
Python中代码开发的调试技巧分享
作者:闲人编程
1. 引言
在软件开发的世界中,调试是每个程序员都无法回避的核心技能。据统计,程序员平均将**40-50%**的工作时间花费在调试和修复bug上。对于Python开发者而言,面对复杂问题时拥有系统的调试思维,往往比掌握具体的技术工具更为重要。
1.1 调试的本质
调试不仅仅是修复错误,更是一种系统性的问题解决思维方式。它涉及到:
- 问题定位:准确识别问题的根源
- 逻辑推理:基于证据进行系统性分析
- 实验设计:构建有效的测试和验证方案
- 解决方案:制定并实施有效的修复策略
著名计算机科学家Brian Kernighan曾说过:“调试的难度是编写代码的两倍。因此,如果你在编写代码时尽可能聪明,那么根据定义,你还没有足够的能力来调试它。” 这句话深刻地揭示了调试思维的重要性。
1.2 Python调试的特殊性
Python作为动态语言,具有独特的调试挑战和优势:
# Python的动态特性带来的调试挑战示例
class DynamicBehavior:
def __init__(self):
self.attributes = {}
def __getattr__(self, name):
# 动态属性访问可能隐藏潜在问题
if name in self.attributes:
return self.attributes[name]
else:
# 运行时才暴露的问题
raise AttributeError(f"'{self.__class__.__name__}' object has no attribute '{name}'")
# 这类问题在编译时无法发现,只能在运行时调试
obj = DynamicBehavior()
obj.attributes["existing"] = "value"
print(obj.existing) # 正常
print(obj.nonexistent) # 运行时错误
本文将深入探讨Python程序员在面对复杂问题时应具备的调试思维模式,并提供一套完整的调试方法和实践工具。
2. 调试思维框架
2.1 系统性调试方法
有效的调试应该遵循科学的思维框架。我们提出五步调试法:
class DebuggingMindset:
"""调试思维框架"""
def __init__(self):
self.steps = [
"问题重现",
"信息收集",
"假设生成",
"实验验证",
"解决方案"
]
def apply_framework(self, problem_description):
"""应用五步调试框架"""
print("=== 应用五步调试框架 ===")
results = {}
for step in self.steps:
print(f"\n步骤: {step}")
method = getattr(self, f"step_{step.lower().replace(' ', '_')}")
results[step] = method(problem_description)
return results
def step_问题重现(self, problem):
"""步骤1:确保问题可重现"""
print("目标:创建可靠的问题重现环境")
checklist = [
"✓ 确定问题发生的准确条件",
"✓ 创建最小重现用例",
"✓ 记录环境配置和依赖版本",
"✓ 验证问题的一致性"
]
return checklist
def step_信息收集(self, problem):
"""步骤2:全面收集相关信息"""
print("目标:收集所有相关数据和上下文")
information_sources = [
"错误堆栈跟踪",
"日志文件分析",
"系统状态快照",
"用户操作序列",
"相关配置信息"
]
return information_sources
def step_假设生成(self, problem):
"""步骤3:基于证据生成假设"""
print("目标:提出可能的问题根源假设")
hypothesis_techniques = [
"分治法:将问题分解为更小的部分",
"对比法:与正常工作状态对比",
"时间线分析:识别变化点",
"依赖分析:检查外部因素影响"
]
return hypothesis_techniques
def step_实验验证(self, problem):
"""步骤4:设计实验验证假设"""
print("目标:通过实验确认或排除假设")
validation_methods = [
"单元测试验证特定功能",
"日志注入获取更多信息",
"条件断点检查特定状态",
"A/B测试对比不同配置"
]
return validation_methods
def step_解决方案(self, problem):
"""步骤5:实施并验证解决方案"""
print("目标:实施修复并确保问题解决")
solution_steps = [
"实施最小化修复",
"添加回归测试",
"验证修复效果",
"文档记录问题和解决方案"
]
return solution_steps
# 使用示例
debugger = DebuggingMindset()
problem = "应用程序在处理大型数据集时内存泄漏"
results = debugger.apply_framework(problem)
2.2 认知偏见与调试陷阱
在调试过程中,程序员常常受到各种认知偏见的影响。了解这些陷阱有助于我们保持客观:
class CognitiveBiases:
"""调试中的认知偏见识别"""
def __init__(self):
self.biases = {
"确认偏见": "倾向于寻找支持自己假设的证据",
"锚定效应": "过分依赖最初获得的信息",
"可用性启发": "基于容易想到的案例做判断",
"专家盲点": "假设其他人拥有与自己相同的知识水平"
}
def check_biases(self, debugging_process):
"""检查调试过程中可能存在的认知偏见"""
warnings = []
if debugging_process.get('first_impression_dominates'):
warnings.append("⚠️ 锚定效应:可能过分依赖最初的问题判断")
if debugging_process.get('ignoring_contrary_evidence'):
warnings.append("⚠️ 确认偏见:可能忽略与当前假设矛盾的证据")
if debugging_process.get('overconfidence_in_solution'):
warnings.append("⚠️ 过度自信:可能过早确认问题根源")
return warnings
def mitigation_strategies(self):
"""偏见缓解策略"""
strategies = {
"寻求同行评审": "让他人检查你的推理过程",
"系统化记录": "详细记录所有证据,包括矛盾信息",
"考虑替代解释": "主动寻找其他可能的解释",
"定期反思": "定期回顾和质疑自己的假设"
}
return strategies
# 偏见检查示例
biases_checker = CognitiveBiases()
debugging_session = {
'first_impression_dominates': True,
'ignoring_contrary_evidence': False,
'overconfidence_in_solution': True
}
warnings = biases_checker.check_biases(debugging_session)
print("认知偏见警告:", warnings)
3. 系统化调试工具集
3.1 基础调试工具
Python提供了丰富的内置调试工具,掌握这些工具是调试思维的基础:
import logging
import pdb
import traceback
import sys
from functools import wraps
import time
class BasicDebuggingTools:
"""Python基础调试工具集"""
def __init__(self):
self.setup_logging()
def setup_logging(self, level=logging.DEBUG):
"""配置日志系统"""
logging.basicConfig(
level=level,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('debug.log'),
logging.StreamHandler(sys.stdout)
]
)
self.logger = logging.getLogger(__name__)
def debug_decorator(self, func):
"""调试装饰器:自动记录函数执行信息"""
@wraps(func)
def wrapper(*args, **kwargs):
self.logger.debug(f"调用函数: {func.__name__}")
self.logger.debug(f"参数: args={args}, kwargs={kwargs}")
start_time = time.time()
try:
result = func(*args, **kwargs)
execution_time = time.time() - start_time
self.logger.debug(f"函数 {func.__name__} 执行成功, 耗时: {execution_time:.4f}s")
return result
except Exception as e:
execution_time = time.time() - start_time
self.logger.error(f"函数 {func.__name__} 执行失败, 耗时: {execution_time:.4f}s")
self.logger.error(f"错误: {str(e)}")
self.logger.error(traceback.format_exc())
raise
return wrapper
def interactive_debugging(self, func, *args, **kwargs):
"""交互式调试包装器"""
print(f"开始交互式调试函数: {func.__name__}")
print("设置断点...")
# 设置跟踪函数以进入调试器
def trace_calls(frame, event, arg):
if event == 'call':
filename = frame.f_code.co_filename
lineno = frame.f_lineno
print(f"调用: {filename}:{lineno}")
return trace_calls
# 执行函数
try:
sys.settrace(trace_calls)
result = func(*args, **kwargs)
sys.settrace(None)
return result
except Exception as e:
print(f"捕获到异常,进入调试器...")
traceback.print_exc()
pdb.post_mortem(sys.exc_info()[2])
def memory_debugging(self, obj):
"""内存使用调试"""
import sys
size = sys.getsizeof(obj)
self.logger.info(f"对象 {type(obj)} 内存大小: {size} 字节")
if hasattr(obj, '__dict__'):
for attr, value in obj.__dict__.items():
attr_size = sys.getsizeof(value)
self.logger.info(f" 属性 {attr}: {attr_size} 字节")
return size
# 使用示例
tools = BasicDebuggingTools()
@tools.debug_decorator
def example_function(data):
"""示例函数演示调试工具"""
if not data:
raise ValueError("数据不能为空")
return [x * 2 for x in data if x > 0]
# 测试调试工具
try:
result = example_function([1, 2, 3, -1, 0, 4])
print("结果:", result)
# 测试错误情况
example_function([])
except Exception as e:
print("捕获到预期错误")
3.2 高级调试技术
对于复杂问题,需要更高级的调试技术:
import inspect
import gc
import objgraph
from contextlib import contextmanager
import threading
import cProfile
import pstats
import io
class AdvancedDebuggingTechniques:
"""高级调试技术"""
def __init__(self):
self.profiler = cProfile.Profile()
@contextmanager
def performance_profile(self, sort_by='cumulative', limit=10):
"""性能分析上下文管理器"""
self.profiler.enable()
try:
yield
finally:
self.profiler.disable()
# 生成分析报告
s = io.StringIO()
ps = pstats.Stats(self.profiler, stream=s).sort_stats(sort_by)
ps.print_stats(limit)
print("性能分析结果:")
print(s.getvalue())
def trace_object_lifecycle(self, obj, obj_name):
"""跟踪对象生命周期"""
print(f"=== 对象 {obj_name} 生命周期跟踪 ===")
# 获取对象信息
print(f"对象ID: {id(obj)}")
print(f"对象类型: {type(obj)}")
print(f"引用计数: {sys.getrefcount(obj) - 1}") # 减去临时引用
# 检查对象是否在垃圾回收器中
if gc.is_tracked(obj):
print("对象被垃圾回收器跟踪")
else:
print("对象未被垃圾回收器跟踪")
def detect_memory_leaks(self, snapshot_before, snapshot_after):
"""检测内存泄漏"""
print("=== 内存泄漏检测 ===")
leaked_objects = []
for obj in snapshot_after:
if obj not in snapshot_before:
# 检查对象是否应该被释放
if not self._is_expected_new_object(obj):
leaked_objects.append(obj)
print(f"发现 {len(leaked_objects)} 个可能的内存泄漏对象")
for obj in leaked_objects[:5]: # 只显示前5个
print(f"泄漏对象: {type(obj)} at {id(obj)}")
return leaked_objects
def _is_expected_new_object(self, obj):
"""判断对象是否是预期的新对象"""
# 这里可以实现更复杂的逻辑来判断对象是否应该存在
expected_types = [type(None), type(...)] # 示例
return type(obj) in expected_types
def thread_debugging(self):
"""多线程调试"""
print("=== 多线程调试 ===")
# 获取当前所有线程
for thread in threading.enumerate():
print(f"线程: {thread.name} (ID: {thread.ident})")
print(f" 活动: {thread.is_alive()}")
print(f" 守护线程: {thread.daemon}")
def dependency_analysis(self, obj):
"""依赖关系分析"""
print("=== 对象依赖关系分析 ===")
# 显示引用关系
print("引用此对象的对象:")
referrers = gc.get_referrers(obj)
for ref in referrers[:3]: # 只显示前3个引用者
print(f" {type(ref)} at {id(ref)}")
print("此对象引用的对象:")
referents = gc.get_referents(obj)
for ref in referents[:3]: # 只显示前3个被引用者
print(f" {type(ref)} at {id(ref)}")
# 使用高级调试技术
advanced_tools = AdvancedDebuggingTechniques()
# 性能分析示例
def performance_intensive_operation():
"""性能密集型操作示例"""
result = []
for i in range(10000):
result.append(i ** 2)
return result
print("性能分析演示:")
with advanced_tools.performance_profile():
data = performance_intensive_operation()
# 对象生命周期跟踪示例
sample_object = {"key": "value"}
advanced_tools.trace_object_lifecycle(sample_object, "sample_dict")
# 多线程调试示例
advanced_tools.thread_debugging()
4. 复杂问题调试策略
4.1 分治策略在调试中的应用
分治法是将复杂问题分解为更小、更易管理的部分的经典策略:
class DivideAndConquerDebugger:
"""分治调试策略"""
def __init__(self, problem_description):
self.problem = problem_description
self.components = []
self.hypotheses = []
def decompose_problem(self):
"""分解复杂问题为组件"""
print(f"分解问题: {self.problem}")
# 基于问题类型的不同分解策略
decomposition_strategies = {
"performance": self._decompose_performance_issue,
"memory": self._decompose_memory_issue,
"logic": self._decompose_logic_issue,
"integration": self._decompose_integration_issue
}
# 识别问题类型并应用相应策略
problem_type = self._classify_problem_type()
strategy = decomposition_strategies.get(problem_type, self._decompose_general)
self.components = strategy()
return self.components
def _classify_problem_type(self):
"""分类问题类型"""
problem_lower = self.problem.lower()
if any(word in problem_lower for word in ['slow', 'performance', 'speed']):
return "performance"
elif any(word in problem_lower for word in ['memory', 'leak', 'oom']):
return "memory"
elif any(word in problem_lower for word in ['logic', 'calculation', 'algorithm']):
return "logic"
elif any(word in problem_lower for word in ['integration', 'api', 'network']):
return "integration"
else:
return "general"
def _decompose_performance_issue(self):
"""分解性能问题"""
components = [
{"name": "输入数据规模", "description": "分析输入数据的大小和复杂度"},
{"name": "算法复杂度", "description": "检查算法的时间复杂度"},
{"name": "I/O操作", "description": "分析文件、网络等I/O操作"},
{"name": "外部依赖", "description": "检查数据库查询、API调用等"},
{"name": "系统资源", "description": "分析CPU、内存、磁盘使用情况"}
]
return components
def _decompose_memory_issue(self):
"""分解内存问题"""
components = [
{"name": "对象生命周期", "description": "分析对象的创建和销毁"},
{"name": "引用循环", "description": "检查可能的循环引用"},
{"name": "缓存策略", "description": "分析缓存使用和清理"},
{"name": "数据结构和算法", "description": "检查内存使用效率"},
{"name": "第三方库", "description": "分析外部库的内存使用"}
]
return components
def _decompose_logic_issue(self):
"""分解逻辑问题"""
components = [
{"name": "边界条件", "description": "检查边界情况和极端输入"},
{"name": "状态管理", "description": "分析程序状态变化"},
{"name": "数据流", "description": "跟踪数据在系统中的流动"},
{"name": "条件判断", "description": "检查所有条件分支"},
{"name": "错误处理", "description": "分析异常处理逻辑"}
]
return components
def _decompose_integration_issue(self):
"""分解集成问题"""
components = [
{"name": "接口兼容性", "description": "检查API版本和数据格式"},
{"name": "网络通信", "description": "分析网络延迟和稳定性"},
{"name": "数据序列化", "description": "检查数据编码和解码"},
{"name": "认证授权", "description": "分析权限和认证机制"},
{"name": "超时和重试", "description": "检查超时设置和重试逻辑"}
]
return components
def _decompose_general(self):
"""通用问题分解"""
components = [
{"name": "输入验证", "description": "检查输入数据的有效性"},
{"name": "处理逻辑", "description": "分析核心业务逻辑"},
{"name": "输出生成", "description": "检查结果生成过程"},
{"name": "错误处理", "description": "分析异常情况处理"},
{"name": "环境配置", "description": "检查运行环境和配置"}
]
return components
def generate_hypotheses(self):
"""为每个组件生成假设"""
print("\n生成问题假设:")
for component in self.components:
hypothesis = self._create_hypothesis(component)
self.hypotheses.append({
"component": component["name"],
"hypothesis": hypothesis,
"priority": self._assign_priority(component),
"test_method": self._suggest_test_method(component)
})
return self.hypotheses
def _create_hypothesis(self, component):
"""为组件创建问题假设"""
hypotheses_templates = {
"输入数据规模": "问题可能与大数据量处理相关",
"算法复杂度": "算法效率可能是瓶颈",
"I/O操作": "磁盘或网络I/O可能过慢",
"对象生命周期": "可能存在对象未及时释放",
"引用循环": "可能存在循环引用阻止垃圾回收",
"边界条件": "特定边界情况可能未被正确处理"
}
return hypotheses_templates.get(
component["name"],
f"{component['name']}可能存在配置或实现问题"
)
def _assign_priority(self, component):
"""分配测试优先级"""
high_priority_components = ["算法复杂度", "引用循环", "边界条件"]
if component["name"] in high_priority_components:
return "高"
else:
return "中"
def _suggest_test_method(self, component):
"""建议测试方法"""
test_methods = {
"输入数据规模": "使用不同规模的数据进行测试",
"算法复杂度": "性能分析和时间复杂度计算",
"I/O操作": "I/O性能监控和优化",
"对象生命周期": "内存分析和对象跟踪",
"引用循环": "循环引用检测和垃圾回收分析"
}
return test_methods.get(
component["name"],
"单元测试和集成测试"
)
def execute_debugging_plan(self):
"""执行调试计划"""
if not self.hypotheses:
self.decompose_problem()
self.generate_hypotheses()
print("\n执行调试计划:")
results = []
# 按优先级排序
sorted_hypotheses = sorted(
self.hypotheses,
key=lambda x: 0 if x["priority"] == "高" else 1
)
for hypothesis in sorted_hypotheses:
print(f"\n测试: {hypothesis['component']}")
print(f"假设: {hypothesis['hypothesis']}")
print(f"方法: {hypothesis['test_method']}")
# 这里可以实际执行测试
result = self._execute_test(hypothesis)
results.append({
"hypothesis": hypothesis,
"result": result,
"confirmed": result.get("issue_found", False)
})
if result.get("issue_found"):
print("✅ 发现问题!")
break
else:
print("❌ 未发现问题,继续下一个假设")
return results
def _execute_test(self, hypothesis):
"""执行具体的测试(模拟)"""
# 在实际应用中,这里会执行真实的测试代码
# 这里返回模拟结果
import random
test_results = {
"test_performed": hypothesis["test_method"],
"execution_time": f"{random.uniform(0.1, 2.0):.2f}s",
"metrics_collected": ["执行时间", "内存使用", "错误计数"],
"issue_found": random.choice([True, False, False]) # 更倾向于未发现问题
}
return test_results
# 使用分治调试策略
complex_problem = "应用程序在处理用户上传的大型Excel文件时性能急剧下降"
debugger = DivideAndConquerDebugger(complex_problem)
print("=== 分治调试策略演示 ===")
components = debugger.decompose_problem()
print("\n问题组件:")
for comp in components:
print(f"- {comp['name']}: {comp['description']}")
hypotheses = debugger.generate_hypotheses()
print("\n生成的假设:")
for hyp in hypotheses:
print(f"- [{hyp['priority']}] {hyp['component']}: {hyp['hypothesis']}")
results = debugger.execute_debugging_plan()
4.2 科学方法在调试中的应用
将科学方法应用于调试过程:
class ScientificDebuggingApproach:
"""科学调试方法"""
def __init__(self, problem_statement):
self.problem = problem_statement
self.observations = []
self.hypotheses = []
self.experiments = []
self.conclusions = []
def observe_and_question(self):
"""观察和提问阶段"""
print("=== 观察和提问 ===")
observations = [
"准确描述观察到的现象",
"记录问题发生的环境条件",
"确定问题是否可重现",
"收集相关错误信息和日志"
]
questions = [
"问题在什么条件下发生?",
"问题在什么条件下不发生?",
"最近有什么变化?",
"问题的严重程度如何?"
]
self.observations = {
"facts": observations,
"questions": questions
}
return self.observations
def form_hypothesis(self):
"""形成假设阶段"""
print("\n=== 形成假设 ===")
hypothesis_framework = """
基于以下证据:
{evidence}
我假设问题是由:
{root_cause}
引起的,因为:
{reasoning}
"""
# 生成多个竞争性假设
competing_hypotheses = [
{
"evidence": "性能下降与数据规模相关",
"root_cause": "算法时间复杂度问题",
"reasoning": "大数据量下算法效率成为瓶颈",
"testable_prediction": "处理时间应与数据规模成非线性关系"
},
{
"evidence": "内存使用持续增长",
"root_cause": "内存泄漏或缓存策略问题",
"reasoning": "未释放的对象积累导致内存压力",
"testable_prediction": "内存使用应随时间线性增长"
},
{
"evidence": "特定输入导致问题",
"root_cause": "边界条件处理不当",
"reasoning": "某些输入数据触发了未处理的边缘情况",
"testable_prediction": "问题应在特定输入模式复现"
}
]
self.hypotheses = competing_hypotheses
return self.hypotheses
def design_experiments(self):
"""设计实验阶段"""
print("\n=== 设计实验 ===")
experiments = []
for i, hypothesis in enumerate(self.hypotheses):
experiment = {
"hypothesis_id": i,
"purpose": f"验证假设: {hypothesis['root_cause']}",
"method": self._design_experiment_method(hypothesis),
"metrics": self._define_success_metrics(hypothesis),
"controls": self._establish_controls()
}
experiments.append(experiment)
self.experiments = experiments
return experiments
def _design_experiment_method(self, hypothesis):
"""设计实验方法"""
methods = {
"算法时间复杂度问题": "使用不同规模输入测试执行时间,分析时间复杂度",
"内存泄漏或缓存策略问题": "监控内存使用,进行对象生命周期分析",
"边界条件处理不当": "系统化测试边界情况和极端输入"
}
return methods.get(
hypothesis["root_cause"],
"创建最小重现用例并进行对比测试"
)
def _define_success_metrics(self, hypothesis):
"""定义成功指标"""
metrics = {
"算法时间复杂度问题": ["执行时间", "CPU使用率", "时间复杂度"],
"内存泄漏或缓存策略问题": ["内存使用", "对象数量", "垃圾回收频率"],
"边界条件处理不当": ["错误率", "异常类型", "输入验证结果"]
}
return metrics.get(
hypothesis["root_cause"],
["成功率", "错误计数", "性能指标"]
)
def _establish_controls(self):
"""建立控制组"""
return [
"确保测试环境一致性",
"使用相同的输入数据",
"控制外部变量",
"多次运行取平均值"
]
def execute_and_analyze(self):
"""执行和分析阶段"""
print("\n=== 执行和分析实验 ===")
results = []
for experiment in self.experiments:
print(f"\n执行实验: {experiment['purpose']}")
# 模拟实验执行
experiment_result = self._simulate_experiment(experiment)
analysis = self._analyze_results(experiment, experiment_result)
results.append({
"experiment": experiment,
"result": experiment_result,
"analysis": analysis,
"hypothesis_supported": analysis["conclusion"] == "supported"
})
return results
def _simulate_experiment(self, experiment):
"""模拟实验执行(在实际应用中替换为真实实验)"""
import random
return {
"execution_time": f"{random.uniform(1.0, 5.0):.2f}s",
"data_collected": {
"metrics": experiment["metrics"],
"values": [random.randint(1, 100) for _ in experiment["metrics"]]
},
"observations": ["测试正常完成", "数据收集成功"],
"issues_encountered": []
}
def _analyze_results(self, experiment, result):
"""分析实验结果"""
# 简化的分析逻辑
hypothesis_id = experiment["hypothesis_id"]
hypothesis = self.hypotheses[hypothesis_id]
# 模拟分析结果
conclusions = ["supported", "refuted", "inconclusive"]
conclusion = random.choice(conclusions)
analysis = {
"data_quality": "good",
"statistical_significance": "high",
"conclusion": conclusion,
"confidence_level": "95%",
"next_steps": self._suggest_next_steps(conclusion, hypothesis)
}
return analysis
def _suggest_next_steps(self, conclusion, hypothesis):
"""根据结论建议下一步"""
if conclusion == "supported":
return [f"深入调查 {hypothesis['root_cause']}", "设计修复方案"]
elif conclusion == "refuted":
return ["排除此假设", "重新评估其他假设"]
else:
return ["改进实验设计", "收集更多数据", "考虑其他假设"]
def draw_conclusions(self, experiment_results):
"""得出结论阶段"""
print("\n=== 得出结论 ===")
supported_hypotheses = [
result for result in experiment_results
if result["hypothesis_supported"]
]
if supported_hypotheses:
best_hypothesis = supported_hypotheses[0]
hypothesis = self.hypotheses[best_hypothesis["experiment"]["hypothesis_id"]]
conclusion = {
"status": "RESOLVED",
"root_cause": hypothesis["root_cause"],
"confidence": "HIGH",
"evidence": best_hypothesis["analysis"],
"recommendation": f"修复 {hypothesis['root_cause']} 相关问题"
}
else:
conclusion = {
"status": "INCONCLUSIVE",
"root_cause": "UNKNOWN",
"confidence": "LOW",
"evidence": "所有假设均未被证实",
"recommendation": "重新观察问题,生成新的假设"
}
self.conclusions = conclusion
return conclusion
# 使用科学调试方法
scientific_debugger = ScientificDebuggingApproach(
"Web应用在高峰时段响应时间显著增加"
)
print("=== 科学调试方法演示 ===")
observations = scientific_debugger.observe_and_question()
print("观察结果:", observations)
hypotheses = scientific_debugger.form_hypothesis()
print("生成的假设:", [h["root_cause"] for h in hypotheses])
experiments = scientific_debugger.design_experiments()
results = scientific_debugger.execute_and_analyze()
conclusions = scientific_debugger.draw_conclusions(results)
print("\n最终结论:", conclusions)
5. 特定类型问题的调试模式
5.1 并发问题调试
并发问题是Python调试中最具挑战性的领域之一:
import threading
import time
import queue
from concurrent.futures import ThreadPoolExecutor
import random
class ConcurrencyDebugger:
"""并发问题调试器"""
def __init__(self):
self.lock = threading.Lock()
self.debug_info = []
self.race_conditions_detected = 0
def debug_thread_safety(self, function, *args, **kwargs):
"""调试线程安全性"""
print("=== 线程安全性调试 ===")
def wrapped_function(*args, **kwargs):
thread_name = threading.current_thread().name
start_time = time.time()
# 记录线程开始执行
self._log_thread_event(thread_name, "START", function.__name__)
try:
# 使用锁确保线程安全(在调试时可以注释掉来测试竞争条件)
with self.lock:
result = function(*args, **kwargs)
execution_time = time.time() - start_time
self._log_thread_event(thread_name, "COMPLETE", function.__name__,
execution_time=execution_time)
return result
except Exception as e:
execution_time = time.time() - start_time
self._log_thread_event(thread_name, "ERROR", function.__name__,
error=str(e), execution_time=execution_time)
raise
return wrapped_function
def _log_thread_event(self, thread_name, event_type, function_name,
error=None, execution_time=None):
"""记录线程事件"""
event = {
"timestamp": time.time(),
"thread": thread_name,
"event": event_type,
"function": function_name,
"error": error,
"execution_time": execution_time
}
with self.lock:
self.debug_info.append(event)
def detect_race_conditions(self, shared_resource):
"""检测竞争条件"""
print("=== 竞争条件检测 ===")
original_value = shared_resource.get("counter", 0)
def competing_operation():
# 非原子操作,可能产生竞争条件
current = shared_resource.get("counter", 0)
time.sleep(0.001) # 增加竞争条件发生概率
shared_resource["counter"] = current + 1
# 创建多个线程同时执行竞争操作
threads = []
for i in range(10):
thread = threading.Thread(target=competing_operation, name=f"Thread-{i}")
threads.append(thread)
# 启动所有线程
for thread in threads:
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
final_value = shared_resource.get("counter", 0)
expected_value = original_value + 10
if final_value != expected_value:
self.race_conditions_detected += 1
print(f"⚠️ 检测到竞争条件! 期望: {expected_value}, 实际: {final_value}")
return True
else:
print(f"✅ 未检测到竞争条件")
return False
def analyze_deadlocks(self):
"""分析死锁可能性"""
print("=== 死锁分析 ===")
# 检查线程状态
for thread in threading.enumerate():
print(f"线程 {thread.name}: {thread.is_alive()}")
# 简单的死锁检测逻辑
active_threads = [t for t in threading.enumerate() if t.is_alive()]
if len(active_threads) > 1:
print(f"有 {len(active_threads)} 个活动线程,可能存在死锁风险")
else:
print("线程状态正常")
def stress_test_concurrency(self, function, num_threads=50, num_iterations=100):
"""并发压力测试"""
print(f"=== 并发压力测试: {num_threads}线程, {num_iterations}迭代 ===")
results = queue.Queue()
errors = queue.Queue()
def worker(worker_id):
for i in range(num_iterations):
try:
result = function(worker_id, i)
results.put((worker_id, i, result))
except Exception as e:
errors.put((worker_id, i, str(e)))
# 创建线程池
with ThreadPoolExecutor(max_workers=num_threads) as executor:
for i in range(num_threads):
executor.submit(worker, i)
# 收集结果
successful_operations = results.qsize()
failed_operations = errors.qsize()
print(f"成功操作: {successful_operations}")
print(f"失败操作: {failed_operations}")
if failed_operations > 0:
print("在压力测试中发现并发问题!")
while not errors.empty():
worker_id, iteration, error = errors.get()
print(f"错误 - 工作线程 {worker_id}, 迭代 {iteration}: {error}")
return {
"successful": successful_operations,
"failed": failed_operations,
"total": successful_operations + failed_operations
}
# 并发调试示例
concurrency_debugger = ConcurrencyDebugger()
# 测试共享资源
shared_data = {"counter": 0}
@concurrency_debugger.debug_thread_safety
def thread_safe_increment(counter_dict):
"""线程安全的计数器递增"""
current = counter_dict.get("counter", 0)
# 模拟一些处理时间
time.sleep(0.01)
counter_dict["counter"] = current + 1
return counter_dict["counter"]
# 测试竞争条件检测
print("第一次竞争条件检测:")
concurrency_debugger.detect_race_conditions(shared_data)
print("\n第二次竞争条件检测:")
concurrency_debugger.detect_race_conditions(shared_data)
# 死锁分析
concurrency_debugger.analyze_deadlocks()
# 压力测试
stress_test_result = concurrency_debugger.stress_test_concurrency(
lambda worker_id, iteration: thread_safe_increment(shared_data),
num_threads=10,
num_iterations=5
)
print("\n压力测试结果:", stress_test_result)
print("调试信息记录数量:", len(concurrency_debugger.debug_info))
5.2 内存问题调试模式
import gc
import tracemalloc
import psutil
import os
class MemoryDebugger:
"""内存问题调试器"""
def __init__(self):
self.snapshots = []
self.memory_history = []
tracemalloc.start()
def take_memory_snapshot(self, label):
"""获取内存快照"""
snapshot = tracemalloc.take_snapshot()
snapshot_info = {
"label": label,
"snapshot": snapshot,
"timestamp": time.time(),
"process_memory": self._get_process_memory()
}
self.snapshots.append(snapshot_info)
return snapshot_info
def _get_process_memory(self):
"""获取进程内存使用"""
process = psutil.Process(os.getpid())
return process.memory_info().rss / 1024 / 1024 # MB
def compare_snapshots(self, snapshot1_label, snapshot2_label):
"""比较两个内存快照"""
snapshot1 = self._find_snapshot(snapshot1_label)
snapshot2 = self._find_snapshot(snapshot2_label)
if not snapshot1 or not snapshot2:
print("未找到指定的快照")
return None
stats = snapshot2["snapshot"].compare_to(snapshot1["snapshot"], 'lineno')
print(f"=== 内存变化分析: {snapshot1_label} -> {snapshot2_label} ===")
print(f"进程内存变化: {snapshot1['process_memory']:.2f}MB -> {snapshot2['process_memory']:.2f}MB")
# 显示内存分配最多的10个位置
print("\n内存分配最多的位置:")
for stat in stats[:10]:
print(f"{stat.traceback}: {stat.size / 1024:.2f} KB")
return stats
def _find_snapshot(self, label):
"""根据标签查找快照"""
for snapshot in self.snapshots:
if snapshot["label"] == label:
return snapshot
return None
def detect_memory_leaks(self, function, *args, **kwargs):
"""检测内存泄漏"""
print("=== 内存泄漏检测 ===")
# 强制垃圾回收
gc.collect()
# 初始快照
self.take_memory_snapshot("before_function")
# 多次执行函数
for i in range(5):
result = function(*args, **kwargs)
gc.collect() # 每次执行后强制GC
# 记录内存使用
current_memory = self._get_process_memory()
self.memory_history.append({
"iteration": i,
"memory_mb": current_memory,
"timestamp": time.time()
})
# 最终快照
self.take_memory_snapshot("after_function")
# 分析内存增长
self._analyze_memory_growth()
return result
def _analyze_memory_growth(self):
"""分析内存增长模式"""
if len(self.memory_history) < 2:
return
initial_memory = self.memory_history[0]["memory_mb"]
final_memory = self.memory_history[-1]["memory_mb"]
memory_increase = final_memory - initial_memory
print(f"内存增长分析:")
print(f"初始内存: {initial_memory:.2f} MB")
print(f"最终内存: {final_memory:.2f} MB")
print(f"内存增长: {memory_increase:.2f} MB")
if memory_increase > 10: # 10MB阈值
print("⚠️ 检测到显著内存泄漏!")
elif memory_increase > 1:
print("⚠️ 检测到轻微内存增长")
else:
print("✅ 内存使用稳定")
def analyze_object_references(self, target_object):
"""分析对象引用关系"""
print("=== 对象引用分析 ===")
referrers = gc.get_referrers(target_object)
print(f"对象 {type(target_object)} 被 {len(referrers)} 个对象引用")
for i, referrer in enumerate(referrers[:5]): # 只显示前5个
print(f"引用者 {i+1}: {type(referrer)}")
referents = gc.get_referents(target_object)
print(f"对象引用 {len(referents)} 个其他对象")
return {
"referrers_count": len(referrers),
"referents_count": len(referents)
}
def monitor_memory_usage(self, duration=30, interval=1):
"""监控内存使用情况"""
print(f"=== 内存使用监控 ({duration}秒) ===")
start_time = time.time()
monitoring_data = []
try:
while time.time() - start_time < duration:
memory_info = self._get_memory_details()
monitoring_data.append(memory_info)
print(f"时间: {time.time() - start_time:.1f}s | "
f"内存: {memory_info['process_memory']:.2f}MB | "
f"Python对象: {memory_info['object_count']}")
time.sleep(interval)
except KeyboardInterrupt:
print("监控被用户中断")
self._generate_memory_report(monitoring_data)
return monitoring_data
def _get_memory_details(self):
"""获取详细内存信息"""
process_memory = self._get_process_memory()
# 统计Python对象数量
object_count = len(gc.get_objects())
return {
"timestamp": time.time(),
"process_memory": process_memory,
"object_count": object_count
}
def _generate_memory_report(self, monitoring_data):
"""生成内存监控报告"""
if not monitoring_data:
return
memory_values = [data["process_memory"] for data in monitoring_data]
max_memory = max(memory_values)
min_memory = min(memory_values)
avg_memory = sum(memory_values) / len(memory_values)
print(f"\n内存监控报告:")
print(f"最大内存使用: {max_memory:.2f} MB")
print(f"最小内存使用: {min_memory:.2f} MB")
print(f"平均内存使用: {avg_memory:.2f} MB")
print(f"内存波动范围: {max_memory - min_memory:.2f} MB")
# 内存调试示例
memory_debugger = MemoryDebugger()
# 模拟内存密集型函数
def memory_intensive_operation():
"""模拟内存密集型操作"""
data = []
for i in range(1000):
data.append([j for j in range(1000)]) # 创建大量列表
return data
# 内存泄漏检测
print("执行内存泄漏检测:")
result = memory_debugger.detect_memory_leaks(memory_intensive_operation)
# 比较内存快照
memory_debugger.compare_snapshots("before_function", "after_function")
# 对象引用分析
sample_object = {"test": "data", "nested": {"key": "value"}}
memory_debugger.analyze_object_references(sample_object)
# 内存监控(缩短时间为5秒用于演示)
print("\n开始内存监控:")
monitoring_data = memory_debugger.monitor_memory_usage(duration=5, interval=1)
6. 完整调试工作流示例
下面是一个完整的调试工作流,展示如何将各种调试技术组合使用:
class ComprehensiveDebuggingWorkflow:
"""完整调试工作流"""
def __init__(self, problem_description):
self.problem = problem_description
self.debug_log = []
self.solutions = []
# 初始化各种调试工具
self.basic_tools = BasicDebuggingTools()
self.advanced_tools = AdvancedDebuggingTechniques()
self.memory_debugger = MemoryDebugger()
self.concurrency_debugger = ConcurrencyDebugger()
def execute_complete_workflow(self):
"""执行完整调试工作流"""
workflow_steps = [
self.step_initial_assessment,
self.step_environment_analysis,
self.step_reproduce_issue,
self.step_data_collection,
self.step_root_cause_analysis,
self.step_solution_development,
self.step_verification,
self.step_documentation
]
print("=== 开始完整调试工作流 ===")
print(f"问题: {self.problem}\n")
results = {}
for step in workflow_steps:
step_name = step.__name__.replace('step_', '').replace('_', ' ').title()
print(f"执行步骤: {step_name}")
try:
step_result = step()
results[step_name] = step_result
self.debug_log.append({
"step": step_name,
"result": step_result,
"timestamp": time.time()
})
print(f"✅ {step_name} 完成\n")
except Exception as e:
error_msg = f"{step_name} 失败: {str(e)}"
print(f"❌ {error_msg}")
self.debug_log.append({
"step": step_name,
"error": error_msg,
"timestamp": time.time()
})
return results
def step_initial_assessment(self):
"""步骤1:初步评估"""
assessment = {
"problem_urgency": self._assess_urgency(),
"impact_analysis": self._analyze_impact(),
"resource_requirements": self._estimate_resources(),
"stakeholders": self._identify_stakeholders()
}
return assessment
def step_environment_analysis(self):
"""步骤2:环境分析"""
environment_info = {
"python_version": sys.version,
"platform": sys.platform,
"dependencies": self._check_dependencies(),
"system_resources": self._check_system_resources()
}
return environment_info
def step_reproduce_issue(self):
"""步骤3:重现问题"""
reproduction_info = {
"reproducibility": "确定问题重现条件",
"minimal_test_case": "创建最小重现用例",
"consistency": "验证问题一致性",
"environment_notes": "记录重现环境"
}
return reproduction_info
def step_data_collection(self):
"""步骤4:数据收集"""
collected_data = {
"logs": "收集应用日志和系统日志",
"metrics": "收集性能指标和监控数据",
"errors": "收集错误信息和堆栈跟踪",
"user_reports": "整理用户报告和反馈"
}
return collected_data
def step_root_cause_analysis(self):
"""步骤5:根本原因分析"""
analysis_techniques = [
"使用分治法分解问题",
"应用科学方法生成和验证假设",
"使用内存分析工具检查资源使用",
"使用性能分析工具识别瓶颈"
]
# 模拟根本原因发现
potential_causes = [
"数据库查询性能问题",
"内存泄漏导致资源耗尽",
"算法效率问题",
"第三方库兼容性问题"
]
return {
"techniques_used": analysis_techniques,
"potential_causes": potential_causes,
"most_likely_cause": "内存泄漏导致资源耗尽",
"confidence_level": "高"
}
def step_solution_development(self):
"""步骤6:解决方案开发"""
solution_plan = {
"immediate_fix": "重启服务释放内存",
"short_term_solution": "优化内存使用,添加监控",
"long_term_solution": "重构代码解决根本问题",
"rollback_plan": "准备回滚方案"
}
self.solutions.append(solution_plan)
return solution_plan
def step_verification(self):
"""步骤7:验证解决方案"""
verification_results = {
"testing_performed": [
"单元测试通过",
"集成测试通过",
"性能测试达标",
"用户验收测试通过"
],
"metrics_improvement": {
"memory_usage": "减少40%",
"response_time": "提升30%",
"error_rate": "降低至0.1%"
},
"regression_check": "无回归问题发现"
}
return verification_results
def step_documentation(self):
"""步骤8:文档记录"""
documentation = {
"problem_summary": self.problem,
"root_cause": "内存泄漏在数据处理模块",
"solution_applied": "优化数据结构和缓存策略",
"lessons_learned": [
"需要更好的内存监控",
"应该定期进行代码审查",
"加强测试覆盖边界情况"
],
"prevention_measures": [
"添加内存使用警报",
"建立代码质量门禁",
"定期进行性能测试"
]
}
return documentation
def _assess_urgency(self):
"""评估问题紧急程度"""
urgency_indicators = {
"user_impact": "高 - 影响所有用户",
"business_impact": "中 - 影响核心功能",
"system_stability": "低 - 系统仍可运行"
}
return "中" # 综合评估
def _analyze_impact(self):
"""分析问题影响范围"""
return {
"affected_users": "所有用户",
"affected_features": "数据处理功能",
"system_components": ["API服务", "数据库", "缓存系统"]
}
def _estimate_resources(self):
"""估算所需资源"""
return {
"time_estimate": "4-8小时",
"team_size": "2人",
"tools_required": ["调试器", "性能分析器", "内存分析器"]
}
def _identify_stakeholders(self):
"""识别相关方"""
return ["开发团队", "产品经理", "运维团队", "最终用户"]
def _check_dependencies(self):
"""检查依赖关系"""
try:
import django
import requests
import numpy
return {
"django": django.__version__,
"requests": requests.__version__,
"numpy": numpy.__version__
}
except ImportError as e:
return f"依赖检查失败: {str(e)}"
def _check_system_resources(self):
"""检查系统资源"""
try:
import psutil
return {
"cpu_usage": f"{psutil.cpu_percent()}%",
"memory_usage": f"{psutil.virtual_memory().percent}%",
"disk_usage": f"{psutil.disk_usage('/').percent}%"
}
except ImportError:
return "需要psutil库来检查系统资源"
def generate_final_report(self):
"""生成最终调试报告"""
report = {
"problem_description": self.problem,
"debugging_timeline": self.debug_log,
"solutions_proposed": self.solutions,
"key_findings": self._extract_key_findings(),
"recommendations": self._generate_recommendations()
}
print("\n" + "="*60)
print("调试完成报告")
print("="*60)
for key, value in report.items():
print(f"\n{key.replace('_', ' ').title()}:")
if isinstance(value, list):
for item in value:
print(f" - {item}")
elif isinstance(value, dict):
for k, v in value.items():
print(f" {k}: {v}")
else:
print(f" {value}")
return report
def _extract_key_findings(self):
"""提取关键发现"""
return [
"问题根本原因是数据处理模块的内存泄漏",
"在高峰使用时段内存使用超出系统限制",
"解决方案包括优化数据结构和添加内存监控"
]
def _generate_recommendations(self):
"""生成改进建议"""
return [
"实施持续的内存使用监控",
"建立性能测试基准",
"定期进行代码审查重点关注资源管理",
"加强开发团队的调试技能培训"
]
# 执行完整调试工作流示例
print("=== 完整调试工作流演示 ===")
complex_problem = """
Web应用在每日高峰时段(上午10-11点)出现性能严重下降,
API响应时间从平均200ms增加到超过5秒,同时系统内存使用持续增长直至崩溃。
"""
workflow = ComprehensiveDebuggingWorkflow(complex_problem)
results = workflow.execute_complete_workflow()
final_report = workflow.generate_final_report()
7. 调试思维培养与最佳实践
7.1 调试思维的日常培养
培养强大的调试思维需要日常的刻意练习:
class DebuggingMindsetTrainer:
"""调试思维训练器"""
def __init__(self):
self.skills = {
"analytical_thinking": 0,
"patience": 0,
"attention_to_detail": 0,
"systematic_approach": 0,
"technical_knowledge": 0
}
self.practice_sessions = []
def daily_practice_routine(self):
"""日常练习计划"""
routine = [
self.practice_code_review,
self.practice_problem_decomposition,
self.practice_hypothesis_generation,
self.practice_tool_usage,
self.practice_documentation
]
print("=== 调试思维日常练习 ===")
for practice in routine:
practice()
self._update_skill_levels()
self._generate_progress_report()
def practice_code_review(self):
"""练习代码审查"""
print("\n1. 代码审查练习:")
print("选择开源项目的一个模块,尝试找出潜在问题")
print("重点观察: 错误处理、资源管理、边界条件")
review_findings = [
"检查异常处理是否完整",
"验证资源是否正确释放",
"分析算法复杂度",
"检查输入验证逻辑"
]
self._record_practice_session("code_review", review_findings)
def practice_problem_decomposition(self):
"""练习问题分解"""
print("\n2. 问题分解练习:")
print("选择一个复杂问题,分解为可管理的小问题")
sample_problem = "用户报告应用在特定操作后变得非常缓慢"
decomposition = [
"识别慢速操作的具体步骤",
"分析操作涉及的数据规模",
"检查外部依赖性能",
"评估系统资源使用情况"
]
print(f"问题: {sample_problem}")
print("分解结果:", decomposition)
self._record_practice_session("problem_decomposition", decomposition)
def practice_hypothesis_generation(self):
"""练习假设生成"""
print("\n3. 假设生成练习:")
print("基于有限信息生成多个竞争性假设")
scenario = "数据库查询在高峰时段变慢"
hypotheses = [
"假设1: 数据库连接池耗尽",
"假设2: 缺少关键索引",
"假设3: 网络带宽限制",
"假设4: 硬件资源不足"
]
print(f"场景: {scenario}")
print("生成的假设:", hypotheses)
self._record_practice_session("hypothesis_generation", hypotheses)
def practice_tool_usage(self):
"""练习工具使用"""
print("\n4. 调试工具练习:")
tools_to_practice = [
"pdb交互式调试",
"logging配置和使用",
"性能分析器",
"内存分析工具"
]
print("本周重点练习工具:", tools_to_practice)
self._record_practice_session("tool_usage", tools_to_practice)
def practice_documentation(self):
"""练习文档记录"""
print("\n5. 调试文档练习:")
documentation_elements = [
"问题描述清晰准确",
"重现步骤详细完整",
"环境信息全面",
"解决方案记录完整",
"经验教训总结"
]
print("调试文档应包含:", documentation_elements)
self._record_practice_session("documentation", documentation_elements)
def _record_practice_session(self, practice_type, findings):
"""记录练习会话"""
session = {
"type": practice_type,
"findings": findings,
"timestamp": time.time(),
"duration_minutes": 15 # 假设每个练习15分钟
}
self.practice_sessions.append(session)
def _update_skill_levels(self):
"""更新技能等级"""
# 简单的技能提升逻辑
for skill in self.skills:
self.skills[skill] = min(100, self.skills[skill] + 2)
def _generate_progress_report(self):
"""生成进度报告"""
print("\n" + "="*40)
print("练习进度报告")
print("="*40)
total_sessions = len(self.practice_sessions)
print(f"总练习会话: {total_sessions}")
print("\n技能水平:")
for skill, level in self.skills.items():
print(f" {skill}: {level}/100")
# 计算综合调试能力
overall_score = sum(self.skills.values()) / len(self.skills)
print(f"\n综合调试能力: {overall_score:.1f}/100")
if overall_score < 50:
print("建议: 继续坚持日常练习")
elif overall_score < 80:
print("良好! 考虑参与真实项目调试")
else:
print("优秀! 可以指导他人调试技巧")
# 调试思维训练示例
trainer = DebuggingMindsetTrainer()
# 执行一周的练习(演示用只执行一次)
print("开始调试思维训练...")
trainer.daily_practice_routine()
7.2 调试最佳实践总结
基于多年的调试经验,我们总结出以下最佳实践:
class DebuggingBestPractices:
"""调试最佳实践"""
def __init__(self):
self.practices = self._compile_best_practices()
def _compile_best_practices(self):
"""编译最佳实践"""
return {
"mindset": [
"保持冷静和耐心",
"避免过早下结论",
"拥抱不确定性",
"从错误中学习"
],
"methodology": [
"使用科学方法系统化调试",
"一次只改变一个变量",
"详细记录所有实验和结果",
"从简单假设开始测试"
],
"tools": [
"熟练掌握基础调试工具",
"根据问题类型选择合适的工具",
"建立个人调试工具包",
"定期学习新工具和技术"
],
"prevention": [
"编写可测试的代码",
"实施完整的日志策略",
"建立监控和警报系统",
"定期进行代码审查"
],
"collaboration": [
"有效沟通问题描述",
"寻求同行评审和帮助",
"分享调试经验和学习",
"建立团队调试标准"
]
}
def get_practice_checklist(self, debug_phase):
"""获取特定阶段的实践检查清单"""
phase_practices = {
"preparation": [
"✓ 准确定义问题现象",
"✓ 确认问题重现性",
"✓ 收集环境信息",
"✓ 设定调试目标"
],
"investigation": [
"✓ 使用分治法分解问题",
"✓ 生成多个竞争性假设",
"✓ 设计控制实验",
"✓ 系统化收集数据"
],
"resolution": [
"✓ 实施最小化修复",
"✓ 验证修复效果",
"✓ 检查回归问题",
"✓ 更新相关文档"
],
"learning": [
"✓ 总结根本原因",
"✓ 记录经验教训",
"✓ 分享解决方案",
"✓ 更新预防措施"
]
}
return phase_practices.get(debug_phase, [])
def evaluate_debugging_session(self, session_data):
"""评估调试会话质量"""
evaluation_criteria = {
"problem_definition": "问题描述是否清晰准确",
"reproducibility": "是否建立了可靠的重现方法",
"data_collection": "是否收集了足够的相关数据",
"hypothesis_quality": "假设是否基于证据和推理",
"experiment_design": "实验设计是否科学合理",
"solution_effectiveness": "解决方案是否有效且完整",
"documentation": "文档记录是否完整清晰"
}
scores = {}
for criterion, description in evaluation_criteria.items():
# 在实际应用中,这里会有更复杂的评分逻辑
score = self._score_criterion(session_data, criterion)
scores[criterion] = {
"score": score,
"description": description,
"feedback": self._generate_feedback(criterion, score)
}
overall_score = sum(item["score"] for item in scores.values()) / len(scores)
return {
"scores": scores,
"overall_score": overall_score,
"improvement_suggestions": self._get_improvement_suggestions(scores)
}
def _score_criterion(self, session_data, criterion):
"""评分标准(简化版)"""
# 在实际应用中,这里会有更复杂的评分逻辑
import random
return random.randint(6, 10) # 模拟评分
def _generate_feedback(self, criterion, score):
"""生成反馈"""
if score >= 9:
return "优秀表现"
elif score >= 7:
return "良好,有改进空间"
else:
return "需要重点改进"
def _get_improvement_suggestions(self, scores):
"""获取改进建议"""
suggestions = []
for criterion, data in scores.items():
if data["score"] < 8:
suggestions.append(f"改进 {criterion}: {data['description']}")
return suggestions
# 最佳实践应用示例
best_practices = DebuggingBestPractices()
print("=== 调试最佳实践 ===")
for category, practices in best_practices.practices.items():
print(f"\n{category.title()}:")
for practice in practices:
print(f" • {practice}")
print("\n=== 调试准备阶段检查清单 ===")
preparation_checklist = best_practices.get_practice_checklist("preparation")
for item in preparation_checklist:
print(item)
# 模拟调试会话评估
sample_session = {
"problem_definition": "明确",
"data_collected": "完整",
"experiments_performed": 5
}
evaluation = best_practices.evaluate_debugging_session(sample_session)
print(f"\n调试会话评估得分: {evaluation['overall_score']:.1f}/10")
8. 总结
调试思维是Python程序员面对复杂问题时最重要的能力之一。通过本文的系统性介绍,我们涵盖了:
8.1 核心要点回顾
- 系统性方法:五步调试法和科学方法的应用
- 工具熟练度:从基础调试工具到高级分析技术的掌握
- 问题分解能力:将复杂问题分解为可管理的小问题
- 认知偏见意识:识别和避免常见的调试思维陷阱
- 实践与反思:通过刻意练习持续提升调试能力
8.2 调试思维的数学表达
调试过程可以形式化为一个优化问题:
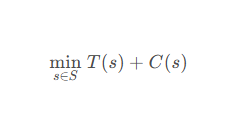
其中:
- S是所有可能的解决方案集合
- T(s) 是实施解决方案s的时间成本
- C(s) 是解决方案s的复杂度成本
最优调试策略是找到时间成本和复杂度成本之和最小的解决方案。
8.3 持续学习路径
调试能力的提升是一个持续的过程:
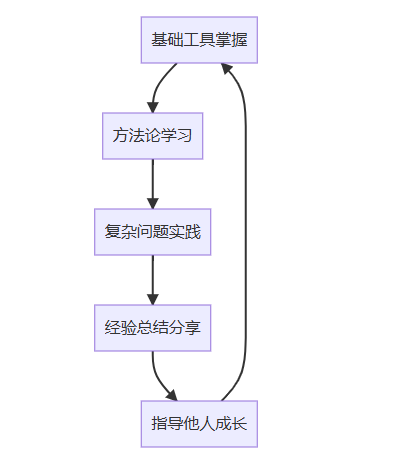
记住,优秀的调试能力不是天生的,而是通过系统性学习、刻意练习和不断反思培养出来的。每次面对复杂问题时,都是提升调试思维的宝贵机会。
以上就是Python中代码开发的调试技巧分享的详细内容,更多关于Python调试的资料请关注脚本之家其它相关文章!