string>', 'exec')
print("2. 编译为代码对象")
# 提取函数的代码对象
for const in code_obj.co_consts:
if isinstance(const, types.CodeType):
func_code = const
break
print("3. 代码对象信息:")
print(f" 函数名: {func_code.co_name}")
print(f" 参数数量: {func_code.co_argcount}")
print(f" 局部变量: {func_code.co_varnames}")
print(f" 常量: {func_code.co_consts}")
print("4. 字节码指令:")
dis.dis(func_code)
# 字节码指令集概述
class BytecodeInstructionSet:
"""字节码指令集分析"""
@staticmethod
def show_instruction_categories():
"""显示指令分类"""
print("\n=== 字节码指令分类 ===")
categories = {
"栈操作指令": [
"LOAD_FAST", "LOAD_CONST", "LOAD_GLOBAL",
"STORE_FAST", "POP_TOP", "DUP_TOP"
],
"算术运算指令": [
"BINARY_ADD", "BINARY_SUBTRACT", "BINARY_MULTIPLY",
"BINARY_TRUE_DIVIDE", "INPLACE_ADD"
],
"比较运算指令": [
"COMPARE_OP", "IS_OP", "CONTAINS_OP"
],
"控制流指令": [
"JUMP_FORWARD", "JUMP_ABSOLUTE",
"POP_JUMP_IF_FALSE", "POP_JUMP_IF_TRUE"
],
"函数调用指令": [
"CALL_FUNCTION", "CALL_METHOD",
"RETURN_VALUE", "YIELD_VALUE"
],
"容器操作指令": [
"BUILD_LIST", "BUILD_TUPLE",
"BUILD_MAP", "BUILD_SET"
]
}
for category, instructions in categories.items():
print(f"\n{category}:")
for instr in instructions:
if instr in opmap:
opcode = opmap[instr]
print(f" {instr:<20} (操作码: {opcode:3d})")
def demo_fundamentals():
"""演示字节码基础"""
fundamentals = BytecodeFundamentals()
fundamentals.explain_bytecode_concept()
fundamentals.demonstrate_compilation_process()
BytecodeInstructionSet.show_instruction_categories()
if __name__ == "__main__":
demo_fundamentals()
1.2 Python执行模型
理解Python字节码之前,我们需要了解Python虚拟机的执行模型:
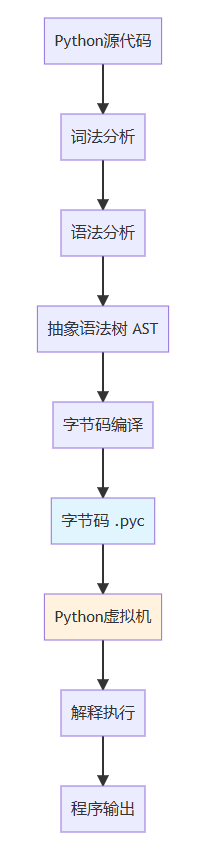
二、dis模块深度探索
2.1 dis模块核心功能
dis模块是Python标准库中的反汇编工具,它可以将字节码转换回人类可读的指令形式。
# dis模块深度探索
import dis
import sys
from types import CodeType, FunctionType
class DisModuleExplorer:
"""dis模块功能探索器"""
def demonstrate_basic_disassembly(self):
"""演示基本反汇编功能"""
print("=== 基本反汇编功能 ===")
# 简单的函数定义
def simple_function(a, b):
c = a + b
return c * 2
print("源代码:")
print(" def simple_function(a, b):")
print(" c = a + b")
print(" return c * 2")
print("\n反汇编结果:")
dis.dis(simple_function)
def analyze_code_object(self):
"""分析代码对象结构"""
print("\n=== 代码对象结构分析 ===")
def sample_function(x, y=10):
z = x + y
for i in range(3):
z += i
return z
# 获取代码对象
code_obj = sample_function.__code__
print("代码对象属性:")
attributes = [
('co_name', '函数名'),
('co_argcount', '参数数量'),
('co_nlocals', '局部变量数量'),
('co_stacksize', '栈大小'),
('co_flags', '标志位'),
('co_code', '字节码序列'),
('co_consts', '常量元组'),
('co_names', '名称元组'),
('co_varnames', '变量名元组'),
('co_filename', '文件名'),
('co_firstlineno', '第一行号'),
('co_lnotab', '行号表'),
('co_freevars', '自由变量'),
('co_cellvars', '单元格变量')
]
for attr, description in attributes:
if hasattr(code_obj, attr):
value = getattr(code_obj, attr)
print(f" {attr:<15} {description}: {value}")
def demonstrate_advanced_dis_features(self):
"""演示高级dis功能"""
print("\n=== 高级dis功能 ===")
def complex_function(data):
result = []
for item in data:
if item % 2 == 0:
result.append(item ** 2)
else:
result.append(item * 3)
return sum(result)
# 1. 显示字节码指令
print("1. 标准反汇编:")
dis.dis(complex_function)
# 2. 获取指令列表
print("\n2. 指令列表:")
instructions = dis.get_instructions(complex_function)
for instr in instructions:
print(f" {instr.opname:<20} {instr.arg:>4} {instr.argval}")
# 3. 显示堆栈效果
print("\n3. 堆栈效果分析:")
self._show_stack_effect(complex_function)
def _show_stack_effect(self, func):
"""显示指令的堆栈效果"""
code_obj = func.__code__
bytecode = code_obj.co_code
print(f"函数: {func.__name__}, 所需栈大小: {code_obj.co_stacksize}")
# 简化的堆栈效果分析
stack_effect = {
'LOAD_FAST': 1, # 推入一个值
'LOAD_CONST': 1, # 推入一个值
'STORE_FAST': -1, # 弹出一个值
'BINARY_ADD': -1, # 弹出两个值,推入一个值
'RETURN_VALUE': -1, # 弹出一个值
}
instructions = list(dis.get_instructions(func))
current_stack = 0
max_stack = 0
print(" 指令执行过程中的堆栈变化:")
for instr in instructions:
effect = stack_effect.get(instr.opname, 0)
current_stack += effect
max_stack = max(max_stack, current_stack)
print(f" {instr.opname:<20} 堆栈效果: {effect:>+2}, 当前堆栈: {current_stack:>2}")
print(f" 最大堆栈深度: {max_stack}")
# 字节码可视化工具
class BytecodeVisualizer:
"""字节码可视化工具"""
@staticmethod
def show_bytecode_hex(code_obj):
"""显示字节码的十六进制表示"""
print("\n=== 字节码十六进制表示 ===")
bytecode = code_obj.co_code
print(f"字节码长度: {len(bytecode)} 字节")
print("十六进制:", bytecode.hex())
# 解析字节码序列
print("\n字节码解析:")
i = 0
while i < len(bytecode):
opcode = bytecode[i]
opname_str = opname[opcode] if opcode < len(opname) else f"UNKNOWN({opcode})"
if opcode >= dis.HAVE_ARGUMENT:
arg = bytecode[i+1] + (bytecode[i+2] << 8)
print(f" 偏移 {i:3d}: {opname_str:<20} 参数: {arg:5d}")
i += 3
else:
print(f" 偏移 {i:3d}: {opname_str:<20}")
i += 1
def demo_dis_module():
"""演示dis模块功能"""
explorer = DisModuleExplorer()
explorer.demonstrate_basic_disassembly()
explorer.analyze_code_object()
explorer.demonstrate_advanced_dis_features()
# 可视化演示
def sample_func():
return 42
visualizer = BytecodeVisualizer()
visualizer.show_bytecode_hex(sample_func.__code__)
if __name__ == "__main__":
demo_dis_module()
2.2 字节码指令详解
让我们深入理解最常见的字节码指令及其作用:
# 字节码指令深度解析
import dis
from opcode import opmap, opname
class BytecodeInstructionAnalyzer:
"""字节码指令深度分析器"""
def analyze_common_instructions(self):
"""分析常见指令"""
print("=== 常见字节码指令分析 ===")
instructions_analysis = {
"LOAD_FAST": {
"功能": "加载局部变量到栈顶",
"参数": "局部变量索引",
"栈效果": "+1",
"示例": "加载函数参数或局部变量"
},
"LOAD_CONST": {
"功能": "加载常量到栈顶",
"参数": "常量元组索引",
"栈效果": "+1",
"示例": "加载数字、字符串等常量"
},
"LOAD_GLOBAL": {
"功能": "加载全局变量到栈顶",
"参数": "全局名称索引",
"栈效果": "+1",
"示例": "加载全局函数或变量"
},
"STORE_FAST": {
"功能": "存储栈顶值到局部变量",
"参数": "局部变量索引",
"栈效果": "-1",
"示例": "保存计算结果到变量"
},
"BINARY_ADD": {
"功能": "二进制加法运算",
"参数": "无",
"栈效果": "-1",
"示例": "执行 a + b 操作"
},
"CALL_FUNCTION": {
"功能": "调用函数",
"参数": "参数数量",
"栈效果": "-(参数数量), +1",
"示例": "调用函数或方法"
},
"RETURN_VALUE": {
"功能": "从函数返回值",
"参数": "无",
"栈效果": "-1",
"示例": "函数返回语句"
}
}
for instr, info in instructions_analysis.items():
print(f"\n{instr}:")
for key, value in info.items():
print(f" {key}: {value}")
def demonstrate_instruction_sequences(self):
"""演示指令序列模式"""
print("\n=== 常见指令序列模式 ===")
# 模式1: 变量赋值
print("1. 变量赋值模式:")
def assignment_pattern():
x = 10
y = 20
z = x + y
dis.dis(assignment_pattern)
# 模式2: 条件判断
print("\n2. 条件判断模式:")
def condition_pattern(a, b):
if a > b:
return a
else:
return b
dis.dis(condition_pattern)
# 模式3: 循环结构
print("\n3. 循环结构模式:")
def loop_pattern(n):
total = 0
for i in range(n):
total += i
return total
dis.dis(loop_pattern)
def show_opcode_statistics(self):
"""显示操作码统计"""
print("\n=== 操作码统计 ===")
def complex_example(data):
results = []
for item in data:
if isinstance(item, (int, float)):
squared = item ** 2
results.append(squared)
elif isinstance(item, str):
results.append(item.upper())
return results
# 统计指令使用频率
from collections import Counter
instructions = list(dis.get_instructions(complex_example))
opcode_counter = Counter(instr.opname for instr in instructions)
print("指令使用频率:")
for opcode, count in opcode_counter.most_common():
print(f" {opcode:<20}: {count:>2} 次")
# 指令执行模拟器
class InstructionSimulator:
"""字节码指令执行模拟器"""
def __init__(self):
self.stack = []
self.locals = {}
self.consts = []
self.names = []
def simulate_instructions(self, instructions):
"""模拟指令执行"""
print("\n=== 指令执行模拟 ===")
for instr in instructions:
print(f"执行: {instr.opname:<20} | 栈: {self.stack}")
if instr.opname == "LOAD_CONST":
self.stack.append(instr.argval)
elif instr.opname == "STORE_FAST":
self.locals[instr.argval] = self.stack.pop()
elif instr.opname == "LOAD_FAST":
self.stack.append(self.locals[instr.argval])
elif instr.opname == "BINARY_ADD":
b = self.stack.pop()
a = self.stack.pop()
self.stack.append(a + b)
elif instr.opname == "RETURN_VALUE":
result = self.stack.pop()
print(f"返回结果: {result}")
return result
return None
def demo_instruction_analysis():
"""演示指令分析"""
analyzer = BytecodeInstructionAnalyzer()
analyzer.analyze_common_instructions()
analyzer.demonstrate_instruction_sequences()
analyzer.show_opcode_statistics()
# 指令模拟演示
print("\n" + "="*50)
def simple_calculation():
a = 5
b = 3
c = a + b
return c
simulator = InstructionSimulator()
simulator.consts = simple_calculation.__code__.co_consts
simulator.names = simple_calculation.__code__.co_names
instructions = list(dis.get_instructions(simple_calculation))
# 过滤掉设置相关的指令,只关注核心计算
core_instructions = [instr for instr in instructions
if instr.opname in ['LOAD_CONST', 'STORE_FAST', 'LOAD_FAST', 'BINARY_ADD', 'RETURN_VALUE']]
simulator.simulate_instructions(core_instructions)
if __name__ == "__main__":
demo_instruction_analysis()
三、代码结构字节码分析
3.1 控制结构字节码
不同代码结构会生成特定的字节码模式,理解这些模式有助于我们深入理解Python执行机制。
# 控制结构字节码分析
import dis
from collections import defaultdict
class ControlStructureAnalyzer:
"""控制结构字节码分析器"""
def analyze_conditional_statements(self):
"""分析条件语句的字节码"""
print("=== 条件语句字节码分析 ===")
# if-else 结构
def if_else_example(x):
if x > 0:
return "positive"
else:
return "non-positive"
print("1. if-else 结构:")
dis.dis(if_else_example)
# if-elif-else 结构
def if_elif_else_example(x):
if x > 0:
return "positive"
elif x < 0:
return "negative"
else:
return "zero"
print("\n2. if-elif-else 结构:")
dis.dis(if_elif_else_example)
# 条件表达式
def conditional_expression(x):
return "even" if x % 2 == 0 else "odd"
print("\n3. 条件表达式:")
dis.dis(conditional_expression)
def analyze_loop_structures(self):
"""分析循环结构的字节码"""
print("\n=== 循环结构字节码分析 ===")
# for 循环
def for_loop_example(items):
total = 0
for item in items:
total += item
return total
print("1. for 循环:")
dis.dis(for_loop_example)
# while 循环
def while_loop_example(n):
i = 0
total = 0
while i < n:
total += i
i += 1
return total
print("\n2. while 循环:")
dis.dis(while_loop_example)
# 列表推导式
def list_comprehension_example(items):
return [x * 2 for x in items if x > 0]
print("\n3. 列表推导式:")
dis.dis(list_comprehension_example)
def analyze_function_calls(self):
"""分析函数调用的字节码"""
print("\n=== 函数调用字节码分析 ===")
def helper_function(x):
return x * 2
def function_call_example(a, b):
result1 = helper_function(a)
result2 = helper_function(b)
return result1 + result2
print("函数调用模式:")
dis.dis(function_call_example)
# 方法调用
def method_call_example():
text = "hello"
return text.upper().lower()
print("\n方法调用链:")
dis.dis(method_call_example)
def demonstrate_bytecode_patterns(self):
"""演示字节码模式识别"""
print("\n=== 字节码模式识别 ===")
patterns = {
"变量赋值": ["LOAD_CONST", "STORE_FAST"],
"二元运算": ["LOAD_FAST", "LOAD_FAST", "BINARY_*", "STORE_FAST"],
"函数调用": ["LOAD_GLOBAL", "LOAD_FAST", "CALL_FUNCTION", "STORE_FAST"],
"条件跳转": ["LOAD_FAST", "COMPARE_OP", "POP_JUMP_IF_FALSE"],
"循环结构": ["SETUP_LOOP", "GET_ITER", "FOR_ITER"]
}
print("常见字节码模式:")
for pattern_name, instruction_sequence in patterns.items():
print(f" {pattern_name}: {' → '.join(instruction_sequence)}")
# 性能模式分析
class PerformancePatternAnalyzer:
"""性能模式分析器"""
@staticmethod
def compare_efficient_vs_inefficient():
"""比较高效与低效代码的字节码"""
print("\n=== 高效 vs 低效代码字节码比较 ===")
# 低效版本
def inefficient_loop(n):
result = []
for i in range(n):
result.append(i * 2)
return result
# 高效版本
def efficient_loop(n):
return [i * 2 for i in range(n)]
print("1. 低效循环版本:")
dis.dis(inefficient_loop)
print("\n2. 高效列表推导式版本:")
dis.dis(efficient_loop)
# 分析差异
print("\n主要差异:")
differences = [
"列表推导式避免了方法调用开销",
"减少了局部变量的使用",
"更少的指令数量",
"更好的内存分配模式"
]
for diff in differences:
print(f" • {diff}")
def demo_control_structures():
"""演示控制结构分析"""
analyzer = ControlStructureAnalyzer()
analyzer.analyze_conditional_statements()
analyzer.analyze_loop_structures()
analyzer.analyze_function_calls()
analyzer.demonstrate_bytecode_patterns()
PerformancePatternAnalyzer.compare_efficient_vs_inefficient()
if __name__ == "__main__":
demo_control_structures()
3.2 高级语言特性字节码
Python的高级特性如装饰器、生成器、上下文管理器等都有独特的字节码模式。
# 高级语言特性字节码分析
import dis
import functools
from contextlib import contextmanager
class AdvancedFeatureAnalyzer:
"""高级语言特性字节码分析器"""
def analyze_decorators(self):
"""分析装饰器的字节码"""
print("=== 装饰器字节码分析 ===")
def simple_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print(f"调用函数: {func.__name__}")
return func(*args, **kwargs)
return wrapper
@simple_decorator
def decorated_function(x):
return x * 2
print("装饰器函数:")
dis.dis(simple_decorator)
print("\n被装饰的函数:")
dis.dis(decorated_function)
# 显示装饰器应用过程
print("\n装饰器应用等价代码:")
def equivalent_code():
def original_function(x):
return x * 2
# 手动应用装饰器
decorated = simple_decorator(original_function)
return decorated
dis.dis(equivalent_code)
def analyze_generators(self):
"""分析生成器的字节码"""
print("\n=== 生成器字节码分析 ===")
def simple_generator(n):
for i in range(n):
yield i * 2
def equivalent_loop(n):
result = []
for i in range(n):
result.append(i * 2)
return result
print("1. 生成器函数:")
dis.dis(simple_generator)
print("\n2. 等效循环函数:")
dis.dis(equivalent_loop)
# 分析生成器特性
gen_code = simple_generator.__code__
print(f"\n生成器特性:")
print(f" 协程标志: {gen_code.co_flags & 0x100 != 0}")
print(f" 生成器标志: {gen_code.co_flags & 0x20 != 0}")
print(f" 包含 YIELD_VALUE 指令: {'YIELD_VALUE' in [instr.opname for instr in dis.get_instructions(simple_generator)]}")
def analyze_context_managers(self):
"""分析上下文管理器的字节码"""
print("\n=== 上下文管理器字节码分析 ===")
@contextmanager
def simple_context():
print("进入上下文")
try:
yield "resource"
finally:
print("退出上下文")
def use_context_manager():
with simple_context() as resource:
print(f"使用资源: {resource}")
return resource.upper()
print("上下文管理器使用:")
dis.dis(use_context_manager)
# 显示等效的try-finally结构
print("\n等效的try-finally结构:")
def equivalent_try_finally():
manager = simple_context()
resource = manager.__enter__()
try:
print(f"使用资源: {resource}")
result = resource.upper()
finally:
manager.__exit__(None, None, None)
return result
dis.dis(equivalent_try_finally)
def analyze_class_definitions(self):
"""分析类定义的字节码"""
print("\n=== 类定义字节码分析 ===")
class SimpleClass:
class_attribute = "class_value"
def __init__(self, value):
self.instance_attribute = value
def method(self):
return self.instance_attribute * 2
print("类定义字节码:")
dis.dis(SimpleClass)
# 分析方法调用
print("\n实例方法调用:")
def method_call_demo():
obj = SimpleClass("test")
return obj.method()
dis.dis(method_call_demo)
# 字节码优化分析
class BytecodeOptimizationAnalyzer:
"""字节码优化分析器"""
@staticmethod
def demonstrate_constant_folding():
"""演示常量折叠优化"""
print("\n=== 常量折叠优化 ===")
# 常量表达式会在编译时计算
def with_constant_folding():
return 10 + 20 * 3 # 编译时计算为70
def without_constant_folding(a, b, c):
return a + b * c # 运行时计算
print("1. 常量折叠优化:")
dis.dis(with_constant_folding)
print("\n2. 无常量折叠:")
dis.dis(without_constant_folding)
print(f"\n常量折叠结果: {with_constant_folding()}")
@staticmethod
def demonstrate_peephole_optimizations():
"""演示窥孔优化"""
print("\n=== 窥孔优化 ===")
# 元组代替列表
def tuple_vs_list():
# 这些会在编译时优化
a = [1, 2, 3] # 可能被优化为元组
b = (1, 2, 3)
return a, b
print("元组/列表优化:")
dis.dis(tuple_vs_list)
# 字符串连接优化
def string_optimization():
# 字符串连接优化
return "hello" + " " + "world" # 编译时连接
print("\n字符串连接优化:")
dis.dis(string_optimization)
def demo_advanced_features():
"""演示高级特性分析"""
analyzer = AdvancedFeatureAnalyzer()
analyzer.analyze_decorators()
analyzer.analyze_generators()
analyzer.analyze_context_managers()
analyzer.analyze_class_definitions()
BytecodeOptimizationAnalyzer.demonstrate_constant_folding()
BytecodeOptimizationAnalyzer.demonstrate_peephole_optimizations()
if __name__ == "__main__":
demo_advanced_features()
四、字节码性能分析
性能优化技巧
通过分析字节码,我们可以发现性能瓶颈并实施优化。
# 字节码性能分析与优化
import dis
import timeit
from collections import Counter
class BytecodePerformanceAnalyzer:
"""字节码性能分析器"""
def __init__(self):
self.performance_data = {}
def analyze_instruction_costs(self):
"""分析指令执行成本"""
print("=== 指令执行成本分析 ===")
# 基于经验的指令相对成本
instruction_costs = {
"LOAD_FAST": 1.0, # 快速局部变量访问
"LOAD_CONST": 1.0, # 快速常量访问
"LOAD_GLOBAL": 3.0, # 较慢的全局变量访问
"STORE_FAST": 1.0, # 快速局部变量存储
"BINARY_ADD": 2.0, # 算术运算
"CALL_FUNCTION": 10.0, # 函数调用开销
"IMPORT_NAME": 50.0, # 导入操作很昂贵
"BUILD_LIST": 5.0, # 容器构建
"FOR_ITER": 3.0, # 迭代开销
}
print("指令相对执行成本:")
for instr, cost in sorted(instruction_costs.items(), key=lambda x: x[1], reverse=True):
print(f" {instr:<20}: {cost:>5.1f}")
def compare_performance_patterns(self):
"""比较性能模式"""
print("\n=== 性能模式比较 ===")
# 模式1: 局部变量 vs 全局变量
global_var = 100
def use_global():
return global_var * 2 # 使用全局变量
def use_local():
local_var = 100
return local_var * 2 # 使用局部变量
print("1. 全局变量 vs 局部变量:")
print(" 全局变量版本:")
dis.dis(use_global)
print(" 局部变量版本:")
dis.dis(use_local)
# 性能测试
global_time = timeit.timeit(use_global, number=100000)
local_time = timeit.timeit(use_local, number=100000)
print(f" 性能比较: 全局={global_time:.4f}s, 局部={local_time:.4f}s")
print(f" 局部变量快 {global_time/local_time:.1f}x")
# 模式2: 函数调用开销
def small_function(x):
return x + 1
def with_function_calls(n):
total = 0
for i in range(n):
total += small_function(i) # 频繁函数调用
return total
def without_function_calls(n):
total = 0
for i in range(n):
total += i + 1 # 内联操作
return total
print("\n2. 函数调用开销:")
n = 1000
with_calls_time = timeit.timeit(lambda: with_function_calls(n), number=1000)
without_calls_time = timeit.timeit(lambda: without_function_calls(n), number=1000)
print(f" 性能比较: 有调用={with_calls_time:.4f}s, 无调用={without_calls_time:.4f}s")
print(f" 内联操作快 {with_calls_time/without_calls_time:.1f}x")
def profile_function_bytecode(self, func, *args):
"""分析函数的字节码性能特征"""
print(f"\n=== 函数字节码性能分析: {func.__name__} ===")
# 分析指令分布
instructions = list(dis.get_instructions(func))
opcode_distribution = Counter(instr.opname for instr in instructions)
print("指令分布:")
total_instructions = len(instructions)
for opcode, count in opcode_distribution.most_common():
percentage = count / total_instructions * 100
print(f" {opcode:<20}: {count:>3} ({percentage:5.1f}%)")
# 识别性能敏感指令
expensive_ops = ['CALL_FUNCTION', 'CALL_METHOD', 'LOAD_GLOBAL', 'IMPORT_NAME', 'BUILD_LIST']
expensive_count = sum(opcode_distribution.get(op, 0) for op in expensive_ops)
print(f"\n性能分析:")
print(f" 总指令数: {total_instructions}")
print(f" 昂贵指令数: {expensive_count}")
print(f" 昂贵指令比例: {expensive_count/total_instructions*100:.1f}%")
if expensive_count / total_instructions > 0.3:
print(" ⚠️ 警告: 高比例昂贵指令,可能存在性能问题")
else:
print(" ✅ 指令分布良好")
return opcode_distribution
# 实时性能监控
class RuntimePerformanceMonitor:
"""运行时性能监控器"""
@staticmethod
def monitor_bytecode_execution(func, *args, **kwargs):
"""监控字节码执行性能"""
import cProfile
import pstats
import io
print(f"\n=== 运行时性能监控: {func.__name__} ===")
# 使用cProfile进行分析
pr = cProfile.Profile()
pr.enable()
result = func(*args, **kwargs)
pr.disable()
s = io.StringIO()
ps = pstats.Stats(pr, stream=s).sort_stats('cumulative')
ps.print_stats(10) # 显示前10个最耗时的函数
print(s.getvalue())
return result
@staticmethod
def analyze_memory_usage_pattern():
"""分析内存使用模式"""
print("\n=== 内存使用模式分析 ===")
def memory_intensive():
# 创建大量临时对象
result = []
for i in range(1000):
# 每次迭代创建新列表
temp_list = [j for j in range(i % 100)]
result.append(temp_list)
return result
def memory_efficient():
# 更高效的内存使用
result = []
for i in range(1000):
# 重用模式或使用生成器
result.append(i % 100)
return result
print("内存密集型模式:")
dis.dis(memory_intensive)
print("\n内存高效模式:")
dis.dis(memory_efficient)
def demo_performance_analysis():
"""演示性能分析"""
analyzer = BytecodePerformanceAnalyzer()
analyzer.analyze_instruction_costs()
analyzer.compare_performance_patterns()
# 分析具体函数
def sample_function(data):
results = []
for item in data:
if item > 0:
results.append(item ** 2)
return sum(results)
analyzer.profile_function_bytecode(sample_function)
# 运行时监控
RuntimePerformanceMonitor.analyze_memory_usage_pattern()
if __name__ == "__main__":
demo_performance_analysis()
五、高级字节码技巧
动态代码生成与修改
字节码不仅可用于分析,还可以用于动态生成和修改代码。
# 高级字节码技巧:动态代码操作
import dis
import types
import inspect
from opcode import opmap, opname
class DynamicBytecodeManipulator:
"""动态字节码操作器"""
def demonstrate_code_object_creation(self):
"""演示代码对象创建"""
print("=== 动态创建代码对象 ===")
# 手动创建简单的代码对象
try:
# 字节码序列 (简化版本)
# LOAD_CONST 0 (42)
# RETURN_VALUE
bytecode = bytes([
opmap['LOAD_CONST'], 0, 0, # 加载常量0
opmap['RETURN_VALUE'] # 返回值
])
# 创建代码对象
code_obj = types.CodeType(
0, # 参数数量
0, # 位置参数数量
0, # 关键字参数数量
1, # 局部变量数量
64, # 栈大小
67, # 标志位
bytecode, # 字节码
(42,), # 常量 (42)
(), # 名称
(), # 变量名
'<dynamic>', # 文件名
'dynamic_func', # 函数名
1, # 第一行号
b'' # 行号表
)
# 创建函数对象
dynamic_func = types.FunctionType(code_obj, {})
print("动态创建的函数:")
result = dynamic_func()
print(f"执行结果: {result}")
print("\n字节码:")
dis.dis(dynamic_func)
except Exception as e:
print(f"动态创建失败: {e}")
def demonstrate_bytecode_patching(self):
"""演示字节码修补"""
print("\n=== 字节码修补 ===")
def original_function(x):
return x * 2
print("原始函数:")
dis.dis(original_function)
print(f"原始执行: original_function(5) = {original_function(5)}")
# 修补字节码:将乘法改为加法
try:
original_code = original_function.__code__
original_bytecode = bytearray(original_code.co_code)
# 查找 BINARY_MULTIPLY 指令并替换为 BINARY_ADD
for i in range(0, len(original_bytecode), 2):
if original_bytecode[i] == opmap['BINARY_MULTIPLY']:
original_bytecode[i] = opmap['BINARY_ADD']
break
# 创建新的代码对象
patched_code = types.CodeType(
original_code.co_argcount,
original_code.co_posonlyargcount,
original_code.co_kwonlyargcount,
original_code.co_nlocals,
original_code.co_stacksize,
original_code.co_flags,
bytes(original_bytecode),
original_code.co_consts,
original_code.co_names,
original_code.co_varnames,
original_code.co_filename,
original_code.co_name + "_patched",
original_code.co_firstlineno,
original_code.co_lnotab
)
# 创建修补后的函数
patched_function = types.FunctionType(
patched_code,
original_function.__globals__,
original_function.__name__ + "_patched"
)
print("\n修补后的函数:")
dis.dis(patched_function)
print(f"修补后执行: patched_function(5) = {patched_function(5)}")
except Exception as e:
print(f"字节码修补失败: {e}")
def create_optimized_function(self, original_func):
"""创建优化版本的函数"""
print(f"\n=== 为 {original_func.__name__} 创建优化版本 ===")
# 分析原始函数
original_instructions = list(dis.get_instructions(original_func))
print("原始函数分析:")
expensive_ops = ['LOAD_GLOBAL', 'CALL_FUNCTION']
expensive_count = sum(1 for instr in original_instructions if instr.opname in expensive_ops)
print(f" 昂贵操作数量: {expensive_count}")
# 这里可以实施具体的优化策略
# 例如:缓存全局变量、内联小函数等
return original_func # 返回优化后的函数
# 字节码调试工具
class BytecodeDebugger:
"""字节码调试工具"""
@staticmethod
def trace_bytecode_execution(func, *args, **kwargs):
"""跟踪字节码执行"""
print(f"\n=== 字节码执行跟踪: {func.__name__} ===")
old_trace = sys.gettrace()
def trace_calls(frame, event, arg):
if event == 'line' and frame.f_code == func.__code__:
# 获取当前指令
code_obj = frame.f_code
bytecode = code_obj.co_code
offset = frame.f_lasti
if offset < len(bytecode):
opcode = bytecode[offset]
opname_str = opname[opcode] if opcode < len(opname) else f"UNKNOWN({opcode})"
# 显示堆栈和局部变量
stack_size = len(frame.f_stack) if hasattr(frame, 'f_stack') else 0
locals_str = {k: v for k, v in frame.f_locals.items() if not k.startswith('_')}
print(f" 行 {frame.f_lineno:3d} | 指令 {offset:3d}: {opname_str:<20} | "
f"栈大小: {stack_size:2d} | 局部变量: {locals_str}")
return trace_calls
sys.settrace(trace_calls)
try:
result = func(*args, **kwargs)
return result
finally:
sys.settrace(old_trace)
def demo_advanced_techniques():
"""演示高级技巧"""
manipulator = DynamicBytecodeManipulator()
manipulator.demonstrate_code_object_creation()
manipulator.demonstrate_bytecode_patching()
# 优化示例函数
def sample_to_optimize(n):
total = 0
for i in range(n):
# 模拟一些计算
squared = i * i
total += squared
return total
manipulator.create_optimized_function(sample_to_optimize)
# 执行跟踪演示
print("\n" + "="*60)
def function_to_trace(x, y):
a = x + y
b = a * 2
c = b - x
return c
BytecodeDebugger.trace_bytecode_execution(function_to_trace, 5, 3)
if __name__ == "__main__":
demo_advanced_techniques()
六、完整字节码分析工具
下面我们实现一个完整的字节码分析工具,集成前面讨论的所有功能:
"""
完整的字节码分析工具
集成反汇编、性能分析、优化建议等功能
"""
import dis
import timeit
import inspect
from collections import Counter, defaultdict
from typing import Dict, List, Any, Tuple
import sys
class ComprehensiveBytecodeAnalyzer:
"""综合字节码分析器"""
def __init__(self):
self.analysis_results = {}
self.performance_data = {}
def analyze_function(self, func, func_name: str = None) -> Dict[str, Any]:
"""全面分析函数"""
if func_name is None:
func_name = func.__name__
print(f"\n{'='*60}")
print(f"综合分析: {func_name}")
print(f"{'='*60}")
analysis = {
'function_name': func_name,
'code_object': func.__code__,
'basic_info': self._get_basic_info(func),
'instruction_analysis': self._analyze_instructions(func),
'performance_characteristics': self._analyze_performance(func),
'optimization_suggestions': self._generate_optimization_suggestions(func)
}
self.analysis_results[func_name] = analysis
self._print_analysis_report(analysis)
return analysis
def _get_basic_info(self, func) -> Dict[str, Any]:
"""获取基本信息"""
code_obj = func.__code__
return {
'filename': code_obj.co_filename,
'first_lineno': code_obj.co_firstlineno,
'arg_count': code_obj.co_argcount,
'local_count': code_obj.co_nlocals,
'stack_size': code_obj.co_stacksize,
'flags': code_obj.co_flags,
'constants': code_obj.co_consts,
'names': code_obj.co_names,
'variables': code_obj.co_varnames
}
def _analyze_instructions(self, func) -> Dict[str, Any]:
"""分析指令"""
instructions = list(dis.get_instructions(func))
opcode_distribution = Counter(instr.opname for instr in instructions)
# 指令分类
categories = {
'load_operations': ['LOAD_FAST', 'LOAD_CONST', 'LOAD_GLOBAL', 'LOAD_NAME'],
'store_operations': ['STORE_FAST', 'STORE_NAME', 'STORE_GLOBAL'],
'arithmetic_operations': ['BINARY_ADD', 'BINARY_SUBTRACT', 'BINARY_MULTIPLY', 'BINARY_TRUE_DIVIDE'],
'control_flow': ['JUMP_FORWARD', 'JUMP_ABSOLUTE', 'POP_JUMP_IF_FALSE', 'POP_JUMP_IF_TRUE'],
'function_calls': ['CALL_FUNCTION', 'CALL_METHOD'],
'expensive_operations': ['CALL_FUNCTION', 'CALL_METHOD', 'LOAD_GLOBAL', 'IMPORT_NAME', 'BUILD_LIST', 'BUILD_MAP']
}
category_counts = {}
for category, ops in categories.items():
category_counts[category] = sum(opcode_distribution.get(op, 0) for op in ops)
return {
'total_instructions': len(instructions),
'opcode_distribution': dict(opcode_distribution),
'category_counts': category_counts,
'expensive_ops_ratio': category_counts['expensive_operations'] / len(instructions) if instructions else 0
}
def _analyze_performance(self, func) -> Dict[str, Any]:
"""分析性能特征"""
# 简单的性能测试
try:
# 准备测试参数
test_args = self._generate_test_arguments(func)
# 执行时间测试
timer = timeit.Timer(lambda: func(*test_args))
execution_time = timer.timeit(number=1000) / 1000 # 平均执行时间
return {
'estimated_execution_time': execution_time,
'performance_rating': self._rate_performance(execution_time),
'memory_usage_hint': self._estimate_memory_usage(func)
}
except:
return {
'estimated_execution_time': None,
'performance_rating': '未知',
'memory_usage_hint': '无法估计'
}
def _generate_test_arguments(self, func):
"""生成测试参数"""
# 简化的参数生成逻辑
sig = inspect.signature(func)
test_args = []
for param in sig.parameters.values():
if param.annotation in (int, float):
test_args.append(42)
elif param.annotation == str:
test_args.append("test")
elif param.annotation == list:
test_args.append([1, 2, 3])
else:
test_args.append(None)
return test_args
def _rate_performance(self, execution_time: float) -> str:
"""评估性能等级"""
if execution_time < 0.0001:
return "优秀"
elif execution_time < 0.001:
return "良好"
elif execution_time < 0.01:
return "一般"
else:
return "需要优化"
def _estimate_memory_usage(self, func) -> str:
"""估计内存使用"""
code_obj = func.__code__
# 基于指令类型和数量简单估计
instructions = list(dis.get_instructions(func))
memory_ops = sum(1 for instr in instructions if instr.opname in ['BUILD_LIST', 'BUILD_MAP', 'BUILD_SET'])
if memory_ops > 10:
return "高内存使用"
elif memory_ops > 5:
return "中等内存使用"
else:
return "低内存使用"
def _generate_optimization_suggestions(self, func) -> List[str]:
"""生成优化建议"""
suggestions = []
instruction_analysis = self._analyze_instructions(func)
# 基于分析结果生成建议
expensive_ratio = instruction_analysis['expensive_ops_ratio']
if expensive_ratio > 0.3:
suggestions.append("减少全局变量访问和函数调用")
if instruction_analysis['category_counts']['load_operations'] > 20:
suggestions.append("考虑重用局部变量减少加载操作")
if instruction_analysis['category_counts']['function_calls'] > 5:
suggestions.append("内联小函数或使用方法缓存")
# 基于具体指令模式的建议
instructions = list(dis.get_instructions(func))
instruction_sequence = [instr.opname for instr in instructions]
# 检查常见的优化机会
if 'LOAD_GLOBAL' in instruction_sequence and instruction_sequence.count('LOAD_GLOBAL') > 3:
suggestions.append("缓存频繁访问的全局变量到局部变量")
if instruction_sequence.count('BUILD_LIST') > 2:
suggestions.append("考虑使用列表推导式或生成器表达式")
if not suggestions:
suggestions.append("代码已经相当优化")
return suggestions
def _print_analysis_report(self, analysis: Dict[str, Any]):
"""打印分析报告"""
basic_info = analysis['basic_info']
instr_analysis = analysis['instruction_analysis']
performance = analysis['performance_characteristics']
print("\n📊 基本信息:")
print(f" 文件: {basic_info['filename']}")
print(f" 行号: {basic_info['first_lineno']}")
print(f" 参数: {basic_info['arg_count']}, 局部变量: {basic_info['local_count']}")
print(f" 栈大小: {basic_info['stack_size']}")
print("\n📈 指令分析:")
print(f" 总指令数: {instr_analysis['total_instructions']}")
print(f" 昂贵操作比例: {instr_analysis['expensive_ops_ratio']:.1%}")
print(" 指令分布:")
for opcode, count in sorted(instr_analysis['opcode_distribution'].items(),
key=lambda x: x[1], reverse=True)[:10]:
percentage = count / instr_analysis['total_instructions'] * 100
print(f" {opcode:<20}: {count:>3} ({percentage:5.1f}%)")
print("\n⚡ 性能特征:")
if performance['estimated_execution_time']:
print(f" 估计执行时间: {performance['estimated_execution_time']:.6f}s")
print(f" 性能评级: {performance['performance_rating']}")
print(f" 内存使用: {performance['memory_usage_hint']}")
print("\n💡 优化建议:")
for i, suggestion in enumerate(analysis['optimization_suggestions'], 1):
print(f" {i}. {suggestion}")
print("\n" + "="*60)
def compare_functions(self, func1, func2, name1: str = "函数1", name2: str = "函数2"):
"""比较两个函数"""
print(f"\n{'='*60}")
print(f"函数比较: {name1} vs {name2}")
print(f"{'='*60}")
analysis1 = self.analyze_function(func1, name1)
analysis2 = self.analyze_function(func2, name2)
# 比较关键指标
print("\n📊 关键指标比较:")
metrics = [
('总指令数', analysis1['instruction_analysis']['total_instructions'],
analysis2['instruction_analysis']['total_instructions']),
('昂贵操作比例', analysis1['instruction_analysis']['expensive_ops_ratio'],
analysis2['instruction_analysis']['expensive_ops_ratio']),
]
if (analysis1['performance_characteristics']['estimated_execution_time'] and
analysis2['performance_characteristics']['estimated_execution_time']):
metrics.append(
('执行时间', analysis1['performance_characteristics']['estimated_execution_time'],
analysis2['performance_characteristics']['estimated_execution_time'])
)
for metric, value1, value2 in metrics:
if value1 is not None and value2 is not None:
if value1 < value2:
winner = f"{name1} 更好"
elif value1 > value2:
winner = f"{name2} 更好"
else:
winner = "平局"
print(f" {metric}: {name1}={value1}, {name2}={value2} → {winner}")
# 使用示例和演示
def demo_comprehensive_analyzer():
"""演示综合分析器"""
analyzer = ComprehensiveBytecodeAnalyzer()
# 示例函数1: 相对高效的实现
def efficient_sum(n):
return sum(i * i for i in range(n) if i % 2 == 0)
# 示例函数2: 相对低效的实现
def inefficient_sum(n):
total = 0
for i in range(n):
if i % 2 == 0:
total = total + i * i
return total
# 分析单个函数
analyzer.analyze_function(efficient_sum, "高效求和")
# 比较两个函数
analyzer.compare_functions(efficient_sum, inefficient_sum, "高效版本", "低效版本")
# 分析更复杂的函数
def complex_operation(data):
results = {}
for key, values in data.items():
if values:
processed = [v * 2 for v in values if v > 0]
results[key] = sum(processed) / len(processed) if processed else 0
return results
analyzer.analyze_function(complex_operation, "复杂操作")
if __name__ == "__main__":
demo_comprehensive_analyzer()
七、代码质量自查与最佳实践
字节码分析最佳实践
"""
字节码分析最佳实践和代码质量检查
"""
import ast
import inspect
from typing import List, Dict, Any
class BytecodeBestPractices:
"""字节码分析最佳实践"""
def __init__(self):
self.practices = self._initialize_best_practices()
def _initialize_best_practices(self) -> List[Dict[str, Any]]:
"""初始化最佳实践"""
return [
{
"category": "性能优化",
"practices": [
"优先使用局部变量而非全局变量",
"避免在循环中创建不必要的临时对象",
"使用列表推导式代替显式循环",
"缓存频繁访问的全局变量",
"使用生成器处理大数据集"
]
},
{
"category": "内存管理",
"practices": [
"及时释放不再需要的大对象",
"使用适当的数据结构减少内存开销",
"避免不必要的容器拷贝",
"使用__slots__减少类实例内存占用"
]
},
{
"category": "代码结构",
"practices": [
"保持函数简洁,单一职责",
"避免过深的嵌套结构",
"使用装饰器谨慎,注意性能影响",
"合理使用上下文管理器"
]
},
{
"category": "字节码分析",
"practices": [
"定期使用dis模块分析关键函数",
"关注LOAD_GLOBAL和CALL_FUNCTION指令数量",
"分析循环体内的指令模式",
"比较不同实现的字节码差异"
]
}
]
def check_function_against_practices(self, func) -> Dict[str, List[str]]:
"""检查函数是否符合最佳实践"""
results = {
"符合": [],
"警告": [],
"需改进": []
}
try:
# 获取字节码分析
instructions = list(dis.get_instructions(func))
opcode_sequence = [instr.opname for instr in instructions]
# 检查1: 全局变量使用
global_loads = opcode_sequence.count('LOAD_GLOBAL')
if global_loads > 5:
results["需改进"].append(f"频繁使用全局变量 ({global_loads}次LOAD_GLOBAL)")
elif global_loads > 2:
results["警告"].append(f"较多全局变量使用 ({global_loads}次LOAD_GLOBAL)")
else:
results["符合"].append("全局变量使用合理")
# 检查2: 函数调用频率
function_calls = opcode_sequence.count('CALL_FUNCTION')
if function_calls > 10:
results["需改进"].append(f"高频率函数调用 ({function_calls}次CALL_FUNCTION)")
elif function_calls > 5:
results["警告"].append(f"较多函数调用 ({function_calls}次CALL_FUNCTION)")
else:
results["符合"].append("函数调用频率适当")
# 检查3: 循环结构优化
if 'SETUP_LOOP' in opcode_sequence:
loop_start = opcode_sequence.index('SETUP_LOOP')
# 简单检查循环体内的操作
loop_ops = opcode_sequence[loop_start:loop_start+10] # 检查前10个指令
expensive_in_loop = sum(1 for op in loop_ops if op in ['LOAD_GLOBAL', 'CALL_FUNCTION'])
if expensive_in_loop > 3:
results["需改进"].append("循环体内包含昂贵操作")
elif expensive_in_loop > 1:
results["警告"].append("循环体内有较多昂贵操作")
else:
results["符合"].append("循环结构优化良好")
# 检查4: 常量使用
const_loads = opcode_sequence.count('LOAD_CONST')
if const_loads > 20:
results["警告"].append(f"较多常量加载 ({const_loads}次LOAD_CONST)")
else:
results["符合"].append("常量使用合理")
except Exception as e:
results["需改进"].append(f"分析过程中出错: {e}")
return results
def generate_practices_report(self):
"""生成最佳实践报告"""
print("=== Python字节码优化最佳实践 ===")
for category in self.practices:
print(f"\n{category['category']}:")
for practice in category['practices']:
print(f" • {practice}")
# 代码质量检查器
class CodeQualityChecker:
"""代码质量检查器"""
@staticmethod
def analyze_code_quality(func) -> Dict[str, Any]:
"""分析代码质量"""
print(f"\n=== 代码质量分析: {func.__name__} ===")
quality_report = {
"complexity": CodeQualityChecker._calculate_complexity(func),
"efficiency": CodeQualityChecker._assess_efficiency(func),
"maintainability": CodeQualityChecker._assess_maintainability(func),
"bytecode_metrics": CodeQualityChecker._get_bytecode_metrics(func)
}
# 打印报告
print(f"复杂度评分: {quality_report['complexity']}/10 (越低越好)")
print(f"效率评分: {quality_report['efficiency']}/10 (越高越好)")
print(f"可维护性: {quality_report['maintainability']}/10 (越高越好)")
# 字节码指标
metrics = quality_report['bytecode_metrics']
print(f"字节码指标:")
print(f" 总指令数: {metrics['total_instructions']}")
print(f" 昂贵指令比例: {metrics['expensive_ratio']:.1%}")
print(f" 函数调用次数: {metrics['function_calls']}")
return quality_report
@staticmethod
def _calculate_complexity(func) -> float:
"""计算代码复杂度"""
# 简化的复杂度计算
instructions = list(dis.get_instructions(func))
control_flow_ops = ['JUMP_FORWARD', 'JUMP_ABSOLUTE', 'POP_JUMP_IF_FALSE', 'POP_JUMP_IF_TRUE']
control_count = sum(1 for instr in instructions if instr.opname in control_flow_ops)
total_instructions = len(instructions)
complexity = (control_count / total_instructions * 100) if total_instructions > 0 else 0
return min(10, complexity / 10) # 归一化到0-10
@staticmethod
def _assess_efficiency(func) -> float:
"""评估效率"""
instructions = list(dis.get_instructions(func))
expensive_ops = ['LOAD_GLOBAL', 'CALL_FUNCTION', 'BUILD_LIST', 'BUILD_MAP']
expensive_count = sum(1 for instr in instructions if instr.opname in expensive_ops)
total_instructions = len(instructions)
efficiency_ratio = 1 - (expensive_count / total_instructions) if total_instructions > 0 else 1
return efficiency_ratio * 10 # 转换为0-10分
@staticmethod
def _assess_maintainability(func) -> float:
"""评估可维护性"""
# 基于一些启发式规则
score = 10.0 # 初始分数
instructions = list(dis.get_instructions(func))
total_instructions = len(instructions)
# 指令数量惩罚
if total_instructions > 50:
score -= 2
elif total_instructions > 100:
score -= 4
# 复杂控制流惩罚
control_flow_ops = ['JUMP_FORWARD', 'JUMP_ABSOLUTE', 'POP_JUMP_IF_FALSE', 'POP_JUMP_IF_TRUE']
control_count = sum(1 for instr in instructions if instr.opname in control_flow_ops)
if control_count > 10:
score -= 2
return max(0, score)
@staticmethod
def _get_bytecode_metrics(func) -> Dict[str, Any]:
"""获取字节码指标"""
instructions = list(dis.get_instructions(func))
opcode_sequence = [instr.opname for instr in instructions]
expensive_ops = ['LOAD_GLOBAL', 'CALL_FUNCTION', 'IMPORT_NAME']
expensive_count = sum(1 for op in opcode_sequence if op in expensive_ops)
return {
'total_instructions': len(instructions),
'expensive_ratio': expensive_count / len(instructions) if instructions else 0,
'function_calls': opcode_sequence.count('CALL_FUNCTION')
}
def demonstrate_best_practices():
"""演示最佳实践"""
practices = BytecodeBestPractices()
# 测试函数
def sample_function(data):
results = []
for item in data:
if item > 0:
squared = item * item
results.append(squared)
return sum(results)
# 检查最佳实践符合度
print("最佳实践符合度检查:")
results = practices.check_function_against_practices(sample_function)
for category, items in results.items():
print(f"\n{category}:")
for item in items:
print(f" • {item}")
# 代码质量分析
CodeQualityChecker.analyze_code_quality(sample_function)
# 生成最佳实践报告
print("\n" + "="*60)
practices.generate_practices_report()
if __name__ == "__main__":
demonstrate_best_practices()
总结
通过本文的深入探索,我们全面了解了Python字节码分析的世界:
核心知识回顾
- 字节码基础:Python代码编译后的中间表示,由Python虚拟机执行
- dis模块:强大的反汇编工具,可将字节码转换回可读的指令形式
- 指令系统:基于栈的操作模型,包含加载、存储、运算、控制流等指令类型
- 性能分析:通过字节码模式识别性能瓶颈和优化机会
关键技术要点
- 控制结构模式:if-else、循环、函数调用等都有特定的字节码模式
- 高级特性实现:装饰器、生成器、上下文管理器等的字节码表现
- 优化技巧:常量折叠、窥孔优化、指令选择等编译器优化
- 动态操作:代码对象创建、字节码修补等高级技巧
实践应用价值
掌握字节码分析具有重要的实践意义:
- 性能优化:识别性能瓶颈,实施针对性优化
- 代码理解:深入理解Python语言特性和执行机制
- 调试能力:定位复杂问题的根本原因
- 元编程:实现动态代码生成和修改
工具与方法 论
本文介绍的工具和方法 论包括:
ComprehensiveBytecodeAnalyzer:综合字节码分析工具BytecodeBestPractices:最佳实践检查器CodeQualityChecker:代码质量评估工具- 性能模式识别和优化建议生成
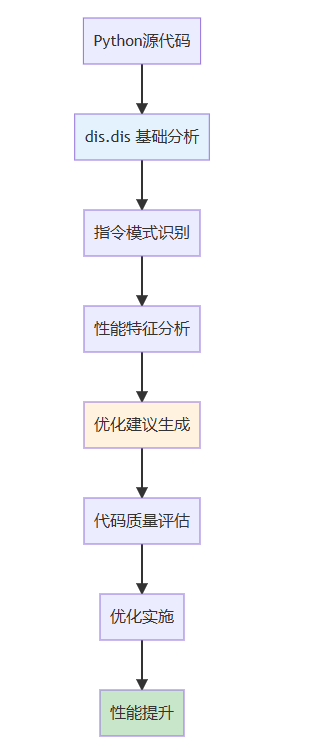
字节码分析是Python高级编程的重要技能,它让我们能够超越表面语法,真正理解代码的执行本质。通过本文的学习,您已经掌握了使用dis模块进行字节码分析的全面技能,能够在实际开发中诊断性能问题、优化代码质量,并深入理解Python语言的运行机制。
记住:优秀的开发者不仅要让代码工作,更要理解代码如何工作。字节码分析正是通向这种深度理解的关键路径。
以上就是Python使用dis模块解析字节码的详细内容,更多关于Python字节码的资料请关注脚本之家其它相关文章!