
python实现文字转声音的详细图文教程
作者:猿界零零七
这篇文章主要介绍了python实现文字转声音的详细图文教程,文中通过pyttsx3、pydub库实现文字转声音与变声功能,需安装ffmpeg工具,并通过代码实现文字转声音、变声及主函数调用,需要的朋友可以参考下
一、准备工资
1.1、python版本
本次实验使用的是python3.10版本
1.2、第三方工具包
使用的三方工具包:pyttsx3、pydub,pyttsx3包将文字转变为声音,pydub包实现变声
安装命令:pip install pyttsx3 pydub
1.3、其它工具
需要安装的工具:ffmpeg,据说pydub包需要用到。下载地址:FFmpeg,步骤如下:
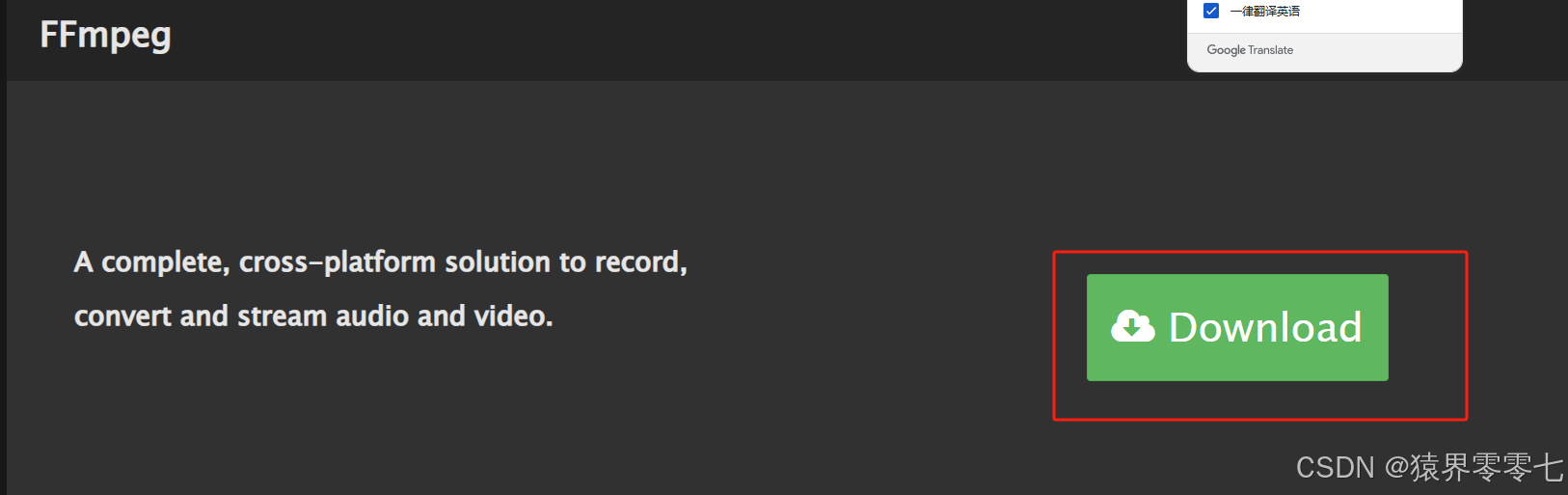
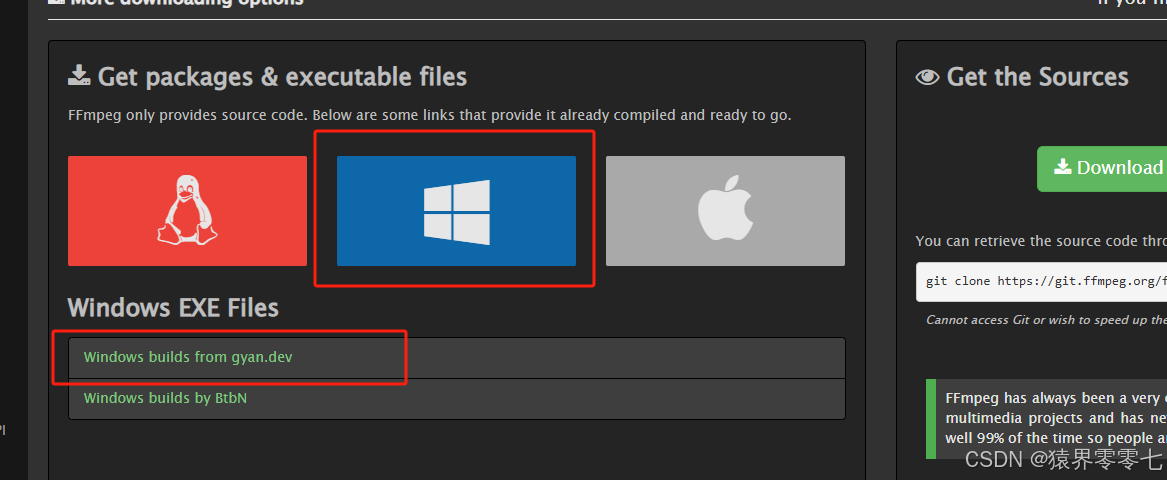
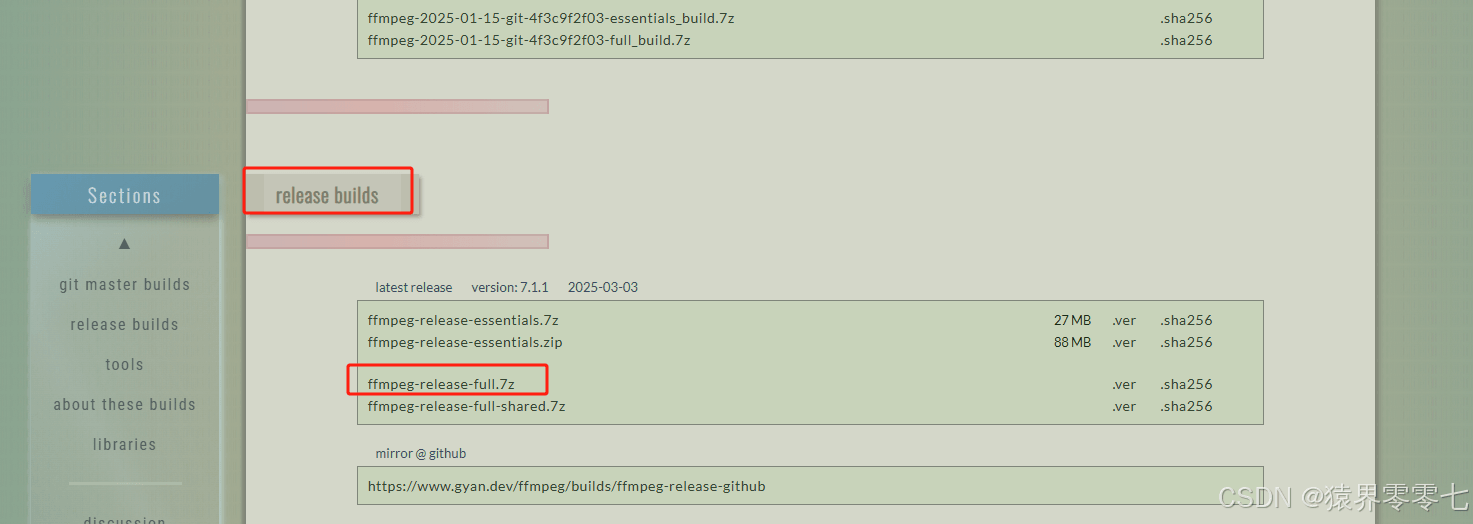
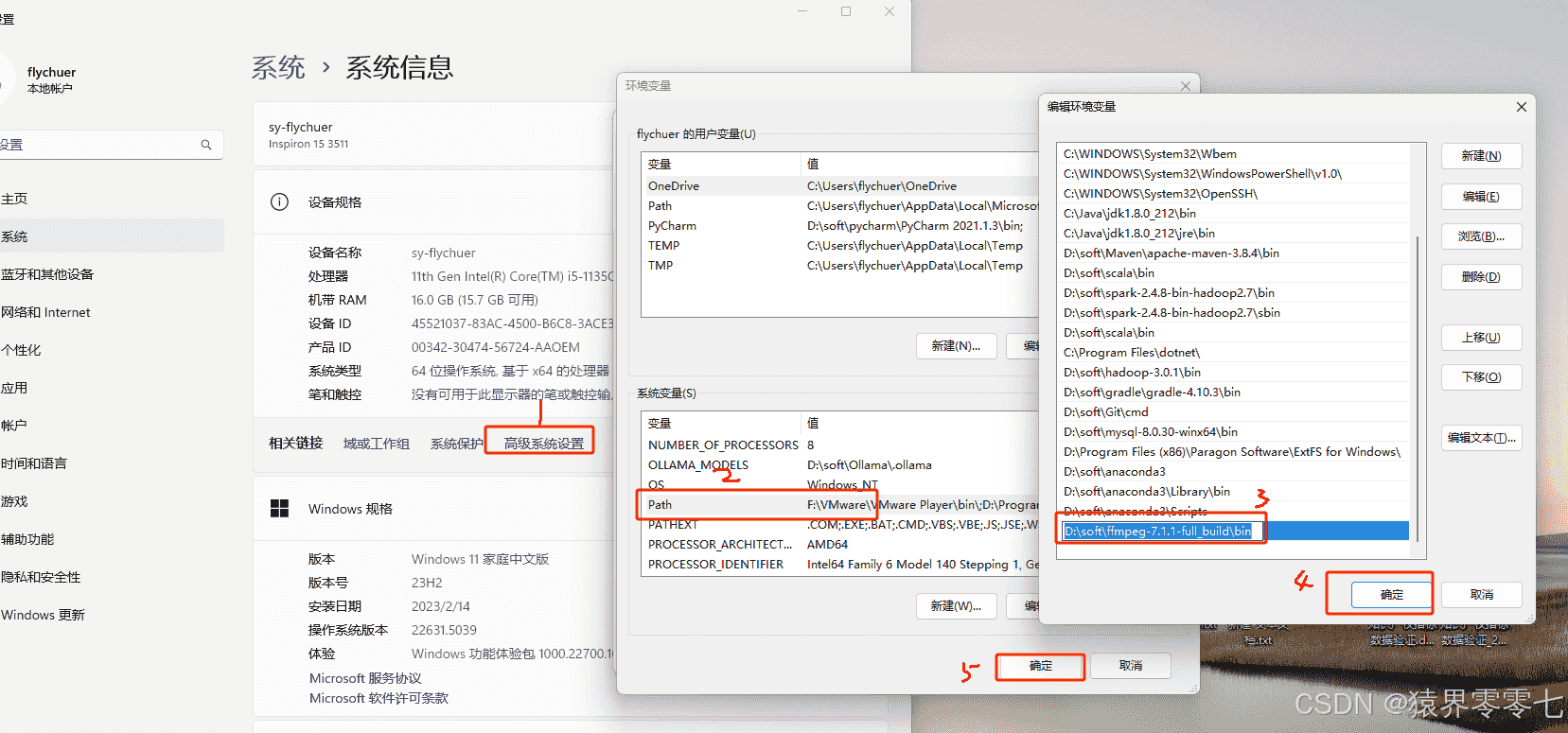
此处是个解压版本的,下载完成后,只需要将压缩包解压到指定目录下,然后配置环境变量就行了。我解压到了D盘,环境变量配置如下:
二、代码实现
2.1、文字转声音
import pyttsx3
from pydub import AudioSegment
from pydub.effects import speedup
import os
def text_to_speech_save_as_mp3(text, mp3_filename):
# 初始化 pyttsx3 引擎
engine = pyttsx3.init()
# 创建一个临时 WAV 文件
wav_filename = "temp.wav"
engine.save_to_file(text, wav_filename)
engine.runAndWait()
# 将 WAV 文件转换为 MP3
audio = AudioSegment.from_wav(wav_filename)
audio.export(mp3_filename, format="mp3")
# 删除临时 WAV 文件
import os
os.remove(wav_filename)
# 示例用法
# text = "妈 妈,妈 妈,你去哪里了?"
text = "救命啊,救命啊,老虎来了。"
mp3_filename = "output.mp3"
text_to_speech_save_as_mp3(text, mp3_filename)2.2、变声
def pitch_shift(audio, semitones):
# 计算新的采样率
new_sample_rate = int(audio.frame_rate * (2.0 ** (semitones / 12.0)))
# 生成新的音频对象,调整采样率以改变音调
return audio._spawn(audio.raw_data, overrides={'frame_rate': new_sample_rate}).set_frame_rate(audio.frame_rate)
def change_pitch(input_file, output_file, pitch_factor=1.6):
# 加载音频文件
audio = AudioSegment.from_file(input_file)
# 调整音频,通过修改semitones改变声音音频
audio_higher = pitch_shift(audio,semitones=6)
# 调整音调,通过改变音频的播放速度来模拟音调变化
new_audio = speedup(audio_higher, playback_speed=pitch_factor)
# 保存修改后的音频文件
new_audio.export(output_file, format="mp3")2.3、调用main函数
if __name__ == "__main__":
input_file = "output.mp3" # 替换为你的输入音频文件路径
output_file = "output_audio.mp3" # 输出音频文件路径
if os.path.exists(input_file):
change_pitch(input_file, output_file)
print(f"音频处理完成,输出文件: {output_file}")
else:
print(f"输入文件 {input_file} 不存在,请检查路径。")总结
到此这篇关于python实现文字转声音的文章就介绍到这了,更多相关python文字转声音内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!