
Python 基于线程的并行 threading模块的用法
作者:V1ncent-CC
threading模块是基于_thread模块的高级线程接口,相比于低层的_thread模块,它提供了代表线程的对象和同步化工具,在threading模块中,只要任何一个派生线程(守护线程除外)在运行中,程序都不会退出,不再需要像_thread那样控制主线程等待。
一、threading模块基本用法
threading模块基于_thread进行了类封装,其用于构造线程的类为threading.Thread,通过创建类实例的方式来创建线程对象。
1.1 threading.Thread类
threading.Thread类的主要参数如下:
class threading.Thread(target=None, name=None, args=(), kwargs={}, *, daemon=None)
参数解释:
- target,用于定义子线程的活动,这应该是个可调用的函数。
- name,线程的名称。
- args,可调用函数的参数。
- kwargs,可调用函数的关键字参数。
- daemon,是否将线程设置为守护线程。
通过调用threading.Thread类创建出来的实例即是线程对象,线程对象创建后,需要调用.start方法启动,这个方法会在独立的线程中唤起run方法,因此有2种方法可以定义子线程的活动:
- 向构造类threading.Thread传递一个可调用对象(target参数)。
- 通过子类重载run方法。
下面通过案例演示2种用法。
1.2 用法1:通过threading.Thread定义子线程活动
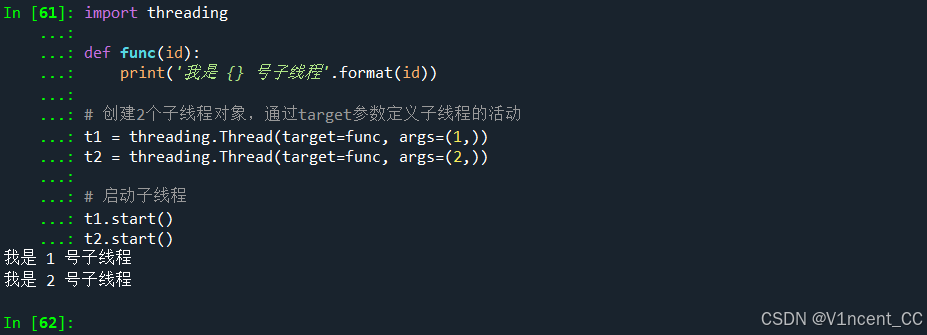
下面代码先定义一个函数func,随后调用threading.Thread创建2个线程对象,调用时通过target=func传递自定义函数(线程活动),最后通过线程对象的.start方法启动线程:
import threading
def func(id):
print('我是 {} 号子线程'.format(id))
t1 = threading.Thread(target=func, args=(1,))
t2 = threading.Thread(target=func, args=(2,))
t1.start()
t2.start()
1.3 用法2:通过子类重载run方法定义子线程活动
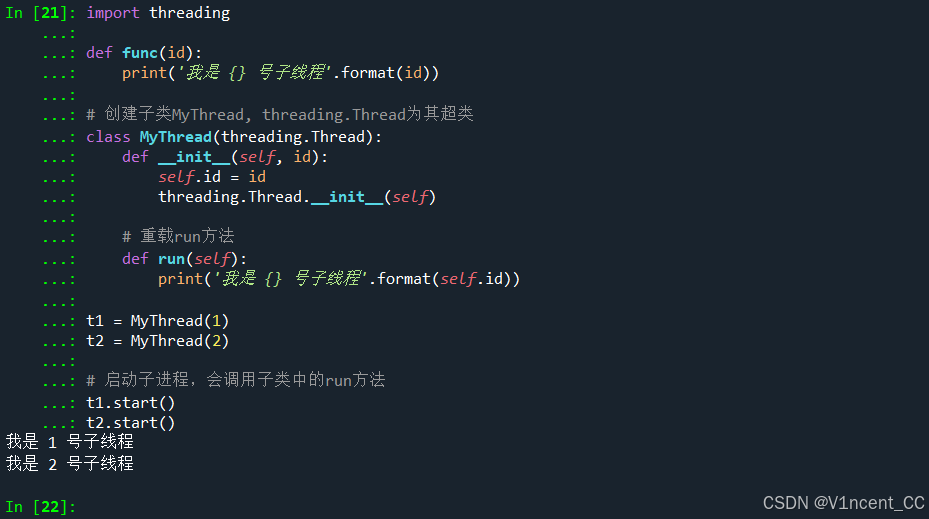
还是上面的例子,这次通过重载子类的run方法来定义子线程活动,当调用线程对象的.start方法启动子线程时,子线程会自动调用.run方法。
import threading
def func(id):
print('我是 {} 号子线程'.format(id))
# 创建子类MyThread, threading.Thread为其超类
class MyThread(threading.Thread):
def __init__(self, id):
self.id = id
threading.Thread.__init__(self)
# 重载run方法
def run(self):
print('我是 {} 号子线程'.format(self.id))
t1 = MyThread(1)
t2 = MyThread(2)
# 启动子线程,会调用子类中的run方法
t1.start()
t2.start()
二、threading模块其他方法
threading模块相对_thread模块额外提供了一些线程状态查询和控制工具,下面介绍几个主要方法。
2.1 共享访问控制 - threading.Lock
多线程必然会涉及到共享资源的访问,threading模块提供了一个.Lock方法(和_thread.allocate_lock是同一个东西)用于创建锁对象,通过锁来控制共享资源的访问,基于上面的类MyThread同时创建10个子线程:
for i in range(10):
MyThread(i).start()
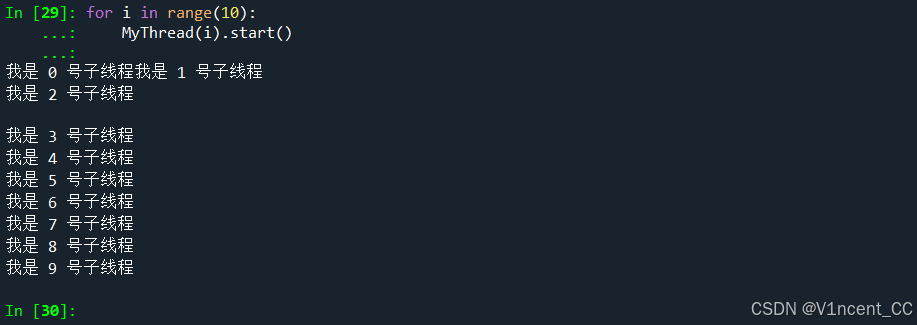
可以看到上面的输出出现了重叠,这是因为这10个子线程共享一个标准输出流,可能出现同时打印的情况。下面把MyThread类改造一下,通过.Lock对象来同步子线程的打印操作(每次打印前先获取锁,防止出现2个子线程同时打印):
class MyThread(threading.Thread):
# 新增一个参数mutex,用于传入锁
def __init__(self, id, mutex):
self.id = id
self.mutex = mutex
threading.Thread.__init__(self)
# 重载run方法
def run(self):
# 通过with语句管理锁,打印前先获取锁,打印完成释放
with self.mutex:
print('我是 {} 号子线程'.format(self.id))
# 创建一个锁对象
mutex = threading.Lock()
for i in range(10):
# 每个子线程启动时都传入该锁
MyThread(i, mutex).start()
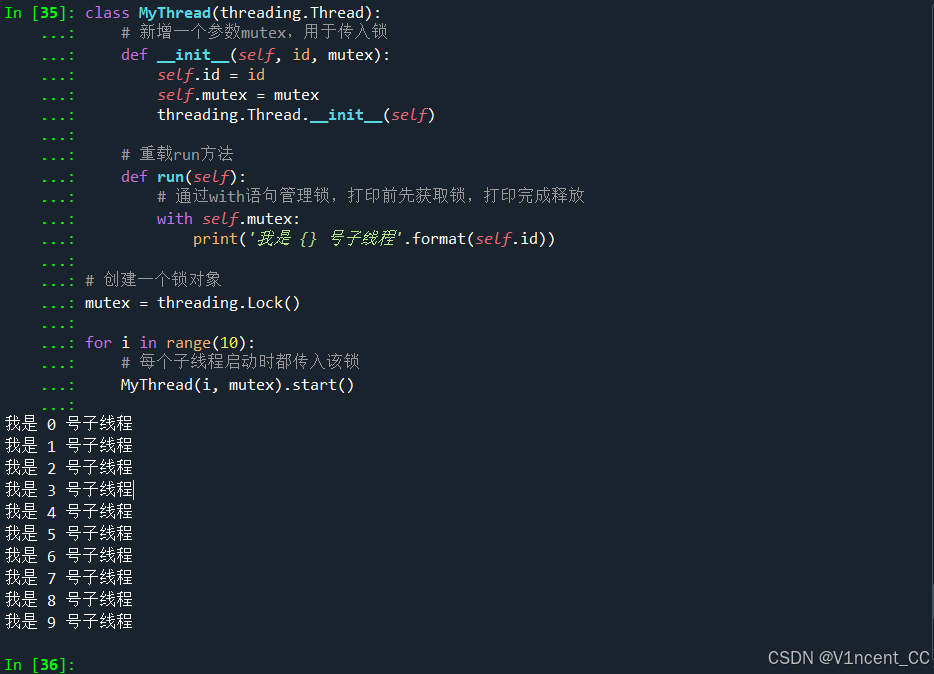
- mutex = threading.Lock() 创建了一个锁对象,并在创建子线程时传入(这10个子线程传入的是同一把锁)。
- 子类的run方法,在执行print语句前新增了with self.mutex,这会尝试获取锁,如果当前锁被其他子线程占用(正在打印),那么它会等待。
- 锁对象也可以通过.acuqure和.release方法手动获取和释放,但建议还是使用with来管理(方便)。
2.2 阻塞方法 - threading.Thread.join
每个线程对象都有一个join方法,这个方法会阻塞调用者,直到线程终结,这对于主线程来说是一个信号,通过join方法可以用来监控子线程的完成情况,适合执行在子线程完成后再执行的动作。
下面改造一下子类的run方法,让每个线程打印前随机等待1-5秒,然后调用Thread.join方法,这个方法会阻塞主线程(等待子线程完成),当所有子线程执行完毕时(.join方法返回),立刻打印"所有子线程执行完毕"。
下面代码在run方法的print之前加入了time.sleep(random.randint(1,5))让子线程随机睡眠1-5秒,因此子线程的结束时间是不确定的:
import time, random
class MyThread(threading.Thread):
# 新增一个参数mutex,用于传入锁
def __init__(self, id):
self.id = id
threading.Thread.__init__(self)
# 重载run方法
def run(self):
# 打印之前随机睡眠1-5秒
time.sleep(random.randint(1,5))
print('我是 {} 号子线程'.format(self.id))
threads = []
for i in range(10):
# 每个子线程启动时都传入该锁
ti = MyThread(i)
threads.append(ti)
ti.start()
print("开始等待子线程执行...")
for thread in threads:
# 针对每个子线程都会调用.join方法,所有子线程结束后,才会继续向下执行
thread.join()
print("所有子线程执行完毕...")
可以看到通过Thread.join方法阻塞主线程,可以保证在所有子线程都执行完毕后,才打印"所有子线程执行完毕…"。
以上即是threading模块的基本用法,子线程还有.is_alive方法用来检测是否存活,另外还有递归锁可以用来嵌套获取锁,有兴趣的同学可以深入研究一下。
最后:由于Cpython的中存在"全局解释器锁(GIL)",这个会限制利用多核CPU的计算资源(Python4.0可能会修复),因此多线程比较适合I/O密集型任务,对于CPU密集型任务,推荐还是使用多进程并发(multiprocessing模块)。
到此这篇关于Python 基于线程的并行 threading模块的用法的文章就介绍到这了,更多相关Python 线程并行threading用法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!