
Python使用生成器轻松处理海量数据
作者:有才叔
不知道大家有没有处理过海量数据,就是数据量非常庞大的时候,如何处理?说实在的在实际项目中确实是没有处理过海量数据,但是没事儿的时候我们可以在本地模拟海量数据来玩玩儿的,那么处理海量数据用什么方式呢?用readlines()读取?还是用生成器和迭代器呢?恐怕大家用的应该也都是生成器和迭代器吧!要不然程序卡死不说,有可能把电脑搞崩溃呦!
那么生成器和迭代器怎么玩儿呢?咱们继续往下走着看着。
从生活场景理解迭代器
想象一下你去吃自助餐,不是一次性把所有的食物都端到你桌上那得多大的桌子啊!,而是想吃的时候去取一点。迭代器就是这样的工作方式。(PS:有的人可能就是一次性端上来,个例个例,比喻不是很恰当)
在Python中,任何实现了__iter__()和__next__()方法的对象都是迭代器。它不会一次性把所有数据加载到内存中,而是按需"生成"每个元素。
Python中很多内置对象都是可迭代的:列表、元组、字符串、字典,甚至文件对象。这就是为什么你能用for循环遍历它们的原因。
生成器:更优雅的迭代器
写迭代器需要定义类并实现两个方法,有点麻烦。于是Python提供了更简单的工具——生成器。
生成器有两种创建方式:
1. 生成器函数:使用def定义,但用yield代替return
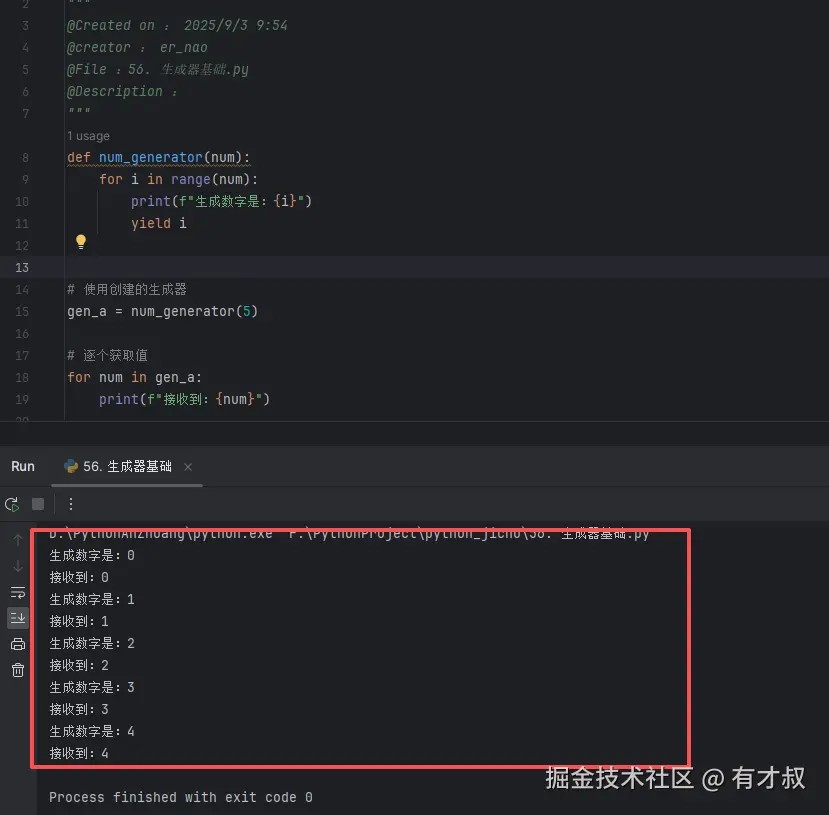
def num_generator(num):
for i in range(num):
print(f"生成数字是:{i}")
yield i
# 使用创建的生成器
gen_a = num_generator(5)
# 逐个获取值
for num in gen_a:
print(f"接收到:{num}")
2. 生成器表达式:类似列表推导式,但用圆括号
print("列表推导式VS生成器表达式:")
# 列表推导式-立即创建所有元素
list_comp = [x ** 2 for x in range(100000)]
# print(f"列表推导式:{list_comp}")
print(f"内存占用:{list_comp.__sizeof__()}字节")
# 生成器表达式-按需生成元素
gen_comp = (x ** 2 for x in range(100000))
# print(f"生成器表达式:{gen_comp}")
print(f"内存占用:{gen_comp.__sizeof__()}字节")
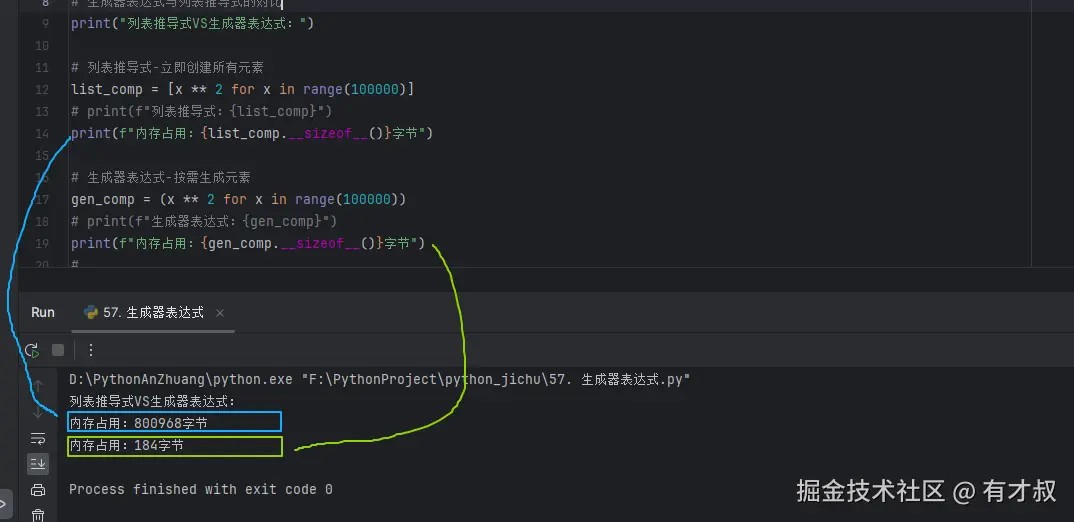
看看海量数据时,这个内存占用大不大?害怕不害怕?
这个时候问题就来了:为什么生成器能高效处理大数据?为什么呢?
为什么生成器能高效处理大数据
这个主要就是生成器的一个执行机制:
- 普通函数:一旦调用,就从头跑到尾(return),然后全部执行完毕,局部变量全部销毁。
- 生成器函数(使用
yield的函数:如上面的第一幅截图):调用时返回一个生成器对象,但并不立即执行函数体。当第一次调用next()时,函数从开始处执行,直到遇到yield语句,暂停并返回 yield 后的值。函数当前的整个局部状态(变量、指针等)都会被冻结保存。 下次再调用next(),函数从上次暂停的yield语句后紧接着继续执行。
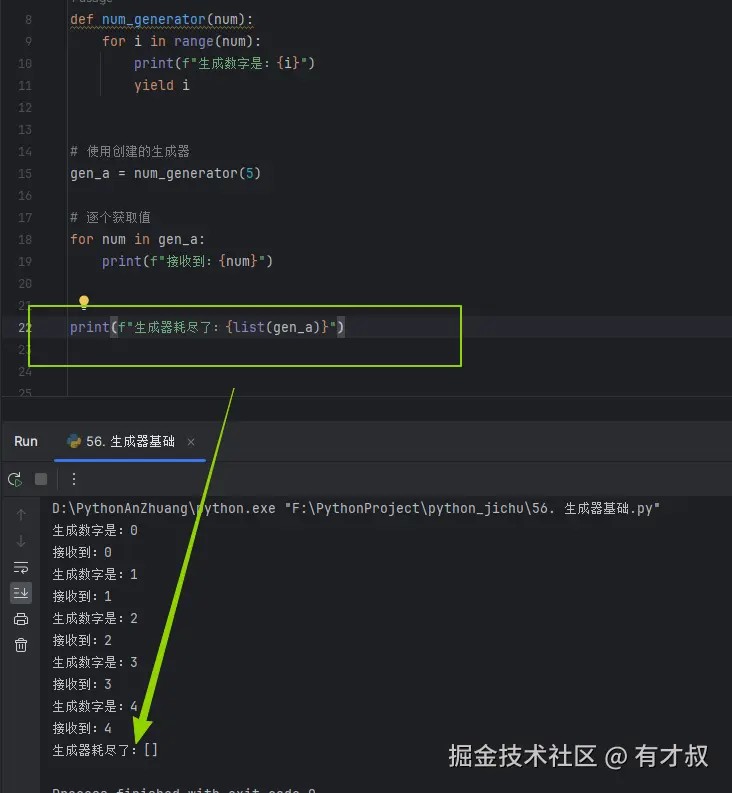
但是注意
生成器只能遍历一次,如需重复使用需要重新创建,就是只能遍历一次,再次打印已空空如也
生成器的高级用法
生成器不仅能产出数据,还能通过send()方法接收数据:
def interactive_generator():
while True:
received = yield # 等待发送数据
print(f"收到:{received}")
gen = interactive_generator()
next(gen) # 启动生成器
gen.send("Hello") # 输出:收到:Hello
gen.send("World") # 输出:收到:World
这种方法在复杂的数据流水线处理中非常有用。
生成器和迭代器是Python处理海量数据的"神器",它们通过惰性计算(需要时才生成值)节省了大量内存。 数据量不大时,用列表更简单直接; 处理GB级别以上数据时,一定要用生成器;管道式数据处理中,生成器可以串联形成高效处理链。
到此这篇关于Python使用生成器轻松处理海量数据的文章就介绍到这了,更多相关Python处理数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!